14 mar 2025·8 min de lectura
Tareas en segundo plano con actualizaciones de progreso: patrones de UI que funcionan
Aprende patrones prácticos para tareas en segundo plano con actualizaciones de progreso: colas, modelo de estado, mensajes en la UI, acciones de cancelar y reintentar, y reporte de errores.
Por qué los usuarios se quedan atascados cuando las tareas se ejecutan en segundo plano
Las acciones largas no deberían bloquear la UI. La gente cambia de pestaña, pierde la conexión, cierra el portátil o simplemente se pregunta si está ocurriendo algo. Cuando la pantalla está congelada, los usuarios empiezan a adivinar, y adivinar se convierte en clics repetidos, envíos duplicados y tickets de soporte.
Un buen trabajo en segundo plano tiene que ver con la confianza. Los usuarios quieren tres cosas:
- Un estado claro (queued, running, done)
- Una sensación del tiempo (incluso una estimación aproximada)
- Una acción siguiente obvia (esperar, seguir trabajando, cancelar o volver más tarde)
Sin eso, el trabajo puede estar ejecutándose bien, pero la experiencia se siente rota.
Una confusión común es tratar una petición lenta como si fuera trabajo en segundo plano real. Una petición lenta sigue siendo una llamada web que hace esperar al usuario. El trabajo en segundo plano es distinto: inicias un trabajo, recibes confirmación inmediata y el procesamiento pesado ocurre en otro lugar mientras la UI sigue usable.
Ejemplo: un usuario sube un CSV para importar clientes. Si la UI bloquea, puede refrescar, subir de nuevo y crear duplicados. Si la importación empieza en segundo plano y la UI muestra una tarjeta de trabajo con progreso y una opción de Cancel segura, pueden seguir trabajando y volver a un resultado claro.
Bloques básicos: trabajos, colas, workers y estado
Cuando se habla de tareas en segundo plano con actualizaciones de progreso, normalmente se refieren a cuatro piezas que trabajan juntas.
Un job es la unidad de trabajo: "import this CSV", "generate this report" o "send 5,000 emails." Una queue es la fila de espera donde los jobs aguardan hasta que puedan ser procesados. Un worker saca jobs de la cola y hace el trabajo (uno a la vez o en paralelo).
Para la UI, lo más importante es el lifecycle state del job. Mantén los estados pocos y previsibles:
- Queued: accepted, waiting for a worker
- Running: actively processing
- Done: finished successfully
- Failed: stopped with an error
Cada job necesita un job ID (una referencia única). Cuando el usuario hace clic en un botón, devuelve ese ID inmediatamente y muestra una fila "Task started" en un panel de tareas.
Luego necesitas una forma de preguntar: "¿Qué está pasando ahora?" Eso suele ser un status endpoint (o cualquier método de lectura) que toma el job ID y devuelve el estado más los detalles de progreso. La UI lo usa para mostrar el porcentaje completado, el paso actual y cualquier mensaje.
Finalmente, el estado debe vivir en un almacen durable, no solo en memoria. Los workers fallan, las apps se reinician y los usuarios refrescan páginas. El almacenamiento durable es lo que hace que el progreso y los resultados sean fiables. Como mínimo, guarda:
- estado actual y marcas de tiempo
- valor de progreso (porcentaje o contadores)
- resumen del resultado (qué se creó o cambió)
- detalles de error (para depuración y mensajes amigables)
Si estás construyendo en una plataforma como AppMaster, trata la tabla de estado como cualquier otro modelo de datos: la UI la lee por ID de trabajo y el worker la actualiza a medida que avanza el job.
Elegir un patrón de cola que encaje con tu carga
El patrón de cola que elijas cambia qué tan “justa” y predecible se siente tu app. Si una tarea queda detrás de un montón de trabajo, los usuarios experimentan demoras aleatorias, aunque el sistema esté sano. Eso convierte la elección de la cola en una decisión de UX, no solo de infraestructura.
Una cola simple basada en la base de datos suele ser suficiente cuando el volumen es bajo, los jobs son cortos y puedes tolerar reintentos ocasionales. Es fácil de configurar, fácil de inspeccionar y puedes mantener todo en un solo lugar. Ejemplo: un admin ejecuta un informe nocturno para un equipo pequeño. Si reintenta una vez, nadie entra en pánico.
