App per la prenotazione delle attrezzature: evita i conflitti e monitora le restituzioni
Progetta un'app per la prenotazione delle attrezzature che eviti le doppie prenotazioni, registri restituzioni e danni e metta in manutenzione i beni difettosi.
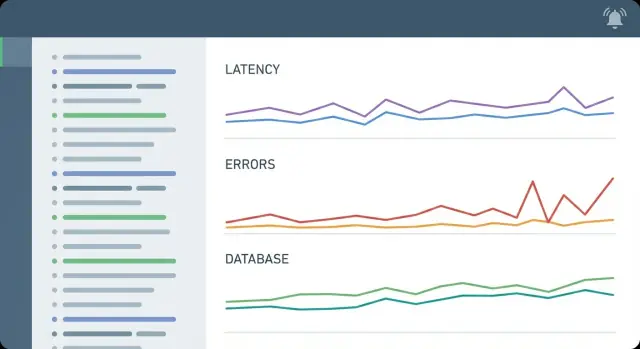
Configurazione minima di osservabilità per backend pesantemente CRUD: log strutturati, metriche essenziali e avvisi pratici per rilevare presto query lente, errori e disservizi.
request_id, utente, endpoint e errore.\n- Alcune metriche core: tasso di richieste, tasso di errori, latenza e tempo sul database.\n- Avvisi legati all'impatto utente (picchi di errori o risposte lente sostenute), non ogni warning interno.\n\nAiuta anche separare i sintomi dalle cause. Un sintomo è ciò che gli utenti percepiscono: 500, timeout, pagine lente. Una causa è ciò che lo crea: contesa di lock, pool di connessioni saturo o una query lenta dopo che è stato aggiunto un nuovo filtro. Avvisa sui sintomi e usa i segnali di “causa” per indagare.\n\nUna regola pratica: scegli un unico posto per vedere i segnali importanti. Passare da uno strumento di log a uno di metriche e a una casella di allarmi separata ti rallenta quando conta di più.\n\n## Log strutturati che restano leggibili sotto pressione\n\nQuando qualcosa si rompe, la via più rapida per una risposta è di solito: “Quale richiesta esatta ha fatto questo utente?” Per questo un ID di correlazione stabile conta più di quasi ogni altra modifica ai log.\n\nScegli un nome di campo (comunemente request_id) e trattalo come obbligatorio. Generalo al bordo (API gateway o primo handler), passalo nelle chiamate interne e includilo in ogni riga di log. Per i job in background, crea un nuovo request_id per ogni esecuzione del job e conserva un parent_request_id quando un job è stato attivato da una chiamata API.\n\nLogga in JSON, non in testo libero. Mantiene i log ricercabili e coerenti quando sei stanco, stressato e stai scorrendo.\n\nUn set semplice di campi è sufficiente per la maggior parte dei servizi API CRUD:\n\n- timestamp, level, service, env\n- request_id, route, method, status\n- duration_ms, db_query_count\n- tenant_id o account_id (identificatori sicuri, non dati personali)\n\nI log dovrebbero aiutarti a restringere “quale cliente e quale schermata”, senza trasformarsi in una fuga di dati. Evita nomi, email, numeri di telefono, indirizzi, token o corpi di richiesta completi per default. Se ti serve più dettaglio, registralo solo su richiesta e con redazione.\n\nDue campi pagano rapidamente nei sistemi CRUD: duration_ms e db_query_count. Catturano handler lenti e pattern N+1 accidentali anche prima di aggiungere il tracing.\n\nDefinisci i livelli di log così tutti li usano nello stesso modo:\n\n- info: eventi attesi (richiesta completata, job avviato)\n- warn: insolito ma recuperabile (richiesta lenta, retry riuscito)\n- error: richiesta o job fallito (eccezione, timeout, dipendenza guasta)\n\nSe costruisci backend con una piattaforma come AppMaster, mantieni gli stessi nomi di campo tra i servizi generati così “cerca per request_id” funziona ovunque.\n\n## Metriche chiave che contano per backend CRUD e API\n\nLa maggior parte degli incidenti in app CRUD ha una forma familiare: uno o due endpoint rallentano, il database si satura e gli utenti vedono spinner o timeout. Le tue metriche dovrebbero rendere quella storia ovvia in pochi minuti.\n\nUn set minimo copre di solito cinque aree:\n\n- Traffico: richieste al secondo (per route o almeno per servizio) e tasso di richieste per classe di status (2xx, 4xx, 5xx)\n- Errori: tasso di 5xx, conteggio timeout e una metrica separata per “errori di business” restituiti come 4xx (così non svegli le persone per errori dell'utente)\n- Latenza (percentili): p50 per l'esperienza tipica e p95 (a volte p99) per rilevare che “qualcosa non va”\n- Saturazione: CPU e memoria, più saturazione specifica dell'app (utilizzo worker, pressione di thread/goroutine se esposta)\n- Pressione sul database: p95 del tempo query, connessioni in uso vs max del pool e tempo di attesa per i lock (o conteggi di query in attesa di lock)\n\nDue dettagli rendono le metriche molto più azionabili.