31 ago 2025·8 min de lectura
Temporizadores SLA y escalaciones: modelado de flujo de trabajo mantenible
Aprende a modelar temporizadores SLA y escalaciones con estados claros, reglas mantenibles y rutas de escalación simples para que las apps de flujo de trabajo sean fáciles de cambiar.
Por qué las reglas basadas en tiempo se vuelven difíciles de mantener
Las reglas basadas en tiempo suelen empezar simples: “Si un ticket no tiene respuesta en 2 horas, notifica a alguien.” Luego el flujo crece, los equipos añaden excepciones y de pronto nadie está seguro de qué pasa. Así es como los temporizadores SLA y las escalaciones se convierten en un laberinto.
Ayuda nombrar las piezas móviles con claridad.
Un temporizador es el reloj que inicias (o programas) tras un evento, como “ticket cambiado a Waiting for Agent”. Una escalación es lo que haces cuando ese reloj alcanza un umbral, por ejemplo notificar a un líder, cambiar la prioridad o reasignar trabajo. Un breach es el hecho registrado que dice “fallamos el SLA”, que usas para informes, alertas y seguimiento.
Los problemas aparecen cuando la lógica de tiempo está esparcida por la app: algunos chequeos en el flujo de “actualizar ticket”, más chequeos en un job nocturno y reglas puntuales añadidas después para un cliente especial. Cada pieza tiene sentido por sí sola, pero juntas crean sorpresas.
Síntomas típicos:
- El mismo cálculo de tiempo se copia en varios flujos y las correcciones no llegan a todas las copias.
- Se pierden casos límite (pausa, reanudar, reasignación, cambios de estado, fines de semana vs horas laborales).
- Una regla se dispara dos veces porque dos caminos programaron temporizadores similares.
- Auditar se vuelve adivinanza: no puedes responder “¿por qué esto se escaló?” sin leer toda la app.
- Los pequeños cambios se sienten riesgosos, así que los equipos añaden excepciones en lugar de arreglar el modelo.
El objetivo es un comportamiento predecible que siga siendo fácil de cambiar más adelante: una fuente de verdad clara para el tiempo del SLA, estados de breach explícitos que puedas reportar y pasos de escalación que puedas ajustar sin buscar por toda la lógica visual.
Empieza definiendo el SLA que realmente necesitas
Antes de construir temporizadores, escribe la promesa exacta que estás midiendo. Mucha lógica desordenada viene de intentar cubrir todas las reglas de tiempo desde el día uno.
Tipos de SLA comunes suenan parecido pero miden cosas diferentes:
- Primera respuesta: tiempo hasta que una persona envía la primera respuesta significativa.
- Resolución: tiempo hasta que el problema está verdaderamente cerrado.
- Esperando al cliente: tiempo que no quieres contar mientras estás bloqueado.
- Handoff interno: tiempo que un ticket puede permanecer en una cola específica.
- SLA de reapertura: qué pasa cuando un ítem “cerrado” vuelve.
Luego decide qué significa “tiempo”. Tiempo calendario cuenta 24/7. Tiempo laboral cuenta sólo horas de negocio definidas (por ejemplo, lun-vie, 9-18). Si no necesitas realmente tiempo laboral, evítalo al principio. Añade casos límite como festivos, zonas horarias y días parciales.
Después, especifica las pausas. Una pausa no es sólo “cambio de estado”. Es una regla con un responsable. ¿Quién puede pausarla (solo agente, solo sistema, acción del cliente)? ¿Qué estados la pausan (Waiting on Customer, On Hold, Pending Approval)? ¿Qué la reanuda? Al reanudar, ¿se continúa con el tiempo restante o se reinicia el temporizador?
Finalmente, define qué significa un breach en términos de producto. Un breach debe ser algo concreto que puedas almacenar y consultar, por ejemplo:
- un flag de breach (true/false)
- una marca de tiempo
breached_at (cuando se perdió la fecha límite)
- un estado de breach (Approaching, Breached, Resolved after breach)
Ejemplo: “First response SLA breached” podría significar que el ticket obtiene un estado Breached, un breached_at y un nivel de escalación fijado a 1.
