App per la prenotazione delle attrezzature: evita i conflitti e monitora le restituzioni
Progetta un'app per la prenotazione delle attrezzature che eviti le doppie prenotazioni, registri restituzioni e danni e metta in manutenzione i beni difettosi.
Indicizzazione per pannelli admin: ottimizza i filtri più usati (status, assignee, intervalli di date, ricerca testuale) basandoti sui reali pattern di query.
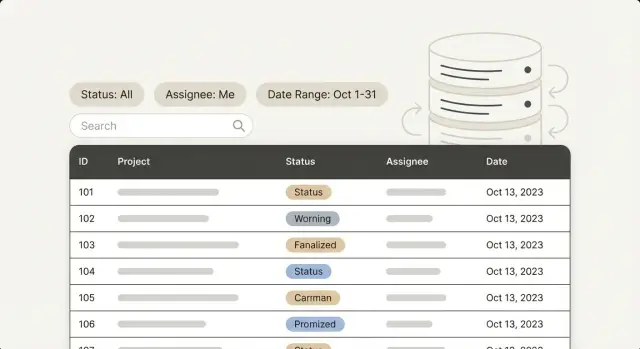
I pannelli amministrativi spesso partono veloci. Apri una lista, scorri, clicchi un record e vai avanti. Il rallentamento emerge quando le persone filtrano nel modo in cui lavorano davvero: "Solo ticket aperti", "Assegnato a Maya", "Creati la settimana scorsa", "Order ID contiene 1047". Ogni clic provoca un'attesa e la lista comincia a sembrare appiccicosa.
Lo stesso tavolo può essere veloce per un filtro e dolorosamente lento per un altro. Un filtro di status può toccare una fetta piccola di righe e rispondere subito. Un filtro "creato fra due date" può costringere il database a leggere un intervallo enorme. Un filtro per assignee può funzionare da solo e poi rallentare quando lo combini con status e ordinamento.
Gli indici sono la scorciatoia che il database usa per trovare le righe corrispondenti senza leggere tutta la tabella. Ma gli indici non sono gratuiti. Occupano spazio e rendono leggermente più lenti insert e update. Aggiungerne troppi può appesantire le scritture e comunque non risolvere il vero collo di bottiglia.
Invece di indicizzare tutto, dai priorità ai filtri che:
Questo articolo rimane intenzionalmente focalizzato. Le prime lamentele sulle prestazioni nelle liste amministrative arrivano quasi sempre dagli stessi quattro tipi di filtro: status, assignee, intervalli di date e campi di testo. Una volta capito perché si comportano diversamente, i passi successivi sono chiari: guarda i pattern reali di query, aggiungi il più piccolo indice che li soddisfa e verifica che il percorso lento sia migliorato senza introdurre nuovi problemi.
I pannelli admin raramente sono lenti per un unico grande report. Diventano lenti perché poche schermate sono usate tutto il giorno e quelle schermate eseguono molte piccole query ripetute.
I team operativi vivono di solito in una manciata di code di lavoro: ticket, ordini, utenti, approvazioni, richieste interne. Su queste pagine i filtri si ripetono:
Il lavoro del database dipende dall'intento:
I pannelli admin combinano anche i filtri in modi prevedibili: "Open + Unassigned", "Pending + Assigned to me" o "Completed negli ultimi 30 giorni". Gli indici funzionano meglio quando corrispondono a quelle forme di query reali, non solo a una lista di colonne.
Se costruisci strumenti admin in AppMaster, questi pattern sono spesso visibili guardando le schermate lista più usate e i loro filtri predefiniti. Questo rende più semplice indicizzare ciò che davvero guida il lavoro quotidiano, non quello che sembra buono sulla carta.
Tratta l'indicizzazione come triage. Non iniziare indicizzando ogni colonna che appare in un menu a tendina dei filtri. Parti dalle poche query che girano costantemente e che infastidiscono di più.
Ottimizzare un filtro che nessuno usa è tempo sprecato. Per trovare i veri percorsi caldi, combina segnali:
In molti team quella vista predefinita è qualcosa come "Open tickets" o "New orders". Si esegue ogni volta che qualcuno aggiorna, cambia tab o torna dopo una risposta.
Prima di aggiungere un indice, raggruppa le query comuni per come si comportano. La maggior parte delle query nelle liste admin rientra in pochi bucket:
status = 'open', assignee_id = 42created_at tra due dateORDER BY created_at DESC e prendi la pagina 2Annota la forma per ogni schermata principale, includendo WHERE, ORDER BY e paginazione. Due query che appaiono simili nell'interfaccia possono comportarsi molto diversamente nel database.
