App per la prenotazione delle attrezzature: evita i conflitti e monitora le restituzioni
Progetta un'app per la prenotazione delle attrezzature che eviti le doppie prenotazioni, registri restituzioni e danni e metta in manutenzione i beni difettosi.
Log di audit pratici per strumenti interni: traccia chi ha fatto cosa e quando su ogni modifica CRUD, conserva diff in modo sicuro e mostra un feed attività admin.
La maggior parte dei team aggiunge i log di audit solo dopo che qualcosa è andato storto. Un cliente contesta una modifica, un valore finanziario si sposta, o un auditor chiede: "Chi ha approvato questo?" Se inizi solo allora, finisci per ricostruire il passato da indizi parziali: timestamp del database, messaggi Slack e supposizioni.
Per la maggior parte delle app interne, "sufficiente per la conformità" non significa un sistema forense perfetto. Significa poter rispondere a un piccolo insieme di domande in modo rapido e coerente: chi ha fatto la modifica, quale record è stato interessato, cosa è cambiato, quando è successo e da dove è partita l'azione (UI, import, API, automazione). Questa chiarezza è ciò che rende un log di audit qualcosa di cui le persone si fidano.
Dove i log di audit falliscono di solito non è il database. È la copertura. La cronologia sembra a posto per modifiche semplici, poi appaiono gap nel momento in cui il lavoro accelera. I colpevoli comuni sono modifiche in blocco, import, job pianificati, azioni admin che bypassano le schermate normali (come resettare password o cambiare ruoli) e cancellazioni (soprattutto hard delete).
Un altro fallimento frequente è mescolare i log di debug con i log di audit. I log di debug sono fatti per sviluppatori: rumorosi, tecnici e spesso incoerenti. I log di audit servono alla responsabilità: campi coerenti, wording chiaro e un formato stabile che puoi mostrare ai non ingegneri.
Un esempio pratico: un manager del supporto cambia il piano di un cliente, poi un'automazione aggiorna i dettagli di fatturazione più tardi. Se registri solo "updated customer", non puoi dire se l'ha fatto una persona, un workflow o se un import l'ha sovrascritto.
Un buon audit logging parte da un obiettivo: una persona dovrebbe leggere una voce e capire cosa è successo senza indovinare.
Memorizza un attore chiaro per ogni modifica. Molti team si fermano a "user id", ma gli strumenti interni spesso modificano dati da più porte.
Includi un tipo di attore e un identificatore dell'attore, così puoi distinguere tra un membro dello staff, un account di servizio o un'integrazione esterna. Se hai team o tenant, memorizza anche l'id dell'organizzazione o dello workspace così gli eventi non si mescolano.
Cattura l'azione (create, update, delete, restore) più il target. "Target" dovrebbe essere sia comprensibile per un umano che preciso: nome della tabella o dell'entità, id del record e idealmente un'etichetta breve (come un numero d'ordine) per una rapida lettura.
Un set minimo pratico di campi:
Memorizza il timestamp in UTC. Sempre. Poi mostralo nel fuso orario del viewer nell'interfaccia admin. Questo evita discussioni del tipo "due persone hanno visto orari diversi" durante una review.
Se gestisci azioni ad alto rischio come cambi di ruolo, rimborsi o esportazioni di dati, aggiungi un campo "reason". Anche una nota breve come "Approvato dal manager nel ticket 1842" può trasformare una traccia di audit da rumore a prova.
La prima scelta progettuale è dove risiede la "verità" della cronologia delle modifiche. La maggior parte dei team finisce con uno dei due modelli: un event log append-only, o tabelle di history versionate per entità.
Un event log è una singola tabella che registra ogni azione come una nuova riga. Ogni riga memorizza chi l'ha fatta, quando è avvenuta, quale entità ha toccato e un payload (spesso JSON) che descrive la modifica.
Questo modello è semplice da aggiungere e flessibile quando il modello dati evolve. Si mappa anche in modo naturale su un feed attività admin perché il feed è fondamentalmente "eventi più recenti prima".
L'approccio versioned history crea tabelle di history per entità, come Order_history o User_versions, dove ogni aggiornamento crea un nuovo snapshot completo (o un set strutturato di campi cambiati) con un numero di versione.
Questo rende più facile il reporting point-in-time ("come era questo record martedì scorso?"). Può anche sembrare più chiaro per gli auditor, perché la timeline di ogni record è autocontenuta.
Un modo pratico per scegliere:
Qualunque sia la scelta, mantieni le voci di audit immutabili: niente aggiornamenti, niente cancellazioni. Se qualcosa era sbagliato, aggiungi una nuova voce che spiega la correzione.
Considera anche di aggiungere un correlation_id (o operation id). Una singola azione utente spesso genera più modifiche (per esempio, "Disattiva utente" aggiorna l'utente, revoca sessioni e cancella task pendenti). Un correlation id condiviso ti permette di raggruppare quelle righe in un'unica operazione leggibile.
