App per la prenotazione delle attrezzature: evita i conflitti e monitora le restituzioni
Progetta un'app per la prenotazione delle attrezzature che eviti le doppie prenotazioni, registri restituzioni e danni e metta in manutenzione i beni difettosi.
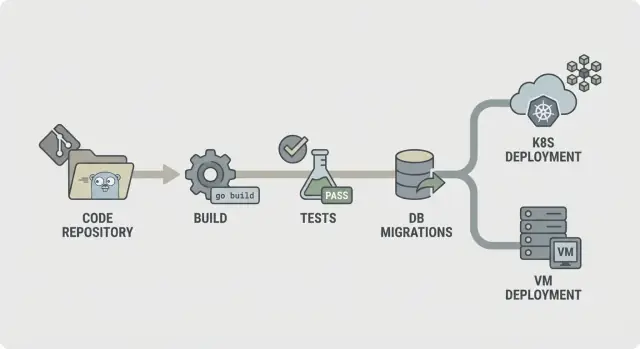
CI/CD per backend Go: passaggi pratici per pipeline di build, test, migrazioni e deploy sicuri su Kubernetes o VM con ambienti prevedibili.
I deploy manuali falliscono in modi noiosi e ripetibili. Qualcuno costruisce sul suo laptop con una versione di Go diversa, dimentica una variabile d'ambiente, salta una migrazione o riavvia il servizio sbagliato. Il rilascio “funziona per me”, ma non in produzione, e te ne accorgi solo quando gli utenti lo percepiscono.
Il codice generato non elimina la necessità di disciplina nel rilascio. Quando rigeneri un backend dopo aver cambiato i requisiti, puoi introdurre nuovi endpoint, nuove forme di dati o nuove dipendenze anche se non hai mai toccato il codice a mano. Proprio allora vuoi che la pipeline faccia da corrimano: ogni cambiamento passa dagli stessi controlli, ogni volta.
Ambienti prevedibili significano che i tuoi step di build e deploy girano in condizioni che puoi nominare e ripetere. Alcune regole coprono la maggior parte dei casi:
Lo scopo del CI/CD per backend Go non è l'automazione fine a sé stessa. È avere rilasci ripetibili con meno stress: rigenera, esegui la pipeline e fidati che il risultato sia distribuibile.
Se usi un generatore come AppMaster che produce backend Go, questo è ancora più importante. La rigenerazione è una funzionalità, ma è sicura solo quando il percorso dal cambiamento alla produzione è consistente, testato e prevedibile.
“Prevedibile” significa che lo stesso input produce lo stesso risultato, ovunque lo esegui. Per il CI/CD dei backend Go, tutto inizia dall'accordo su cosa deve rimanere identico tra dev, staging e prod.
Gli elementi non negoziabili di solito sono la versione di Go, l'immagine OS base, le flag di build e come viene caricata la configurazione. Se uno di questi cambia per ambiente, ottieni sorprese come comportamento TLS diverso, pacchetti di sistema mancanti o bug che si manifestano solo in produzione.
La maggior parte della deriva ambientale si manifesta negli stessi punti:
Scegliere tra Kubernetes e VM riguarda più cosa il tuo team riesce a gestire con calma che non cosa sia “migliore”.
Kubernetes è adatto quando ti servono autoscaling, rolling updates e uno standard per eseguire molti servizi. Aiuta anche a far rispettare la coerenza perché i pod partono dalle stesse immagini. Le VM possono avere senso quando hai uno o pochi servizi, un team piccolo e vuoi meno componenti in movimento.
Puoi mantenere la stessa pipeline anche con runtime diversi standardizzando l'artefatto e il contratto attorno a esso. Per esempio: costruisci sempre la stessa immagine container in CI, esegui gli stessi test e pubblica lo stesso pacchetto di migrazioni. Solo lo step di deploy cambia: Kubernetes applica un nuovo tag immagine, mentre le VM tirano l'immagine e riavviano il servizio.
Un esempio pratico: un team rigenera un backend Go da AppMaster e distribuisce su staging in Kubernetes ma usa una VM in produzione per ora. Se entrambi tirano esattamente la stessa immagine e caricano la config dallo stesso tipo di store per i segreti, il “runtime diverso” diventa un dettaglio di deployment, non una fonte di bug. Se stai usando AppMaster (appmaster.io), questo modello si adatta bene perché puoi distribuire su target cloud gestiti o esportare il codice sorgente ed eseguire la pipeline sulla tua infrastruttura.
