22 feb 2025·8 min de lectura
UX del historial de cambios a nivel de campo para diferencias en el panel de administración
El historial de cambios por campo en un panel de administración debe ser fácil de escanear, filtrar y restaurar. Patrones de UX y esquema para diffs, eventos y acciones.
Por qué se ignora el historial de cambios en paneles de administración
La mayoría de los usuarios de administración no ignoran el historial porque no les importe. Lo ignoran porque requiere demasiada atención para poco beneficio. Cuando un cliente espera o un pedido está bloqueado, nadie tiene tiempo para leer una larga lista gris de eventos “actualizado”.
Un historial legible a nivel de campo se gana su lugar cuando responde las preguntas que la gente ya tiene:
- ¿Quién hizo el cambio (y desde dónde, si importa)?
- ¿Qué cambió (nombre del campo más antes y después)?
- ¿Cuándo sucedió (y en qué zona horaria)?
- ¿Por qué sucedió (una razón, ticket, nombre de automatización o al menos una pista)?
La mayoría de los registros fallan al menos en uno de estos puntos. El modo de fallo más común es el ruido: cada guardado crea 20 entradas, jobs en segundo plano escriben timestamps inofensivos cada minuto y los procesos del sistema parecen iguales a las acciones humanas. Los diffs suelen ser vagos también. Ves “estado cambiado” pero no “Pendiente -> Aprobado”, o te muestran un blob de JSON sin pista de qué mirar.
La falta de contexto remata la faena. No puedes saber qué flujo de trabajo disparó un cambio, si fue manual o automatizado, o por qué dos campos cambiaron juntos.
El resultado es predecible. Los equipos dejan de confiar en la pista de auditoría y pasan a adivinar, preguntar o rehacer trabajo. Eso se vuelve peligroso en cuanto añades acciones de restauración.
Un buen historial reduce el tiempo de soporte, evita errores repetidos y hace que las restauraciones se sientan seguras porque los usuarios pueden verificar antes y después rápidamente. Trata la UI de auditoría como una característica principal, no como una pantalla de depuración, y diseñala para escanear bajo presión.
Empieza con los trabajos por hacer
Un historial legible empieza con una decisión: quién lo va a usar cuando algo sale mal. “Todo el mundo” no es un rol. En muchos paneles de administración, la misma vista de auditoría se impone a soporte, ops y managers, y al final no sirve a ninguno.
Elige tus roles principales y qué deben resolver al usarlo:
- Soporte necesita una historia clara para contar al cliente.
- Ops necesita detectar patrones y capturar errores de proceso rápido.
- Finanzas necesita evidencia para aprobaciones, reembolsos y contracargos.
- Managers necesitan responsabilidad sin ahogarse en detalles.
Define las tareas principales que tu historial debe soportar:
- Investigar qué cambió, cuándo y por quién
- Explicar el cambio en lenguaje claro a un cliente o compañero
- Deshacer un error de forma segura (restaurar un valor previo)
- Exportar o conservar prueba para cumplimiento y auditorías
A continuación, decide qué vas a rastrear y explícitalo. Un historial a nivel de campo sólido suele incluir ediciones de campos, transiciones de estado y acciones clave de flujo de trabajo (como “aprobado”, “bloqueado”, “reembolsado”). Muchos equipos también incluyen subidas y eliminaciones de archivos, cambios de permisos y actualizaciones disparadas por integraciones. Si no registras algo, los usuarios asumen que el sistema lo está ocultando.
Finalmente, define las reglas de restauración desde el principio. Restaurar debería permitirse solo cuando sea seguro y significativo. Restaurar una dirección de envío puede estar bien. Restaurar un estado “pagado” puede estar bloqueado una vez que se haya procesado un pago. Explica la razón del bloqueo en la UI (“Restauración desactivada: reembolso ya emitido”).
Un escenario rápido: un cliente afirma que su plan fue degradado sin permiso. Soporte necesita ver si fue un agente, el cliente o una regla de facturación automatizada, y si se permite restaurar. Diseña pensando en esa historia y las decisiones de UI serán mucho más fáciles.
