App per la prenotazione delle attrezzature: evita i conflitti e monitora le restituzioni
Progetta un'app per la prenotazione delle attrezzature che eviti le doppie prenotazioni, registri restituzioni e danni e metta in manutenzione i beni difettosi.
Scopri pattern pratici per attività in background con aggiornamenti di progresso: code, modello di stato, messaggistica UI, annulla e riprova, e segnalazione errori.
Le azioni lunghe non dovrebbero bloccare l'interfaccia. Le persone cambiano tab, perdono la connessione, chiudono il portatile o semplicemente si chiedono se stia succedendo qualcosa. Quando lo schermo è congelato, gli utenti indovinano, e l'indovinare si trasforma in clic ripetuti, invii duplicati e ticket al supporto.
Un buon lavoro in background riguarda soprattutto la fiducia. Gli utenti vogliono tre cose:
Senza queste, il job potrebbe essere eseguito correttamente, ma l'esperienza sembra rotta.
Un errore comune è trattare una richiesta lenta come se fosse un vero lavoro in background. Una richiesta lenta è comunque una singola chiamata web che fa aspettare l'utente. Il lavoro in background è diverso: avvii un job, ottieni una conferma immediata e l'elaborazione pesante avviene altrove mentre l'interfaccia resta utilizzabile.
Esempio: un utente carica un CSV per importare clienti. Se l'interfaccia si blocca, potrebbe aggiornare la pagina, inviare di nuovo il file e creare duplicati. Se l'import parte in background e l'interfaccia mostra una scheda del job con progresso e una opzione di Annulla sicura, può continuare a lavorare e tornare a un risultato chiaro.
Quando si parla di attività in background con aggiornamenti di progresso, di solito si intendono quattro pezzi che lavorano insieme.
Un job è l'unità di lavoro: "importa questo CSV", "genera questo report" o "invia 5.000 email". Una coda è la fila d'attesa dove i job restano finché non possono essere processati. Un worker prende i job dalla coda e fa il lavoro (uno alla volta o in parallelo).
Per l'interfaccia, la parte più importante è lo stato del ciclo di vita del job. Mantieni gli stati pochi e prevedibili:
Ogni job ha bisogno di un ID job (un riferimento unico). Quando l'utente clicca un pulsante, restituisci subito quell'ID e mostra una riga “Task avviato” in un pannello delle attività.
Poi serve un modo per chiedere: "Cosa sta succedendo ora?". Di solito è un endpoint di stato (o qualsiasi metodo di lettura) che prende l'ID job e restituisce lo stato più dettagli di progresso. L'interfaccia lo usa per mostrare percentuale completata, passo corrente e eventuali messaggi.
Infine, lo stato deve vivere in un archivio durevole, non solo in memoria. I worker crashano, le app si riavviano e gli utenti ricaricano le pagine. Lo storage durevole è ciò che rende progresso e risultati affidabili. Al minimo, salva:
Se costruisci su una piattaforma come AppMaster, tratta lo store di stato come qualsiasi altro modello di dati: l'interfaccia lo legge per ID job e il worker lo aggiorna mentre procede attraverso il job.
Il pattern di coda che scegli cambia quanto l'app si percepisce “giusta” e prevedibile. Se un task resta dietro a una montagna di lavoro, gli utenti lo percepiranno come ritardo casuale, anche quando il sistema è sano. Questo rende la scelta della coda una decisione di UX, non solo infrastrutturale.
Una coda semplice basata sul database spesso basta quando il volume è basso, i job sono brevi e puoi tollerare retry occasionali. È facile da configurare, facile da ispezionare e puoi tenere tutto in un posto. Esempio: un admin esegue un report notturno per un piccolo team. Se fa un retry una volta, nessuno entra in panico.
Serve solitamente un sistema di code dedicato quando il throughput cresce, i job diventano pesanti o l'affidabilità è imprescindibile. Importazioni, elaborazione video, notifiche di massa e qualsiasi workflow che deve continuare attraverso riavvii beneficiano di migliore isolamento, visibilità e comportamento di retry più sicuro. Questo conta per il progresso visibile perché le persone notano aggiornamenti mancanti e stati bloccati.
La struttura della coda influisce anche sulle priorità. Una sola coda è più semplice, ma mischiare lavoro veloce e lento può rallentare le azioni rapide. Code separate aiutano quando hai lavoro attivato dall'utente che deve sembrare istantaneo accanto a lavori batch pianificati che possono aspettare.