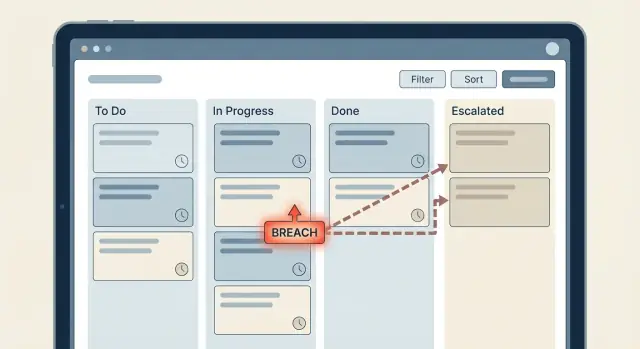
Modela el SLA como estados explícitos, no condiciones dispersas
Si quieres que los temporizadores SLA y las escalaciones sigan siendo legibles, trata el SLA como una pequeña máquina de estados. Cuando la “verdad” está repartida entre chequeos pequeños (if now > due, if priority is high, if last reply is empty), la lógica visual se complica rápido y los pequeños cambios rompen cosas.
Empieza con un conjunto corto y acordado de estados SLA que cada paso del flujo pueda entender. Para muchos equipos, estos cubren la mayoría de los casos:
- On track
- Warning
- Breached
- Paused
- Completed
Un único flag breached = true/false rara vez es suficiente. Aún necesitas saber qué SLA se incumplió (primera respuesta vs resolución), si está actualmente pausado y si ya se escaló. Sin ese contexto, la gente empieza a derivar significado de comentarios, timestamps y nombres de estado. Ahí es donde la lógica se vuelve frágil.
Haz el estado explícito y almacena las marcas de tiempo que lo expliquen. Entonces las decisiones se mantienen simples: tu evaluador lee el registro, decide el siguiente estado y todo lo demás reacciona a ese estado.
Campos útiles para guardar junto al estado:
started_at y due_at (qué reloj ejecutamos y cuándo vence)breached_at (cuándo cruzó efectivamente la línea)paused_at y paused_reason (por qué se detuvo el reloj)breach_reason (qué regla disparó el breach, en palabras sencillas)last_escalation_level (para no notificar el mismo nivel dos veces)
Ejemplo: un ticket pasa a “Waiting on customer”. Fija el estado SLA a Paused, registra paused_reason = "waiting_on_customer" y detén el temporizador. Cuando el cliente responda, reanuda fijando un nuevo started_at (o despausando y recalculando due_at). No hay que buscar en muchas condiciones.
Diseña una escalera de escalación que encaje con tu organización
Una escalera de escalación es un plan claro de qué ocurre cuando un temporizador SLA está cerca de incumplir o ya lo incumplió. El error es copiar el organigrama dentro del flujo. Quieres el conjunto más pequeño de pasos que haga que un ítem estancado vuelva a moverse.
Una escalera simple que usan muchos equipos: el agente asignado (Nivel 0) recibe el primer empujón, luego el líder de equipo (Nivel 1) se involucra y sólo después va a un manager (Nivel 2). Funciona porque empieza donde se puede hacer el trabajo y escala autoridad sólo si hace falta.
Para mantener las reglas de escalación manejables, guarda los umbrales de escalación como datos, no como condiciones hardcodeadas. Ponlos en una tabla o en un objeto de ajustes: “primer recordatorio después de 30 minutos” o “escalar al lead después de 2 horas”. Cuando cambie la política, actualizas un lugar en vez de editar varios flujos.
Mantén las escalaciones útiles, no ruidosas
Las escalaciones se vuelven spam cuando se disparan con demasiada frecuencia. Añade salvaguardas para que cada paso tenga un propósito:
- Una regla de reintento (por ejemplo, reenviar al Nivel 0 una vez si no hay acción).
- Una ventana de cooldown (por ejemplo, no enviar notificaciones de escalación durante 60 minutos después de una enviada).
- Una condición de parada (cancelar futuras escalaciones en cuanto el ítem pase a un estado conforme).
- Un nivel máximo (no pasar de Nivel 2 a menos que un humano lo desencadene).
Decide quién se hace responsable tras una escalación
Solo las notificaciones no arreglan trabajo estancado si la responsabilidad queda difusa. Define reglas de propiedad desde el inicio: ¿el ticket sigue asignado al agente, se reasigna al líder o pasa a una cola compartida?