Suele ser necesario un sistema de colas dedicado cuando aumenta el throughput, los jobs son pesados o la fiabilidad es innegociable. Importaciones, procesamiento de video, notificaciones masivas y cualquier flujo que deba seguir ejecutándose tras reinicios se benefician de mayor aislamiento, visibilidad y reintentos más seguros. Esto importa para el progreso visible por usuarios porque la gente nota las actualizaciones faltantes y los estados atascados.
La estructura de la cola también afecta prioridades. Una cola es más simple, pero mezclar trabajo rápido y lento puede hacer que las acciones rápidas parezcan lentas. Colas separadas ayudan cuando tienes trabajo iniciado por el usuario que debe sentirse instantáneo junto con trabajo por lotes programado que puede esperar.
Define límites de concurrencia con propósito. Mucha paralelización puede saturar tu base de datos y hacer que el progreso salte. Muy poca hace que el sistema se sienta lento. Comienza con concurrencia pequeña y predecible por cola, y aumenta solo cuando puedas mantener tiempos de finalización estables.
Diseñar un modelo de progreso que realmente puedas mostrar en la UI
Si tu modelo de progreso es vago, la UI también lo será. Decide qué puede reportar honestamente el sistema, con qué frecuencia cambia y qué deben hacer los usuarios con esa información.
Un esquema de estado simple que la mayoría de jobs puede soportar se ve así:
- state: queued, running, succeeded, failed, canceled
- percent: 0-100 cuando puedas medirlo
- message: una frase corta que los usuarios entiendan
- timestamps: created, started, last_updated, finished
- result_summary: contadores como processed, skipped, errors
A continuación, define qué significa “progreso”.
El porcentaje funciona cuando hay un denominador real (filas en un archivo, emails a enviar). Engaña cuando el trabajo es impredecible (esperando a un tercero, computación variable, consultas caras). En esos casos, el progreso por pasos genera más confianza porque avanza en fragmentos claros.
Una regla práctica:
- Usa percent cuando puedas reportar “X of Y”.
- Usa steps cuando la duración sea desconocida (Validate file, Import, Rebuild indexes, Finalize).
- Usa indeterminate cuando ninguna opción sea válida, pero mantén el mensaje actualizado.
Almacena resultados parciales mientras el job corre. Eso permite que la UI muestre algo útil antes de que el trabajo termine, como un conteo de errores en vivo o una vista previa de lo que cambió. Para una importación CSV, podrías guardar rows_read, rows_created, rows_updated, rows_rejected, más los últimos mensajes de error.
Esta es la base para tareas en segundo plano con actualizaciones de progreso en las que los usuarios confían: la UI se mantiene tranquila, los números siguen avanzando y el resumen de “qué pasó” está listo cuando el job termina.
Entrega de actualizaciones de progreso: polling, push e híbrido
Envía actualizaciones push cuando las necesites
Añade estado en tiempo real con notificaciones web o móviles y usa polling como respaldo.
Llevar el progreso del backend a la pantalla es donde muchas implementaciones fallan. Elige un método de entrega que encaje con la frecuencia con la que cambia el progreso y con cuántos usuarios esperas que lo estén observando.
El polling es lo más simple: la UI pregunta por el estado cada N segundos. Un buen valor por defecto es 2 a 5 segundos mientras el usuario está activamente mirando la página, luego desacelerar con el tiempo. Si la tarea dura más de un minuto, pasa a 10–30 segundos. Si la pestaña está en segundo plano, reduce aún más la frecuencia.
Las actualizaciones push (WebSockets, server-sent events o notificaciones móviles) ayudan cuando el progreso cambia rápido o a los usuarios les importa el “ahora mismo”. El push es excelente para inmediatez, pero aún necesitas un fallback cuando la conexión cae.
Un enfoque híbrido suele ser el mejor: poll rápido al inicio (para que la UI vea pronto queued → running), luego ralentizar una vez que el job está estable. Si añades push, mantén un poll lento como red de seguridad.
Cuando las actualizaciones se detienen, trátalo como un estado de primera clase. Muestra “Última actualización hace 2 minutos” y ofrece un refresco. En el backend, marca jobs como stale si no han enviado heartbeats.