Inizia con un obiettivo prioritario: la query della lista predefinita che viene caricata per prima. Poi scegli altre 2 o 3 query ad alta frequenza. Di solito è sufficiente per tagliare i ritardi maggiori senza trasformare il database in un museo di indici.
Esempio: un team di support apre una lista Tickets filtrata su status = 'open', ordinata per newest, con assignee e intervallo di date opzionali. Ottimizza esattamente quella combinazione prima. Una volta veloce, passa alla schermata successiva in base all'uso.
Lo status è uno dei primi filtri che si aggiungono e uno dei più facili da indicizzare in modo che però non aiuti molto.
La maggior parte dei campi status ha bassa cardinalità: pochi valori (open, pending, closed). Un indice aiuta quando può ridurre i risultati a una fetta piccola della tabella. Se l'80–95% delle righe condivide lo stesso status, un indice solo su status spesso non cambia molto: il database deve comunque leggere gran parte delle righe e l'indice aggiunge overhead.
Di solito si sente il beneficio quando:
Un pattern comune è "mostrami elementi aperti, dal più recente". In questo caso indicizzare filtro e ordinamento insieme spesso è meglio che indicizzare status da solo.
Le combinazioni che di solito pagano prima:
status + updated_at (filtra per status, ordina per cambiamenti recenti)status + assignee_id (viste delle code di lavoro)status + updated_at + assignee_id (solo se quella vista esatta è molto usata)Gli indici parziali sono un buon compromesso quando uno status domina. Se "open" è la vista principale, indicizza solo le righe open. L'indice resta più piccolo e il costo sulle scritture rimane più basso.
-- PostgreSQL example: index only open rows, optimized for newest-first lists
CREATE INDEX CONCURRENTLY tickets_open_updated_idx
ON tickets (updated_at DESC)
WHERE status = 'open';
Un test pratico: esegui la query admin lenta con e senza il filtro di status. Se è lenta in entrambi i casi, un indice solo su status non la salverà. Concentrati sull'ordinamento e sul secondo filtro che riduce davvero la lista.
Nella maggior parte dei pannelli admin, assignee è un ID utente memorizzato sul record: una foreign key come assignee_id. È un classico filtro di uguaglianza e spesso un guadagno rapido con un indice semplice.
L'assignee compare anche insieme ad altri filtri perché rispecchia il modo di lavorare. Un lead può filtrare "Assigned to Alex" e poi restringere a "Open" per vedere cosa resta da gestire. Se questa vista è lenta, spesso serve più di un indice a colonna singola.
Un buon punto di partenza è un indice composito che corrisponda alla combo comune:
(assignee_id, status) per "i miei elementi aperti"(assignee_id, status, updated_at) se la lista è anche ordinata per attività recenteL'ordine conta negli indici compositi. Metti prima i filtri di uguaglianza (spesso assignee_id, poi status) e metti l'ordinamento o la colonna di range per ultima (updated_at). Questo si allinea con ciò che il database può usare in modo efficiente.
Gli elementi non assegnati sono un punto dolente comune. Molti sistemi rappresentano "unassigned" come NULL in assignee_id e i manager filtrano spesso per questo. A seconda del database e della forma della query, i NULL possono cambiare il piano a tal punto che un indice che funziona bene per gli assegnati sembra inutile per i non assegnati.
Se "unassigned" è parte del flusso, scegli un approccio chiaro e testalo:
assignee_id nullable, ma assicurati che WHERE assignee_id IS NULL sia testato e indicizzato se necessario.Se costruisci un pannello admin in AppMaster, aiuta registrare i filtri e gli ordinamenti esatti che il tuo team usa di più e poi rispecchiare quei pattern con un piccolo set di indici ben scelti invece di indicizzare ogni campo disponibile.
I filtri sulle date appaiono spesso come preset veloci tipo "ultimi 7 giorni" o "ultimi 30 giorni", più un selettore personalizzato con data di inizio e fine. Sembrano semplici, ma su tabelle grandi possono causare lavori molto diversi al database.
Prima di tutto, chiarisci quale colonna timestamp la gente intende effettivamente. Usa:
created_at per le viste "nuovi elementi"updated_at per le viste "modifiche recenti"Metti un indice btree su quella colonna. Senza di esso, ogni clic su "ultimi 30 giorni" può trasformarsi in una scansione completa della tabella.