Ejemplo: después de la escalación Nivel 1, reasigna al líder de equipo y pon al agente original como observador. Eso deja claro quién debe actuar y evita que la escalera rebote el mismo ítem entre personas.
Un patrón mantenible: eventos, evaluador, acciones
Almacenar reglas de escalación como ajustes
Convierte los umbrales de escalación en una simple tabla de políticas en lugar de condiciones dispersas.
La forma más fácil de mantener temporizadores SLA y escalaciones es tratarlos como un pequeño sistema con tres partes: eventos, un evaluador y acciones. Esto evita que la lógica de tiempo se disperse en docenas de comprobaciones “if time > X”.
1) Eventos: registra sólo lo que pasó
Los eventos son hechos simples que no deberían contener matemática de temporizadores. Responden “¿qué cambió?” no “¿qué deberíamos hacer al respecto?”. Eventos típicos: ticket creado, agente respondió, cliente respondió, estado cambiado o pausa/reanudación manual.
Guárdalos como timestamps y campos de estado (por ejemplo: created_at, last_agent_reply_at, last_customer_reply_at, status, paused_at).
2) Evaluador: un único lugar que calcula tiempo y fija estado
Crea un único “evaluador SLA” que se ejecute tras cualquier evento y en un horario periódico. Este evaluador es el único lugar que calcula due_at y tiempo restante. Lee los hechos actuales, recalcula deadlines y escribe campos de estado SLA explícitos como sla_response_state y sla_resolution_state.
Aquí es donde el modelado del estado de breach se mantiene limpio: el evaluador fija estados como OK, AtRisk, Breached, en lugar de ocultar lógica dentro de notificaciones.
3) Acciones: reacciona a cambios de estado, no a matemática de tiempo
Notificaciones, asignaciones y escalaciones deben dispararse sólo cuando un estado cambia (por ejemplo: OK -> AtRisk). Mantén el envío de mensajes separado de la actualización del estado SLA. Así puedes cambiar quién recibe notificaciones sin tocar los cálculos.
Paso a paso: construir temporizadores y escalaciones en lógica visual
Una configuración mantenible suele verse así: pocos campos en el registro, una pequeña tabla de políticas y un evaluador único que decide qué pasa a continuación.
1) Prepara datos para que la lógica de tiempo tenga un único hogar
Empieza con la entidad que posee el SLA (ticket, pedido, solicitud). Añade timestamps explícitos y un campo único de “estado SLA actual”. Mantenlo aburrido y predecible.
Luego agrega una pequeña tabla de políticas que describa reglas en lugar de hardcodearlas en muchos flujos. Una versión simple es una fila por prioridad (P1, P2, P3) con columnas para minutos objetivo y umbrales de escalación (por ejemplo: advertir al 80%, incumplir al 100%). Esto es la diferencia entre cambiar un registro y editar cinco flujos.
2) Ejecuta un evaluador programado, no docenas de temporizadores
En vez de crear temporizadores separados por todas partes, usa un proceso programado que revise ítems periódicamente (cada minuto para SLAs estrictos, cada 5 minutos para muchos equipos). El programador llama a un evaluador que:
- selecciona registros aún activos (no cerrados)
- calcula “ahora vs due” y deriva el siguiente estado
- calcula el siguiente momento de comprobación (para no re-chequear con demasiada frecuencia)
- escribe
sla_state y next_check_at
Así es más fácil razonar sobre temporizadores SLA y escalaciones porque depuras un solo evaluador, no muchos temporizadores.
3) Haz que las acciones sean activadas por borde (solo al cambiar)
El evaluador debe producir tanto el nuevo estado como si cambió. Solo dispara mensajes o tareas cuando el estado se mueve (por ejemplo ok -> warning, warning -> breached). Si el registro permanece breached durante una hora, no quieres 12 notificaciones repetidas.
Un patrón práctico: guarda sla_state y last_escalation_level, compáralos con los valores calculados y sólo entonces llama al sistema de mensajería (email/SMS/Telegram) o crea una tarea interna.
Manejo de pausas, reanudaciones y cambios de estado
Hacer los incumplimientos explícitos en los datos
Modele tickets, SLAs y marcas de tiempo de breach en un único esquema de datos que puedas auditar.