Una pipeline prevedibile è facile da descrivere: controlla il codice, buildalo, dimostra che funziona, spedisci esattamente ciò che hai testato e poi distribuiscilo nello stesso modo ogni volta. Questa chiarezza è ancora più importante quando il backend è rigenerato (per esempio da AppMaster), perché i cambiamenti possono interessare molti file e vuoi feedback rapido e coerente.
Un flusso CI/CD semplice per backend Go appare così:
Strutturalo in modo che i fallimenti si fermino presto. Se il lint fallisce, nulla di altro dovrebbe girare. Se la build fallisce, non vale la pena avviare database per i controlli di integrazione. Questo mantiene i costi bassi e la pipeline veloce.
Non ogni step deve girare ad ogni commit. Una divisione comune è:
Decidi cosa conservare come artefatti. Di solito sono il binario compilato o l'immagine container (ciò che distribuisci), più log di migrazione e report di test. Conservali per rendere rollback e audit più semplici perché puoi indicare esattamente cosa è stato testato e promosso.
Uno stage di build deve rispondere a una domanda: possiamo produrre lo stesso binario oggi, domani e su un runner diverso? Se non è così, ogni step successivo (test, migrazioni, deploy) diventa meno affidabile.
Inizia bloccando l'ambiente. Usa una versione fissa di Go (per esempio 1.22.x) e un'immagine runner fissata (distro Linux e versioni dei pacchetti). Evita tag “latest”. Piccole variazioni in libc, Git o nella toolchain di Go possono creare fallimenti “funziona sulla mia macchina” difficili da debug.
La cache dei moduli aiuta, ma solo se la consideri uno speed boost, non la fonte di verità. Cache il Go build cache e la cache dei moduli, ma chiavala con go.sum (o svuotala su main quando le dipendenze cambiano) così nuove dipendenze forzano un download pulito.
Aggiungi un gate veloce prima della compilazione. Deve essere rapido così gli sviluppatori non lo aggirano. Un set tipico è gofmt, go vet e (se rimane veloce) staticcheck. Fallisci su file generati mancanti o obsoleti, che è un problema comune in codebase rigenerate.
Compila in modo riproducibile e incorpora info di versione. Flag come -trimpath aiutano, e puoi usare -ldflags per iniettare SHA del commit e tempo di build. Produci un unico artefatto nominato per servizio. Così tracci cosa gira in Kubernetes o su una VM, specialmente quando il backend è rigenerato.
I test aiutano solo se girano allo stesso modo ogni volta. Punta prima a un feedback veloce, poi aggiungi controlli più profondi che però terminino in tempi prevedibili.
Inizia con test unitari su ogni commit. Imposta un timeout rigido così un test bloccato fallisce rumorosamente invece di bloccare tutta la pipeline. Decidi anche cosa significa “copertura sufficiente” per il tuo team. La copertura non è un trofeo, ma una soglia minima aiuta a prevenire un degrado lento della qualità.
Uno stage di test stabile include di solito:
go test ./... con timeout per pacchetto e timeout globale del job.Il race detector è utile ma rallenta molto le build. Un compromesso valido è eseguirlo sulle pull request e nei build notturni, o solo su pacchetti selezionati invece che in ogni push.
I test flaky devono far fallire la build. Se devi mettere in quarantena un test, fallo in modo visibile: spostalo in un job separato che comunque gira e segnala rosso, e richiedi un owner e una scadenza per la correzione.
Conserva l'output dei test così il debug non richiede di rilanciare tutto. Salva i log grezzi più un report semplice (pass/fail, durata e test più lenti). Questo rende più facile individuare regressioni, specialmente quando rigenerazioni toccano molti file.
I test unitari ti dicono che il codice funziona isolatamente. I controlli di integrazione ti dicono che l'intero servizio si comporta correttamente quando parte, si connette a servizi reali e gestisce richieste reali. Questa è la rete di sicurezza che cattura problemi che emergono solo quando tutto è cablato insieme.
Usa dipendenze effimere quando il tuo codice ne ha bisogno per partire o per rispondere a richieste chiave. Un PostgreSQL temporaneo (e Redis, se lo usi) avviato solo per il job è generalmente sufficiente. Mantieni le versioni vicine alla produzione, ma non cercare di copiare ogni dettaglio produttivo.
