App per la prenotazione delle attrezzature: evita i conflitti e monitora le restituzioni
Progetta un'app per la prenotazione delle attrezzature che eviti le doppie prenotazioni, registri restituzioni e danni e metta in manutenzione i beni difettosi.
Impara a fare modifiche allo schema senza downtime con migrazioni additive, backfill sicuri e rollout a fasi che mantengono i client vecchi funzionanti durante i rilasci.
Zero-downtime non significa che nulla cambi. Significa che gli utenti possono continuare a lavorare mentre aggiorni il database e l'app, senza errori o flussi di lavoro bloccati.
Downtime è qualsiasi momento in cui il sistema non si comporta normalmente. Può manifestarsi con errori 500, timeout delle API, schermate che si caricano ma mostrano valori vuoti o sbagliati, job in background che crashano, o un database che accetta letture ma blocca le scritture perché una migrazione lunga tiene lock.
Una modifica allo schema può rompere più del solo UI principale. Punti di fallimento comuni includono client API che si aspettano una forma di risposta vecchia, job in background che leggono o scrivono colonne specifiche, report che interrogano tabelle direttamente, integrazioni di terze parti e script amministrativi interni che “ieri funzionavano”.
Le app mobili vecchie e i client in cache sono un problema frequente perché non puoi aggiornarli istantaneamente. Alcuni utenti mantengono una versione dell'app per settimane. Altri hanno connettività intermittente e ritentano richieste vecchie. Anche i client web possono comportarsi come “versioni vecchie” quando un service worker, CDN o proxy cache mantiene codice o assunzioni obsolete.
L'obiettivo reale non è “una grande migrazione che finisce presto.” È una sequenza di piccoli passi in cui ogni passo funziona da solo, anche quando client diversi sono su versioni diverse.
Una definizione pratica: dovresti essere in grado di distribuire nuovo codice e nuovo schema in qualsiasi ordine, e il sistema funziona comunque.
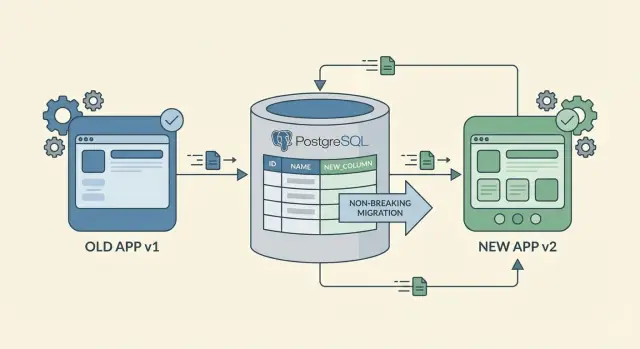
Questo approccio ti aiuta ad evitare la trappola classica: distribuire una nuova app che si aspetta una colonna nuova prima che la colonna esista, o aggiungere una nuova colonna che il codice vecchio non sa gestire. Pianifica i cambiamenti per essere prima additivi, rilasciali a fasi e rimuovi i percorsi vecchi solo dopo esserti accertato che nessuno li usa.
La strada più sicura verso modifiche allo schema senza downtime è aggiungere, non sostituire. Aggiungere una colonna o una tabella nuova raramente rompe qualcosa perché il codice esistente può continuare a leggere e scrivere la forma vecchia.
Rinominare e cancellare sono mosse rischiose. Una rinomina è in pratica “aggiungi nuovo + rimuovi vecchio”, e la parte "rimuovi vecchio" è dove i client più vecchi vanno in crash. Se ti serve rinominare, trattalo come un cambiamento in due fasi: aggiungi prima il campo nuovo, mantieni quello vecchio per un po’, e rimuovilo solo quando sei sicuro che nessuno dipenda più da esso.
Quando aggiungi colonne, inizia con campi nullable. Una colonna nullable permette al codice vecchio di continuare a inserire righe senza conoscere il nuovo campo. Se alla fine vuoi NOT NULL, aggiungilo prima come nullable, esegui il backfill e poi imponi NOT NULL più tardi. I default possono aiutare, ma attenzione: aggiungere un default può comunque toccare molte righe in alcuni database, rallentando il cambiamento.