Patrones de modelo de datos para eventos de auditoría
Si tu modelo de datos es desordenado, tu historial también lo será. La UI solo puede ser tan clara como los registros que la respaldan.
Evento vs snapshot
Un modelo de eventos almacena solo lo que cambió (campo, antes, después). Un modelo de snapshot guarda el registro completo después de cada edición. Para paneles de administración, a menudo funciona mejor un híbrido: mantén eventos como fuente de la verdad y, opcionalmente, guarda un snapshot ligero para vistas rápidas o restauraciones.
Los eventos responden qué cambió, quién lo hizo y cuándo. Los snapshots ayudan cuando los usuarios necesitan una vista rápida del “estado en el tiempo X” o cuando debes restaurar varios campos juntos.
Lo mínimo que deberías registrar
Mantén cada registro de cambio pequeño, pero lo bastante completo para explicarse después. Un mínimo práctico:
- actor_id (y actor_type como user, system, integration)
- occurred_at (timestamp en UTC)
- entity_type + entity_id (qué se editó)
- field_key (estable, no una etiqueta de presentación)
- before_value + after_value (almacenar como texto o JSON, más un data_type)
Para responder “¿por qué pasó esto?”, añade contexto opcional. Un comentario corto suele ser suficiente, pero las referencias estructuradas son mejores cuando las tienes: ticket_id, workflow_run_id, import_batch_id, o una automated_reason como “nightly sync”.
Agrupa ediciones multi‑campo en un change set
La gente casi nunca piensa en campos aislados. Piensan “actualicé la dirección del cliente” aunque cambien cinco campos. Modélalo con un change_set_id que ate múltiples eventos de campo.
Un patrón simple:
- Una fila change_set por cada acción de guardado
- Muchas filas field_change que apuntan a ese change_set
- Una razón/comentario compartido en el change_set (no repetida por campo)
Esto permite que la UI muestre una entrada legible por guardado, con opción de expandir para ver cada diff de campo.
Patrones de diseño que la gente puede escanear rápido
Un buen historial pertenece donde surge la pregunta: en la pantalla de detalle del registro. Una pestaña “Historial” junto a “Detalles” y “Notas” mantiene a la gente en contexto para confirmar qué cambió sin perder el hilo.
Una página de auditoría separada sigue teniendo su lugar. Úsala cuando la tarea implique búsqueda entre registros (por ejemplo, “muéstrame cada cambio de precio hecho por Kim ayer”) o cuando los auditores necesiten exportaciones. Para el trabajo cotidiano de soporte y ops, el historial a nivel de registro gana.
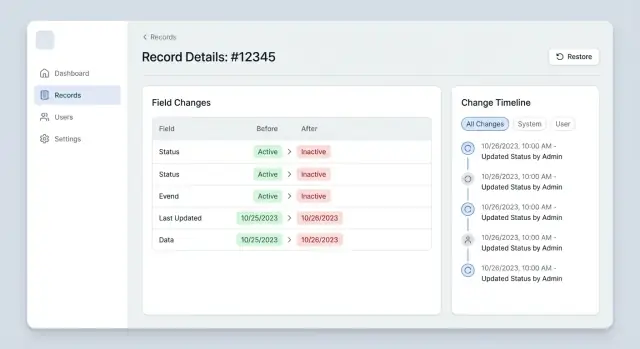
La vista por defecto debe responder cuatro preguntas de un vistazo: qué cambió, quién lo hizo, cuándo pasó y si fue parte de una edición mayor. Ordenar de más nuevo a más antiguo es esperado, pero agrupar por sesión de edición es lo que lo hace legible: un ítem por acción de guardado, con los campos cambiados dentro.
Para mantener el escaneo rápido, muestra solo lo que cambió. No reimprimas todo el registro. Eso convierte el historial en ruido y hace más difícil detectar los cambios reales.
Una tarjeta de evento compacta suele funcionar bien:
- Cabecera: nombre (o etiqueta del sistema) y timestamp exacto
- Etiqueta de origen: Edición manual, Importación, API, Automatización
- Campos cambiados: una línea por campo con valores antiguo y nuevo
- “Mostrar más” para texto largo
- Campos importantes fijados arriba (estado, responsable, precio)
Haz que “quién lo hizo” y “cuándo” sean visualmente destacados, no enterrados. Usa alineación consistente y un formato de timestamp único.
