11 dic 2025·8 min de lectura
Cambios de esquema sin tiempo de inactividad: migraciones aditivas seguras
Aprende cambios de esquema sin tiempo de inactividad con migraciones aditivas, backfills seguros y despliegues por fases que mantienen a clientes antiguos funcionando durante las releases.
Qué significa realmente “sin tiempo de inactividad” para los cambios de esquema
Los cambios de esquema sin tiempo de inactividad no significan que nada cambie. Significan que los usuarios pueden seguir trabajando mientras actualizas la base de datos y la app, sin fallos ni flujos bloqueados.
El tiempo de inactividad es cualquier momento en que tu sistema deja de comportarse con normalidad. Eso puede verse como errores 500, timeouts en la API, pantallas que cargan pero muestran valores en blanco o equivocados, jobs en background que se caen, o una base de datos que acepta lecturas pero bloquea escrituras porque una migración larga tiene locks.
Un cambio de esquema puede romper más que la UI principal. Puntos de fallo comunes incluyen clientes de API que esperan una forma de respuesta antigua, jobs en background que leen o escriben columnas específicas, informes que consultan tablas directamente, integraciones de terceros y scripts administrativos internos que “estaban funcionando ayer”.
Las apps móviles antiguas y los clientes cacheados son un problema frecuente porque no puedes actualizarlos al instante. Algunos usuarios mantienen una versión de la app semanas. Otros tienen conectividad intermitente y reintentan peticiones antiguas más tarde. Incluso clientes web pueden comportarse como “versiones antiguas” cuando un service worker, CDN o proxy cache conserva código o supuestos obsoletos.
El objetivo real no es “una gran migración que termine rápido.” Es una secuencia de pequeños pasos donde cada paso funciona por sí solo, incluso cuando distintos clientes están en versiones diferentes.
Una definición práctica: debes poder desplegar código nuevo y esquema nuevo en cualquier orden, y que el sistema siga funcionando.
Esa mentalidad te ayuda a evitar la trampa clásica: desplegar una app nueva que espera una columna nueva antes de que exista, o desplegar una columna nueva que el código antiguo no sabe manejar. Planifica cambios para que sean aditivos primero, distribúyelos por fases y elimina las rutas antiguas solo cuando estés seguro de que nadie las usa.
Empieza con cambios aditivos que no rompan el código existente
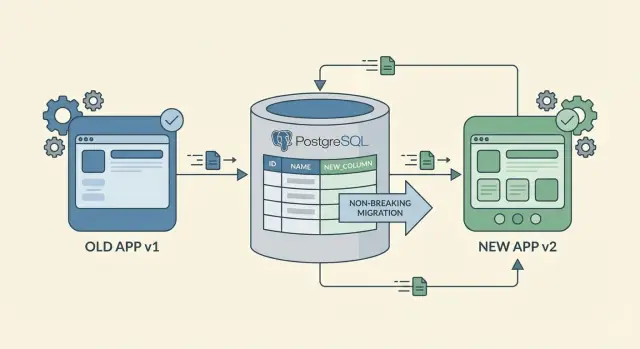
El camino más seguro hacia cambios de esquema sin tiempo de inactividad es añadir, no reemplazar. Añadir una columna nueva o una tabla rara vez rompe algo porque el código existente puede seguir leyendo y escribiendo la forma antigua.
Los renombrados y las eliminaciones son movimientos riesgosos. Un rename es efectivamente “añadir nuevo + quitar viejo”, y la parte de “quitar viejo” es donde los clientes antiguos se estrellan. Si necesitas renombrar, trátalo como un cambio en dos pasos: añade el campo nuevo primero, conserva el campo viejo durante un tiempo y elimínalo solo cuando estés seguro de que nadie depende de él.
Al añadir columnas, empieza con campos nullable. Una columna nullable permite que el código antiguo siga insertando filas sin saber del nuevo campo. Si al final quieres NOT NULL, añádelo como nullable primero, haz el backfill y luego impón NOT NULL más adelante. Los defaults también ayudan, pero cuidado: añadir un default puede tocar muchas filas en algunas bases de datos y ralentizar el cambio.