Un audit logging affidabile parte da una regola: ogni write passa per un'unica strada che scrive anche l'evento di audit. Se alcuni aggiornamenti avvengono in un job in background, in un import o in una schermata di modifica veloce che bypassa il flusso di salvataggio, i tuoi log avranno buchi.
Per le create, registra l'attore e la source (UI, API, import). Gli import sono dove i team spesso perdono il "chi", quindi memorizza un valore esplicito "performed by" anche se i dati vengono da un file o da un'integrazione. È utile anche salvare i valori iniziali (o uno snapshot completo o un piccolo insieme di campi chiave) così puoi spiegare perché esiste un record.
Gli update sono più complessi. Puoi registrare solo i campi cambiati (piccolo, leggibile e veloce), o salvare uno snapshot completo dopo ogni salvataggio (semplice da interrogare dopo, ma pesante). Un compromesso pratico è salvare diff per le modifiche normali e snapshot solo per oggetti sensibili (come permessi, dati bancari o regole di prezzo).
Le delete non devono cancellare le prove. Preferisci una soft delete (un flag is_deleted più un evento di audit). Se devi fare hard delete, scrivi prima l'evento di audit e includi uno snapshot del record così puoi dimostrare cosa è stato rimosso.
Tratta l'undelete come un'azione a sé. "Restore" non è la stessa cosa di "Update", e separarla rende revisioni e controlli di conformità molto più semplici.
Per le modifiche in blocco, evita una singola voce vaga come "updated 500 records." Devi avere abbastanza dettaglio per rispondere a "quali record sono cambiati?" più tardi. Un pattern pratico è un evento parent più eventi child per record:
Esempio: un team leader del supporto chiude in blocco 120 ticket. La voce parent cattura il filtro "status=open, older than 30 days," e ogni ticket ottiene una voce child che mostra status open -> closed.
I log di audit si trasformano in spazzatura in fretta quando o memorizzano troppo (ogni record completo, per sempre) o troppo poco (solo "edited user"). L'obiettivo è una registrazione difendibile per la conformità e leggibile da un admin.
Un default pratico è memorizzare un diff a livello di campo per la maggior parte degli aggiornamenti. Salva solo i campi che sono cambiati, con i valori "before" e "after". Questo mantiene lo storage basso e rende il feed attività facile da scorrere: "Status: Pending -> Approved" è più chiaro di un gigantesco blob.
Conserva snapshot completi per i momenti che contano: create, delete e transizioni di workflow importanti. Uno snapshot è più pesante, ma ti protegge quando qualcuno chiede "Com'era esattamente il profilo cliente prima che venisse rimosso?"
I dati sensibili richiedono regole di mascheramento, altrimenti la tabella di audit diventa un secondo database pieno di segreti. Regole comuni:
I cambi di schema possono anche rompere la cronologia di audit. Se un campo viene rinominato o rimosso in seguito, memorizza un fallback sicuro come "unknown field" più la chiave del campo originale. Per i campi eliminati tieni l'ultimo valore noto ma segnalalo come "field removed from schema" così il feed resta onesto.
Infine, rendi le voci leggibili per gli umani. Memorizza etichette di visualizzazione ("Assigned to") insieme alle chiavi raw ("assignee_id"), e formatta i valori (date, valuta, nomi di stato).
Una traccia di audit affidabile non riguarda il loggare di più. Riguarda l'uso di un pattern ripetibile ovunque così non finisci con buchi tipo "l'import in blocco non è stato registrato" o "le modifiche da mobile sembrano anonime."
Inizia nel modello dati e crea un piccolo set di tabelle che possano descrivere qualsiasi cambiamento.
Mantienilo semplice: una tabella per l'evento, una per i campi cambiati e un piccolo contesto attore.
Crea un sotto-processo riutilizzabile che:
La regola è ferrea: ogni percorso di scrittura deve chiamare questo stesso sotto-processo. Questo include pulsanti UI, endpoint API, automazioni pianificate e integrazioni.
Non fidarti del browser per il "chi" e il "quando." Leggi l'attore dalla sessione di autenticazione e genera i timestamp lato server. Se un'automazione gira, imposta actor_type su system e salva il nome del job come label dell'attore.
Scegli un singolo record (come un ticket cliente): crealo, modifica due campi (status e assignee), cancellalo, poi ristabiliscilo. Il feed di audit dovrebbe mostrare cinque eventi, con due item di update sotto l'evento di edit, e attore e timestamp popolati nello stesso modo ogni volta.