Diffs de antes y después que siguen siendo legibles
Haz filtros de auditoría que la gente use
Añade filtros por campo, actor y origen que mantengan el ruido opcional.
La gente abre el historial cuando algo parece mal. Si el diff es difícil de escanear, se rinden y preguntan a un compañero. Los buenos diffs hacen el cambio obvio de un vistazo y detallado con un clic.
Para la mayoría de campos, inline funciona mejor: muestra Antes -> Después en una línea, con solo la parte cambiada resaltada. Lado a lado es útil cuando los valores son largos (como direcciones) o cuando los usuarios necesitan comparar varias partes a la vez, pero ocupa más espacio. Una regla simple: por defecto inline, cambia a lado a lado solo cuando el ajuste de línea oculta lo que cambió.
El texto largo requiere cuidado extra. Mostrar un párrafo diffs dentro de una lista densa hace que todo parezca ruido. Muestra un extracto corto (120–200 caracteres) y un control Expandir que revela el valor completo. Al expandir, preserva los saltos de línea. Usa fuente monoespaciada solo para contenido genuinamente parecido a código y resalta solo los fragmentos cambiados para que el ojo tenga un ancla.
Los números, moneda y fechas a menudo parecen “sin cambios” aunque no lo estén. Cuando importe, muestra tanto el valor bruto como el formato que ve el usuario. Por ejemplo, “10000” -> “10,000.00 USD” puede ser un cambio real (precisión y moneda), no solo presentación.
Los enums y estados son otra trampa. La gente reconoce etiquetas, mientras que los sistemas usan códigos internos. Muestra la etiqueta primero y el valor interno solo cuando soporte o cumplimiento lo necesite.
Patrones prácticos de diff que se pueden escanear
- Inline: Antes -> Después, resalta solo la parte editada
- Lado a lado: dos columnas para campos largos o multipartes
- Texto largo colapsado: extracto con Expand, preservar saltos de línea al abrir
- Formato tipado: muestra valor más su formato (zona horaria, moneda, precisión)
- Estado/enums: etiqueta más código interno opcional
Filtros que reducen el ruido sin ocultar hechos
La mayoría abre el historial solo cuando algo anda mal. Si la primera pantalla muestra 300 ediciones diminutas, la cerrarán. Los buenos filtros hacen dos cosas: cortan el ruido rápido y mantienen la verdad completa a un clic.
Empieza con un conjunto pequeño y predecible de filtros:
- Rango de tiempo (última hora, 24 horas, 7 días, personalizado)
- Actor (una persona, una cuenta de servicio, desconocido)
- Campo (estado, precio, dirección, permisos)
- Tipo de cambio (creado, actualizado, limpiado, restaurado)
- Origen (acción de usuario vs automatización/import/API)
Los valores por defecto importan más que controles sofisticados. Un buen valor por defecto es “Campos importantes” y “Últimos 7 días”, con una opción clara para expandir a “Todos los campos” y rangos más largos. Un interruptor simple “Mostrar ruido” funciona para cosas como last_seen_at, ediciones menores de formato o totales auto‑calculados. El objetivo no es ocultar hechos; es mantenerlos fuera del camino hasta que sean necesarios.
La búsqueda dentro del historial a menudo es la forma más rápida de confirmar una sospecha. Hazla tolerante: permite coincidencias parciales, ignora mayúsculas y busca en nombre de campo, nombre del actor y valores mostrados. Si alguien escribe “reembolso”, debe ver notas, cambios de estado y actualizaciones de pago sin adivinar dónde vive cada cosa.
Las vistas de filtro guardadas ayudan en investigaciones repetidas. Los equipos de soporte ejecutan las mismas comprobaciones en cada ticket. Mantén unas pocas y amigables por rol (por ejemplo, “Solo campos de cara al cliente” o “Cambios por automatización”).
Acciones de restauración que se sienten seguras
Lanza herramientas administrativas con lógica
Construye backend, admin web y herramientas móviles juntos sin escribir todo a mano.