Los índices son otra adición “segura pero no gratis”. Pueden acelerar lecturas, pero construir y mantener un índice puede ralentizar escrituras. Añade índices cuando sepas exactamente qué consulta los usará y considera desplegarlos en horas más tranquilas si la base de datos está ocupada.
Un conjunto de reglas simples para migraciones de base de datos aditivas:
- Añade tablas o columnas nuevas primero, deja las antiguas intactas.
- Haz que los nuevos campos sean opcionales (nullable) hasta que los datos estén llenos.
- Mantén las consultas y payloads antiguos funcionando hasta que los clientes actualicen.
- Retrasa restricciones (NOT NULL, unique, foreign keys) hasta después de los backfills.
Plan de despliegue paso a paso que mantiene a los clientes antiguos funcionando
Trata los cambios de esquema sin tiempo de inactividad como un despliegue gradual, no como un único deploy. El objetivo es dejar que versiones antiguas y nuevas de la app coexistan mientras la base de datos se mueve gradualmente a la nueva forma.
Una secuencia práctica:
- Añade el esquema nuevo de forma compatible. Crea columnas o tablas nuevas, permite nulls y evita restricciones estrictas que el código antiguo no pueda satisfacer. Si necesitas un índice, añádelo de forma que no bloquee escrituras.
- Despliega cambios en el backend que hablen ambos “idiomas”. Actualiza la API para que acepte peticiones viejas y nuevas. Empieza a escribir el campo nuevo mientras mantienes el campo viejo correcto. Esta fase de “escritura dual” es lo que hace seguros los clientes en versiones mixtas.
- Backfill de datos existentes en pequeños lotes. Pobla la columna nueva para filas antiguas gradualmente. Limita el tamaño de los lotes, añade pausas si es necesario y registra el progreso para poder pausar si aumenta la carga.
- Cambia las lecturas solo después de que la cobertura sea alta. Cuando la mayoría de filas estén backfilled y tengas confianza, cambia el backend para preferir el campo nuevo. Mantén una alternativa al campo viejo por un tiempo.
- Elimina el campo viejo al final y solo cuando esté realmente sin uso. Espera a que las versiones antiguas de móviles hayan desaparecido en su mayoría, revisa logs para asegurarte de que no haya lecturas del campo viejo y ten un plan de rollback limpio. Entonces elimina la columna vieja y el código relacionado.
Ejemplo: introduces full_name pero clientes antiguos siguen enviando first_name y last_name. Durante un periodo, el backend puede construir full_name al escribir, backfillear usuarios existentes y luego leer full_name por defecto mientras sigue soportando payloads antiguos. Solo cuando la adopción esté clara eliminas los campos viejos.
Backfills sin sorpresas: cómo poblar datos nuevos con seguridad
Un backfill pobla una columna o tabla nueva para filas existentes. Suele ser la parte más arriesgada porque puede generar carga pesada en la base de datos, locks largos y comportamientos “medio migrados”.
Empieza eligiendo cómo ejecutarás el backfill. Para datasets pequeños, una ejecución manual con un runbook puede bastar. Para datasets grandes, prefiere un worker en background o una tarea programada que pueda ejecutarse repetidamente y detenerse con seguridad.
Segmenta el trabajo por lotes para controlar la presión en la base de datos. No actualices millones de filas en una sola transacción. Busca un tamaño de chunk predecible y una pausa corta entre lotes para que el tráfico normal de usuarios siga fluido.
Un patrón práctico:
- Selecciona un lote pequeño (por ejemplo, las siguientes 1.000 filas) usando una clave indexada.
- Actualiza solo lo que falta (evita reescribir filas ya backfilled).
- Confirma la transacción rápidamente y luego duerme brevemente.
- Registra el progreso (último ID procesado o timestamp).
- Reintenta en fallos sin empezar desde cero.
Haz el job reiniciable. Guarda un marcador de progreso simple en una tabla dedicada y diseña el job para que re-ejecutarlo no corrompa datos. Actualizaciones idempotentes (por ejemplo, UPDATE ... WHERE new_field IS NULL) son tus aliadas.