Gli indici sono un’altra aggiunta “sicura ma non gratuita”. Possono rendere le letture più veloci, ma creare e mantenere un indice può rallentare le scritture. Aggiungi indici quando sai esattamente quale query li userà e considera di farlo in orari più tranquilli se il DB è sotto carico.
Una semplice serie di regole per migrazioni additive:
Considera le modifiche zero-downtime come un rollout, non come un singolo deploy. L'obiettivo è lasciare che versioni vecchie e nuove dell'app girino insieme mentre il database si sposta gradualmente alla nuova forma.
Una sequenza pratica:
Esempio: introduci full_name ma i client più vecchi inviano ancora first_name e last_name. Per un periodo il backend può costruire full_name in scrittura, backfillare gli utenti esistenti, poi leggere full_name per default continuando a supportare i payload vecchi. Solo quando l’adozione è chiara elimini i campi vecchi.
Un backfill popola una nuova colonna o tabella per le righe esistenti. È spesso la parte più rischiosa delle modifiche zero-downtime perché può generare carico pesante sul database, lock lunghi e comportamenti “metà migrati” confusi.
Inizia scegliendo come eseguire il backfill. Per dataset piccoli, una runbook manuale una tantum può andare bene. Per dataset grandi, preferisci un worker in background o un task schedulato che possa girare ripetutamente e fermarsi in sicurezza.
Batti il lavoro a batch così controlli la pressione sul DB. Non aggiornare milioni di righe in una sola transazione. Punta a una dimensione dei chunk prevedibile e a una breve pausa tra i batch così il traffico utente normale resta fluido.
Un pattern pratico:
Rendi il job riavviabile. Memorizza un semplice indicatore di progresso in una tabella dedicata e progetta il job in modo che rieseguirelo non corrompa i dati. Aggiornamenti idempotenti (per esempio, UPDATE ... WHERE new_field IS NULL) sono tuoi alleati.
Valida mentre procedi. Tieni traccia di quante righe sono ancora senza il nuovo valore e aggiungi alcuni controlli di sanità. Per esempio: nessun saldo negativo, timestamp in un intervallo atteso, status in un set consentito. Controlla a campione record reali.
Decidi cosa deve fare l'app mentre il backfill è incompleto. Un'opzione sicura è le letture fallback: se il campo nuovo è null, calcola o leggi il valore vecchio. Esempio: aggiungi preferred_language. Finché il backfill non termina, l'API può restituire la lingua esistente dalle impostazioni del profilo quando preferred_language è vuoto, e iniziare a richiedere il campo solo dopo il completamento.
Quando spedisci una modifica allo schema, raramente controlli ogni client. Gli utenti web si aggiornano velocemente, mentre build mobili vecchie possono restare attive per settimane. Per questo le API retrocompatibili sono importanti anche se la migrazione del DB è “sicura”.
Tratta i nuovi dati come opzionali all'inizio. Aggiungi nuovi campi a richieste e risposte, ma non li richiedere dal primo giorno. Se un client vecchio non invia il campo nuovo, il server dovrebbe comunque accettare la richiesta e comportarsi come prima.
Evita di cambiare il significato dei campi esistenti. Rinominare un campo può andare bene se mantieni funzionante il nome vecchio. Riutilizzare un campo per un nuovo significato è dove avvengono rotture sottili.
I default server-side sono la tua rete di sicurezza. Quando introduci una colonna come preferred_language, imposta un default sul server quando manca. La risposta API può includere il campo nuovo e i client vecchi possono ignorarlo.
Regole di compatibilità che prevengono la maggior parte degli outage:
Esempio: aggiungi company_size al flusso di signup. Il backend può impostare un default come “unknown” quando il campo manca. I client nuovi inviano il valore reale, quelli vecchi continuano a funzionare e i dashboard restano leggibili.
Se la tua piattaforma rigenera l'applicazione, ottieni una ricostruzione pulita di codice e configurazione. Questo aiuta con le modifiche zero-downtime perché puoi fare piccoli passi additivi e ridistribuire spesso invece di tenere patch per mesi.
La chiave è una sola fonte di verità. Se lo schema DB cambia in un posto e la logica business in un altro, il drift avviene in fretta. Decidi dove definire i cambiamenti e tratta tutto il resto come output generato.