Las pausas son donde las reglas de tiempo suelen ensuciarse. Si no las modelas claramente, tu SLA seguirá corriendo cuando no debería o se reiniciará cuando alguien pulse el estado equivocado.
Una regla simple: sólo un estado (o un conjunto pequeño) pausa el reloj. Una elección común es Waiting for customer. Cuando un ticket entra en ese estado, guarda un timestamp pause_started_at. Cuando el cliente responde y el ticket sale de ese estado, cierra la pausa escribiendo pause_ended_at y sumando la duración a paused_total_seconds.
No te quedes sólo con un contador. Captura cada ventana de pausa (inicio, fin, quién o qué la disparó) para tener una pista de auditoría. Después, si alguien pregunta por qué un caso incumplió, puedes mostrar que estuvo 19 horas esperando al cliente.
La reasignación y cambios normales de estado no deben reiniciar el reloj. Mantén timestamps SLA separados de campos de ownership. Por ejemplo, sla_started_at y sla_due_at deberían fijarse una vez (en la creación, o cuando cambia la política SLA), mientras que la reasignación solo actualiza assignee_id. Tu evaluador puede entonces calcular tiempo transcurrido como: ahora menos sla_started_at menos paused_total_seconds.
Reglas para mantener temporizadores y escalaciones predecibles:
- Pausar sólo en estados explícitos (como Waiting for customer), no en flags suaves.
- Reanudar sólo al salir de ese estado, no por cualquier mensaje entrante.
- Nunca reiniciar SLA en una reasignación; trátala como enrutamiento, no como un nuevo caso.
- Permitir overrides manuales, pero exigir motivo y limitar quién puede hacerlo.
- Registrar cada cambio de estado y cada ventana de pausa.
Escenario de ejemplo: ticket de soporte con SLAs de respuesta y resolución
Publicar una app completa de tickets
Genera backend, web app y apps móviles para tu herramienta interna de soporte desde un proyecto.
Una manera simple de probar tu diseño es un ticket con dos SLAs: primera respuesta en 30 minutos y resolución completa en 8 horas. Aquí es donde la lógica suele romperse si está repartida entre pantallas y botones.
Asume que cada ticket almacena: state (New, InProgress, WaitingOnCustomer, Resolved), response_status (Pending, Warning, Breached, Met), resolution_status (Pending, Warning, Breached, Met), además de timestamps como created_at, first_agent_reply_at, y resolved_at.
Una línea de tiempo realista:
- 09:00 Ticket creado (New). Arrancan el temporizador de respuesta y el de resolución.
- 09:10 Asignado al Agente A (ambos SLAs siguen Pending).
- 09:25 Aún sin respuesta del agente. La respuesta llega a 25 minutos y pasa a Warning.
- 09:40 Sigue sin respuesta. La respuesta llega a 30 minutos y pasa a Breached.
- 09:45 El agente responde. Response pasa a Met (incluso si estuvo Breached, conserva el registro de breach y marca Met para reporting).
- 10:30 El cliente responde con más info. El ticket pasa a InProgress y la resolución continúa.
- 11:00 El agente pide una aclaración. El ticket pasa a WaitingOnCustomer y el temporizador de resolución se pausa.
- 14:00 El cliente responde. El ticket vuelve a InProgress y el temporizador de resolución se reanuda.
- 16:30 Ticket resuelto. Resolution pasa a Met si el tiempo activo total está bajo 8 horas; de lo contrario Breached.
Para escalaciones, mantén una cadena clara que se dispare por transiciones de estado. Por ejemplo, cuando response pasa a Warning, notifica al agente asignado. Cuando pasa a Breached, notifica al team lead y actualiza la prioridad.
En cada paso, actualiza el mismo pequeño conjunto de campos para que sea fácil de razonar:
- Fija
response_status o resolution_status a Pending, Warning, Breached o Met.
- Escribe
*_warning_at y *_breach_at una vez y nunca los sobreescribas.
- Incrementa
escalation_level (0, 1, 2) y fija escalated_to (Agent, Lead, Manager).
- Añade una fila en el log
sla_events con el tipo de evento y quién fue notificado.