Un botón de restaurar solo ayuda si la gente confía en él. Restaurar debe sentirse como una edición cuidadosa y visible, no una máquina del tiempo mágica.
Muestra la restauración donde la intención sea clara. Para campos simples (estado, plan, asignado), una restauración por campo funciona bien porque el usuario entiende exactamente qué cambiará. Para ediciones mult‑campo (bloque de dirección, conjunto de permisos, datos de facturación), prefiere restaurar todo el change set, u ofrece “restaurar todo de esta edición” junto a restauraciones individuales. Esto evita medias‑restauraciones que crean combinaciones extrañas.
Haz el impacto explícito antes de que ocurra cualquier cosa. Una buena confirmación de restauración nombra el registro, el campo y los valores exactos, y muestra qué será modificado.
- Requiere el permiso adecuado (separado de “editar”) y muestra quién puede hacerlo.
- Confirma con valores exactos antes y después.
- Advierte sobre efectos secundarios (por ejemplo, restaurar un email puede disparar una notificación).
- Ofrece un flujo seguro: previsualizar primero, luego aplicar.
Los conflictos son donde se rompe la confianza, así que trátalos con calma. Si el campo cambió de nuevo después del evento que quieres restaurar, no sobrescribas a ciegas.
Manejo de conflictos
Cuando el valor actual difiere del valor “after” del evento, muestra una vista corta de comparación: “Intentas restaurar a X, pero el valor actual es Y.” Luego ofrece acciones como restaurar de todos modos, copiar el valor antiguo o cancelar. Si encaja en tu flujo, incluye un cuadro de motivo para que la restauración tenga contexto.
Nunca borres historial al restaurar. Registra la restauración como un nuevo evento con atribución clara: quién restauró, cuándo y de qué evento provino.
Paso a paso: implementar un historial legible de extremo a extremo
Añade acciones de restauración seguras
Previsualiza valores antes y después y registra las restauraciones como nuevos eventos.
Puedes construir un historial en el que la gente confíe si tomas unas decisiones desde el principio y las mantienes consistentes entre UI, API y automatizaciones.
Un 5‑pasos práctico para construir
- Paso 1: Elige las entidades que realmente necesitan historial. Empieza con objetos que provocan disputas o riesgo monetario: usuarios, pedidos, precios, permisos. Si no puedes responder “¿Quién cambió esto y cuándo?” para estos, soporte y finanzas lo notarán primero.
- Paso 2: Define tu esquema de evento y qué cuenta como un change set. Decide si un guardado es un evento que puede incluir muchas ediciones de campo. Almacena tipo/ID de entidad, actor (usuario o sistema), origen (UI admin, API, automatización), timestamp y la lista de campos cambiados con valores antes/después.
- Paso 3: Captura cambios de la misma forma en todas partes. Las ediciones desde la UI son fáciles. Lo difícil son las llamadas API y los jobs en background. Centraliza el auditing en un solo lugar (capa de servicio o lógica de negocio) para no olvidar caminos.
- Paso 4: Construye la UI de historial en la página del registro y el conjunto de filtros juntos. Empieza con una lista inverso‑cronológica donde cada ítem muestra quién, cuándo y un corto resumen “cambió 3 campos”. Los filtros deben coincidir con preguntas reales: por campo, por actor, por origen y “mostrar solo cambios importantes”.
- Paso 5: Añade restauración con permisos estrictos y logging extra. Restaurar es un cambio nuevo, no una máquina del tiempo. Cuando un usuario restaura un valor, crea un evento de auditoría fresco que capture quién lo hizo, qué cambió y (opcionalmente) por qué.
Antes de lanzar, prueba un escenario realista: un agente de soporte abre un pedido, filtra a campos de precio, ve un único guardado que cambió subtotal, descuento e impuesto, y luego restaura solo el descuento. Si ese flujo se entiende sin explicación, tu historial será usado.
Errores comunes y trampas
La mayoría de las vistas de historial fallan por una razón simple: no respetan la atención. Si el registro es ruidoso o confuso, la gente deja de usarlo y vuelve a adivinar.
Una trampa común es registrar demasiado. Si guardas cada pulsación, tick de sincronización o actualización automática, la señal desaparece. El personal no puede detectar el cambio que importaba. Registra commits significativos: “Estado cambiado”, “Dirección actualizada”, “Límite incrementado”, no “Usuario tecleó A, luego B”.