Naming chiaro riduce gli incidenti durante rollout a fasi. Se introduci un campo nuovo, rendi ovvio quale è sicuro per i client vecchi e quale è il percorso nuovo. Per esempio, nominare una colonna status_v2 è più sicuro di status_new perché ha senso anche fra sei mesi.
Anche quando i cambiamenti sono additivi, una ricostruzione può far emergere accoppiamenti nascosti. Dopo ogni rigenerazione e deploy, ricontrolla un piccolo set di flussi critici:
Pianifica i passaggi di migrazione prima di aprire l'editor: aggiungi il campo nuovo, distribuisci con entrambi i campi supportati, esegui il backfill, passa alle letture, poi ritira il percorso vecchio più tardi. Questa sequenza mantiene schema, logica e codice generato allineati così i cambiamenti restano piccoli, revisionabili e reversibili.
La maggior parte degli outage durante modifiche zero-downtime non sono causati dal “lavoro duro” sul database. Derivano dal cambiare il contratto tra database, API e client nell'ordine sbagliato.
Trappole comuni e mosse più sicure:
Se rigeneri l'app, è tentante “pulire” nomi e vincoli in un colpo solo. Resisti. Il cleanup è l'ultimo passo, non il primo.
Una buona regola: se un cambiamento non può essere tranquillamente portato avanti e invertito, non è pronto per la produzione.
Le modifiche zero-downtime si vincono o si perdono su due cose: cosa osservi e quanto velocemente puoi fermare.
Monitora segnali che riflettono l'impatto reale sull'utente, non solo “il deploy è finito”:
Se fai dual writes, aggiungi logging temporaneo che confronta i due. Mantienilo ristretto: logga solo quando valori divergono, includi l'ID del record e un breve codice motivo, e campiona se il volume è alto. Crea un promemoria per rimuovere questo logging dopo la migrazione così non diventi rumore permanente.
Il rollback deve essere realistico. Di solito non torni indietro con lo schema. Torni indietro con il codice e lasci lo schema additivo.
Un runbook pratico di rollback:
Per i backfill, costruisci un interruttore di stop che puoi premere in pochi secondi (feature flag, valore di config, pausa del job). Comunica anche le fasi in anticipo: quando iniziano le dual write, quando gira il backfill, quando cambiano le letture e cosa significa “stop” così nessuno improvvisa sotto pressione.
Poco prima di spedire una modifica allo schema, fermati e fai questo controllo rapido. Cattura quelle piccole assunzioni che diventano outage quando ci sono versioni client miste.
Se usi una piattaforma che rigenera, aggiungi un ulteriore controllo: genera e distribuisci una build esattamente dal modello che stai migrando, poi conferma che l'API e la logica generate tollerino ancora i record vecchi. Un fallimento comune è presumere che il nuovo schema implichi logica richiesta nuova.
Scrivi anche due azioni rapide da eseguire se qualcosa va storto dopo il deploy: cosa monitorare (errori, timeout, progresso del backfill) e cosa revertare prima (spegnere il feature flag, mettere in pausa il backfill, revertare la release server). Questo trasforma “reagire velocemente” in un piano reale.
Gestisci un'app di ordini. Ti serve un campo nuovo, delivery_window, che sarà richiesto per nuove regole di business. Il problema è che build iOS e Android più vecchie sono ancora in uso e non invieranno quel campo per giorni o settimane. Se rendi il DB obbligatorio subito, quei client inizieranno a fallire.
Un percorso sicuro:
delivery_window per le righe vecchie usando una regola (inferisci dal metodo di spedizione, o usa “anytime” finché il cliente non lo modifica).delivery_window prima, ma fai fallback al valore inferito quando manca.Cosa percepiscono gli utenti durante ogni fase resta noioso (questo è l'obiettivo):
Un gate di monitoraggio semplice per ogni passo: traccia la percentuale di nuovi ordini con delivery_window non null. Quando resta costantemente alta (e gli errori di validazione per “campo mancante” sono vicini allo zero), di solito è sicuro passare da backfill a imporre il vincolo.
Una rollout attento una-tantum non è una strategia. Tratta le modifiche allo schema come routine: stessi passi, stessa nomenclatura, stessi OK. Così la prossima modifica additiva resta noiosa, anche quando l'app è impegnata e i client sono su versioni diverse.