\n\nPrimo, separa le richieste API interattive dal lavoro in background. Un invio email lento o un loop di retry webhook possono consumare CPU, connessioni DB o rete in uscita e far sembrare l'API “lenta a caso”. Monitora code, retry e durata dei job come serie temporali a sé stanti, anche se girano nello stesso backend.\n\nSecondo, allega sempre metadata di versione/build a dashboard e avvisi. Quando deployi un nuovo backend generato (per esempio dopo aver rigenerato codice da uno strumento no-code come AppMaster), vuoi rispondere rapidamente a una domanda: il tasso di errori o la latenza p95 è aumentata subito dopo questa release?\n\nUna regola semplice: se una metrica non può dirti cosa fare dopo (rollback, scalare, fixare una query o fermare un job), non appartiene al tuo set minimo.\n\n## Segnali del database: la causa abituale del dolore CRUD\n\nNelle app CRUD, il database è spesso il luogo dove “sembra lento” diventa dolore reale per l'utente. Una configurazione minima dovrebbe rendere ovvio quando il collo di bottiglia è PostgreSQL (non il codice API) e che tipo di problema DB è.\n\n### Cosa misurare per primo in PostgreSQL\n\nNon hai bisogno di decine di dashboard. Inizia con segnali che spiegano la maggior parte degli incidenti:\n\n- Tasso di query lente e tempo query p95/p99 (più le query lente principali)\n- Attese per lock e deadlock (chi blocca chi)\n- Utilizzo delle connessioni (connessioni attive vs limite del pool, connessioni fallite)\n- Pressione su disco e I/O (latenza, saturazione, spazio libero)\n- Lag di replica (se usi read replica)\n\n### Separare il tempo dell'app dal tempo DB\n\nAggiungi un istogramma dei tempi delle query nel layer API e taggalo con l'endpoint o il caso d'uso (per esempio: GET /customers, “search orders”, “update ticket status”). Questo mostra se un endpoint è lento perché esegue molte query piccole o una sola grande.\n\n### Individuare presto i pattern N+1\n\nLe schermate CRUD spesso scatenano N+1: una query per la lista e poi una query per ogni riga per prendere dati correlati. Osserva gli endpoint dove il numero di richieste rimane stabile ma il conteggio di query DB per richiesta aumenta. Se generi backend da modelli e logica business, qui è spesso dove si ottimizza il pattern di fetch.\n\nSe hai già una cache, monitora il tasso di hit. Non aggiungere una cache solo per avere grafici migliori.\n\nTratta i cambiamenti di schema e le migrazioni come una finestra di rischio. Registra quando iniziano e finiscono, poi osserva picchi in lock, tempo query ed errori di connessione durante quella finestra.\n\n## Avvisi che svegliano la persona giusta per il motivo giusto\n\nGli avvisi dovrebbero puntare a un problema reale per l'utente, non a un grafico rumoroso. Per le app CRUD, inizia monitorando ciò che gli utenti percepiscono: errori e lentezza.\n\nSe aggiungi solo tre avvisi all'inizio, rendili:\n\n- aumento del tasso di 5xx\n- latenza p95 sostenuta\n- calo improvviso delle richieste riuscite\n\nDopo, aggiungi un paio di avvisi “probabile causa”. I backend CRUD spesso falliscono in modi prevedibili: il database esaurisce le connessioni, una coda in background si accumula o un singolo endpoint inizia a scadere e trascina giù tutta l'API.\n\n### Soglie: baseline + margine, non congetture\n\nHardcodare numeri tipo “p95 > 200ms” raramente funziona in tutti gli ambienti. Misura una settimana normale, poi imposta l'avviso poco sopra la norma con un margine di sicurezza. Per esempio, se p95 è solitamente 350–450 ms durante l'orario lavorativo, avvisa a 700 ms per 10 minuti. Se 5xx è tipicamente 0.1–0.3%, manda pagina a 2% per 5 minuti.