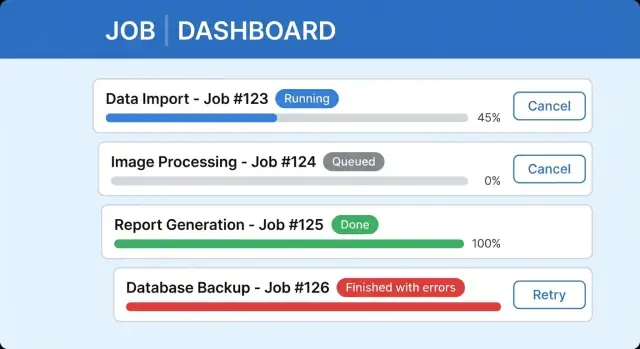
Patrones UI para tareas de larga duración que se entienden con facilidad
La claridad viene de dos cosas: un conjunto pequeño de estados previsibles y copy que diga a la gente qué ocurre después.
Nombra los estados en la UI, no solo en el backend. Un job puede estar queued (esperando su turno), running (haciendo el trabajo), waiting for input (necesita una elección), completed, completed with errors o failed. Si los usuarios no distinguen entre ellos, asumirán que la app está atascada.
Usa texto claro y útil junto al indicador de progreso. “Importing 3,200 rows (1,140 processed)” vence a “Processing.” Añade una frase que responda: ¿puedo irme? ¿qué pasará? Por ejemplo: "You can close this window. We'll keep importing in the background and notify you when it's ready." (puedes traducir esta copy en la UI final según el idioma del producto).
Dónde vive el progreso debe coincidir con el contexto del usuario:
- Un modal funciona cuando la tarea bloquea el siguiente paso (por ejemplo, generar un PDF de factura que necesitan ahora).
- Un toast sirve para tareas rápidas que no deben interrumpir.
- Progreso inline en una fila de tabla funciona para operaciones por ítem.
Para cualquier cosa de más de un minuto, añade una página de Jobs (o panel de Actividad) para que la gente pueda encontrar el trabajo más tarde.
Una UI clara para tareas largas suele incluir una etiqueta de estado con la última actualización, una barra de progreso (o pasos) con una línea de detalle, comportamiento de Cancel seguro y un área de resultados con un resumen y acción siguiente. Mantén los jobs completados accesibles para que los usuarios no sientan que deben quedarse en una sola pantalla.
Reportar “finalizado con errores” sin confundir a los usuarios
Conecta mensajería para notificaciones
Envía alertas por Telegram o email cuando los trabajos terminen para que los usuarios sigan trabajando.
“Finalizado” no siempre es una victoria. Cuando un trabajo procesa 9,500 registros y 120 fallan, los usuarios necesitan entender qué ocurrió sin leer logs.
Trata el éxito parcial como un resultado de primera clase. En la línea principal de estado, muestra ambos lados: “Imported 9,380 of 9,500. 120 failed.” Eso mantiene alta la confianza porque el sistema es honesto y confirma que el trabajo se guardó.
Luego muestra un pequeño resumen de errores que los usuarios puedan actuar: "Missing required field (63)" y "Invalid date format (41)." En el estado final, “Completed with issues” suele ser más claro que “Failed”, porque no implica que nada funcionó.
Un informe de errores exportable convierte la confusión en una lista de tareas. Mantenlo simple: identificador de fila o ítem, categoría de error, un mensaje humano y el nombre del campo cuando aplique.
Haz la acción siguiente obvia y cerca del resumen: arreglar datos y reintentar los ítems fallidos, descargar el informe de errores o contactar soporte si parece un problema del sistema.
Acciones de cancelar y reintentar en las que los usuarios confían
Cancelar y reintentar parecen sencillos, pero rompen la confianza rápido cuando la UI dice una cosa y el sistema hace otra. Define qué significa Cancel para cada tipo de job y refléjalo honestamente en la interfaz.
Suelen existir dos modos válidos de cancelación:
- "Stop now": el worker revisa una flag de cancelación con frecuencia y sale rápido.
- "Stop after this step": el paso actual termina y luego el job se para antes del siguiente paso.
En la UI, muestra un estado intermedio como “Cancel requested” para que los usuarios no sigan haciendo clic.
Haz la cancelación segura diseñando el trabajo para que sea repetible. Si un job escribe datos, prefiere operaciones idempotentes (seguras de ejecutar dos veces) y haz limpieza cuando sea necesario. Por ejemplo, si una importación CSV crea registros, guarda un job-run ID para poder revisar lo que cambió en la ejecución #123.
El reintento necesita la misma claridad. Reintentar la misma instancia puede tener sentido cuando puede reanudar. Crear una nueva instancia de job es más seguro cuando quieres una ejecución limpia con nueva marca de tiempo y rastro de auditoría. En ambos casos, explica qué ocurrirá y qué no.
