App per la prenotazione delle attrezzature: evita i conflitti e monitora le restituzioni
Progetta un'app per la prenotazione delle attrezzature che eviti le doppie prenotazioni, registri restituzioni e danni e metta in manutenzione i beni difettosi.
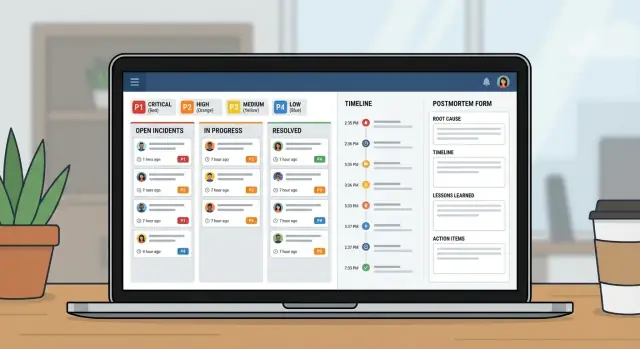
Progetta e realizza un'app per la gestione degli incidenti per team IT con workflow di severità, ownership chiara, timeline e postmortem in un unico strumento interno.
Quando scatta un outage, la maggior parte dei team prende qualunque cosa sia a portata di mano: una conversazione in chat, una catena di email, magari un foglio di calcolo che qualcuno aggiorna quando ha un minuto. Sotto pressione, quella configurazione fallisce sempre negli stessi modi: l'ownership diventa sfocata, i timestamp spariscono e le decisioni si perdono nello scrolling.
Un'app semplice di incident management sistema le basi. Ti dà un posto unico dove vive l'incidente, con un responsabile chiaro, un livello di severità condiviso e una timeline di cosa è successo e quando. Quel record singolo è importante perché le stesse domande emergono in ogni incidente: chi guida? Quando è iniziato? Qual è lo stato attuale? Cosa è già stato provato?
Senza quel record condiviso, i passaggi di consegna sprecano tempo. Il supporto comunica ai clienti una cosa mentre l'engineering fa qualcos'altro. I manager chiedono aggiornamenti che distolgono i responder dalla risoluzione. Dopo, nessuno riesce a ricostruire la timeline con fiducia e il postmortem diventa congettura.
L'obiettivo non è sostituire il monitoring, la chat o il ticketing. Gli alert possono partire altrove. Il punto è catturare la traccia decisionale e mantenere le persone allineate.
Le operation IT e gli on-call lo usano per coordinare la risposta. Il supporto lo usa per fornire aggiornamenti accurati in fretta. I manager lo usano per vedere i progressi senza interrompere i responder.
Alle 09:12 il monitoring segnala un picco di errori 500 sul portale clienti. Un agente di supporto segnala anche: “Login fallisce per la maggior parte degli utenti.” Il responsabile on-call apre un incidente P1 nell'app e allega il primo alert più uno screenshot dal supporto.
Con un P1, il comportamento cambia rapidamente. L'owner dell'incidente coinvolge il responsabile backend, il responsabile DB e un referente del supporto. Il lavoro non essenziale si mette in pausa. Le deploy programmate si fermano. Il team concorda una cadenza di aggiornamento (per esempio ogni 15 minuti). Parte una call condivisa, ma la pagina dell'incidente rimane la fonte di verità.
Alle 09:18 qualcuno chiede: “Cosa è cambiato?” La timeline mostra una deploy alle 08:57, ma non dice cosa è stato deployato. Il responsabile backend rollbacka comunque. Gli errori calano, poi ritornano. Ora il team sospetta il database.
La maggior parte dei ritardi appare in pochi punti prevedibili: passaggi di consegna poco chiari (“pensavo che lo controllassi tu”), contesto mancante (cambi recenti, rischi noti, owner attuale) e aggiornamenti sparsi tra chat, ticket ed email.
Alle 09:41 il responsabile DB trova una query fuori controllo avviata da un job schedulato. Disabilita il job, riavvia il servizio coinvolto e conferma il recovery. La severità viene abbassata a P2 per monitoraggio.
Una buona chiusura non è “ora funziona”. È un record pulito: una timeline minuto per minuto, la root cause finale, chi ha preso quale decisione, cosa è stato messo in pausa e i follow-up con owner e scadenze. Così un P1 stressante diventa apprendimento invece di dolore ripetuto.