Imposta limiti di concorrenza con criterio. Troppa parallelizzazione può sovraccaricare il database e rendere il progresso irregolare. Troppo poca rende il sistema lento. Parti con una concorrenza bassa e prevedibile per coda, poi aumenta solo quando puoi mantenere tempi di completamento stabili.
Se il tuo modello di progresso è vago, anche l'interfaccia sembrerà vaga. Decidi cosa il sistema può riportare onestamente, quanto spesso cambia e cosa gli utenti dovrebbero fare con quell'informazione.
Uno schema di stato semplice che la maggior parte dei job può supportare somiglia a questo:
Poi, definisci cosa significa “progresso”.
La percentuale funziona quando esiste un vero denominatore (righe in un file, email da inviare). È fuorviante quando il lavoro è imprevedibile (attesa di terze parti, calcolo variabile, query costose). In quei casi, il progresso basato su passi costruisce più fiducia perché avanza in blocchi chiari.
Una regola pratica:
Salva risultati parziali mentre il job gira. Questo permette all'interfaccia di mostrare qualcosa di utile prima che il job finisca, come un conto live degli errori o l'anteprima di ciò che è cambiato. Per un'importazione CSV, potresti salvare rows_read, rows_created, rows_updated, rows_rejected e gli ultimi messaggi di errore.
Questa è la base per attività in background con aggiornamenti di progresso che gli utenti possono fidarsi: l'interfaccia resta calma, i numeri si muovono e il riepilogo “cosa è successo?” è pronto quando il job termina.
Portare il progresso dal backend allo schermo è dove molte implementazioni falliscono. Scegli un metodo di consegna che si adatti a quanto spesso cambia il progresso e a quanti utenti ti aspetti che lo osservino.
Il polling è il più semplice: l'interfaccia chiede lo stato ogni N secondi. Un buon default è 2–5 secondi mentre l'utente è attivamente sulla pagina, poi rallentare col tempo. Se il job dura più di un minuto, passa a 10–30 secondi. Se la tab è in background, rallenta ulteriormente.
Gli aggiornamenti push (WebSocket, server-sent events o notifiche mobile) aiutano quando il progresso cambia rapidamente o gli utenti tengono d'occhio lo stato “in tempo reale”. Il push è ottimo per l'immediatezza, ma serve comunque un fallback quando la connessione cade.
Un approccio ibrido è spesso il migliore: poll veloce all'inizio (così l'interfaccia vede rapidamente il passaggio da in coda a in esecuzione), poi rallenta quando il job è stabile. Se aggiungi il push, mantieni un poll lento come rete di sicurezza.
Quando gli aggiornamenti si fermano, trattalo come uno stato di primo piano. Mostra “Ultimo aggiornamento 2 minuti fa” e offri un refresh. Sul backend, marca i job come stale se non ricevono heartbeat.
La chiarezza viene da due cose: un piccolo insieme di stati prevedibili e copy che dice alle persone cosa succederà dopo.
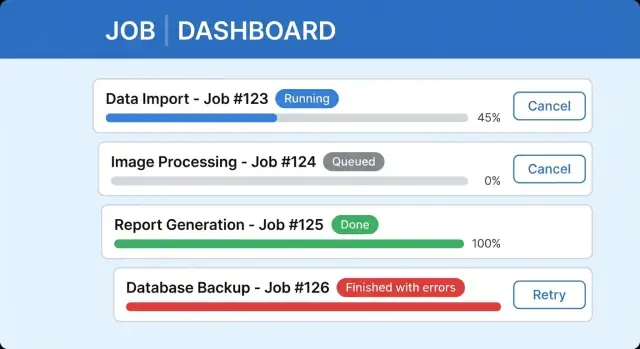
Dai un nome agli stati nell'interfaccia, non solo nel backend. Un job potrebbe essere in coda (in attesa), in esecuzione (sta facendo lavoro), in attesa di input (serve una scelta), completato, completato con errori o fallito. Se gli utenti non riescono a distinguerli, penseranno che l'app sia bloccata.
