App per la prenotazione delle attrezzature: evita i conflitti e monitora le restituzioni
Progetta un'app per la prenotazione delle attrezzature che eviti le doppie prenotazioni, registri restituzioni e danni e metta in manutenzione i beni difettosi.
Scopri come progettare policy di retention per app business con finestre chiare, strategie di archiviazione e flussi di eliminazione o anonimizzazione che mantengono i report utili.
Una policy di retention è un insieme chiaro di regole che la tua app segue sui dati: cosa conservi, per quanto tempo, dove risiede e cosa succede quando scade il tempo. Lo scopo non è “eliminare tutto”. È conservare ciò che serve per gestire l’attività e spiegare eventi passati, rimuovendo ciò che non serve più.
Senza un piano, emergono tre problemi velocemente. Lo storage cresce silenziosamente finché non inizia a costare davvero. Il rischio per la privacy e la sicurezza aumenta con ogni copia aggiuntiva di dati personali. E i report diventano inaffidabili quando i record vecchi non corrispondono alla logica attuale, o quando le persone cancellano elementi in modo ad hoc e le dashboard cambiano all’improvviso.
Una policy pratica bilancia operatività quotidiana, evidenza e protezione del cliente:
La maggior parte delle app business ha le stesse aree di dati, anche con nomi diversi: profili utente, transazioni, log di audit, messaggi e file caricati.
Una policy è in parte regole, in parte workflow, in parte strumenti. La regola può dire: “conserva i ticket di supporto per 2 anni.” Il workflow definisce cosa significa in pratica: spostare i ticket più vecchi in un’area di archivio, anonimizzare i campi cliente e registrare cosa è successo. Gli strumenti rendono tutto ripetibile e verificabile.
Se costruisci la tua app su AppMaster, tratta la retention come comportamento del prodotto, non come una pulizia occasionale. I Business Processes schedulati possono archiviare, eliminare o anonimizzare i dati nello stesso modo ogni volta, così i report restano coerenti e le persone si fidano dei numeri.
Prima di impostare le date, chiarisci perché stai conservando i dati. Le decisioni di retention sono spesso dettate da leggi sulla privacy, contratti con i clienti e regole di audit o fiscali. Saltare questo passaggio ti porta o a conservare troppo (più rischi e costi) o a cancellare qualcosa che ti servirà poi.
Inizia separando il “da conservare per forza” dal “bello da avere”. I dati da conservare per forza spesso includono fatture, registrazioni contabili e log di audit necessari per dimostrare chi ha fatto cosa e quando. I dati “bello da avere” possono essere vecchie trascrizioni di chat, cronologie di click dettagliate o log di eventi raw usati solo occasionalmente per analisi.
I requisiti variano anche per paese e settore. Un portale di supporto per un fornitore sanitario ha vincoli molto diversi rispetto a uno strumento admin B2B. Anche all’interno di un’unica azienda, utenti in più paesi possono significare regole diverse per lo stesso tipo di record.
Scrivi le decisioni in linguaggio semplice e assegna un responsabile. “Conserviamo i ticket per 24 mesi” non basta. Definisci cosa è incluso, cosa è escluso e cosa succede alla fine della finestra (archiviare, anonimizzare, eliminare). Metti una persona o un team responsabile così gli aggiornamenti non si bloccano quando prodotti o leggi cambiano.
Ottieni approvazioni in anticipo, prima che l’ingegneria costruisca qualcosa. Legal conferma i minimi e gli obblighi di cancellazione. Security valuta il rischio, i controlli di accesso e il logging. Product conferma ciò che gli utenti devono ancora vedere. Finance conferma le esigenze di conservazione dei registri.
Esempio: puoi conservare i documenti di fatturazione per 7 anni, mantenere i ticket per 2 anni e anonimizzare i campi del profilo utente dopo la chiusura dell’account mantenendo però metriche aggregate. In AppMaster, quelle regole scritte si mappano chiaramente a processi schedulati e controlli di accesso basati su ruoli, con meno ambiguità in seguito.
Le policy di retention falliscono quando i team decidono “conserva per 2 anni” senza sapere cosa include “ciò”. Costruisci una mappa semplice dei dati che hai. Non puntare alla perfezione. Punta a qualcosa che un responsabile support e un responsabile finance possano entrambi capire.