I preset spesso sono del tipo created_at >= now() - interval '30 days'. È una condizione di range e un indice su created_at può essere usato in modo efficiente. Se l'UI ordina anche per i più recenti, far corrispondere la direzione dell'ordinamento (per esempio created_at DESC in PostgreSQL) può aiutare sulle liste molto usate.
Quando gli intervalli si combinano con altri filtri (status, assignee), sii selettivo. Gli indici compositi sono ottimi quando la combo è comune; altrimenti aggiungono costo alle scritture senza benefici.
Regole pratiche:
(status, created_at) può aiutare.created_at ed evita troppi compositi.Fusi orari e confini causano molti bug di "record mancanti". Se gli utenti scelgono date (non orari), decidi come interpretare la data di fine. Un pattern sicuro è start inclusivo ed end esclusivo: created_at >= start e created_at < end_next_day. Conserva i timestamp in UTC e converti l'input dell'utente in UTC prima di fare la query.
Esempio: un admin sceglie dal 10 gen al 12 gen e si aspetta di vedere anche tutto il 12 gen. Se la query usa <= '2026-01-12 00:00' perderai quasi tutti i record del 12 gen. L'indice va bene, ma la logica dei confini è sbagliata.
La ricerca testuale è dove molti pannelli admin rallentano, perché la gente si aspetta una singola casella che trovi tutto. La prima distinzione da fare è tra ricerca esatta (veloce e prevedibile) e ricerca contains (flessibile ma più pesante).
Ricerca esatta: campi come order ID, ticket number, email, telefono o un riferimento esterno. Sono perfetti per indici normali. Se gli admin incollano spesso un ID o un'email, un semplice indice più una query di uguaglianza può rendere tutto istantaneo.
Contains search: quando qualcuno digita un frammento come "refund" o "john" e si aspetta risultati in nomi, note e descrizioni. Spesso implementata come LIKE %term%. Il wildcard iniziale impedisce a un indice btree di restringere la ricerca, quindi il database esegue molte scansioni.
Un modo pratico per far funzionare la ricerca senza sovraccaricare il database:
term%), un indice standard può aiutare e spesso è sufficiente per i nomi.LIKE %term%.Le regole di input contano più di quanto molti team pensino. Riduzione del carico e risultati più coerenti:
Esempio pratico: un manager cerca "ann" per trovare un cliente. Se il sistema esegue LIKE %ann% su note, nomi e indirizzi, può scansionare migliaia di record. Se prima controlli campi esatti (email o customer ID) e poi ricorri a un indice testuale più intelligente solo se serve, la ricerca resta veloce.
Gli indici sono facili da aggiungere e facili da rimpiangere. Un flusso sicuro ti mantiene concentrato sui filtri su cui gli admin fanno affidamento e ti aiuta a evitare indici "magari utili" che rallentano le scritture.
Inizia dall'uso reale. Estrai le query top in due modi:
Per i pannelli admin sono di solito le pagine lista con filtri e ordinamento.
Poi cattura la forma esatta della query come la vede il database. Annota il WHERE e l'ORDER BY precisi, inclusa la direzione di ordinamento e le combinazioni comuni (per esempio: status = 'open' AND assignee_id = 42 ORDER BY created_at DESC). Piccole differenze possono cambiare quale indice aiuta.
Usa un ciclo semplice:
La paginazione merita un controllo a parte. La paginazione basata su offset (OFFSET 20000) spesso peggiora andando più in profondità, anche con indici. Se gli utenti arrivano spesso a pagine molto profonde, considera la paginazione basata su cursore ("show items before this timestamp/id") così l'indice può lavorare in modo consistente su tabelle grandi.
Infine, tieni un piccolo registro così la lista di indici resta comprensibile mesi dopo: nome indice, tabella, colonne (e ordine) e la query che supporta.
Il modo più rapido per far sembrare lento un pannello admin è aggiungere indici senza controllare come le persone filtrano, ordinano e paginano. Gli indici costano spazio e aggiungono lavoro a ogni insert e update.
Questi pattern causano la maggior parte dei problemi:
LIKE '%term%'.Uno scenario comune: un team filtra ticket con Status = Open, ordina per updated time e scorre i risultati. Se aggiungi solo un indice su status, il database potrebbe comunque dover raccogliere tutti i ticket aperti e ordinarli. Un indice che rispecchia filtro e ordinamento insieme può restituire la pagina 1 rapidamente.
Prima e dopo cambi nell'UI admin, fai una breve revisione:
WHERE + ORDER BY.LIKE '%term%') e decidi se la ricerca contains è davvero necessaria.Se costruisci pannelli admin in AppMaster su PostgreSQL, rendi questa revisione parte del rilascio di nuove schermate. Gli indici giusti tendono a derivare direttamente dai filtri e dagli ordinamenti che la tua UI usa realmente.