Usa copy semplice e utile vicino all'indicatore di progresso. “Importazione 3.200 righe (1.140 processate)” è meglio di “Elaborazione.” Aggiungi una frase che risponda: posso lasciare la pagina e cosa succede? Per esempio: “Puoi chiudere questa finestra. Continueremo l'import in background e ti notificheremo quando è pronto.”
Dove mostrare il progresso dovrebbe corrispondere al contesto dell'utente:
Per qualsiasi cosa più lunga di un minuto, aggiungi una pagina Jobs semplice (o un pannello Activity) così le persone possono trovare il lavoro più tardi.
Un'interfaccia chiara per task lunghi di solito include un'etichetta di stato con l'ultimo aggiornamento, una barra di progresso (o passi) con una riga di dettaglio, un comportamento di Annulla sicuro e un'area risultati con riepilogo e azione successiva. Mantieni i job completati facilmente reperibili così gli utenti non si sentono costretti ad aspettare su una singola schermata.
“Completato” non è sempre una vittoria. Quando un job elabora 9.500 record e 120 falliscono, gli utenti devono capire cosa è successo senza leggere log.
Tratta il successo parziale come un esito a sé stante. Nella riga di stato principale mostra entrambi i lati: “Importati 9.380 di 9.500. 120 falliti.” Questo mantiene alta la fiducia perché il sistema è onesto e conferma che il lavoro è stato salvato.
Poi mostra un piccolo riepilogo errori azionabile: “Campo obbligatorio mancante (63)” e “Formato data non valido (41).” Nello stato finale “Completato con problemi” è spesso più chiaro di “Fallito”, perché non implica che nulla abbia funzionato.
Un report errori esportabile trasforma la confusione in una lista di cose da fare. Sii semplice: identificatore di riga o elemento, categoria dell'errore, messaggio leggibile e il nome del campo quando rilevante.
Rendi l'azione successiva ovvia e vicina al riepilogo: correggi i dati e riprova le righe fallite, scarica il report errori o contatta il supporto se sembra un problema di sistema.
Annulla e Riprova sembrano semplici, ma rompono rapidamente la fiducia quando l'interfaccia dice una cosa e il sistema ne fa un'altra. Definisci cosa significa Annulla per ogni tipo di job e rifletti quella scelta onestamente nell'interfaccia.
Di solito ci sono due modalità valide di annullamento:
Nell'interfaccia mostra uno stato intermedio come “Richiesta di cancellazione” così gli utenti non continuano a cliccare.
Rendi la cancellazione sicura progettando il lavoro in modo ripetibile. Se un job scrive dati, preferisci operazioni idempotenti (sicure da eseguire più volte) e fai pulizia quando necessario. Per esempio, se un'importazione CSV crea record, memorizza un job-run ID così puoi rivedere cosa è cambiato nella run #123.
Il retry necessita della stessa chiarezza. Riprova lo stesso job quando ha senso riprendere; creare una nuova istanza job è più sicuro quando vuoi una run pulita con nuovo timestamp e audit trail. In entrambi i casi, spiega cosa verrà eseguito e cosa no.
Guardrail che mantengono cancel e retry prevedibili:
Un buon flusso end-to-end inizia con una regola: l'interfaccia non dovrebbe mai aspettare il lavoro in sé. Dovrebbe aspettare solo un ID job.
L'utente avvia il task, l'API risponde velocemente. Quando l'utente clicca Importa o Genera report, il tuo server crea immediatamente un record job e restituisce un ID job unico.
Accoda il lavoro e imposta il primo stato. Metti l'ID job in una coda e imposta lo stato su in coda con progresso 0%. Questo dà all'interfaccia qualcosa di reale da mostrare anche prima che un worker lo prenda.
Il worker esegue e segnala il progresso. Quando un worker parte, imposta lo stato su in esecuzione, salva il tempo di inizio e aggiorna il progresso in salti piccoli e onesti. Se non puoi misurare percentuale, mostra passi come Parsing, Validazione, Salvataggio.
L'interfaccia mantiene l'utente orientato. L'interfaccia fa polling o si iscrive agli aggiornamenti e rende stati chiari. Mostra un messaggio breve (cosa sta succedendo ora) e solo le azioni sensate in quel momento.
Finalizza con un risultato durevole. Alla fine, salva il tempo di fine, l'output (riferimento download, ID creati, conteggi di riepilogo) e i dettagli errore. Supporta l'esito “finito con errori” come risultato distinto, non come un vago successo.