Un set pratico di partenza:
Poi marca la sensibilità in termini semplici: dati personali (nome, email), finanziari (dati bancari, token di pagamento), credenziali (hash delle password, chiavi API) o dati regolamentati (ad esempio informazioni sanitarie). Se non sei sicuro, etichettalo come “potenzialmente sensibile” e trattalo con attenzione fino a conferma.
“Dove risiede” è spesso più della sola database principale. Nota la posizione esatta: tabelle del database, storage file, log email/SMS, strumenti di analytics o data warehouse. Nota anche chi si affida a ciascun dataset (support, vendite, finanza, leadership) e con quale frequenza. Questo ti dice cosa si romperà se cancelli troppo aggressivamente.
Un’abitudine utile: documenta lo scopo di ogni dataset in una frase. Esempio: “I ticket di supporto sono conservati per risolvere dispute e tracciare trend di tempi di risposta.”
Se costruisci con AppMaster, puoi allineare questo inventario a ciò che è effettivamente distribuito rivedendo i modelli in Data Designer, la gestione dei file e le integrazioni abilitate.
Una volta che la mappa esiste, la retention diventa una serie di scelte piccole e chiare invece di un grande azzardo.
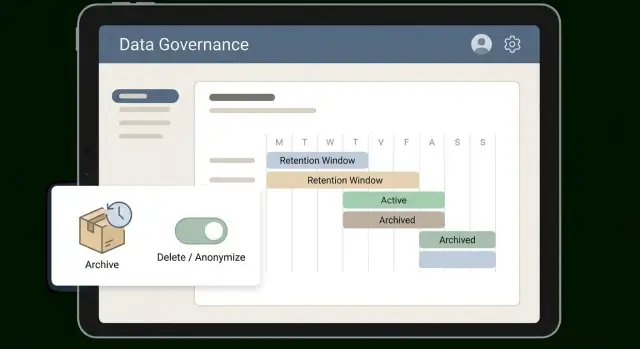
Una finestra funziona solo se è facile da spiegare e ancora più facile da applicare. Molti team si trovano bene con tier semplici che corrispondono a come i dati sono usati: hot (usati quotidianamente), warm (usati di tanto in tanto), cold (conservati come prova), poi cancellati o anonimizzati. I tier trasformano una policy astratta in una routine.
Imposta finestre per categoria, non un numero globale unico. Le fatture e i record di pagamento di solito richiedono un lungo periodo cold per tasse e audit. Le trascrizioni di supporto perdono valore rapidamente.
Decidi anche cosa fa scattare il conteggio. “Conserva per 2 anni” è privo di senso a meno che tu non definisca “2 anni da quando”. Scegli un trigger per categoria, come data di creazione, ultima attività del cliente, data di chiusura del ticket o chiusura dell’account. Se i trigger variano senza regole chiare, le persone indovineranno e la retention deriverà.
Scrivi le eccezioni in anticipo così i team non improvvisano dopo. Le eccezioni comuni includono legal hold, chargeback e indagini per frode. Queste dovrebbero mettere in pausa la cancellazione. Non dovrebbero portare a copie nascoste.
Mantieni le regole finali corte e verificabili:
legal_hold=true: non eliminare finché non viene rimossoUn archivio non è un backup. I backup servono per il recupero dopo errori o outage. Gli archivi sono deliberati: dati più vecchi lasciano le tue tabelle hot e vanno in storage più economico, ma restano disponibili per audit, dispute e domande storiche.
La maggior parte delle app ha bisogno di entrambi. I backup sono frequenti e ampi. Gli archivi sono selettivi e controllati, e normalmente recuperi solo ciò che ti serve.
Lo storage più economico aiuta solo se le persone riescono ancora a trovare ciò che serve. Molti team usano un database o uno schema separato ottimizzato per query di sola lettura, o esportano in file con una tabella indice per il lookup. Se la tua app è basata su PostgreSQL (incluso in AppMaster), uno schema “archive” o un database separato può mantenere le tabelle di produzione veloci permettendo comunque reporting autorizzato su dati archiviati.
Prima di scegliere il formato, definisci cosa significa “ricercabile” per il tuo business. Il support potrebbe aver bisogno di lookup via email o ticket ID. Finance potrebbe avere bisogno di totali per mese. Gli audit potrebbero richiedere una traccia per order ID.
I record completi preservano il dettaglio, ma costano di più e aumentano il rischio per la privacy. I sommari (totali mensili, conteggi, principali cambi di stato) sono più economici e spesso sufficienti per il reporting.
