App per la prenotazione delle attrezzature: evita i conflitti e monitora le restituzioni
Progetta un'app per la prenotazione delle attrezzature che eviti le doppie prenotazioni, registri restituzioni e danni e metta in manutenzione i beni difettosi.
La cronologia delle modifiche a livello di campo in un pannello admin dovrebbe essere facile da scansionare, filtrare e ripristinare. Pattern di UX e schema per diff, eventi e azioni.
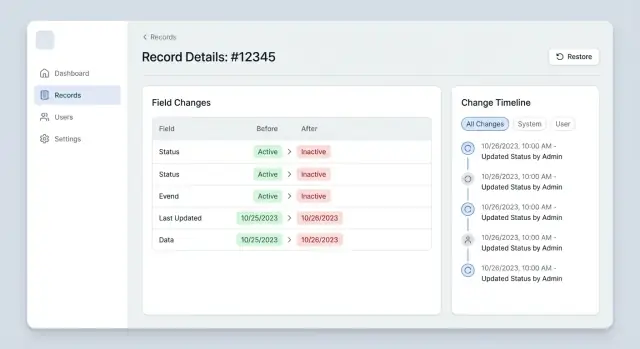
La maggior parte degli utenti admin non ignora la cronologia perché non gli importi: la ignorano perché richiede troppa attenzione per troppo poco rendimento. Quando un cliente è in attesa o un ordine è bloccato, nessuno ha tempo di leggere una lunga lista grigia di eventi "updated".
Una cronologia leggibile a livello di campo si guadagna il suo posto quando risponde alle domande che le persone si stanno già ponendo:
Molti log falliscono su almeno uno di questi punti. Il fallimento più comune è il rumore: ogni salvataggio crea 20 voci, job in background scrivono timestamp innocui ogni minuto e i processi di sistema somigliano alle azioni umane. I diff sono spesso vaghi. Vedi "status changed" ma non "Pending -> Approved", o ottieni un blob di JSON senza indizi su cosa guardare.
La mancanza di contesto completa il quadro. Non puoi capire quale workflow ha scatenato una modifica, se è stata manuale o automatica, o perché due campi sono cambiati insieme.
Il risultato è prevedibile. I team smettono di fidarsi del registro e ricorrono a ipotesi, chiedono in giro o rifanno il lavoro. Questo diventa pericoloso non appena aggiungi azioni di ripristino.
Una buona cronologia riduce i tempi di supporto, evita errori ripetuti e rende i ripristini sicuri perché gli utenti possono verificare prima e dopo rapidamente. Tratta l'interfaccia di audit come una feature primaria, non come una schermata di debug, e progettala per essere scansionata sotto pressione.
Una cronologia leggibile parte da una decisione: chi la userà quando qualcosa va storto. "Tutti" non è un ruolo. In molti pannelli admin, la stessa vista di audit è imposta a support, ops e manager, e finisce per servire nessuno.
Scegli i ruoli principali e cosa devono ottenere:
Definisci i task principali che la tua cronologia deve supportare:
Poi decidi cosa registrerai, e rendilo esplicito. Una cronologia solida a livello di campo include di solito modifiche di campo, transizioni di stato e azioni chiave di workflow (come "approved", "locked", "refunded"). Molti team includono anche upload e cancellazioni di file, cambi di permessi e aggiornamenti triggerati da integrazioni. Se non registri qualcosa, gli utenti presumono che il sistema lo stia nascondendo.
Infine, definisci le regole di ripristino da subito. Il ripristino dovrebbe essere permesso solo quando è sicuro e significativo. Ripristinare un indirizzo di spedizione può essere OK. Ripristinare uno stato "paid" potrebbe essere bloccato una volta che un pagamento è stato liquidato. Spiega il motivo del blocco nell'UI ("Ripristino disabilitato: rimborso già emesso").
Un breve scenario: un cliente sostiene che il suo piano è stato declassato senza autorizzazione. Il supporto ha bisogno di vedere se è stato un agente, il cliente o una regola di fatturazione automatica, e se è permesso il ripristino. Progetta intorno a quella storia e le decisioni UI diventano molto più semplici.
Se il tuo modello dati è disordinato, la cronologia lo sarà anche. L'interfaccia può essere chiara solo quanto lo sono i record dietro di essa.
Un modello a eventi memorizza solo ciò che è cambiato (campo, prima, dopo). Un modello a snapshot memorizza l'intero record dopo ogni modifica. Per i pannelli admin, spesso funziona meglio un ibrido: conserva gli eventi come fonte di verità e opzionalmente memorizza uno snapshot leggero per visualizzazioni veloci o ripristini.
