App per la prenotazione delle attrezzature: evita i conflitti e monitora le restituzioni
Progetta un'app per la prenotazione delle attrezzature che eviti le doppie prenotazioni, registri restituzioni e danni e metta in manutenzione i beni difettosi.
Impara a risolvere i problemi delle integrazioni webhook standardizzando le firme, gestendo i ritentativi in sicurezza, abilitando il replay e mantenendo log degli eventi facilmente ricercabili.
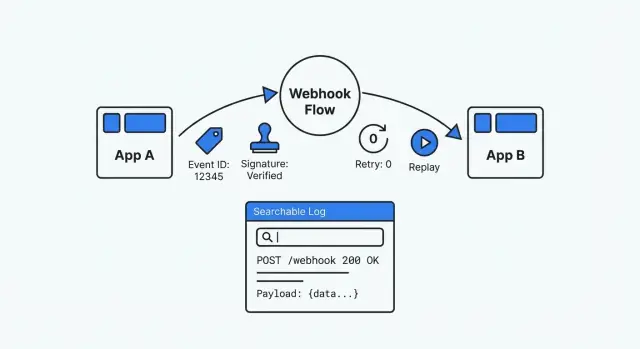
Un webhook è semplicemente un'app che chiama la tua app quando succede qualcosa. Un provider di pagamenti ti dice “payment succeeded”, uno strumento di form dice “new submission”, o un CRM segnala “deal updated”. Sembra semplice finché qualcosa non si rompe e ti rendi conto che non c'è uno schermo da aprire, nessuna cronologia ovvia e nessun modo sicuro per riprodurre quanto è successo.
Per questo i problemi webhook sono così frustranti. La richiesta arriva (o non arriva). Il tuo sistema la elabora (o fallisce). Il primo segnale è spesso un ticket vago come “i clienti non riescono a pagare” o “lo stato non si è aggiornato”. Se il provider ritenta, potresti ricevere duplicati. Se cambiano campi nel payload, il tuo parser può rompersi solo per alcuni account.
Sintomi comuni:
Una configurazione webhook debuggabile è l'opposto del lavorare a tentoni. È tracciabile (puoi trovare ogni consegna e cosa ne hai fatto), ripetibile (puoi riprodurre in sicurezza un evento passato) e verificabile (puoi dimostrare autenticità e risultati di elaborazione). Quando qualcuno chiede “cosa è successo a questo evento?”, dovresti poter rispondere con evidenze in pochi minuti.
Se costruisci app su una piattaforma come AppMaster, questo approccio conta ancora di più. La logica visuale cambia rapidamente, ma hai comunque bisogno di una cronologia chiara degli eventi e di un replay sicuro così che i sistemi esterni non diventino una scatola nera.
Quando stai facendo debugging sotto pressione, hai bisogno delle stesse basi ogni volta: un registro di cui ti puoi fidare, che puoi cercare e riprodurre. Senza quello, ogni webhook diventa un mistero isolato.
Decidi cosa significa un singolo “evento” webhook nel tuo sistema. Trattalo come una ricevuta: una richiesta in entrata = un evento memorizzato, anche se l'elaborazione avviene dopo.
Al minimo, memorizza:
received_at separato dai timestamp all'interno del payload.Esempio: un provider di pagamenti invia “payment_succeeded” ma il cliente risulta ancora non pagato. Se il tuo log eventi include la richiesta grezza, puoi confermare la firma e vedere l'importo e la valuta esatti. Se include anche invoice_id, il supporto può trovare l'evento dall'invoice, vedere che è bloccato in “failed” e passare a ingegneria una ragione d'errore chiara.
In AppMaster, un approccio pratico è una tabella “WebhookEvent” nel Data Designer, con un Business Process che aggiorna lo stato man mano che ogni passo si completa. Lo strumento non è il punto. Il punto è il record coerente.
Se ogni provider invia un payload con forma diversa, i tuoi log saranno sempre disordinati. Un envelope stabile per l'evento rende il debugging più veloce perché puoi cercare sempre gli stessi campi, anche quando i dati cambiano.
Un envelope utile tipicamente include:
id (id evento univoco)type (nome chiaro dell'evento come invoice.paid)created_at (quando è avvenuto l'evento, non quando lo hai ricevuto)data (il payload di business)version (es. v1)Ecco un semplice esempio che puoi loggare e memorizzare così com'è:
{
"id": "evt_01H...",
"type": "payment.failed",
"created_at": "2026-01-25T10:12:30Z",
"version": "v1",
"correlation": {"order_id": "A-10492", "customer_id": "C-883"},
"data": {"amount": 4990, "currency": "USD", "reason": "insufficient_funds"}
}
Scegli uno stile di naming (snake_case o camelCase) e mantienilo. Sii rigoroso anche sui tipi: non fare amount stringa a volte e numero altre volte.