- Si hace falta, ajusta
priority y due_at para que la UI y los informes reflejen la escalación.
La clave es que Warning y Breached sean estados explícitos. Puedes verlos en los datos, auditarlos y cambiar la escalera más tarde sin buscar chequeos de tiempo ocultos.
Trampas comunes y cómo evitarlas
La lógica SLA se ensucia cuando se dispersa. Un chequeo rápido añadido a un botón aquí, una alerta condicional allá y pronto nadie puede explicar por qué un ticket se escaló. Mantén temporizadores SLA y escalaciones como una pieza pequeña y central de lógica de la que dependen todas las pantallas y acciones.
Una trampa común es incrustar chequeos de tiempo en muchos sitios (UI, handlers de API, acciones manuales). La solución es computar el estado SLA en un solo evaluador y almacenar el resultado en el registro. Las pantallas deben leer el estado, no inventarlo.
Otra trampa es dejar que los temporizadores discrepen porque usan relojes diferentes. Si el navegador calcula “minutos desde creado” pero el backend usa tiempo del servidor, verás casos límite con suspensión, zonas horarias y cambios de horario. Prefiere tiempo del servidor para cualquier cosa que dispare una escalación.
Las notificaciones también pueden volverse ruidosas rápido. Si “revisas cada minuto y envías si está vencido”, la gente puede recibir spam cada minuto. Ata los mensajes a transiciones: “warning enviado”, “escalado”, “breached”. Así envías una vez por paso y puedes auditar qué sucedió.
La lógica de horas laborales es otra fuente de complejidad accidental. Si cada regla tiene su propio "si es fin de semana entonces...", las actualizaciones serán dolorosas. Pon la matemática de horas laborales en una función (o un bloque compartido) que devuelva “minutos SLA consumidos hasta ahora” y reutilízala.
Finalmente, no confíes en recomputar el breach desde cero. Guarda el momento en que ocurrió:
- Salva
breached_at la primera vez que detectes un breach y no lo sobrescribas.
- Guarda
escalation_level y last_escalated_at para que las acciones sean idempotentes.
- Guarda
notified_warning_at (o similar) para prevenir alertas repetidas.
Ejemplo: un ticket alcanza “Response SLA breached” a las 10:07. Si sólo recomputas, un cambio de estado posterior o un bug de pausa/reanudación puede hacer que parezca que el breach ocurrió a las 10:42. Con breached_at = 10:07, los informes y postmortems permanecen consistentes.
Lista rápida para lógica SLA mantenible
Mantener una vía de escape con código fuente
Exporta código fuente real cuando necesites control total sobre el hosting y los lanzamientos.
Antes de añadir temporizadores y alertas, haz una pasada con el objetivo de que las reglas sean legibles dentro de un mes.
- Cada SLA tiene fronteras claras. Escribe el evento exacto de inicio, el evento de parada, reglas de pausa y qué cuenta como breach. Si no puedes señalar un evento único que arranca el reloj, la lógica se esparcirá en condiciones aleatorias.
- Las escalaciones son una escalera, no un montón de alertas. Para cada nivel, define el umbral (30m, 2h, 1d), quién lo recibe, un cooldown y el nivel máximo.
- Los cambios de estado se registran con contexto. Cuando un estado SLA cambia (Running, Paused, Breached, Resolved), almacena quién lo provocó, cuándo y por qué.
- Las comprobaciones programadas son seguras de ejecutar dos veces. Tu evaluador debe ser idempotente: si corre otra vez para el mismo registro, no debe crear escalaciones duplicadas ni reenviar el mismo mensaje.
- Las notificaciones vienen de transiciones, no de la matemática de tiempo cruda. Envía alertas cuando el estado cambie, no cuando “ahora - created_at > X”.
Una prueba práctica: elige un ticket cercano a incumplir y reproduce su línea de tiempo. Si no puedes explicar qué pasará en cada cambio de estado sin leer todo el flujo, tu modelo está demasiado disperso.
Siguientes pasos: implementar, observar y luego refinar
Construye la unidad mínima útil primero. Elige un SLA (por ejemplo, primera respuesta) y un nivel de escalación (por ejemplo, notificar al team lead). Aprenderás más con una semana de uso real que con un diseño perfecto en papel.