Gli eventi rispondono a cosa è cambiato, chi l'ha fatto e quando. Gli snapshot aiutano quando gli utenti hanno bisogno di una rapida "state at time X" o quando devi ripristinare più campi insieme.
Mantieni ogni record di modifica piccolo, ma abbastanza completo da potersi spiegare in seguito. Un minimo pratico:
Per rispondere a "perché è successo?", aggiungi contesto opzionale. Un breve commento è spesso sufficiente, ma riferimenti strutturati sono migliori quando li hai: ticket_id, workflow_run_id, import_batch_id o una automated_reason come "nightly sync".
Le persone raramente pensano a singoli campi. Pensano "Ho aggiornato l'indirizzo del cliente" anche se sono cambiati cinque campi. Modella questo con un change_set_id che collega molti eventi di campo insieme.
Un pattern semplice:
Questo permette all'interfaccia di mostrare una voce leggibile per salvataggio, con un'opzione di espansione per vedere ogni diff di campo.
Una buona cronologia sta dove avviene la domanda: nella schermata di dettaglio del record. Una scheda "History" accanto a "Details" e "Notes" mantiene le persone nel contesto così possono confermare cosa è cambiato senza perdere il filo.
Una pagina di audit separata ha ancora senso. Usala quando il job richiede ricerche cross-record (ad esempio, "mostrami ogni cambio di prezzo fatto da Kim ieri") o quando gli auditor hanno bisogno di esportazioni. Per il lavoro quotidiano di supporto e ops, la cronologia a livello di record vince.
La vista predefinita dovrebbe rispondere a quattro domande in uno sguardo: cosa è cambiato, chi l'ha cambiato, quando è successo e se faceva parte di una modifica più ampia. Ordinare dal più recente è atteso, ma raggruppare per sessione di modifica è ciò che la rende leggibile: una voce per salvataggio, con i campi cambiati all'interno.
Per mantenere la scansione veloce, mostra solo ciò che è cambiato. Non ristampare l'intero record. Questo trasforma la cronologia in rumore e rende più difficile individuare le modifiche reali.
Una card evento compatta solitamente funziona bene:
Rendi "chi l'ha fatto" e "quando" visivamente evidenti, non nascosti. Usa allineamento coerente e un formato di timestamp uniforme.
Le persone aprono la cronologia quando qualcosa sembra sbagliato. Se il diff è difficile da scansionare, mollano e chiedono a un collega. I buoni diff rendono la modifica ovvia in un colpo d'occhio e dettagliata con un click.
Per la maggior parte dei campi, inline funziona meglio: mostra Prima -> Dopo su una riga, con solo la parte modificata evidenziata. Side-by-side è utile quando i valori sono lunghi (come indirizzi) o quando gli utenti devono confrontare più parti insieme, ma richiede spazio. Regola semplice: default inline, passa a side-by-side solo quando l'andamento delle righe nasconde la differenza.
I testi lunghi richiedono cura. Mostrare un intero paragrafo in una lista densa rende tutto rumore. Mostra un estratto breve (primi 120–200 caratteri) e un controllo Expand che rivela il valore completo. Quando espandi, conserva i ritorni a capo. Usa font a larghezza fissa solo per contenuti veramente simili a codice e evidenzia solo i frammenti modificati così l'occhio ha un punto di riferimento.
Numeri, valute e date spesso sembrano "invariati" anche quando non lo sono. Quando conta, mostra sia il valore raw sia il formato rivolto all'utente. Per esempio, "10000" -> "10,000.00 USD" può essere un cambiamento reale (precisione e valuta), non solo presentazione.
Enum e status sono un'altra trappola. Le persone riconoscono le etichette, i sistemi si affidano ai codici interni. Mostra prima l'etichetta e l'eventuale valore interno solo quando il supporto o la compliance lo richiedono.
La maggior parte delle persone apre la cronologia solo quando qualcosa va storto. Se la prima schermata mostra 300 piccole modifiche, la chiudono. I buoni filtri fanno due cose: tagliano il rumore rapidamente e tengono la verità completa a portata di un click.
Inizia con un set piccolo e prevedibile di filtri:
I default contano più dei controlli sofisticati. Un buon default è "Campi importanti" e "Ultimi 7 giorni", con un'opzione chiara per espandere a "Tutti i campi" e intervalli più lunghi. Un toggle semplice "Mostra rumore" funziona bene per cose come last_seen_at, piccole modifiche di formattazione o totali ricalcolati. L'obiettivo non è nascondere i fatti, ma tenerli fuori dalla vista finché servono.