Valida sobre la marcha. Lleva cuenta de cuántas filas aún faltan por llenar el nuevo valor y añade algunas comprobaciones de cordura: por ejemplo, saldos no negativos, timestamps en rango esperado, estado en un conjunto permitido. Verifica registros reales muestreando.
Decide qué debe hacer la app mientras el backfill esté incompleto. Una opción segura es lecturas de respaldo: si el campo nuevo es null, calcula o lee el valor antiguo. Ejemplo: añades preferred_language. Hasta que el backfill termine, la API puede devolver el idioma existente del perfil cuando preferred_language esté vacío, y solo empezar a exigir el nuevo campo tras finalizar.
Reglas de compatibilidad de API para versiones de cliente mixtas
Rastrea backfills con menos fricción
Crea herramientas internas para monitorizar backfills, progreso y validaciones en un solo lugar.
Cuando lanzas un cambio de esquema, rara vez controlas todos los clientes. Los usuarios web se actualizan rápido, mientras que builds móviles antiguas pueden permanecer activos semanas. Por eso las APIs compatibles hacia atrás importan incluso si la migración de la BD es “segura”.
Trata los datos nuevos como opcionales al principio. Añade campos nuevos en requests y responses, pero no los exijas el primer día. Si un cliente antiguo no envía el campo nuevo, el servidor debe aceptar la petición y comportarse como antes.
Evita cambiar el significado de campos existentes. Renombrar un campo puede ser aceptable si mantienes el nombre antiguo funcionando también. Reutilizar un campo para un nuevo significado es donde ocurren fallos sutiles.
Los defaults del lado servidor son tu red de seguridad. Cuando introduces una columna como preferred_language, asigna un valor por defecto en el servidor cuando falte. La respuesta de la API puede incluir el campo nuevo y los clientes antiguos deben poder ignorarlo.
Reglas de compatibilidad que previenen la mayoría de outages:
- Añade campos nuevos como opcionales al principio y aplícalos forzados después de la adopción.
- Mantén el comportamiento antiguo estable, incluso si añades un comportamiento mejor detrás de una bandera.
- Aplica defaults en el servidor para que clientes antiguos puedan omitir campos nuevos.
- Asume tráfico mixto y prueba ambos caminos: “cliente nuevo lo envía” y “cliente antiguo lo omite”.
- Mantén mensajes y códigos de error estables para que el monitoring no se vuelva ruidoso de repente.
Ejemplo: añades company_size en un flujo de registro. El backend puede poner por defecto “unknown” cuando falta el campo. Clientes nuevos envían el valor real, clientes antiguos siguen funcionando y los dashboards siguen legibles.
Cuando tu app se regenera: mantener esquema y lógica sincronizados
Si tu plataforma regenera la aplicación, obtienes una reconstrucción limpia de código y configuración. Eso ayuda con los cambios de esquema sin tiempo de inactividad porque puedes hacer pasos pequeños, aditivos y redeployar a menudo en lugar de llevar parches meses.
La clave es una única fuente de verdad. Si el esquema cambia en un lugar y la lógica de negocio en otro, la deriva ocurre rápido. Decide dónde se definen los cambios y trata todo lo demás como salida generada.
Nombres claros reducen accidentes durante rollouts por fases. Si introducís un campo nuevo, deja claro cuál es seguro para clientes antiguos y cuál es la nueva vía. Por ejemplo, nombrar una columna status_v2 es más seguro que status_new porque sigue teniendo sentido seis meses después.
Qué re-testear después de cada regeneración
Incluso cuando los cambios son aditivos, una reconstrucción puede revelar acoplamientos ocultos. Después de cada regeneración y deploy, vuelve a comprobar un pequeño conjunto de flujos críticos:
- Registro, login, restablecimiento de contraseña, refresh de token.
- Acciones principales de creación y actualización (las más usadas).
- Comprobaciones de admin y permisos.
- Pagos y webhooks (por ejemplo, eventos de Stripe).
- Notificaciones y mensajería (email/SMS, Telegram).
Planifica los pasos de migración antes de tocar tu editor: añade el campo nuevo, despliega con ambos campos soportados, backfillea, cambia lecturas y luego retira la vía antigua. Esa secuencia mantiene esquema, lógica y código generado moviéndose juntos para que los cambios sean pequeños, revisables y reversibles.