Cancel deve essere esplicito: la richiesta di cancellazione viene inviata, poi il worker la riconosce e marca il job come annullato. Retry dovrebbe creare un nuovo ID job, mantenere l'originale come cronistoria e spiegare cosa verrà rieseguito.
Un caso comune dove gli aggiornamenti di progresso contano è l'importazione CSV. Immagina un CRM dove una persona carica customers.csv con 8.420 righe.
Subito dopo il caricamento, l'interfaccia dovrebbe passare da “Ho cliccato un pulsante” a “esiste un job e puoi andartene.” Una semplice scheda job in una pagina Imports funziona bene:
Mentre è in esecuzione, mostra un singolo numero di progresso su cui gli utenti possono fare affidamento (righe processate) e una breve linea di stato (cosa sta facendo ora). Se l'utente naviga via, mantieni il job visibile in un'area Recent jobs.
Aggiungendo i fallimenti parziali: quando il job termina, evita un banner spaventoso “Fallito” se la maggior parte delle righe è andata a buon fine. Usa “Completato con problemi” più un chiaro split:
Importati 8.102 clienti. 318 righe saltate.
Spiega le ragioni principali in parole semplici: formato email non valido, campi obbligatori mancanti come company o ID esterni duplicati. Permetti all'utente di scaricare o visualizzare una tabella errori con numero riga, nome cliente e il campo esatto da correggere.
Il retry dovrebbe risultare sicuro e specifico. L'azione primaria può essere “Riprova righe fallite”, creando un nuovo job che rielabora solo le 318 righe saltate dopo che l'utente ha sistemato il CSV. Mantieni il job originale in sola lettura così la cronistoria resta veritiera.
Infine, rendi i risultati semplici da trovare in seguito. Ogni import dovrebbe avere un riepilogo stabile: chi l'ha eseguito, quando, nome file, conteggi (importati, saltati) e un modo per aprire il report errori.
Il modo più rapido per perdere fiducia è mostrare numeri che non sono reali. Una barra di progresso che resta allo 0% per due minuti e poi salta al 90% sembra un azzardo. Se non conosci la vera percentuale, mostra passi (In coda, Elaborazione, Finalizzazione) o “X di Y elementi processati.”
Un altro problema comune è salvare il progresso solo in memoria. Se il worker si riavvia, l'interfaccia “dimentica” il job o resetta il progresso. Salva lo stato del job in storage durevole e fai in modo che l'interfaccia legga da quella singola fonte di verità.
La UX del retry si rompe anche quando gli utenti possono avviare lo stesso job più volte. Se il pulsante Importa CSV sembra ancora attivo, qualcuno clicca due volte e crea duplicati. Ora i retry sono confusi perché non è chiaro quale run correggere.
Errori ricorrenti:
Un dettaglio piccolo ma importante: separa il messaggio per l'utente dai dettagli per lo sviluppatore. Mostra “12 righe non valide” all'utente e conserva la traccia tecnica nei log.
Prima del rilascio, fai un passaggio rapido sulle parti che gli utenti notano: chiarezza, fiducia e recupero.
Ogni job dovrebbe esporre uno snapshot che puoi mostrare ovunque: stato (in coda, in esecuzione, riuscito, fallito, annullato), progresso (0–100 o passi), un messaggio breve, timestamp (creato, iniziato, finito) e un puntatore al risultato (dove vive l'output o il report).
Rendi gli stati dell'interfaccia ovvi e coerenti. Gli utenti hanno bisogno di un posto affidabile dove trovare job correnti e passati, più etichette chiare quando tornano più tardi (“Completato ieri”, “Ancora in esecuzione”). Un pannello Recent jobs spesso previene clic ripetuti e lavori duplicati.
Definisci regole di annulla e riprova in termini semplici. Decidi cosa significa Cancel per ogni job, se il retry è permesso e cosa viene riutilizzato (stessi input, nuovo ID job). Poi testa casi limite come cancellare subito prima del completamento.
Tratta i fallimenti parziali come un vero esito. Mostra un breve riepilogo (“Importati 97, saltati 3”) e fornisci un report azionabile che gli utenti possano usare subito.
Pianifica il recovery. I job devono sopravvivere ai riavvii e i job bloccati devono scadere in uno stato chiaro con istruzioni ("Riprova" o "Contatta il supporto con l'ID job").