La ricerca dentro la cronologia è spesso il modo più veloce per confermare un sospetto. Rendila indulgente: permetti match parziali, ignora le maiuscole e cerca su nome campo, nome attore e valori mostrati. Se qualcuno digita "refund", dovrebbe vedere note, cambi di stato e aggiornamenti di pagamento senza indovinare dove si trovano.
Le viste filtro salvate aiutano nelle indagini ripetute. I team di supporto eseguono gli stessi controlli su ogni ticket. Mantieni poche viste e amichevoli per ruolo (per esempio, "Solo campi a contatto col cliente" o "Modifiche da automazioni").
Un pulsante di ripristino è utile solo se la gente si fida. Il ripristino dovrebbe sembrare una modifica attenta e visibile, non un rollback magico.
Mostra il ripristino dove l'intento è chiaro. Per campi semplici (status, plan, assignee), un ripristino per campo va bene perché l'utente capisce esattamente cosa cambierà. Per modifiche multi-campo (blocco indirizzo, set di permessi, dettagli di fatturazione), preferisci il ripristino dell'intero change set, o offri "ripristina tutto da questa modifica" accanto ai ripristini individuali. Questo evita ripristini parziali che creano combinazioni strane.
Rendi l'impatto esplicito prima di agire. Una buona conferma di ripristino nomina il record, il campo e i valori esatti, e mostra cosa sarà toccato.
I conflitti sono dove la fiducia si rompe, quindi gestiscili con calma. Se il campo è cambiato di nuovo dopo l'evento che stai ripristinando, non sovrascrivere a occhi chiusi.
Quando il valore corrente è diverso dall'"after" dell'evento, mostra una breve vista comparativa: "Stai tentando di ripristinare a X, ma il valore corrente è Y." Poi offrire azioni come ripristina comunque, copia il valore vecchio o annulla. Se si adatta al tuo workflow, includi una casella motivo così il ripristino ha contesto.
Non cancellare mai la cronologia ripristinando. Registra il ripristino come un nuovo evento con chiara attribuzione: chi ha ripristinato, quando e da quale evento proviene.
Puoi costruire una cronologia di cui le persone si fidano se prendi poche decisioni in anticipo e le mantieni coerenti su UI, API e automazioni.
Prima di rilasciare, testa uno scenario realistico: un agente di supporto apre un ordine, filtra i campi di pricing, vede un singolo salvataggio che ha cambiato subtotal, discount e tax, poi ripristina solo il discount. Se quel flow è chiaro senza spiegazioni, la tua cronologia verrà usata.
La maggior parte delle viste di cronologia fallisce per una ragione semplice: non rispettano l'attenzione. Se il log è rumoroso o confuso, le persone smettono di usarlo e tornano alle supposizioni.
Una trappola comune è loggare troppo. Se registri ogni battitura, ogni tick di sincronizzazione o ogni auto-aggiornamento, il segnale scompare. Il personale non riesce a trovare la singola modifica che contava. Registra commit significativi: "Status changed", "Address updated", "Limit increased", non "User typed A, then B".
Registrare troppo poco è altrettanto dannoso. Una vista di cronologia senza attore, senza timestamp, senza motivo o senza valore prima non è cronologia. È una voce di pettegolezzo.
Le etichette possono rompere la fiducia silenziosamente. Nomi di database grezzi (come cust_id), ID interni o valori enum criptici costringono il personale non tecnico a interpretare il sistema invece dell'evento. Usa etichette umane ("Cliente", "Piano", "Indirizzo di spedizione") e mostra nomi amichevoli insieme agli ID solo quando serve.
Errori che spesso uccidono l'usabilità:
Le azioni di ripristino sono l'area a più alto rischio. Un undo one-click sembra veloce finché non rompe qualcos'altro (pagamenti, permessi, inventario). Fai sentire i ripristini sicuri:
Una buona vista di cronologia è quella che il tuo team di supporto può usare mentre il cliente è ancora in linea. Se ci vogliono più di pochi secondi per rispondere a "cosa è cambiato, quando e da chi?", la gente smette di aprirla.
Un modo pratico per validare è un breve esercizio di "disputa di supporto". Scegli un record con molte modifiche e chiedi a un collega: "Perché il cliente vede un indirizzo di spedizione diverso da ieri?" Se può filtrare per Address, vedere il diff prima/dopo e identificare l'attore in meno di 10 secondi, sei vicino.