Mantén umbrales y destinatarios como datos, no como lógica. Pon minutos y horas, reglas de horas laborales, quién recibe notificaciones y qué cola posee el caso en tablas o registros de configuración. Así el flujo se mantiene estable mientras el negocio ajusta números y enrutamiento.
Planea una vista de dashboard simple pronto. No necesitas un gran sistema analítico, sólo una imagen compartida de qué está pasando ahora: on track, warning, breached, escalated.
Si lo construyes en una app no-code, ayuda elegir una plataforma que te permita modelar datos, lógica y evaluadores programados en un mismo lugar. Por ejemplo, AppMaster (appmaster.io) soporta modelado de base de datos, procesos de negocio visuales y generación de apps listas para producción, lo que encaja bien con el patrón “eventos, evaluador, acciones”.
Refina con seguridad iterando en este orden:
- Añade un nivel de escalación más sólo después de que el Nivel 1 funcione bien
- Pasa de un SLA a dos (respuesta y resolución)
- Añade reglas de pausa/reanudar (waiting on customer, on hold)
- Ajusta notificaciones (deduplicar, horas de silencio, destinatarios correctos)
- Revisa semanalmente: ajusta umbrales en datos, no re-cableando el flujo
Cuando estés listo, construye una versión pequeña primero y luego hazla crecer con feedback real y tickets reales.
FAQ
Empieza por definir con claridad la promesa que mides, como primera respuesta o resolución, y anota exactamente qué eventos empiezan, paran y pausan el reloj. Luego centraliza la matemática de tiempo en un evaluador que establezca estados SLA explícitos en lugar de esparcir comprobaciones “if now > X” por muchos flujos.
Un temporizador es el reloj que inicias o programas después de un evento (por ejemplo, que un ticket cambie de estado). Una escalación es la acción que tomas cuando se alcanza un umbral (notificar a un líder, cambiar prioridad). Un breach es el hecho almacenado de que el SLA se incumplió, que puedes reportar más tarde.
Sí. La primera respuesta mide el tiempo hasta la primera respuesta humana significativa, mientras que resolución mide hasta que el problema está realmente cerrado. Se comportan de forma diferente ante pausas y reaperturas, así que modelarlas por separado mantiene las reglas simples y los informes precisos.
Usa tiempo calendario por defecto porque es más simple y fácil de depurar. Añade reglas de tiempo laboral sólo si realmente las necesitas; las horas laborales introducen complejidades adicionales como festivos, zonas horarias y cálculos de días parciales.
Modela las pausas como estados explícitos ligados a estatus específicos (por ejemplo, Waiting on Customer), y guarda cuándo comenzó y terminó la pausa. Al reanudar, continúa con el tiempo restante o recalcula la fecha de vencimiento en un solo lugar; no permitas que cambios de estado aleatorios reinicien el reloj.
Un solo campo breached = true/false oculta contexto importante (qué SLA se incumplió, si está pausado, si ya se escaló). Estados explícitos como On track, Warning, Breached, Paused y Completed hacen el sistema predecible y más fácil de auditar y cambiar.
Guarda marcas de tiempo que expliquen el estado, por ejemplo started_at, due_at, breached_at, y campos de pausa como paused_at y paused_reason. También registra seguimiento de escalación como last_escalation_level para no notificar el mismo nivel dos veces.
Crea una escalera pequeña que empiece por la persona que puede actuar, luego escale a un líder y después a un manager sólo si es necesario. Mantén umbrales y destinatarios como datos (por ejemplo, una tabla de políticas) para que cambiar el timing no requiera editar varios flujos.
Asocia las notificaciones a transiciones de estado como OK -> Warning o Warning -> Breached, no a comprobaciones continuas de “sigue vencido”. Añade defensas simples como ventanas de cooldown y condiciones de parada para enviar un mensaje por paso en lugar de repetidos avisos.
Usa el patrón eventos, evaluador y acciones: los eventos registran hechos, el evaluador calcula plazos y establece el estado SLA, y las acciones reaccionan sólo a cambios de estado. En AppMaster (appmaster.io) puedes modelar los datos, construir el evaluador como un proceso visual y disparar notificaciones o reasignaciones desde las actualizaciones de estado manteniendo la matemática del tiempo centralizada.