Uno stage di integrazione ben fatto è volutamente piccolo:
Per i controlli del contratto API, concentrati sugli endpoint che farebbero più male se si rompessero. Non serve una suite end-to-end completa. Alcune verità su request/response bastano: campi richiesti rifiutati con 400, autenticazione richiesta ritorna 401 e un happy-path ritorna 200 con le chiavi JSON attese.
Per mantenere i test di integrazione abbastanza veloci, limita l'ambito e controlla il clock. Preferisci un solo database con un dataset minimo. Esegui poche richieste. Imposta timeout rigidi così un boot bloccato fallisce in secondi, non minuti.
Se rigeneri il backend (per esempio con AppMaster), questi controlli hanno un peso extra. Confermano che il servizio rigenerato parte correttamente e parla ancora l'API che la tua app web o mobile si aspetta.
Inizia scegliendo dove eseguire le migrazioni. Farle in CI è utile per catturare errori presto, ma CI di solito non dovrebbe toccare la produzione. La maggior parte dei team esegue le migrazioni durante il deploy (come step dedicato) o come job separato “migrate” che deve completare prima che la nuova versione parta.
Una regola pratica è: builda e testa in CI, poi esegui le migrazioni il più vicino possibile alla produzione, con credenziali di produzione e limiti simili a quelli produttivi. In Kubernetes spesso è un Job one-off. Su VM può essere un comando scriptato nello step di rilascio.
L'ordine conta più di quanto la gente si aspetti. Usa file timestamped (o numeri sequenziali) e applica “esegui in ordine, esattamente una volta”. Rendi le migrazioni idempotenti quando possibile, così un retry non crea duplicati o non si blocca a metà.
Mantieni la strategia di migrazione semplice:
Aggiungi un gate di sicurezza prima di esecuzioni reali. Può essere un lock sul database così solo una migrazione gira alla volta, più una policy tipo “nessuna modifica distruttiva senza approvazione”. Per esempio, falla fallire se una migrazione contiene DROP TABLE o DROP COLUMN a meno che non ci sia un gate manuale approvato.
Il rollback è la dura verità: molte modifiche allo schema non sono reversibili. Se elimini una colonna, non puoi ripristinarne i dati. Pianifica i rollback attorno a fix forward: conserva una down migration solo quando è davvero sicura, e affidati a backup più una migrazione forward quando non lo è.
Associa a ogni migrazione un piano di recovery: cosa fare se fallisce a metà e cosa fare se l'app deve tornare indietro. Se generi backend Go (per esempio con AppMaster), tratta le migrazioni come parte del contratto di rilascio così codice rigenerato e schema restano in sync.
Una pipeline sembra prevedibile quando ciò che distribuisci è sempre la cosa che hai testato. Questo dipende da packaging e configurazione. Tratta l'output di build come un artefatto sigillato e tieni tutte le differenze d'ambiente fuori da esso.
Il packaging segue in genere due strade. Un'immagine container è la scelta di default se distribuisci su Kubernetes, perché fissa il layer OS e rende i rollout coerenti. Un bundle per VM può essere altrettanto affidabile quando servono VM, purché includa il binario compilato più il piccolo insieme di file necessari a runtime (certificati CA, template, asset statici) e tu lo distribuisca sempre allo stesso modo.
La configurazione dovrebbe essere esterna, non incorporata nel binario. Usa variabili d'ambiente per la maggior parte delle impostazioni (porte, host DB, feature flag). Usa un file di config solo quando i valori sono lunghi o strutturati e mantienilo specifico per ambiente. Se usi un servizio di config, trattalo come una dipendenza: permessi bloccati, log di audit e un piano di fallback chiaro.
I segreti sono la linea da non oltrepassare. Non stanno nel repo, nell'immagine o nei log CI. Evita di stampare connection string all'avvio. Conserva i segreti nello secret store del CI e iniettali a deploy.
Per rendere gli artefatti tracciabili, incorpora l'identità in ogni build: tagga artefatti con versione e commit hash, includi metadata di build (versione, commit, build time) in un endpoint info e registra il tag dell'artefatto nel log di deploy. Rendi facile rispondere a “cosa sta girando” da un comando o da una dashboard.