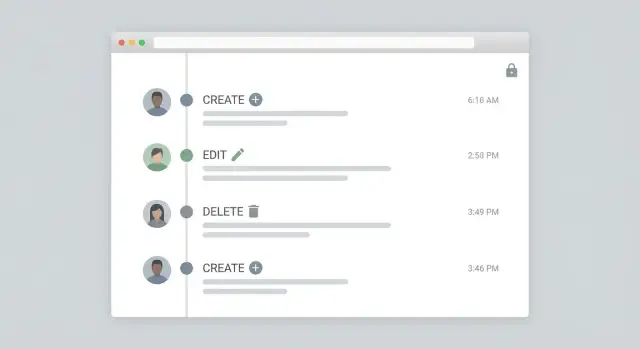
Un log di audit è utile solo se qualcuno lo può leggere rapidamente durante una review o un incidente. L'obiettivo del feed admin è semplice: rispondere a "cosa è successo?" a colpo d'occhio, e poi permettere un approfondimento senza annegare le persone in JSON raw.
Inizia con un layout a timeline: più recenti prima, una riga per evento, e verbi chiari come Created, Updated, Deleted, Restored. Ogni riga dovrebbe mostrare l'attore (persona o sistema), il target (tipo di record più un nome leggibile), e l'ora.
Un formato di riga pratico:
Mantieni "cosa è cambiato" compatto. Mostra 1-3 campi inline, poi offri un pannello di drill-down (drawer/modal) che rivela i dettagli completi: valori before/after, source della request (web, mobile, API) e ogni campo reason/comment.
Il filtraggio è ciò che rende il feed usabile dopo la prima settimana. Concentrati su filtri che rispondono a domande reali:
Linkare è utile, ma solo quando permesso. Se il viewer ha accesso al record interessato, mostra un'azione "View record". Altrimenti mostra un placeholder sicuro (per esempio, "Restricted record") mantenendo visibile la voce di audit.
Rendi le azioni di sistema evidenti. Etichetta job schedulati e integrazioni distintamente così gli admin possono distinguere "Dana l'ha cancellato" da "Nightly billing sync l'ha aggiornato."
I log di audit sono prove, ma sono anche dati sensibili. Tratta l'audit logging come un prodotto separato dentro la tua app: regole di accesso chiare, limiti definiti e gestione attenta delle informazioni personali.
Decidi chi può vedere cosa. Una divisione comune è: system admin vede tutto; manager di dipartimento vede eventi per il proprio team; il proprietario del record vede eventi legati ai record che già può visualizzare (e nient'altro). Se esponi un activity feed, applica le stesse regole a ogni riga, non solo alla schermata.
La visibilità a livello di riga è cruciale in strumenti multi-tenant o cross-department. La tabella di audit dovrebbe avere le stesse chiavi di scoping dei dati business (tenant_id, department_id, project_id), così puoi filtrare in modo coerente. Esempio: un manager del supporto dovrebbe vedere le modifiche ai ticket della sua coda, ma non gli aggiustamenti salariali in HR, anche se avvengono nella stessa app.
Una policy semplice che funziona nella pratica:
La privacy è la seconda metà. Conserva abbastanza per dimostrare cosa è successo, ma evita di trasformare il log in una copia del database. Per campi sensibili (SSN, note mediche, dettagli di pagamento) preferisci la redazione: registra che il campo è cambiato senza memorizzare il vecchio/nuovo valore. Puoi loggare "email changed" mascherando il valore reale, o salvare un'impronta hash per verifica.
Mantieni gli eventi di sicurezza separati dalle modifiche di record business. Tentativi di login, reset MFA, creazione di API key e cambi di ruolo dovrebbero andare in uno stream security_audit con accesso più restrittivo e retention più lunga. Le modifiche business (aggiornamenti di stato, approvazioni, cambi di workflow) possono vivere in uno stream generale di audit.
Quando qualcuno richiede la cancellazione dei dati personali, non cancellare l'intero audit trail. Invece:
Un audit log utile non è solo "registriamo eventi." Per la conformità, devi dimostrare tre cose: hai conservato i dati abbastanza a lungo, non sono stati modificati dopo il fatto e puoi recuperarli rapidamente quando servono.
Inizia con una regola semplice che corrisponda al tuo rischio. Molti team scelgono 90 giorni per il troubleshooting quotidiano, 1-3 anni per la compliance interna e più a lungo solo per record regolamentati. Metti per iscritto cosa resetta il conteggio (spesso: event time) e cosa è escluso (per esempio, log che includono campi che non dovresti conservare).
Se hai più ambienti, imposta retention diverse per ambiente. I log di produzione generalmente richiedono la retention più lunga; i log di test spesso non ne hanno bisogno.
Tratta i log di audit come append-only. Non aggiornare le righe e non permettere agli admin normali di cancellarle. Se una cancellazione è davvero necessaria (richiesta legale, pulizia dati), registra anche quell'azione come evento a sé.