Prima di aggiungere altri indici, verifica che quelli esistenti aiutino le esatte combinazioni di filtri che la gente usa ogni giorno. Un buon pannello admin sembra istantaneo sui percorsi comuni, non sulle ricerche rare.
Alcuni controlli catturano la maggior parte dei problemi:
WHERE sia ORDER BY, non solo una parte.Un passo pratico: scrivi i tuoi percorsi d'oro in frasi semplici, per esempio: "Gli agenti support filtrano ticket aperti, assegnati a me, ultimi 7 giorni, ordinati per i più recenti." Usa queste frasi per progettare un piccolo set di indici che le supporti chiaramente.
Se sei ancora alle prime fasi, aiuta modellare i dati e i filtri predefiniti prima di creare troppe schermate. Con AppMaster (appmaster.io) puoi iterare velocemente sulle viste admin e poi aggiungere i pochi indici che rispecchiano i percorsi caldi una volta che l'uso reale li rende evidenti.
Inizia con le query che vengono eseguite costantemente: la vista predefinita che gli amministratori vedono per prima, più le 2–3 filtrazioni che usano tutto il giorno. Misura frequenza e impatto (le query più lente e più usate), poi indicizza solo ciò che riduce chiaramente i tempi di attesa su quelle esatte forme di query.
Perché diversi filtri richiedono quantità diverse di lavoro: alcuni riducono a un piccolo sottoinsieme di righe, altri devono leggere o ordinare un intervallo molto ampio. Una query può usare bene un indice mentre un'altra finisce per eseguire scansioni e ordinamenti su molti dati.
Non sempre. Se la maggior parte delle righe ha lo stesso valore di status, un indice solo su status spesso non riduce molto il lavoro. Conviene quando lo status è raro, o quando si indicizza status insieme all'ordinamento o a un altro filtro che restringe davvero i risultati.
Usa un indice composito che rispecchi ciò che le persone fanno, ad esempio filtrare per status e ordinare per attività recente. In PostgreSQL un indice parziale può essere una soluzione pulita quando uno status domina, perché mantiene l'indice piccolo e focalizzato sul flusso di lavoro comune.
Un semplice indice su assignee_id è spesso un buon punto di partenza, perché è un filtro di uguaglianza. Se “my open items” è un flusso di lavoro centrale, un indice composito che inizia con assignee_id e include status (e opzionalmente la colonna di ordinamento) di solito funziona meglio di indici su singole colonne.
Il valore NULL si comporta diversamente da un valore esplicito come 123. WHERE assignee_id IS NULL può portare a un piano diverso rispetto a WHERE assignee_id = 123. Se le code "unassigned" sono importanti, testa quella query e valuta un indice mirato (ad esempio un indice parziale) per le righe non assegnate, se il database lo supporta.
Aggiungi un indice btree sulla colonna timestamp che la gente filtra davvero: di solito created_at per le "nuove voci" e updated_at per le "modifiche recenti". Se poi ordini per i più recenti, un indice che rispecchia la direzione di ordinamento può aiutare, ma limita i compositi alle poche combinazioni veramente usate.
La maggior parte degli errori viene dai confini delle date, non dagli indici. Un buon approccio è includere l'inizio e escludere la fine: converti le date selezionate dall'utente in UTC e usa >= start e < end_next_day, così non perdi i record che ricadono nell'ultimo giorno della finestra.
Perché una ricerca con wildcard all'inizio come LIKE %term% non può usare efficacemente un indice btree e quindi richiede spesso una scansione. Considera le ricerche esatte (ID, email, numero ordine) come percorso veloce, e aggiungi la ricerca "contains" solo quando serve, usando strumenti adeguati come il full-text search PostgreSQL o gli indici trigram.
Troppe index aumentano lo spazio su disco e rallentano insert e update, e potresti comunque non risolvere il vero collo di bottiglia se l'indice non rispecchia il pattern WHERE + ORDER BY. Un ciclo più sicuro: cambia un indice alla volta, misura la stessa query lenta prima e dopo, e conserva solo le modifiche che migliorano in modo chiaro il percorso caldo.
Se costruisci schermate admin con AppMaster, registra i filtri e gli ordinamenti più usati dal tuo team e aggiungi solo pochi indici che rispecchiano quelle viste reali invece di indicizzare ogni campo disponibile.



Sperimenta con AppMaster con un piano gratuito.
Quando sarai pronto potrai scegliere l'abbonamento appropriato.