Guardarraíces que mantienen predictivos cancelar y reintentar:
- Limita reintentos y muestra el conteo.
- Previene ejecuciones dobles deshabilitando Retry mientras un job está en ejecución.
- Pide confirmación cuando reintentar podría duplicar efectos secundarios (emails, pagos, exportaciones).
- Muestra el último error y el último paso exitoso en un panel de detalles.
Paso a paso: un flujo de extremo a extremo desde el clic hasta la finalización
Lanza una UI de importación CSV
Combina procesamiento en backend y una UI con tarjetas de progreso en el mismo proyecto de AppMaster.
Un buen flujo de extremo a extremo comienza con una regla: la UI nunca debería esperar por el trabajo en sí. Solo debe esperar un job ID.
El flujo (del clic del usuario al estado final)
-
El usuario inicia la tarea, la API responde rápido. Cuando el usuario hace clic en Import o Generate report, tu servidor crea inmediatamente un registro de job y devuelve un job ID único.
-
Encola el trabajo y establece el primer estado. Mete el job ID en una cola y establece el estado en queued con progreso 0%. Esto le da a la UI algo real que mostrar incluso antes de que un worker lo tome.
-
El worker corre y reporta progreso. Cuando un worker empieza, establece el estado en running, guarda la hora de inicio y actualiza el progreso en saltos pequeños y honestos. Si no puedes medir porcentaje, muestra pasos como Parsing, Validating, Saving.
-
La UI mantiene orientado al usuario. La UI hace polling o se suscribe a actualizaciones y renderiza estados claros. Muestra un mensaje corto (qué está pasando ahora) y solo las acciones que tienen sentido en ese momento.
-
Finaliza con un resultado durable. Al completar, guarda la hora de finalización, la salida (referencia de descarga, IDs creados, resúmenes), y detalles de error. Soporta finished-with-errors como su propio resultado, no como un éxito vago.
Reglas de cancel y retry
La cancelación debe ser explícita: Cancel job solicita la cancelación, luego el worker la reconoce y marca como canceled. Reintentar debería crear un nuevo job ID, mantener el original como historial y explicar qué se volverá a ejecutar.
Escenario de ejemplo: importación CSV con progreso y fallos parciales
Construye apps completas, no spinners
Crea backend, UI web y apps móviles nativas alrededor de tareas largas en AppMaster.
Un lugar común donde importan las actualizaciones de progreso es una importación CSV. Imagina un CRM donde una persona de sales ops sube customers.csv con 8,420 filas.
Justo después de la subida, la UI debería cambiar de “Hice clic” a “existe un job y puedes irte.” Una tarjeta simple en una página de Imports funciona bien:
- Upload received: "File uploaded. Validating columns..."
- Queued: "Waiting for an available worker (2 jobs ahead)."
- Running: "Importing customers: 3,180 of 8,420 processed (38%)."
- Wrapping up: "Saving results and building a report..."
Mientras corre, muestra un número de progreso confiable (filas procesadas) y una línea de estado corta (qué está haciendo ahora). Si el usuario se va, mantén el job visible en un área de Recent jobs.
Ahora añade fallos parciales. Cuando el job termina, evita un banner alarmante de Failed si la mayoría de filas salieron bien. Usa Finished with issues junto con una división clara:
Imported 8,102 customers. Skipped 318 rows.
Explica las principales razones en palabras sencillas: formato de email inválido, campo requerido faltante como company, o IDs externas duplicadas. Permite al usuario descargar o ver una tabla de errores con número de fila, nombre del cliente y el campo exacto que necesita corrección.
Reintentar debe sentirse seguro y específico. La acción principal puede ser Retry failed rows, creando un nuevo job que solo reprocesa las 318 filas omitidas después de que el usuario corrija el CSV. Mantén el job original como lectura para que el historial sea veraz.
Por último, facilita encontrar resultados más tarde. Cada importación debe tener un resumen estable: quién la ejecutó, cuándo, nombre del archivo, contadores (imported, skipped) y una forma de abrir el informe de errores.
Errores comunes que llevan a confusión en progreso y reintentos
La forma más rápida de perder confianza es mostrar números que no son reales. Una barra de progreso que se queda en 0% durante dos minutos y salta al 90% parece una suposición. Si no conoces el porcentaje real, muestra pasos (Queued, Processing, Finalizing) o “X of Y items processed.”