Se generi backend Go (per esempio con AppMaster), questa disciplina è ancora più importante: la rigenerazione è sicura quando le regole di naming degli artefatti e della config rendono ogni rilascio riproducibile.
La maggior parte dei fallimenti di deploy non è “codice cattivo”. È ambiente non corrispondente: config diversa, segreti mancanti o un servizio che parte ma non è realmente pronto. Lo scopo è semplice: distribuisci lo stesso artefatto ovunque e cambia solo la configurazione.
Su Kubernetes punta a un rollout controllato. Usa rolling updates per sostituire gradualmente i pod e aggiungi readiness e liveness checks così la piattaforma sa quando inviare traffico e quando riavviare un container bloccato. Requests e limits sono importanti: un servizio Go che funziona su un runner CI grande può essere OOM-killed su un nodo piccolo.
Tieni config e segreti fuori dall'immagine. Builda un'immagine per commit, poi inietta impostazioni specifiche d'ambiente al deploy (ConfigMaps, Secrets o il tuo secret manager). Così staging e prod eseguono gli stessi bit.
Se distribuisci su macchine virtuali, systemd può essere il tuo “mini orchestrator”. Crea un unit file con working directory chiara, file di environment e policy di restart. Rendi i log prevedibili inviando stdout/stderr al tuo collector o a journald, così gli incidenti non si trasformano in cacce via SSH.
Puoi ancora fare rollout sicuri senza un cluster. Un semplice blue/green funziona: tieni due directory (o due VM), cambia il load balancer e mantieni la versione precedente pronta per rollback rapido. Il canary è simile: manda una piccola percentuale di traffico alla nuova versione prima di confermare.
Prima di dichiarare un deploy “finito”, esegui lo stesso smoke check post-deploy ovunque:
Se rigeneri backend (per esempio un backend Go da AppMaster), questo approccio resta stabile: builda una volta, distribuisci l'artefatto e lascia che la config d'ambiente guidi le differenze, non script ad-hoc.
La maggior parte dei rilasci rotti non è causata da “codice cattivo”. Succede quando la pipeline si comporta diversamente di volta in volta. Se vuoi che il CI/CD per backend Go sia calmo e prevedibile, evita questi pattern.
Eseguire migrazioni automaticamente ad ogni deploy senza guardrail è classico. Una migrazione che blocca una tabella può mettere giù un servizio occupato. Metti le migrazioni dietro uno step esplicito, richiedi approvazione per produzione e assicurati di poterle rieseguire in sicurezza.
Usare tag latest o immagini base non bloccate è un altro modo facile per creare fallimenti misteriosi. Blocca le immagini Docker e le versioni di Go così l'ambiente di build non derivi.
Condividere un database tra ambienti “temporaneamente” tende a diventare permanente ed è così che i dati di test finiscono in staging e gli script di staging colpiscono la produzione. Separa database (e credenziali) per ambiente, anche se lo schema è lo stesso.
Mancati health check e readiness check lasciano passare un deploy “riuscito” mentre il servizio è rotto e il traffico viene instradato troppo presto. Aggiungi controlli che riflettano il comportamento reale: l'app parte, si connette al database e serve una richiesta.
Infine, proprietà poco chiare su segreti, config e accessi trasformano i rilasci in congetture. Qualcuno deve possedere il processo di creazione, rotazione e iniezione dei segreti.
Un fallimento realistico: il team fa merge, la pipeline deploya e una migrazione automatica parte prima. Completa in staging (pochi dati), ma scade in produzione (dati grandi). Con immagini bloccate, separazione degli ambienti e uno step di migrazione gated, il deploy si sarebbe fermato in sicurezza.
Se generi backend Go (per esempio con AppMaster), queste regole contano ancora di più perché la rigenerazione può toccare molti file. Input prevedibili e gate espliciti impediscono che cambiamenti “grossi” diventino rilanci rischiosi.
Usala come controllo intuitivo per CI/CD di backend Go. Se puoi rispondere “sì” a ogni punto, i rilasci saranno più semplici.
Limita e rendi auditabile l'accesso alla produzione. CI dovrebbe deployare con un service account dedicato, i segreti vanno gestiti centralmente e ogni azione manuale in produzione dovrebbe lasciare traccia chiara (chi, cosa, quando).