Un approccio pratico:
Pianifica i campi indice da subito. Alcuni comuni includono ID primario, user/customer ID, bucket di data (mese), regione e stato. Senza questi, i dati archiviati esistono ma sono difficili da recuperare.
Definisci anche le regole di restore: chi può richiederlo, chi approva, dove vengono ripristinati i dati e i tempi previsti. Il ripristino può essere intenzionalmente lento se questo riduce il rischio, ma deve essere prevedibile.
Le policy di retention spesso impongono una scelta: eliminare i record o conservarli rimuovendo i dettagli personali. Entrambi possono essere giusti, ma risolvono problemi diversi.
Una hard delete rimuove fisicamente il record. È adatta quando non hai ragioni legali o di business per conservare i dati e il mantenerli crea rischio (ad esempio vecchie trascrizioni di chat con dettagli sensibili).
Un soft delete mantiene la riga ma la marca come eliminata (spesso con un timestamp deleted_at) e la nasconde dalle schermate e dalle API normali. Il soft delete è utile quando gli utenti si aspettano di poter ripristinare, o quando sistemi downstream potrebbero ancora fare riferimento al record. Lo svantaggio è che i dati soft-delete esistono ancora, consumano storage e possono fuoriuscire tramite esportazioni se non sei attento.
L'anonimizzazione conserva l’evento o la transazione ma rimuove o sostituisce tutto ciò che identifica una persona. Fatto correttamente, non è reversibile. La pseudonimizzazione è diversa: sostituisci identificatori (come email) con un token ma mantieni una mappatura separata che permette la re-identificazione. Questo aiuta per indagini antifrode, ma non è equivalente all’essere anonimi.
Sii esplicito sui dati correlati, perché qui le policy spesso si rompono. Eliminare un record ma lasciare allegati, miniature, cache, indici di ricerca o copie in analytics può vanificare l’intero scopo.
Hai anche bisogno di una prova che l’eliminazione sia avvenuta. Conserva una semplice ricevuta di eliminazione: cosa è stato rimosso o anonimizzato, quando è stato eseguito, quale workflow l’ha eseguito e se è andato a buon fine. In AppMaster, questo può essere un Business Process che scrive una voce di audit al termine del job.
I report si rompono quando elimini o anonimizzi record su cui le dashboard fanno join nel tempo. Prima di cambiare qualcosa, scrivi quali numeri devono rimanere confrontabili mese su mese. Altrimenti ti ritroverai a debuggare “perché il grafico dello scorso anno è cambiato?” dopo l’operazione.
Inizia con una lista breve di metriche che devono restare accurate:
Poi riprogetta cosa conservi per il reporting in modo che non richieda identificatori personali. L’approccio più sicuro è l’aggregazione. Invece di tenere ogni riga raw per sempre, conserva totali giornalieri, coorti settimanali e conteggi che non possono essere ricondotti a una persona. Per esempio, puoi mantenere “ticket creati al giorno per categoria” e “tempo medio di prima risposta per settimana” anche se poi rimuovi i contenuti originali dei ticket.
Alcuni report necessitano ancora di un modo stabile per raggruppare comportamenti nel tempo. Usa una chiave analitica surrogata che non sia direttamente identificabile (per esempio, un UUID casuale usato solo per analytics) e rimuovi o blocca qualsiasi mappatura verso il vero user ID quando la finestra di retention scade.
Se puoi, separa le tabelle operative da quelle di reporting. I dati operativi cambiano e vengono cancellati. Le tabelle di reporting dovrebbero essere snapshot append-only o aggregati.
L’anonimizzazione ha conseguenze. Documenta cosa cambierà così i team non restino sorpresi:
Se costruisci in AppMaster, tratta l’anonimizzazione come un workflow: scrivi prima gli aggregati, verifica i risultati dei report, poi anonimizza i campi nelle sorgenti.
Una policy di retention funziona solo quando diventa comportamento software normale. Trattala come qualsiasi altra feature: definisci input, azioni e rendi i risultati visibili.
Inizia con una matrice su una pagina. Per ogni tipo di dato, registra la finestra di retention, il trigger e cosa succede dopo (conservare, archiviare, eliminare, anonimizzare). Se le persone non riescono a spiegarla in un minuto, non sarà seguita.
Aggiungi stati di ciclo di vita chiari così i record non spariscono “misteriosamente”. La maggior parte delle app può cavarsela con tre stati: active, archived e pending delete. Conserva lo stato sul record stesso, non solo su un foglio di calcolo.