Un buon strumento di incident è soprattutto un buon modello dati. Se i record sono vaghi, le persone litigheranno su cosa sia l'incidente, quando è iniziato e cosa è ancora aperto.
Mantieni le entità core vicine al modo in cui i team IT già parlano:
Per evitare confusione dopo, dai all'Incident pochi campi strutturati che siano sempre compilati. Il testo libero aiuta, ma non dovrebbe essere l'unica fonte di verità. Un minimo pratico è: titolo chiaro, impatto (cosa sperimenta l'utente), servizi coinvolti, orario di inizio, stato corrente e severità.
Le relazioni contano più dei campi extra. Un incidente dovrebbe avere molti aggiornamenti e molti task, più un link molti-a-molti ai servizi (perché spesso l'outage coinvolge sistemi multipli). Un postmortem dovrebbe essere uno a uno con un incidente, così c'è una storia finale unica.
Esempio: un incidente “Errori checkout” è collegato ai servizi “Payments API” e “PostgreSQL”, ha aggiornamenti ogni 15 minuti e task come “Rollback deploy” e “Aggiungi retry guard.” Dopo, il postmortem cattura la root cause e crea task a lungo termine.
Quando le persone sono sotto stress, servono etichette semplici che significhino la stessa cosa per tutti. Definisci P1–P4 in linguaggio piano e mostra la definizione vicino al campo severità.
Gli obiettivi di risposta dovrebbero leggere come impegni. Una baseline semplice (adatta alla vostra realtà):
| Severity | First response (ack) | First update | Update frequency |
|---|---|---|---|
| P1 | 5 min | 15 min | every 30 min |
| P2 | 15 min | 30 min | every 60 min |
| P3 | 4 hours | 1 business day | daily |
| P4 | 2 business days | 1 week | weekly |
Mantieni le regole di escalation meccaniche. Se un P2 salta la cadenza di aggiornamento o l'impatto cresce, il sistema dovrebbe suggerire una revisione della severità. Per evitare oscillazioni, limita chi può cambiare la severità (spesso l'incident owner o l'incident commander), permettendo comunque a chiunque di chiedere una revisione con un commento.
Una matrice d'impatto rapida aiuta anche a scegliere la severità velocemente. Catturala come pochi campi richiesti: utenti coinvolti, rischio di revenue, sicurezza/safety, compliance/security e se esiste un workaround.
Durante un incidente, alle persone non servono più opzioni. Serve un set ridotto di stati che renda ovvio il passo successivo.
Parti dagli step che già segui in una buona giornata, poi tieni la lista corta. Se hai più di 6–7 stati, i team discuteranno le etichette invece di risolvere il problema.
Un set pratico:
Ogni stato necessita regole chiare di entrata e uscita. Per esempio:
Usa le transizioni per imporre i campi che la gente dimentica. Una regola comune: non puoi chiudere un incidente senza una breve sintesi della root cause e almeno un elemento di follow-up. Se lasci “RCA: TBD”, di solito rimane così.
La pagina dell'incidente dovrebbe rispondere a tre domande in un colpo d'occhio: chi lo possiede, qual è la prossima azione e quando è stato pubblicato l'ultimo aggiornamento.
Quando un incidente è rumoroso, il modo più veloce per perdere tempo è l'ownership vaga. La tua app dovrebbe rendere una persona chiaramente responsabile, pur facilitando l'aiuto degli altri.
Un pattern semplice che funziona:
L'assegnazione deve essere esplicita e verificabile. Traccia chi ha impostato l'owner, chi l'ha accettato e ogni cambiamento successivo. «Accettato» conta, perché assegnare qualcuno assente o che dorme non equivale a vera ownership.
L'assegnazione on-call vs di team dipende spesso dalla severità. Per P1/P2, di default usa la rotazione on-call così c'è sempre un owner nominato. Per severità più basse, l'assegnazione per team può funzionare, ma richiedi comunque un owner singolo entro una finestra breve.
Pianifica ferie e outage nel processo umano, non solo nei sistemi. Se la persona assegnata è segnata come non disponibile, instrada automaticamente al secondario on-call o al team lead. Mantienilo automatico ma visibile così si può correggere rapidamente.