Il versioning è la tua rete di sicurezza. Quando devi cambiare campi, pubblica v2 mantenendo v1 funzionante per un po'. Previene incidenti di supporto e rende gli upgrade molto più facili da debuggare.
Le firme impediscono che il tuo endpoint webhook diventi una porta aperta. Senza verifica, chiunque conosca l'URL può inviare eventi falsi e gli attaccanti possono cercare di manomettere richieste reali.
Lo schema più comune è una firma HMAC con un segreto condiviso. Il mittente firma il body grezzo della richiesta (meglio) o una stringa canonica. Tu ricalcoli l'HMAC e confronti. Molti provider includono un timestamp in ciò che firmano così le richieste catturate non possono essere riprodotte in seguito.
Una routine di verifica dovrebbe essere noiosa e coerente:
Rendila testabile. Metti la verifica in una funzione piccola e scrivi test con campioni noti "buoni" e "cattivi". Uno spreco di tempo comune è firmare il JSON parsato invece dei byte grezzi.
Pianifica la rotazione dei segreti fin dal giorno zero. Supporta due segreti attivi durante la transizione: prova il più recente prima, poi ricadere su quello precedente.
Quando la verifica fallisce, logga abbastanza informazioni per fare debugging senza esporre segreti: nome del provider, timestamp (e se era troppo vecchio), versione della firma, request/correlation ID e un breve hash del body grezzo (non il body stesso).
I ritentativi sono normali. I provider ritentano su timeout, problemi di rete o risposte 5xx. Anche se il tuo sistema ha fatto il lavoro, il provider potrebbe non aver ricevuto la tua risposta in tempo, quindi lo stesso evento può arrivare di nuovo.
Decidi in anticipo cosa significa “retry” vs “stop”. Molti team usano regole come:
L'idempotenza significa poter gestire lo stesso evento più volte senza ripetere effetti collaterali (ad es. addebitare due volte, creare ordini duplicati, inviare due email). Tratta i webhook come consegna at-least-once.
Un pattern pratico è memorizzare l'ID univoco di ogni evento in entrata con l'esito dell'elaborazione. Su consegna ripetuta:
Per i retry interni, usa backoff esponenziale e limita i tentativi. Dopo il limite, sposta l'evento in uno stato “needs review” con l'ultimo errore. In AppMaster, questo si mappa bene a una piccola tabella per event ID e stati, più un Business Process che pianifica i retry e instrada i fallimenti ripetuti.
I retry sono automatici. Il replay è intenzionale.
Uno strumento di replay trasforma “pensiamo che l'abbiano inviato” in un test ripetibile con lo stesso payload esatto. È sicuro solo quando sono vere due cose: idempotenza e audit trail. L'idempotenza evita ricarichi doppi, spedizioni doppi o email doppie. L'audit trail mostra cosa è stato riprodotto, da chi e cosa è successo.
Il replay di singoli eventi è il caso d'uso comune del supporto: un cliente, un evento fallito, reinviarlo dopo una correzione. Il replay per intervalli è per gli incidenti: un outage del provider in una finestra specifica e devi reinviare tutto ciò che è fallito.
Mantieni la selezione semplice: filtra per tipo evento, intervallo temporale e stato (failed, timed out, o delivered ma non confermato), poi riproduci un singolo evento o un batch.
Il replay dovrebbe essere potente ma non pericoloso. Alcuni guardrail utili:
Dopo il replay, mostra i risultati accanto all'evento originale: successo, ancora in errore (con l'ultimo errore) o ignorato (duplicate rilevato via idempotenza).
Quando un webhook si rompe durante un incidente, hai bisogno di risposte in minuti. Un buon log racconta una storia chiara: cosa è arrivato, cosa hai fatto e dove si è fermato.
Memorizza la richiesta grezza esattamente come ricevuta: timestamp, path, method, headers e body grezzo. Quel payload grezzo è la tua fonte di verità quando i vendor cambiano campi o il tuo parser legge male i dati. Maschera i valori sensibili prima di salvare (authorization header, token e qualsiasi dato personale o di pagamento che non ti serve).