Un pattern pratico:
Gli auditor spesso richiedono CSV o JSON. Pianifica un'esportazione che filtri per intervallo di date e tipo di oggetto (come Invoice, User, Ticket) così non stai interrogando il DB nel peggior momento.
Per le performance, indicizza in base a come cerchi:
Tieni d'occhio i fallimenti silenziosi. Se la scrittura degli audit fallisce, perdi prove e spesso non te ne accorgi. Aggiungi un alert semplice: se l'app elabora scritture ma gli eventi di audit scendono a zero per un periodo, notifica i proprietari e logga l'errore in modo evidente.
Il modo più veloce per perdere tempo è raccogliere molte righe che non rispondono alle vere domande: chi ha cambiato cosa, quando e da dove.
Una trappola comune è affidarsi solo a trigger del database. I trigger possono registrare che una riga è cambiata, ma spesso perdono il contesto business: quale schermata ha usato l'utente, quale request l'ha causata, quale ruolo aveva e se è stata una modifica normale o una regola automatica.
Errori che più spesso rompono la conformità e l'usabilità quotidiana:
Standardizza il vocabolario degli eventi presto (per esempio: user.created, user.updated, invoice.voided, access.granted) e richiedi a ogni percorso di scrittura di emettere un evento. Tratta i dati di audit come write-once: se qualcuno ha fatto la modifica sbagliata, logga una nuova azione correttiva invece di riscrivere la storia.
Prima di considerarlo fatto, esegui alcuni controlli rapidi. Un buon audit log è noioso nel modo migliore: completo, coerente e facile da leggere quando qualcosa va storto.
Usa questa checklist in un ambiente di test con dati realistici:
Se costruisci strumenti interni con AppMaster (appmaster.io), un modo pratico per mantenere alta la copertura è instradare azioni UI, endpoint API, import e automazioni attraverso lo stesso Business Process che scrive sia la modifica dei dati sia l'evento di audit. Così il tuo audit trail CRUD resta coerente anche quando schermi e workflow cambiano.
Inizia in piccolo con un workflow che conta (ticket, approvazioni, modifiche di fatturazione), rendi leggibile il feed attività, poi estendi finché ogni percorso di scrittura emette un evento di audit prevedibile e cercabile.
Aggiungi i log di audit non appena lo strumento può modificare dati reali. La prima disputa o richiesta di audit arriva spesso prima di quanto pensi, e ricostruire la storia dopo è per lo più lavoro di congetture.
Un log di audit utile deve rispondere a chi ha fatto la modifica, quale record è stato interessato, cosa è cambiato, quando è successo e da dove è partita l'azione (UI, API, import o job). Se non puoi rispondere rapidamente a una di queste, il log non sarà affidabile.
I log di debug sono destinati agli sviluppatori: rumorosi e incoerenti. I log di audit servono alla responsabilità: campi stabili, wording chiaro e un formato leggibile anche per non ingegneri nel tempo.
La copertura spesso fallisce quando le modifiche avvengono fuori dalla schermata di modifica normale. Modifiche in blocco, import, job schedulati, scorciatoie admin e cancellazioni sono i punti comuni dove si dimentica di emettere eventi di audit.
Conserva un tipo di attore e un identificatore dell'attore, non solo un user id. Così puoi distinguere chiaramente un membro dello staff da un job di sistema, un account di servizio o un'integrazione esterna e evitare l'ambiguità del tipo "qualcuno l'ha fatto".
Memorizza i timestamp in UTC nel database, poi mostrali nel fuso orario del visualizzatore nell'interfaccia admin. Questo evita discussioni sui fusi orari e rende le esportazioni coerenti tra team e sistemi.
Usa un event log append-only quando vuoi un unico posto per cercare ed un feed attività semplice. Usa versioned history quando necessiti frequentemente di viste point-in-time di un singolo record; in molte app, un event log con diff a livello di campo copre la maggior parte dei casi con meno spazio.
Preferisci soft delete e registra esplicitamente l'azione di cancellazione. Se devi fare hard delete, scrivi prima l'evento di audit e includi uno snapshot o i campi chiave così da poter dimostrare cosa è stato rimosso.
Una pratica comune è memorizzare diff a livello di campo per gli aggiornamenti e snapshot per create e delete. Per i campi sensibili registra che il valore è cambiato senza salvare il segreto stesso, e redigi o maschera i dati personali così che il log non diventi una copia del database.
Crea un unico percorso "write + audit" e obbliga ogni scrittura a usarlo: azioni UI, endpoint API, import e job in background. In AppMaster, i team spesso implementano questo come un Business Process riutilizzabile che esegue la modifica dei dati e scrive l'evento di audit nello stesso flusso per evitare buchi.



Sperimenta con AppMaster con un piano gratuito.
Quando sarai pronto potrai scegliere l'abbonamento appropriato.