Sequenza pratica di implementazione:
archived_at e delete_after) e aggiorna schermate e API per rispettarli.Esempio: i ticket di supporto possono restare attivi per 90 giorni, poi passare in archivio per 18 mesi, infine essere anonimizzati. Il workflow marca i ticket come archiviati, sposta allegati pesanti in storage più economico, conserva ID e timestamp dei ticket e sostituisce nomi ed email con valori anonimi.
In AppMaster, gli stati di ciclo di vita possono vivere in Data Designer e la logica di archivio/purge può essere eseguita da Business Processes schedulati. L’obiettivo è esecuzioni ripetute con log chiari facili da auditare.
La maggior parte dei fallimenti nella retention non riguarda la finestra scelta. Succede quando la cancellazione tocca le tabelle sbagliate, ignora file correlati o modifica chiavi di cui i report dipendono.
Uno scenario comune: il team di support cancella “ticket vecchi” ma dimentica gli allegati memorizzati in una tabella separata o in uno storage file. Più tardi, un auditor chiede prove dietro a un rimborso. Il testo del ticket esiste, ma gli screenshot sono andati.
Altri tranelli comuni:
user_id) senza aggiornare dashboard, join e query salvateUn altro break frequente riguarda report costruiti su chiavi persona-based. Sovrascrivere email e nome è spesso accettabile. Sostituire l’ID interno può dividere silenziosamente la storia di una persona in identità multiple, e metriche come monthly active users o lifetime value deriveranno.
Due correzioni aiutano la maggior parte dei team. Prima, definisci chiavi di reporting che non cambino mai (per esempio un account ID interno) e tienile separate dai campi personali che verranno anonimizzati o eliminati. Secondo, implementa l’eliminazione come workflow completo che attraversa tutti i dati correlati, inclusi file e log. In AppMaster, questo spesso si mappa a un Business Process che parte da un user o account, raccoglie dipendenze e poi elimina o anonimizza in ordine sicuro.
Infine, decidi chi può mettere in pausa le cancellazioni per legal hold e come viene registrata quella pausa. Se nessuno si occupa delle eccezioni, la policy verrà applicata in modo incoerente.
Prima di eseguire job di cancellazione o archiviazione, fai un reality check. La maggior parte dei fallimenti avviene perché nessuno sa chi possiede i dati, dove sono memorizzate le copie o come i report dipendono da esse.
Una policy di retention ha bisogno di responsabilità chiare e di un piano verificabile, non solo di un documento.
Una convalida semplice è una dry run: prendi un piccolo batch (per esempio i casi vecchi di un cliente), esegui il workflow in un ambiente di test, poi confronta i report chiave prima e dopo.
Conserva prove in modo che non reintrodurre dati personali:
Se costruisci su AppMaster, questi controlli si mappano direttamente all’implementazione: campi di retention in Data Designer, job schedulati nel Business Process Editor e output di audit chiari.
Immagina un portale clienti che memorizza ticket di supporto, fatture e rimborsi, e log di attività raw (login, page view, chiamate API). L’obiettivo è ridurre rischio e costi di storage senza rompere fatturazione, audit o report di trend.
Inizia separando i dati che devi conservare da quelli usati solo per support quotidiano.
Un programma di retention semplice potrebbe essere:
Aggiungi uno step di archivio per i ticket più vecchi. Invece di tenere ogni messaggio per sempre nelle tabelle principali, sposta i ticket chiusi più vecchi di 18 mesi in un’area di archivio con un piccolo sommario ricercabile: ticket ID, date, area prodotto, tag, codice di risoluzione ed un breve estratto dell’ultima nota agente. Questo mantiene il contesto senza conservare tutti i dettagli personali.
Per account chiusi, scegli l’anonimizzazione piuttosto che l’eliminazione quando ti servono ancora trend. Sostituisci identificatori personali (nome, email, indirizzo) con token casuali, ma conserva campi non identificativi come tipo di piano e totali mensili. Conserva metriche di utilizzo aggregate (daily active user counts, ticket per mese, revenue per mese) in una tabella di reporting separata che non memorizza dati personali.
I report mensili cambieranno, ma non dovrebbero peggiorare se pianifichi:
In AppMaster, i passaggi di archivio e anonimizzazione possono essere eseguiti come Business Processes schedulati, così la policy si esegue nello stesso modo ogni volta.