\n\nMantieni le soglie stabili. Non ritoccarle ogni giorno. Modificale dopo un incidente, quando puoi collegare il cambiamento a un risultato reale.\n\n### Paging vs ticket: decidilo prima che serva\n\nUsa due severità così le persone si fidano del segnale:\n\n- Pagina quando gli utenti sono bloccati o i dati sono a rischio (alto tasso di 5xx, timeout API, pool di connessioni DB vicino all'esaurimento).\n- Crea un ticket quando è degradazione ma non urgente (lentezza graduale in p95, backlog della coda che cresce, uso disco in aumento).\n\nSilenzia gli avvisi durante cambi previsti come finestre di deploy e manutenzioni programmate.\n\nRendi gli avvisi azionabili. Includi “cosa controllare prima” (endpoint principale, connessioni DB, deploy recente) e “cosa è cambiato” (nuova release, aggiornamento schema). Se usi AppMaster, nota quale backend o modulo è stato rigenerato e deployato più di recente, perché spesso è la pista più rapida.\n\n## SLO semplici per app business (e come modellano gli avvisi)\n\nUna configurazione minima diventa più facile quando decidi cosa significa “sufficientemente buono”. Questo è lo scopo degli SLO: obiettivi chiari che trasformano il monitoraggio vago in avvisi specifici.\n\nInizia con SLI che mappano a ciò che gli utenti percepiscono: disponibilità (gli utenti possono completare le richieste), latenza (quanto sono veloci le azioni) e tasso di errori (quanto spesso le richieste falliscono).\n\nImposta gli SLO per gruppi di endpoint, non per route. Per app CRUD, raggruppare mantiene le cose leggibili: letture (GET/list/search), scritture (create/update/delete) e auth (login/refresh token). Eviti centinaia di piccoli SLO che nessuno mantiene.\n\nEsempi di SLO che si adattano a aspettative tipiche:\n\n- App CRUD interna (portale admin): 99.5% di disponibilità al mese, 95% delle richieste di lettura sotto 800 ms, 95% delle scritture sotto 1.5 s, tasso di errori sotto 0.5%.\n- API pubblica: 99.9% di disponibilità al mese, 99% delle letture sotto 400 ms, 99% delle scritture sotto 800 ms, tasso di errori sotto 0.1%.\n\nI budget di errore sono il tempo “cattivo” permesso entro lo SLO. Uno SLO di disponibilità 99.9% mensile significa che puoi avere circa 43 minuti di downtime al mese. Se li consumi presto, sospendi cambi rischiosi finché la stabilità non ritorna.\n\nUsa gli SLO per decidere cosa merita un avviso contro cosa è solo una tendenza in dashboard. Avvisa quando stai bruciando il budget di errore velocemente (gli utenti stanno effettivamente fallendo), non quando una metrica è solo un po' peggiore di ieri.\n\nSe generi backend velocemente (per esempio con AppMaster che genera un servizio Go), gli SLO mantengono il focus sull'impatto utente anche se l'implementazione cambia sotto il cofano.\n\n## Passo dopo passo: costruire una configurazione minima in un giorno\n\nInizia con la fetta del sistema che gli utenti toccano di più. Scegli le chiamate API e i job che, se lenti o rotti, fanno sembrare l'intera app giù.\n\nAnnota i tuoi endpoint e i lavori in background principali. Per un'app CRUD business, di solito sono login, list/search, create/update e un job di export o import. Se hai costruito il backend con AppMaster, includi gli endpoint generati e i Business Process che girano su schedule o webhook.\n\n### Un piano da un giorno\n\n- Ora 1: Scegli i tuoi 5 endpoint principali e 1–2 job in background. Annota cosa significa “bene”: latenza tipica, tasso di errori atteso, tempo DB normale.\n- Ore 2–3: Aggiungi log strutturati con campi coerenti: request_id, user_id (se disponibile), endpoint, status_code, latency_ms, db_time_ms e un breve error_code per errori noti.\n- Ore 3–4: Aggiungi le metriche core: richieste al secondo, latenza p95, tasso 4xx, tasso 5xx e tempi DB (durata query e saturazione pool di connessioni se disponibili).