Mantieni il playbook breve. Deve rispondere: cosa aggiungiamo, come lo distribuiamo in sicurezza e quando rimuoviamo le parti vecchie.
Un template semplice:
Inizia con una tabella a basso rischio (uno status opzionale nuovo, un campo note) e percorri l'intero playbook: cambiamento additivo, backfill, client in versione mista e poi cleanup. Quella prova pratica mette in luce gap in monitoraggio, batching e comunicazione prima di tentare una grande riprogettazione.
Una buona abitudine che previene confusione a lungo termine: traccia le voci “rimuovere dopo” come lavoro reale. Quando aggiungi una colonna temporanea, codice di compatibilità o logica di dual-write, crea subito un ticket di cleanup con un owner e una data. Tieni un piccolo appunto di “debito di compatibilità” nei documenti di rilascio così resta visibile.
Se costruisci con AppMaster, puoi trattare la rigenerazione come parte del processo di sicurezza: modella lo schema additivo, aggiorna la logica di business per gestire sia i campi vecchi che quelli nuovi durante la transizione, e rigenera così il codice sorgente resta pulito man mano che i requisiti cambiano. Se vuoi vedere come questo workflow si adatta a un setup no-code che produce comunque codice reale, AppMaster (appmaster.io) è progettato attorno a questo stile di delivery iterativa e a fasi.
L'obiettivo non è la perfezione. È la ripetibilità: ogni migrazione ha un piano, una metrica e una rampa di uscita.
Zero-downtime significa che gli utenti possono continuare a lavorare normalmente mentre cambi lo schema e distribuisci codice. Include evitare interruzioni evidenti, ma anche rotture silenziose come schermate vuote, valori errati, crash di job o scritture bloccate da lock lunghi.
Perché molte parti del sistema dipendono dalla forma del database, non solo dall'interfaccia principale. Job in background, report, script amministrativi, integrazioni e app mobili vecchie possono continuare a inviare o aspettarsi campi obsoleti molto dopo il deploy del nuovo codice.
Perché build mobili più vecchie possono restare in uso per settimane, e alcuni client ritentano richieste più vecchie in seguito. La tua API deve accettare sia payload vecchi che nuovi per un po’ in modo che le versioni miste possano coesistere senza errori.
Le modifiche additive di solito non rompono il codice esistente perché lo schema vecchio resta presente. Rinominare o cancellare è rischioso perché rimuove qualcosa che i client vecchi ancora leggono o scrivono, causando crash o richieste fallite.
Aggiungi prima la colonna come nullable così il codice vecchio può continuare a inserire righe. Esegui il backfill delle righe esistenti a batch, poi solo quando la copertura è alta e le scritture nuove sono coerenti imponi NOT NULL come passo finale.
Trattala come un rollout: aggiungi uno schema compatibile, deploya codice che supporta entrambe le versioni, esegui backfill a piccoli batch, cambia le letture con un fallback e rimuovi il campo vecchio solo quando puoi dimostrare che non viene più usato. Ogni step deve funzionare da solo.
Esegui il backfill a piccoli batch con transazioni brevi per non bloccare le tabelle o sovraccaricare il DB. Rendi il job riavviabile e idempotente aggiornando solo le righe mancanti e tracciando il progresso in modo da poter mettere in pausa e riprendere in sicurezza.
Rendi i nuovi campi opzionali all'inizio e applica default sul server quando mancano. Mantieni stabile il comportamento vecchio, evita di cambiare il significato di campi esistenti e testa entrambe le strade: “il client nuovo lo invia” e “il client vecchio lo omette”.
Nella maggior parte dei casi reverti il codice applicativo, non lo schema. Mantieni le colonne/tabelle additive, disabilita prima le nuove letture, poi le nuove scritture, e metti in pausa i backfill finché le metriche non tornano stabili per recuperare senza perdita di dati.
Monitora segnali di impatto reale sull'utente come tassi di errore, query lente, latenza delle scritture, profondità delle code e CPU/IO del DB. Procedi solo quando i metriche sono stabili e la copertura del nuovo campo è alta, poi programma il cleanup come lavoro reale, non come “poi”.



Sperimenta con AppMaster con un piano gratuito.
Quando sarai pronto potrai scegliere l'abbonamento appropriato.