Un cliente apre un ticket: "Il totale della mia fattura è cambiato dopo che ho applicato uno sconto. Sono stato addebitato di più." Qui la cronologia a livello di campo fa risparmiare tempo, ma solo se è leggibile e azionabile.
Nel record della fattura, l'agente di supporto apre la scheda History e prima riduce il rumore. Filtra agli ultimi 7 giorni e seleziona i campi Discount e Total. Poi filtra per attore per mostrare solo le modifiche fatte da un utente interno (non il cliente o un'automazione).
La timeline ora mostra tre voci chiare:
La storia è ovvia: lo sconto è stato rimosso e il totale è stato ricalcolato subito dopo. L'agente può confermare se la rimozione era corretta controllando il commento e le regole promo.
Se è stato un errore, l'agente usa un flusso di ripristino sicuro sul campo Discount. L'UI anteprima cosa cambierà (Discount di nuovo al 10%, Total ricalcolato) e chiede una nota.
Se stai costruendo un pannello admin con una piattaforma no-code come AppMaster (appmaster.io), puoi modellare le tabelle di audit in PostgreSQL, centralizzare le scritture di audit nei Business Processes e riusare gli stessi pattern di UI della cronologia su web e mobile così la storia resta consistente ovunque il tuo team lavori.
La maggior parte delle persone lo ignora perché è difficile da scansionare ed è pieno di rumore a basso valore. Fai in modo che ogni voce risponda subito a quattro cose: chi l'ha fatto, cosa è cambiato con valori prima/dopo, quando è successo in un formato coerente, e perché o da quale fonte è avvenuto.
Registra commit significativi, non ogni piccola modifica. Traccia le modifiche ai campi, le transizioni di stato e le azioni di workflow chiave, e indica chiaramente se l'attore era una persona, un'automazione, un'importazione o una chiamata API in modo che il rumore di sistema non sembri comportamento umano.
Inizia con un modello a eventi che memorizza solo ciò che è cambiato, poi aggiungi opzionalmente snapshot leggeri se ti servono visualizzazioni rapide dello “stato al tempo X” o ripristini di massa. Un ibrido funziona spesso meglio: eventi per la verità e la leggibilità, snapshot per le prestazioni e i casi di ripristino multi-campo.
Un minimo pratico è l'identità e il tipo dell'attore, il timestamp in UTC, il tipo di entità e l'ID, una chiave di campo stabile e i valori prima/dopo con il tipo di dato. Aggiungi contesto opzionale come un commento, workflow_run_id, import_batch_id o una ragione automatica così il “perché” potrà essere risposto in seguito.
Usa un change set ID per raggruppare tutte le modifiche di campo di uno stesso salvataggio o esecuzione di workflow. Così l'interfaccia può mostrare una voce leggibile come “Modificati 5 campi” con una vista espandibile, invece di inondare la timeline con 20 righe separate.
Di default mostra inline prima -> dopo su una sola riga, e passa a side-by-side solo quando l'andamento delle righe nasconde la differenza significativa. Per testi lunghi mostra un estratto breve per default e un'espansione su richiesta, preservando i ritorni a capo in modo che resti leggibile.
Conserva i timestamp in UTC e scegli un formato unico; poi visualizza nell'area timezone dell'utente quando serve. Se i team lavorano in fusi orari diversi, mostra l'etichetta del fuso accanto all'orario così il “quando” è inequivocabile durante le chiamate di supporto.
Inizia con un piccolo set che corrisponde a domande reali: intervallo di tempo, attore, campo, tipo di modifica e fonte (manuale vs automazione/import/API). Imposta un default sensato come “ultimi 7 giorni” più “campi importanti”, e rendi ovvio come rivelare tutto quando serve.
Tratta il ripristino come una nuova modifica visibile con permessi stringenti e un'anteprima chiara di cosa cambierà. Se il valore corrente è diverso dall'"after" dell'evento che stai ripristinando, mostra il conflitto in modo trasparente e richiedi una scelta deliberata così non sovrascrivi lavori più recenti senza volerlo.
Centralizza le scritture di audit in un unico punto così le modifiche da UI, API e job non sincroni vengono registrate nello stesso modo. In AppMaster puoi modellare le tabelle di audit in PostgreSQL, scrivere eventi di audit dai Business Processes e riusare gli stessi pattern di UI della cronologia su web e mobile per mantenere la storia consistente.



Sperimenta con AppMaster con un piano gratuito.
Quando sarai pronto potrai scegliere l'abbonamento appropriato.