Errores comunes que causan outages (y cómo evitarlos)
Practica migraciones aditivas rápido
Modela un esquema aditivo seguro y regenera tu backend y APIs cuando cambien los requisitos.
La mayoría de outages durante cambios de esquema sin tiempo de inactividad no vienen del trabajo “duro” de la base de datos. Provienen de cambiar el contrato entre la BD, la API y los clientes en el orden equivocado.
Trampas comunes y movimientos más seguros:
- Renombrar una columna mientras el código antiguo aún la lee. Mantén la columna antigua, añade la nueva y mapea ambas por un tiempo (escribe en las dos o usa una vista). Renombra solo cuando puedas demostrar que nadie depende del nombre antiguo.
- Hacer obligatorio un campo nullable demasiado pronto. Añade la columna como nullable, lanza código que la escriba en todos lados, backfillea filas antiguas y luego impón NOT NULL con una migración final.
- Hacer el backfill en una única transacción masiva que bloquee tablas. Backfillea en pequeños lotes con límites y pausas. Registra el progreso para poder reanudar con seguridad.
- Cambiar lecturas antes de que las escrituras produzcan el dato nuevo. Cambia escrituras primero, luego backfill y después lecturas. Si las lecturas cambian primero, obtendrás pantallas vacías, totales erróneos o errores de “campo faltante”.
- Eliminar campos viejos sin prueba de que los clientes antiguos desaparecieron. Mantén campos viejos más tiempo del que crees. Elimina solo cuando las métricas muestren versiones antiguas inactivas y hayas comunicado una ventana de deprecación.
Si regenera tu app, es tentador “limpiar” nombres y restricciones de una vez. Resiste esa tentación. La limpieza es el paso final, no el primero.
Una buena regla: si un cambio no puede desplegarse hacia adelante y hacia atrás de forma segura, no está listo para producción.
Monitorización y planificación de rollback para migraciones por fases
Mantén el esquema y el código alineados
Regenera código fuente limpio a medida que evoluciona tu esquema, sin arrastrar parches desordenados.
Los cambios de esquema sin tiempo de inactividad se ganan o se pierden por dos cosas: qué vigilas y lo rápido que puedes parar.
Mide señales que reflejen impacto real en usuarios, no solo “el deploy terminó”:
- Tasa de errores de la API (picos 4xx/5xx en endpoints actualizados).
- Consultas lentas (p95 o p99 para las tablas tocadas).
- Latencia de escritura (tiempo de inserts/updates en tráfico pico).
- Profundidad de colas (jobs acumulándose para backfills o procesamiento de eventos).
- Presión de CPU/IO de la base de datos (cualquier salto tras el cambio).
Si haces escrituras duales, añade logging temporal que compare ambas. Manténlo selectivo: registra solo cuando difieran, incluye ID del registro y un código de razón corto, y muestrea si el volumen es alto. Crea un recordatorio para eliminar este logging después de la migración para que no sea ruido permanente.
El rollback debe ser realista. La mayoría de las veces no reviertes el esquema: reviertes el código y mantienes el esquema aditivo en su sitio.
Un runbook práctico de rollback:
- Revertir la lógica de la aplicación a la última versión conocida buena.
- Desactivar nuevas lecturas primero y luego nuevas escrituras.
- Mantener tablas o columnas nuevas, pero dejar de usarlas.
- Pausar backfills hasta que las métricas se estabilicen.
Para los backfills, crea un interruptor de parada que puedas accionar en segundos (feature flag, valor de config, pausa del job). También comunica las fases con antelación: cuándo empiezan las escrituras duales, cuándo corre el backfill, cuándo cambian las lecturas y qué significa “parar” para que nadie improvise bajo presión.
Lista rápida previa al despliegue
Justo antes de lanzar un cambio de esquema, párate y corre esta verificación rápida. Atrapa suposiciones pequeñas que se vuelven outages con versiones de cliente mixtas.
- El cambio es aditivo, no destructivo. La migración añade tablas, columnas o índices solo. Nada se elimina, renombra o endurece de forma que pueda rechazar escrituras antiguas.