Registrar muy poco es igual de dañino. Un historial sin actor, sin timestamp, sin razón o sin valor anterior no es historial. Es un rumor.
Las etiquetas también pueden romper la confianza silenciosamente. Nombres crudos de BD (como cust_id), IDs internas o valores de enum crípticos obligan al personal no técnico a interpretar el sistema en vez del evento. Usa etiquetas humanas (“Cliente”, “Plan”, “Dirección de envío”) y muestra nombres amigables junto a IDs solo cuando haga falta.
Errores que más matan la usabilidad:
- Tratar el ruido del sistema como eventos de primera clase (syncs, heartbeats, auto‑cálculos)
- Almacenar cambios sin contexto (falta actor, razón, origen como API vs UI)
- Mostrar claves técnicas de campo en vez de palabras que entiende el usuario
- Mezclar cambios no relacionados en un solo blob, dificultando el escaneo
- Ocultar eventos importantes con filtros agresivos o por defecto
Las acciones de restauración son la zona de mayor riesgo. Un undo de un clic se siente rápido hasta que rompe otra cosa (pagos, permisos, inventario). Haz que las restauraciones se sientan seguras:
- Confirma siempre y muestra exactamente qué se revertirá
- Advierte sobre efectos secundarios (reglas disparadas, campos dependientes recalculados)
- Exige una nota de motivo para campos sensibles
- Muestra qué pasó después de restaurar (un nuevo evento, no ediciones silenciosas)
Lista de verificación rápida para un buen historial de cambios
Reduce el tiempo de soporte con historial
Da a los agentes quién‑qué‑cuándo en una sola pantalla para cerrar tickets más rápido.
Un buen historial es el que tu equipo de soporte puede usar mientras el cliente sigue en la llamada. Si tarda más de unos segundos en responder “qué cambió, cuándo y por quién?”, la gente deja de abrirlo.
- Prueba de respuesta en 10 segundos: Desde la primera pantalla, ¿puede alguien señalar la entrada exacta que explica qué cambió, mostrando valores antiguo y nuevo sin clicks extra?
- Atribución clara siempre: Cada evento muestra quién lo hizo (usuario nombrado) o qué lo hizo (sistema, importación, automatización), más un timestamp legible y la zona horaria del usuario si procede.
- Filtrado rápido sin adivinar: Los filtros facilitan saltar a un campo y a una ventana temporal estrecha (por ejemplo, Estado + últimos 7 días), y la UI muestra cuántos resultados quedan.
- Restaurar se siente seguro, no temible: Restaurar visible solo para roles adecuados, requiere confirmación que nombra el campo y el valor exacto que vas a restaurar, y advierte si sobrescribirá un cambio más reciente.
- Las restauraciones se registran como eventos reales: Una restauración crea un nuevo registro de auditoría (no una reversión oculta) que captura quién restauró, qué valor se restauró y qué valor reemplazó.
Una forma práctica de validar esto es un pequeño simulacro de “disputa de soporte”. Elige un registro con muchas ediciones y pregunta a un compañero: “¿Por qué el cliente ve una dirección de envío distinta que ayer?” Si pueden filtrar a Dirección, ver el diff antes/después e identificar al actor en menos de 10 segundos, estás cerca.
Ejemplo: resolver una disputa de soporte con historial de auditoría
Un cliente abre un ticket: “Mi total de factura cambió después de aplicar un descuento. Me cobraron de más.” Aquí el historial por campo ahorra tiempo, pero solo si es legible y accionable.
En el registro de la factura, el agente de soporte abre la pestaña Historial y reduce el ruido primero. Filtra a los últimos 7 días y selecciona los campos Descuento y Total. Luego filtra por actor para mostrar solo cambios hechos por un usuario interno (no el cliente ni una automatización).