Scegli un workflow per cui gli utenti si lamentano già: import CSV, esportazione report, invio email in massa o elaborazione immagini. Parti in piccolo e dimostra le basi: un job viene creato, eseguito, segnala stato e l'utente può ritrovarlo in seguito.
Una semplice schermata della cronologia job è spesso il salto di qualità più grande. Dà alle persone un posto dove tornare, invece di fissare uno spinner.
Scegli un metodo di consegna del progresso per la versione uno. Il polling va bene per cominciare. Imposta l'intervallo di aggiornamento abbastanza lento da essere gentile con il backend, ma abbastanza veloce da sembrare vivo.
Un ordine pratico di implementazione che evita riscritture:
Se costruisci senza scrivere codice, una piattaforma no-code come AppMaster può aiutare permettendoti di modellare una tabella di stato job (PostgreSQL) e aggiornarla dai workflow, poi renderizzare quello stato su web e mobile. Per i team che vogliono un unico posto per costruire backend, UI e logica in background, AppMaster (appmaster.io) è pensato per applicazioni complete, non solo moduli o pagine.
Un job in background viene avviato rapidamente e restituisce subito un ID job, così l'interfaccia può restare utilizzabile. Una richiesta lenta fa invece attendere l'utente fino al completamento della chiamata web, con rischi di refresh, doppi clic e invii duplicati.
Mantieni le cose semplici: in coda, in esecuzione, completato e fallito, più annullato se supporti la cancellazione. Aggiungi un esito separato come “completato con problemi” quando la maggior parte del lavoro è andata a buon fine ma alcuni elementi sono falliti, così gli utenti non pensano che tutto sia andato perso.
Restituisci immediatamente un ID job unico quando l'utente avvia l'azione, quindi mostra una riga o scheda del task usando quell'ID. L'interfaccia deve leggere lo stato per ID job in modo che l'utente possa aggiornare la pagina, cambiare tab o tornare più tardi senza perdere il tracciamento.
Memorizza lo stato del job in una tabella persistente del database, non solo in memoria. Salva stato corrente, timestamp, valore di progresso, un breve messaggio per l'utente e un riepilogo di risultato o errore in modo che l'interfaccia possa ricostruire sempre la stessa vista dopo riavvii.
Usa la percentuale solo quando puoi onestamente riportare “X di Y” elementi processati. Se non hai un denominatore reale, mostra progressi basati su passi come “Validazione”, “Importazione” e “Finalizzazione”, e mantieni il messaggio aggiornato in modo che l'utente percepisca movimento.
Il polling è il più semplice e funziona bene per la maggior parte delle app; inizia con intervalli di 2–5 secondi mentre l'utente osserva, poi rallenta per job lunghi o per tab in background. Gli aggiornamenti push possono sembrare più istantanei, ma serve comunque un fallback perché le connessioni cadono e gli utenti si spostano tra le schermate.
Mostra che gli aggiornamenti sono obsoleti invece di fingere che il job sia ancora attivo, ad esempio con “Ultimo aggiornamento 2 minuti fa” e offrendo un aggiornamento manuale. Sul backend, rileva la mancanza di heartbeat e sposta il job in uno stato chiaro con indicazioni, per esempio riprovare o contattare il supporto con l'ID job.
Rendi ovvia l'azione successiva: se l'utente può continuare a lavorare, lasciare la pagina o cancellare in sicurezza. Per attività più lunghe di un minuto, una vista dedicata Jobs o Activity aiuta gli utenti a ritrovare i risultati più tardi invece di fissare un singolo spinner.
Consideralo come un esito a sé stante e mostra entrambe le parti chiaramente, ad esempio “Importati 9.380 di 9.500. 120 falliti.” Poi fornisci un piccolo riepilogo degli errori azionabile che gli utenti possano risolvere senza leggere i log; tieni i dettagli tecnici nei log interni, non in primo piano.
Definisci cosa significa Cancel per ogni tipo di job e mostrala onestamente, includendo uno stato intermedio “cancel requested” così gli utenti non continuano a cliccare. Rendi le operazioni idempotenti quando possibile, limita i retry e decidi se il retry riprende lo stesso job o crea un nuovo ID job con una cronologia pulita.



Sperimenta con AppMaster con un piano gratuito.
Quando sarai pronto potrai scegliere l'abbonamento appropriato.