L'escalation dovrebbe scattare sia per severità sia per silenzio. Un punto di partenza utile:
Una buona timeline è memoria condivisa. Durante un incidente, il contesto evapora velocemente. Se catturi i momenti giusti in un unico posto, i passaggi di consegna diventano più semplici e il postmortem è in gran parte già scritto prima che qualcuno apra un documento.
Rendi la timeline opinabile: non trasformarla in un log di chat. La maggior parte dei team si affida a poche voci: rilevamento, presa in carico, passi chiave di mitigazione, ripristino e chiusura.
Ogni voce deve avere timestamp, autore e una breve descrizione in linguaggio piano. Chi si unisce in ritardo dovrebbe poter leggere cinque voci e capire cosa sta succedendo.
Aggiornamenti diversi servono pubblici diversi. Aiuta quando le voci hanno un tipo, per esempio nota interna (dettagli grezzi), aggiornamento per cliente (formulazione sicura), decisione (perché scelto l'opzione A) e handoff (cosa deve sapere il prossimo).
I promemoria dovrebbero seguire la severità, non le preferenze personali. Se il timer scade, prima avvisa l'owner corrente, poi scala se viene ripetutamente ignorato.
Le notifiche devono essere mirate e prevedibili. Un piccolo insieme di regole è solitamente sufficiente: notificare alla creazione, al cambio di severità, al ripristino e agli aggiornamenti scaduti. Evita di notificare tutta l'azienda per ogni cambiamento.
Un postmortem deve fare due cose: spiegare cosa è successo in linguaggio semplice e rendere meno probabile la stessa falla la volta successiva.
Mantieni il resoconto breve e obbliga a trasformare le conclusioni in azioni. Una struttura pratica: sommario, impatto sul cliente, root cause, fix applicati e follow-up.
I follow-up sono il punto. Non lasciarli come un paragrafo alla fine. Trasforma ogni follow-up in un task tracciato con owner e scadenza, anche se la scadenza è “prossimo sprint.” Questa è la differenza tra «dovremmo migliorare il monitoring» e «Alex aggiunge un alert di saturazione connessioni DB entro venerdì.»
I tag rendono i postmortem utili nel tempo. Aggiungi 1–3 temi ad ogni incidente (gap di monitoring, deploy, capacità, processo). Dopo un mese puoi rispondere a domande base come se la maggior parte dei P1 derivi da release o da alert mancanti.
L'evidenza dovrebbe essere facile da allegare, non obbligatoria. Supporta campi opzionali per screenshot, snippet di log e riferimenti a sistemi esterni (ID ticket, thread chat, numeri caso vendor). Mantienilo leggero così le persone lo compileranno davvero.
Tratta questo come un piccolo prodotto, non come un foglio di calcolo con colonne extra. Una buona app per incidenti sono davvero tre viste: cosa succede ora, cosa fare dopo e cosa imparare dopo.
Inizia disegnando le schermate che le persone apriranno sotto pressione:
Costruisci modello dati e permessi insieme. Se tutti possono modificare tutto, la cronologia diventa caotica. Un approccio comune: accesso in lettura ampio per IT, cambi di stato/severità controllati, i responder possono aggiungere aggiornamenti e un owner chiaro per l'approvazione del postmortem.
Poi aggiungi regole di workflow che prevengano incidenti mezzi compilati. I campi obbligatori dovrebbero dipendere dallo stato. Potresti permettere lo stato “New” con solo titolo e reporter, ma richiedere che “Mitigating” includa un sommario d'impatto e che “Resolved” includa una sintesi della root cause più almeno un follow-up.
Infine, testa riproducendo 2–3 incidenti passati. Fai fare a una persona il ruolo di incident commander e a un'altra quello di responder. Vedrai subito quali stati sono poco chiari, quali campi saltano e dove servono default migliori.
La maggior parte dei sistemi di incident fallisce per ragioni semplici: le persone non ricordano le regole sotto stress e l'app non cattura i fatti utili in seguito.
Se hai sei livelli di severità e dieci stati, la gente indovinerà. Mantieni 3–4 severità e stati focalizzati su quale dovrebbe essere il prossimo passo.
Quando tutti «guardano», nessuno guida. Richiedi un owner nominato prima che l'incidente possa procedere e rendi espliciti i passaggi di consegna.