La línea de tiempo ahora muestra tres entradas claras:
- 2026-01-18 14:12, Actor: Sales Rep, Campo: Descuento, 10% -> 0%, Razón: “Promo expired”
- 2026-01-18 14:12, Actor: System, Campo: Total, $90 -> $100, Razón: “Recalculated from line items”
- 2026-01-18 14:13, Actor: Sales Rep, Comentario: “Customer requested removal”
La historia es obvia: se eliminó el descuento y el total se recalculó inmediatamente. El agente puede ahora confirmar si la eliminación fue correcta revisando el comentario y las reglas de la promo.
Si fue un error, el agente usa un flujo de restauración seguro en el campo Descuento. La UI previsualiza lo que cambiará (Descuento de vuelta a 10%, Total recalculado) y pide una nota.
- Clic en Restaurar junto a “Descuento: 10% -> 0%”
- Añadir comentario: “Restaurado descuento según ticket #18421. Promo aún válida.”
- Confirmar y notificar al equipo de facturación (y opcionalmente al cliente)
Si construyes un panel de administración con una plataforma no‑code como AppMaster (appmaster.io), puedes modelar las tablas de auditoría en PostgreSQL, centralizar las escrituras de auditoría en Business Processes, y reutilizar los mismos patrones de UI de historial en web y móvil para que la historia sea consistente allí donde trabaje tu equipo.
FAQ
La mayoría de las personas lo ignoran porque es difícil de escanear y está lleno de ruido de poco valor. Haz que cada entrada responda cuatro cosas de inmediato: quién lo hizo, qué cambió con valores antes/después, cuándo pasó en un formato consistente y por qué o desde qué origen ocurrió.
Registra compromisos significativos, no cada pequeño cambio. Sigue ediciones de campos, transiciones de estado y acciones clave de flujo de trabajo, y etiqueta claramente si el actor fue una persona, una automatización, una importación o una llamada API para que el ruido del sistema no parezca comportamiento humano.
Empieza con un modelo de eventos que guarde solo lo que cambió y, opcionalmente, añade snapshots ligeros si necesitas ver rápidamente el “estado en el tiempo X” o restaurar por lotes. Un híbrido suele ser lo mejor: eventos para la verdad y legibilidad, snapshots para rendimiento y restauraciones multi‑campo.
Un mínimo práctico es la identidad y tipo del actor, timestamp en UTC, tipo de entidad e ID, una clave de campo estable, y valores antes/después con un tipo de dato. Añade contexto opcional como comentario, workflow_run_id, import_batch_id o una razón de automatización para poder responder el “por qué” más adelante.
Usa un change_set ID para agrupar todos los cambios de campo de un mismo guardado o ejecución de workflow. Así la UI puede mostrar una entrada legible como “Se cambiaron 5 campos” con opción de expandir, en lugar de saturar la línea de tiempo con 20 filas separadas.
Por defecto usa inline de antes‑y‑después en una línea, y cambia a lado a lado solo cuando el ajuste de texto o el envolvimiento ocultan la diferencia significativa. Para textos largos, muestra un extracto corto por defecto y expande a demanda preservando saltos de línea para mantener la legibilidad.
Almacena timestamps en UTC y elige un formato único para mostrarlos; al presentar, conviértelos a la zona horaria del usuario si hace falta. Si los equipos trabajan en varias zonas, muestra la etiqueta de zona junto a la hora para que el “cuándo” sea inequívoco en llamadas de soporte.
Empieza con un conjunto pequeño que responda preguntas reales: rango de tiempo, actor, campo, tipo de cambio y origen (manual vs automatización/import/API). Un valor por defecto útil es “últimos 7 días” más “campos importantes” y deja claro cómo revelar todo cuando sea necesario.
Trata la restauración como una edición nueva y visible con permisos estrictos y una vista previa clara de lo que cambiará. Si el valor actual difiere del valor “after” del evento que restauras, muestra el conflicto y exige una elección deliberada para no sobrescribir trabajo más reciente de forma silenciosa.
Centraliza las escrituras de auditoría en un solo lugar para que las ediciones desde UI, llamadas API y jobs en segundo plano registren de la misma forma. En AppMaster (appmaster.io) puedes modelar tablas de auditoría en PostgreSQL, escribir eventos de auditoría desde Business Processes y reutilizar los mismos patrones de UI de historial en web y móvil para mantener la historia consistente donde trabaje tu equipo.