Una policy di retention funziona quando le persone la seguono e il sistema la applica in modo coerente. Inizia con una matrice di retention semplice: ogni dataset, owner, finestra, trigger, azione successiva (archiviare, eliminare, anonimizzare) e firma. Rivedila con legale, security, finanza e il team che gestisce i ticket clienti.
Non automatizzare tutto in una volta. Scegli un dataset end-to-end, idealmente qualcosa di comune come i ticket di supporto o i log di accesso. Rendi reale il workflow, eseguilo per una settimana e conferma che i report corrispondono a quanto l’azienda si aspetta. Poi estendi al dataset successivo riutilizzando lo stesso pattern.
Mantieni l’automazione osservabile. Il monitoraggio base di solito copre:
Pianifica anche l’aspetto rivolto agli utenti. Decidi cosa gli utenti possono richiedere (esportazione, cancellazione, correzione), chi approva e cosa fa il sistema. Fornisci al support uno script interno breve: quali dati sono coinvolti, quanto tempo ci vuole e cosa non si può recuperare dopo l’eliminazione.
Se vuoi implementare tutto senza scrivere codice personalizzato, AppMaster (appmaster.io) è adatto all’automazione della retention perché puoi modellare campi di ciclo di vita in Data Designer ed eseguire Business Processes schedulati per archivio e anonimizzazione con logging di audit. Parti da un dataset, rendilo noioso e affidabile, poi ripeti il pattern sul resto dell’app.
Una policy di retention evita la crescita incontrollata dei dati e l’abitudine pericolosa del “tieni tutto”. Imposta regole prevedibili su cosa conservare, per quanto e cosa succede alla scadenza, così costi, rischi per la privacy e sorprese nei report non aumentano col tempo.
Parti dal motivo per cui i dati esistono e da chi li usa: operazioni, audit/tasse e protezione del cliente. Scegli finestre semplici per categoria (fatture, ticket, log, file) e ottieni approvazione anticipata da legale, security, finanza e prodotto così non costruisci flussi che poi dovranno essere rifatti.
Definisci un unico trigger chiaro per ogni categoria, ad esempio la data di chiusura del ticket, l’ultima attività o la chiusura dell’account. Se il trigger è vago, team diversi lo interpreteranno in modo diverso e la retention deriverà, finendo per significare cinque cose diverse per la stessa frase.
Usa un flag o uno stato di legal hold che metta in pausa l’archiviazione/anonimizzazione/eliminazione per record specifici, e rendi la sospensione visibile e tracciabile. L’obiettivo è fermare il workflow normale senza creare copie nascoste che nessuno può spiegare dopo.
Un backup serve per il disaster recovery e per recuperare da errori: è ampio e frequente. Un archivio è una scelta deliberata: sposti dati vecchi fuori dalle tabelle hot verso storage più economico ma controllato, ancora recuperabile per audit e dispute.
Elimina quando non hai più alcuna ragione legale o di business per conservare i dati e il mantenerli rappresenta un rischio. Anonimizza quando devi conservare l’evento o la transazione per trend o prove, ma puoi rimuovere definitivamente i campi personali in modo che non siano più collegabili a una persona.
Il soft delete è utile per il ripristino o per evitare riferimenti rotti, ma non è una rimozione reale. Le righe soft-delete occupano ancora spazio e possono fuoriuscire in esportazioni, analytics o viste amministrative a meno che ogni query e processo non le filtri costantemente.
Proteggi i report memorizzando metriche a lungo termine come aggregati o snapshot che non dipendono da identificatori personali. Se i cruscotti fanno join su campi che prevedi di sovrascrivere (come email), ridisegna prima il modello di reporting così i grafici storici non cambiano dopo le operazioni di retention.
Tratta la retention come una funzionalità di prodotto: campi di ciclo di vita sui record, job schedulati per archiviare e poi pulire/anonimizzare, e voci di audit che provano cosa è successo. In AppMaster, questo si mappa a campi in Data Designer e Business Processes schedulati che eseguono sempre nello stesso modo.
Esegui una piccola dry run in ambiente di test o su una copia simile alla produzione e confronta i totali chiave prima e dopo. Assicurati anche di poter tracciare un record in ogni luogo in cui esiste (tabelle, storage file, esportazioni, log) e di catturare una ricevuta di eliminazione/anonimizzazione con timestamp, nome della regola e conteggi.



Sperimenta con AppMaster con un piano gratuito.
Quando sarai pronto potrai scegliere l'abbonamento appropriato.