\n- Ore 4–6: Costruisci tre dashboard: una overview (salute a colpo d'occhio), una vista dettagliata API (breakdown per endpoint) e una vista database (query lente, lock, uso connessioni).\n- Ore 6–8: Aggiungi gli avvisi, provoca un guasto controllato e conferma che l'avviso è azionabile.\n\nMantieni pochi avvisi e focalizzati. Vuoi avvisi che puntino all'impatto utente, non a “qualcosa è cambiato”.\n\n### Avvisi da cui partire (5–8 totali)\n\nUn set iniziale solido è: p95 API troppo alta, tasso 5xx sostenuto, picco improvviso di 4xx (spesso auth o cambi di validazione), fallimenti di job in background, query DB lente, connessioni DB vicine al limite e poco spazio su disco (se self-hosted).\n\nPoi scrivi un mini runbook per ogni avviso. Una pagina basta: cosa controllare prima (pannelli dashboard e campi log chiave), cause probabili (lock DB, indice mancante, query lenta downstream) e la prima azione sicura (riavviare un worker bloccato, fare rollback, mettere in pausa un job pesante).\n\n## Errori comuni che rendono il monitoraggio rumoroso o inutile\n\nIl modo più rapido per sprecare una configurazione minima è trattare il monitoring come una casella da spuntare. Le app CRUD falliscono in alcuni modi prevedibili (call DB lente, timeout, release problematiche), quindi i tuoi segnali dovrebbero rimanere focalizzati su quelli.\n\nL'errore più comune è la fatica da alert: troppi avvisi, poche azioni. Se svegli le persone per ogni picco, dopo due settimane non si fideranno più degli avvisi. Una buona regola: un avviso dovrebbe indicare una probabile soluzione, non solo “qualcosa è cambiato”.\n\nUn altro errore classico è la mancanza di ID di correlazione. Se non riesci a collegare un log di errore, una richiesta lenta e una query DB a una sola richiesta, perdi ore. Assicurati che ogni richiesta abbia un request_id (e includilo nei log, nei trace se li hai, e nelle risposte quando è sicuro).\n\n### Cosa crea di solito rumore\n\nI sistemi rumorosi tendono a condividere gli stessi problemi:\n\n- Un avviso miscela 4xx e 5xx, così errori client e server sembrano identici.\n- Le metriche tracciano solo medie, nascondendo la latenza della coda (p95 o p99) dove gli utenti soffrono.\n- I log includono per sbaglio dati sensibili (password, token, corpi di richiesta completi).\n- Gli avvisi scattano sui sintomi senza contesto (CPU alta) invece che sull'impatto utente (tasso di errori, latenza).\n- I deploy sono invisibili, quindi le regressioni sembrano guasti casuali.\n\nLe app CRUD sono particolarmente vulnerabili alla “trappola della media”. Una singola query lenta può rendere il 5% delle richieste dolorose mentre la media sembra ok. La latenza della coda più il tasso di errori danno un quadro più chiaro.\n\nAggiungi marker di deploy. Che tu spedisca da CI o rigeneri codice su una piattaforma come AppMaster, registra la versione e il tempo di deploy come evento e nei log.\n\n## Controlli rapidi: una checklist minima di osservabilità\n\nLa tua configurazione funziona quando puoi rispondere a poche domande velocemente, senza scavare nelle dashboard per 20 minuti. Se non riesci a rispondere rapidamente con sì/no, ti manca un segnale chiave o le tue viste sono troppo disperse.\n\n### Controlli veloci durante un incidente\n\nDovresti poter fare la maggior parte di questo in meno di un minuto:\n\n- Riesci a dire se gli utenti stanno fallendo ora (sì/no) da una singola vista errori (5xx, timeout, job falliti)?\n- Riesci a individuare il gruppo di endpoint più lento e la sua latenza p95, e vedere se sta peggiorando?\n- Riesci a separare il tempo app dal tempo DB per una richiesta (tempo handler, tempo query DB, chiamate esterne)?\n- Vedi se il database è vicino ai limiti di connessione o CPU e se le query stanno in coda?\n- Se un avviso è scattato, suggerisce una azione successiva (rollback, scalare, controllare connessioni DB, ispezionare un endpoint), non solo “latenza alta”?