Un piccolo team ops di quattro persone rilascia una volta a settimana. Rigenera spesso il backend Go perché il prodotto evolve. L'obiettivo è semplice: meno riparazioni notturne e rilasci che non sorprendano.
Un cambiamento tipico del venerdì: aggiungono un nuovo campo a customers (cambio di schema) e aggiornano l'API che lo scrive (cambio di codice). La pipeline tratta tutto come un unico rilascio. Costruisce un artefatto, esegue i test su quell'artefatto e solo dopo applica le migrazioni e distribuisce. Così il database non è mai avanti rispetto al codice che lo aspetta, e il codice non viene distribuito senza lo schema corrispondente.
Quando è inclusa una modifica di schema, la pipeline aggiunge un gate di sicurezza. Verifica che la migrazione sia additiva (per esempio aggiungere una colonna nullable) e segnala azioni rischiose (come drop di colonne o rewrite di grandi tabelle). Se la migrazione è rischiosa, il rilascio si ferma prima della produzione. Il team riscrive la migrazione in modo più sicuro o programma una finestra di manutenzione.
Se i test fallano, nulla procede. Lo stesso vale se le migrazioni falliscono in pre-produzione. La pipeline non deve cercare di far passare cambiamenti forzando “solo questa volta”.
Passi successivi semplici che funzionano per la maggior parte dei team:
Se generi backend con AppMaster, mantieni la rigenerazione negli stessi stage: rigenera, builda, testa, migra in un ambiente sicuro e poi distribuisci. Tratta il codice generato come qualsiasi altro sorgente. Ogni rilascio deve essere riproducibile da una versione taggata, con gli stessi passaggi ogni volta.
Blocca la versione di Go e l'ambiente di build in modo che gli stessi input producano sempre lo stesso binario o immagine. Questo elimina le differenze “funziona sulla mia macchina” e rende i guasti più riproducibili e facili da correggere.
La rigenerazione può cambiare endpoint, modelli di dati e dipendenze anche se nessuno ha modificato il codice a mano. Una pipeline fa passare queste modifiche dagli stessi controlli ogni volta, così la rigenerazione resta sicura anziché rischiosa.
Costruisci una volta sola, poi promuovi lo stesso artefatto attraverso dev, staging e produzione. Ricostruire per ogni ambiente può far finire in produzione qualcosa che non hai mai testato, anche se il commit è lo stesso.
Esegui controlli veloci su ogni pull request: formattazione, controlli statici di base, build e test unitari con timeout. Mantienili rapidi in modo che gli sviluppatori non li saltino, ma abbastanza severi da bloccare cambiamenti rotti subito.
Usa uno stage di integrazione piccolo che avvia il servizio con una config simile alla produzione e parla con dipendenze reali come PostgreSQL. L'obiettivo è catturare “compila ma non parte” e rotture evidenti del contratto senza trasformare la CI in una suite end-to-end di ore.
Tratta le migrazioni come uno step di rilascio controllato, non come qualcosa che avviene implicitamente ad ogni deploy. Eseguili con log chiari e un lock per esecuzioni singole, e sii onesto sul rollback: molte modifiche allo schema richiedono correzioni forward o backup, non un semplice undo.
Aggiungi readiness checks così il traffico raggiunge i nuovi pod solo quando il servizio è pronto, e liveness checks per riavviare container bloccati. Imposta risorse realistiche in modo che un servizio che passa in CI non venga ucciso in produzione per memoria eccessiva.
Un semplice unit file systemd più uno script di rilascio coerente spesso bastano per deploy tranquilli su VM. Mantieni lo stesso modello di artefatto usato per i container e aggiungi un piccolo smoke check post-deploy così un “riavvio avvenuto” non nasconde un servizio rotto.
Mai inserire segreti nel repository, nell'artefatto di build o nei log. Inietta i segreti al momento del deploy da uno store centralizzato, limita chi può leggerli e rendi la rotazione una routine invece che un'emergenza.
Metti la rigenerazione dentro gli stessi stage della pipeline: rigenera, builda, testa, impacchetta, poi migra e distribuisci con i dovuti gate. Se usi AppMaster per generare il backend Go, questo ti permette di muoverti velocemente senza indovinare cosa è cambiato.



Sperimenta con AppMaster con un piano gratuito.
Quando sarai pronto potrai scegliere l'abbonamento appropriato.