Se «quando è successo cosa» dipende dalla storia della chat, i postmortem diventano discussioni. Cattura automaticamente timestamp per aperture, acknowledge, mitigazioni e risoluzioni, e mantieni le voci della timeline brevi.
Evita anche di chiudere con note vaghe sulla root cause come «problema di rete.» Richiedi una frase chiara sulla root cause più almeno un passaggio concreto successivo.
Prima del rollout a tutta l'organizzazione IT, stressa le basi. Se le persone non trovano il pulsante giusto nei primi due minuti, torneranno su chat e fogli di calcolo.
Concentrati su un piccolo set di controlli di lancio: ruoli e permessi, definizioni di severità chiare, ownership forzata, regole di promemoria e un percorso di escalation quando i target di risposta vengono mancati.
Pilota con un team e alcuni servizi che generano alert frequenti. Usalo per due settimane, poi aggiusta in base agli incidenti reali.
Se vuoi costruirlo come un unico strumento interno senza unire fogli di calcolo e app separate, AppMaster (appmaster.io) è un'opzione. Permette di creare il modello dati, le regole di workflow e le interfacce web/mobile in un unico posto, che si adatta bene a una coda incidenti, una pagina incidente e al tracciamento dei postmortem.
Sostituisce aggiornamenti sparsi con un unico record condiviso che risponde rapidamente alle domande base: chi è il responsabile, cosa vedono gli utenti, cosa è già stato provato e quale sarà il passo successivo. Questo riduce il tempo perso in passaggi di consegna, messaggi contraddittori e interruzioni per riassunti.
Apri l'incidente non appena ritieni che ci sia un impatto reale sul cliente o sul business, anche se la causa non è ancora chiara. Puoi aprirlo con un titolo provvisorio e «impatto sconosciuto», poi dettagliare man mano che confermi severità e scope.
Mantienilo piccolo e strutturato: titolo chiaro, sommario dell'impatto, servizio/i coinvolti, orario di inizio, stato corrente, severità e un owner singolo. Aggiungi aggiornamenti e task mentre evolve la situazione, ma non affidarti solo a testo libero per i fatti core.
Usa 3–4 livelli con definizioni chiare e non discutibili. Un buon default: P1 per outage core o rischio di perdita dati, P2 per impatto su feature importanti con workaround o raggio limitato, P3 per problemi a basso impatto e P4 per problemi estetici o minori.
Traccia obiettivi che sembrino impegni: tempo di presa in carico, tempo al primo aggiornamento e cadenza degli aggiornamenti. Poi attiva promemoria e escalation quando la cadenza viene saltata: nel caos, il vero errore è il silenzio.
Punta a circa sei stati: New, Acknowledged, Investigating, Mitigating, Monitoring e Resolved. Ogni stato deve rendere ovvio il passo successivo e le transizioni devono imporre i campi che spesso vengono dimenticati sotto stress, per esempio richiedere un owner prima di Acknowledged o una sintesi della root cause prima della chiusura.
Richiedi un owner primario che sia responsabile di guidare la risposta e di pubblicare aggiornamenti. Registra esplicitamente l'accettazione così da non «assegnare» qualcuno che è offline, e registra le handoff in modo che il successivo non debba ricominciare l'indagine da capo.
Cattura solo i momenti importanti: rilevamento, presa in carico, decisioni chiave, azioni di mitigazione, ripristino e chiusura. Ogni voce deve avere timestamp e autore. Considerala memoria condivisa, non una trascrizione di chat, così chi arriva tardi capisce in pochi elementi.
Rendi il postmortem breve e focalizzato sull'azione: cosa è successo, impatto sui clienti, root cause, cosa avete cambiato durante la mitigazione e i follow-up con owner e scadenze. Il documento è utile, ma sono i task tracciati che impediscono la ripetizione dell'incidente.
Sì: se modelli incidenti, aggiornamenti, task, servizi e postmortem come dati reali e applichi regole di workflow nell'app, non serve incollare sistemi diversi. Con AppMaster (appmaster.io) è possibile creare il modello dati, le schermate web/mobile e le validazioni basate stato in un unico posto, evitando il ritorno ai fogli di calcolo sotto stress.



Sperimenta con AppMaster con un piano gratuito.
Quando sarai pronto potrai scegliere l'abbonamento appropriato.