I dati grezzi non bastano. Memorizza anche una vista parsata e ricercabile: tipo evento, external event ID, identificatori customer/account, ID oggetto correlati (invoice_id, order_id) e il tuo correlation ID interno. Questo permette al supporto di trovare “tutti gli eventi per il cliente 8142” senza aprire ogni payload.
Durante l'elaborazione, conserva una breve timeline dei passaggi con wording coerente, per esempio: “validated signature”, “mapped fields”, “checked idempotency”, “updated records”, “queued follow-ups”.
La retention conta. Tieni abbastanza storia per coprire ritardi reali e dispute, ma non accumulare indefinitamente. Considera di cancellare o anonimizzare prima i payload grezzi mantenendo metadati leggeri più a lungo.
Costruisci il ricevitore come una piccola pipeline con checkpoint chiari. Ogni richiesta diventa un evento memorizzato, ogni esecuzione di elaborazione diventa un tentativo, e ogni errore diventa ricercabile.
Tratta l'endpoint HTTP solo come intake. Fai il lavoro minimo subito, poi sposta l'elaborazione su un worker così i timeout non si trasformano in comportamenti misteriosi.
In pratica, vorrai due record core: una riga per evento webhook e una riga per ogni tentativo di elaborazione.
Un modello evento solido include: event_id, provider, received_at, signature_status, payload_hash, payload_json (o payload grezzo), current_status, last_error, next_retry_at. I record dei tentativi possono contenere: attempt_number, started_at, finished_at, http_status (se applicabile), error_code, error_text.
Una volta che i dati esistono, aggiungi una piccola pagina admin così il supporto può cercare per event ID, customer ID o intervallo temporale e filtrare per stato. Mantienila noiosa e veloce.
Imposta alert su pattern, non su singoli fallimenti. Per esempio: “provider failed 10 times in 5 minutes” o “evento bloccato in failed”.
Se controlli il lato invio, standardizza tre cose: includi sempre un event ID, firma sempre il payload nello stesso modo e pubblica una policy di retry in linguaggio chiaro. Previene lunghe discussioni quando un partner dice “l'abbiamo inviato” e il tuo sistema non mostra nulla.
Un pattern comune è un webhook Stripe che fa due cose: crea un record Order e poi invia una ricevuta via email/SMS. Sembra semplice finché un evento fallisce e nessuno sa se il cliente è stato addebitato, se l'ordine esiste o se la ricevuta è stata inviata.
Ecco un guasto realistico: ruoti il segreto di firma di Stripe. Per alcuni minuti il tuo endpoint verifica ancora con il vecchio segreto, così Stripe invia eventi ma il tuo server li rifiuta con 401/400. La dashboard mostra “webhook failed”, mentre i log della tua app dicono solo “invalid signature”.
Buoni log rendono la causa ovvia. Per l'evento fallito, il record dovrebbe mostrare un event ID stabile più abbastanza dettagli di verifica per individuare la discrepanza: versione della firma, timestamp della firma, risultato della verifica e un chiaro motivo del rifiuto (segreto sbagliato vs drift del timestamp). Durante la rotazione, aiuta anche loggare quale segreto è stato tentato (per esempio “current” vs “previous”), non il segreto grezzo.
Una volta che il segreto è corretto e sia “current” che “previous” sono accettati per una finestra breve, devi comunque gestire l'arretrato. Uno strumento di replay trasforma quello in un'attività rapida:
La maggior parte dei problemi webhook sembra misteriosa perché i sistemi registrano solo l'errore finale. Tratta ogni consegna come un piccolo rapporto d'incidente: cosa è arrivato, cosa hai deciso e cosa è successo dopo.
Alcuni errori ricorrenti:
Fix pratici:
Se usi AppMaster, questi pezzi si inseriscono naturalmente nella piattaforma: una tabella eventi nel Data Designer, un Business Process guidato dallo stato per verifica ed elaborazione e un'interfaccia admin per ricerca e replay.
Punta sempre a queste basi:
Mancare anche solo uno di questi può trasformare ancora un'integrazione in una scatola nera. Se non memorizzi il payload grezzo, non puoi dimostrare cosa ha inviato il provider. Se i fallimenti di firma non sono specifici, sprecherai ore a discutere di chi ha torto.
Se vuoi costruire questo rapidamente senza scrivere a mano ogni componente, AppMaster (appmaster.io) può aiutarti ad assemblare il modello dati, i flussi di elaborazione e l'interfaccia admin in un unico posto, generando comunque codice sorgente reale per l'app finale.



Sperimenta con AppMaster con un piano gratuito.
Quando sarai pronto potrai scegliere l'abbonamento appropriato.