- Las lecturas funcionan con cualquiera de las formas. El código nuevo maneja tanto “campo nuevo presente” como “campo nuevo ausente” sin errores. Los valores opcionales tienen defaults seguros.
- Las escrituras siguen siendo compatibles. Clientes nuevos pueden enviar datos nuevos y clientes antiguos pueden seguir enviando payloads antiguos y tener éxito. Si deben coexistir, el servidor acepta ambos formatos y produce respuestas que los clientes antiguos entiendan.
- El backfill es seguro para detener y arrancar. El job corre en lotes, reinicia sin duplicar o corromper datos y tiene un número medible de “filas restantes”.
- Sabes la fecha de eliminación. Existe una regla concreta de cuándo es seguro eliminar campos o lógica heredada (por ejemplo, después de X días más confirmación de que Y% de peticiones vienen de clientes actualizados).
Si usas una plataforma que regenera, añade una comprobación más: genera y despliega un build desde el modelo exacto que vas a migrar y confirma que la API y la lógica generadas aún toleran registros antiguos. Un fallo común es asumir que el nuevo esquema implica lógica nueva obligatoria.
También escribe dos acciones rápidas que harás si algo va mal tras el deploy: qué monitorizar (errores, timeouts, progreso del backfill) y qué revertirás primero (apagar feature flag, pausar backfill, revertir release del servidor). Eso convierte “reaccionaremos rápido” en un plan real.
Ejemplo: añadir un campo nuevo mientras clientes móviles antiguos siguen activos
Diseña APIs compatibles hacia atrás
Crea APIs que acepten payloads viejos y nuevos mientras haces la transición de campos.
Tienes una app de pedidos. Necesitas un campo nuevo, delivery_window, que será obligatorio para nuevas reglas de negocio. El problema es que builds antiguas de iOS y Android siguen en uso y no enviarán ese campo por días o semanas. Si haces que la BD lo requiera de inmediato, esos clientes empezarán a fallar.
Un camino seguro:
- Fase 1: Añade la columna como nullable, sin restricciones. Mantén lecturas y escrituras existentes.
- Fase 2: Escritura dual. Clientes nuevos (o el backend) escriben el campo nuevo. Los clientes antiguos siguen funcionando porque la columna permite null.
- Fase 3: Backfill. Pobla
delivery_window para filas antiguas usando una regla (inferir por método de envío, o por defecto “cualquier momento” hasta que el cliente lo edite).
- Fase 4: Cambia lecturas. Actualiza la API y la UI para leer
delivery_window primero, pero usar el valor inferido cuando falte.
- Fase 5: Imponer más tarde. Tras adopción y backfill completos, añade NOT NULL y quita la alternativa.
Lo que los usuarios notan en cada fase debe ser aburrido (ese es el objetivo):
- Usuarios móviles antiguos todavía pueden hacer pedidos porque la API no rechaza datos faltantes.
- Usuarios nuevos ven el campo nuevo y sus elecciones se guardan consistentemente.
- Soporte y ops ven el campo rellenarse gradualmente, sin brechas repentinas.
Una puerta de monitorización simple para cada paso: mide el porcentaje de pedidos nuevos con delivery_window no nulo. Cuando se mantiene alto de forma consistente (y los errores de validación por “campo faltante” están cerca de cero), suele ser seguro pasar de backfill a imponer la restricción.
Próximos pasos: crea un playbook de migración repetible
Un despliegue cuidadoso único no es una estrategia. Trata los cambios de esquema como una rutina: mismos pasos, mismo nombrado, mismas aprobaciones. Así el siguiente cambio aditivo sigue siendo aburrido, incluso cuando la app está ocupada y los clientes en versiones distintas.
Mantén el playbook corto. Debe responder: qué añadimos, cómo lo desplegamos de forma segura y cuándo eliminamos lo antiguo.
Una plantilla simple:
- Solo añadir (columna/tabla/índice nuevo, campo API nuevo opcional).
- Despliega código que lea ambas formas, antigua y nueva.
- Backfill en pequeños lotes con una señal clara de “hecho”.