\n\nI log devono essere sicuri e utili allo stesso tempo. Devono avere abbastanza contesto per seguire una richiesta fallita attraverso i servizi, ma non devono perdere dati personali.\n\n### Controllo di sanità dei log\n\nScegli un fallimento recente e apri i suoi log. Conferma che hai request_id, endpoint, codice di stato, durata e un messaggio d'errore chiaro. Conferma anche di non loggare token grezzi, password, dati di pagamento completi o campi personali.\n\nSe costruisci backend CRUD con AppMaster, punta a una singola “vista incidente” che combini questi controlli: errori, latenza p95 per endpoint e salute DB. Questo copre la maggior parte dei blackout reali in app business.\n\n## Esempio: diagnosticare una schermata CRUD lenta con i segnali giusti\n\nUn portale admin interno va bene tutta la mattina, poi rallenta in modo evidente durante un'ora di punta. Gli utenti si lamentano che aprire la lista “Orders” e salvare modifiche richiede 10–20 secondi.\n\nSi parte dai segnali top-level. La dashboard API mostra p95 per gli endpoint di lettura schizzato da ~300 ms a 4–6 s, mentre il tasso di errori resta basso. Contemporaneamente, il pannello database mostra connessioni attive vicine al limite del pool e un aumento delle attese per lock. La CPU dei nodi backend è normale, quindi non sembra un problema di compute.\n\nPoi prendi una richiesta lenta e la segui nei log. Filtra per endpoint (per esempio GET /orders) e ordina per durata. Prendi un request_id da una richiesta di 6 secondi e cercalo in tutti i servizi. Vedi che l'handler è terminato rapidamente, ma la riga di log della query DB con lo stesso request_id mostra una query da 5.4 secondi con rows=50 e un grande lock_wait_ms.\n\nOra puoi indicare la causa con sicurezza: la lentezza è nel percorso database (query lenta o contesa di lock), non nella rete o nella CPU backend. Questo è ciò che una configurazione minimale ti compra: restringere la ricerca più velocemente.\n\nFix tipici, in ordine di sicurezza:\n\n- Aggiungere o regolare un indice per il filtro/ordinamento usato nella schermata di elenco.\n- Eliminare query N+1 ottenendo i dati correlati con una singola query o un join.\n- Sintonizzare il pool di connessioni per non soffocare il DB sotto carico.\n- Aggiungere caching solo per dati stabili e di sola lettura (e documentare le regole di invalidamento).\n\nChiudi il ciclo con un avviso mirato. Manda pagina solo quando la latenza p95 del gruppo di endpoint resta sopra la soglia per 10 minuti e l'utilizzo delle connessioni DB è oltre (per esempio) l'80%. Questa combinazione evita rumore e cattura il problema prima la prossima volta.\n\n## Prossimi passi: mantieni il setup minimale, poi migliora con incidenti reali\n\nUna configurazione minima di osservabilità dovrebbe essere noiosa il primo giorno. Se inizi con troppe dashboard e avvisi, le tarerai per sempre e comunque perderai i problemi reali.\n\nTratta ogni incidente come feedback. Dopo che la correzione è in produzione, chiedi: cosa avrebbe reso più veloce individuarlo e più semplice diagnosticarlo? Aggiungi solo quello.\n\nStandardizza presto, anche se oggi hai un solo servizio. Usa gli stessi nomi di campo nei log e gli stessi nomi di metrica ovunque così i nuovi servizi seguono il pattern senza discussioni. Rende anche le dashboard riutilizzabili.\n\nUna piccola disciplina di release paga rapidamente:\n\n- Aggiungi un marker di deploy (versione, environment, commit/build ID) così puoi vedere se i problemi sono iniziati dopo una release.\n- Scrivi un mini runbook per i top 3 avvisi: cosa significa, primi controlli e chi lo possiede.\n- Mantieni una singola dashboard “golden” con l'essenziale per ogni servizio.\n\nSe costruisci backend con AppMaster, conviene pianificare i campi di osservabilità e le metriche chiave prima di generare i servizi, così ogni nuova API esce con log strutturati coerenti e segnali di health di base. Se vuoi un posto unico per iniziare a costruire quei backend, AppMaster (appmaster.io) è pensato per generare backend, web e mobile production-ready mantenendo l'implementazione coerente man mano che i requisiti cambiano.