- Cambia el comportamiento con una feature flag o config, no con un redeploy.
- Elimina campos/endpoint viejos solo después de una fecha límite y verificación.
Empieza con una tabla de bajo riesgo (un estado opcional nuevo, un campo de notas) y ejecuta todo el playbook: cambio aditivo, backfill, clientes en versiones mixtas y limpieza. Esa práctica revela huecos en monitorización, batching y comunicación antes de intentar un rediseño mayor.
Un hábito que evita desorden a largo plazo: trata los ítems “eliminar más tarde” como trabajo real. Cuando añades una columna temporal, código de compatibilidad o lógica de escritura dual, crea de inmediato un ticket de limpieza con un propietario y una fecha. Mantén una nota de “deuda de compatibilidad” en los documentos de release para que siga visible.
Si construyes con AppMaster, puedes tratar la regeneración como parte del proceso de seguridad: modela el esquema aditivo, actualiza la lógica de negocio para manejar ambos campos durante la transición y regenera para que el código fuente se mantenga limpio a medida que cambian los requisitos. Si quieres ver cómo encaja este flujo en un entorno no-code que aún produce código real, AppMaster (appmaster.io) está diseñado alrededor de este estilo de entrega iterativa y por fases.
El objetivo no es la perfección. Es la repetibilidad: cada migración tiene un plan, una medición y una rampa de salida.
FAQ
Zero-downtime significa que los usuarios pueden seguir trabajando con normalidad mientras cambias el esquema y despliegas código. Eso incluye evitar caídas obvias, pero también evitar fallos silenciosos como pantallas en blanco, valores erróneos, procesos en background que fallan o escrituras bloqueadas por migraciones largas.
Porque muchas partes del sistema dependen de la forma de la base de datos, no solo la interfaz principal. Jobs en background, informes, scripts administrativos, integraciones y apps móviles antiguas pueden seguir enviando o esperando campos antiguos mucho tiempo después del despliegue.
Las versiones antiguas de las apps móviles pueden permanecer en uso semanas, y algunos clientes reintentan peticiones antiguas más tarde. Tu API debe aceptar payloads tanto antiguos como nuevos durante un tiempo para que las versiones mixtas coexistan sin errores.
Los cambios aditivos normalmente no rompen el código existente porque el esquema antiguo sigue estando disponible. Los renombrados y las eliminaciones son riesgosos porque quitan algo que los clientes antiguos aún leen o escriben, lo que provoca fallos o peticiones erróneas.
Añade la columna como nullable primero para que el código antiguo pueda seguir insertando filas. Haz backfill de las filas existentes en lotes y, solo cuando la cobertura sea alta y las escrituras nuevas sean consistentes, aplica NOT NULL como paso final.
Trátalo como un despliegue gradual: añade un esquema compatible, despliega código que soporte ambas versiones, rellena datos en pequeños lotes, cambia lecturas con una alternativa de respaldo y elimina el campo antiguo solo cuando puedas probar que no se usa. Cada paso debe ser seguro por sí mismo.
Ejecuta el backfill en pequeños lotes con transacciones cortas para no bloquear tablas ni generar picos de carga. Hazlo reiniciable e idempotente actualizando solo filas que faltan el nuevo valor y registra el progreso para pausar y reanudar con seguridad.
Haz los nuevos campos opcionales al principio y aplica valores por defecto en el servidor cuando falten. Mantén el comportamiento antiguo estable, evita cambiar el significado de campos existentes y prueba ambos caminos: “el cliente nuevo lo envía” y “el cliente antiguo lo omite”.
La mayoría de las veces se revierte el código de la aplicación, no el esquema. Mantén las columnas/tablas aditivas, desactiva nuevas lecturas primero y luego las nuevas escrituras, y pausa los backfills hasta que las métricas se estabilicen para recuperarte sin pérdida de datos.
Vigila señales que reflejen el impacto real en usuarios: tasas de error, consultas lentas (p95/p99), latencia de escrituras, profundidad de colas, y CPU/IO de la BD. Avanza de fase solo cuando veas métricas estables y alta cobertura del nuevo campo; programa la limpieza como trabajo real, no como “luego”.