\n\nScegli un miglioramento alla volta, basato su ciò che ha davvero fatto male:\n\n- Aggiungi il timing delle query DB (e logga le query più lente con contesto).\n- Restringi gli avvisi in modo che puntino all'impatto utente, non solo a picchi di risorse.\n- Rendi una dashboard più chiara (rinomina grafici, aggiungi soglie, rimuovi pannelli inutilizzati).\n\nRipeti il ciclo dopo ogni incidente reale. In poche settimane avrai un monitoraggio che si adatta alla tua app CRUD e al traffico API invece di un template generico.Inizia con l'osservabilità quando i problemi in produzione richiedono più tempo a essere spiegati che a essere risolti. Se vedi “500 casuali”, pagine lente di elenco o timeout non riproducibili, un piccolo set coerente di log, metriche e avvisi ti farà risparmiare ore di ipotesi.
Il monitoring ti dice che c'è qualcosa che non va, mentre l'osservabilità ti aiuta a capire perché è successo usando segnali ricchi di contesto che puoi correlare. Per le API CRUD l'obiettivo pratico è una diagnosi rapida: quale endpoint, quale utente/tenant e se il tempo è stato speso nell'app o nel database.
Parti da log strutturati per le richieste, una manciata di metriche core e pochi avvisi focalizzati sull'impatto utente. Il tracing può aspettare per molte app CRUD se già registri duration_ms, db_time_ms (o simili) e un request_id stabile che puoi cercare ovunque.
Usa un unico campo di correlazione come request_id e includilo in ogni riga di log delle richieste e in ogni esecuzione di job in background. Generalo al bordo (gateway API o primo handler), passalo tra le chiamate interne e assicurati di poter cercare i log per quell'ID per ricostruire rapidamente una singola richiesta lenta o fallita.
Registra timestamp, level, service, env, route, method, status, duration_ms e identificatori sicuri come tenant_id o account_id. Evita di loggare dati personali, token e corpi di richiesta completi per default; se ti serve dettaglio, aggiungilo solo per errori specifici con redazione.
Monitora il tasso di richieste, il tasso di 5xx, i percentili di latenza (almeno p50 e p95) e la saturazione di base (CPU/memoria più qualsiasi pressione su worker o code). Aggiungi presto il tempo DB e l'utilizzo del pool di connessioni, perché molti outage CRUD sono davvero contesa sul database o esaurimento del pool.
Perché mostrano la coda lenta che gli utenti percepiscono. Le medie possono sembrare ok mentre la latenza p95 è pessima per una parte significativa delle richieste, ed è proprio così che le schermate CRUD sembrano “lente a caso” senza errori evidenti.
Osserva il tasso di query lente e i percentili di tempo query, le attese per lock/deadlock e l'utilizzo di connessioni rispetto al limite del pool. Questi segnali ti dicono se il database è il collo di bottiglia e se il problema è la performance delle query, la contesa o semplicemente l'esaurimento delle connessioni sotto carico.
Inizia con avvisi sui sintomi utente: tasso di 5xx sostenuto, latenza p95 sostenuta e un calo improvviso delle richieste riuscite. Aggiungi avvisi orientati alla causa solo dopo (per esempio connessioni DB vicine al limite o accumulo della coda) così il segnale on-call resta affidabile e azionabile.
Allega metadati di versione/build ai log, alle dashboard e agli avvisi e registra i marker di deploy così puoi vedere quando sono state spedite le modifiche. Con backend generati (come servizi Go generati da AppMaster) questo è particolarmente importante perché rigenerazioni e redeploy possono avvenire spesso, e devi confermare rapidamente se una regressione è iniziata dopo una release.



Sperimenta con AppMaster con un piano gratuito.
Quando sarai pronto potrai scegliere l'abbonamento appropriato.