Otro problema común es mantener el progreso solo en memoria. Si el worker se reinicia, la UI “olvida” el job o reinicia el progreso. Guarda el estado del job en almacenamiento durable y haz que la UI lea desde esa única fuente de verdad.
La experiencia de reintento también falla cuando los usuarios pueden iniciar el mismo job varias veces. Si el botón Import CSV sigue activo, alguien hace clic dos veces y crea duplicados. Ahora los reintentos no quedan claros porque no se sabe qué ejecución arreglar.
Errores recurrentes:
- porcentaje falso que no coincide con el trabajo real
- volcado técnico de errores mostrado a usuarios finales (stack traces, códigos)
- sin manejo para timeouts, duplicados o idempotencia
- reintentos que crean un job nuevo sin explicar qué pasará
- cancelación que solo cambia la UI y no el comportamiento del worker
Un detalle pequeño pero importante: separa el mensaje para el usuario del detalle para desarrolladores. Muestra “12 filas fallaron validación” al usuario y guarda el rastro técnico en logs.
Lista rápida antes de lanzar trabajos en segundo plano a usuarios
Despliega tu sistema de trabajos en cualquier lugar
Ejecuta en AppMaster Cloud o exporta el código fuente para tu propia infraestructura.
Antes del lanzamiento, revisa rápido las partes que los usuarios notan: claridad, confianza y recuperación.
Cada job debería exponer un snapshot que puedas mostrar en cualquier lugar: state (queued, running, succeeded, failed, canceled), progreso (0-100 o pasos), un mensaje corto, timestamps (created, started, finished) y un puntero al resultado (dónde está la salida o informe).
Haz obvios y consistentes los estados en la UI. Los usuarios necesitan un lugar fiable para encontrar jobs actuales y pasados, más etiquetas claras cuando vuelven más tarde ("Completed yesterday", "Still running"). Un panel de Recent jobs suele evitar clics repetidos y trabajo duplicado.
Define reglas de cancel y retry en términos sencillos. Decide qué significa Cancel para cada tipo de job, si se permite reintento y qué se reutiliza (misma entrada, nuevo job ID). Luego prueba casos límite como cancelar justo antes de la finalización.
Trata los fallos parciales como un resultado real. Muestra un resumen corto ("Imported 97, skipped 3") y proporciona un informe accionable que los usuarios puedan usar de inmediato.
Planifica la recuperación. Los jobs deben sobrevivir reinicios y los jobs atascados deben caducar a un estado claro con orientación ("Try again" o "Contact support with job ID").
Siguientes pasos: implementa un flujo y expande desde ahí
Elige un flujo que ya moleste a los usuarios: importaciones CSV, exportaciones de informes, envíos masivos de email o procesamiento de imágenes. Empieza pequeño y demuestra lo básico: se crea un job, se ejecuta, reporta estado y el usuario puede encontrarlo más tarde.
Una pantalla simple de historial de jobs suele ser el mayor salto de calidad. Da a la gente un lugar al que volver en lugar de mirar un spinner.
Elige primero un método de entrega de progreso. El polling está bien para la versión uno. Haz el intervalo de refresco lo bastante lento para ser amable con el backend, pero lo bastante rápido para sentirse vivo.
Un orden de construcción práctico que evita reescrituras:
- implementa estados y transiciones de job primero (queued, running, succeeded, failed, finished-with-errors)
- añade una pantalla de historial de jobs con filtros básicos (últimas 24 horas, solo mis jobs)
- añade números de progreso solo cuando puedas mantenerlos honestos
- añade Cancel solo después de garantizar limpieza consistente
- añade Retry solo después de confirmar que el job es idempotente
Si estás construyendo esto sin escribir código, una plataforma no-code como AppMaster puede ayudar permitiéndote modelar una tabla de estado de jobs (PostgreSQL) y actualizarla desde workflows, para luego renderizar ese estado en web y móvil. Para equipos que quieren un único lugar para construir backend, UI y lógica de fondo, AppMaster (appmaster.io) está diseñado para aplicaciones completas, no solo formularios o páginas.
FAQ
Un trabajo en segundo plano se crea rápido y devuelve un ID de trabajo de inmediato, de modo que la interfaz puede seguir siendo usable. Una petición lenta mantiene al usuario esperando a que termine la misma llamada web, lo que provoca refrescos, dobles clics y envíos duplicados.
Mantenlo simple: queued, running, done y failed, además de canceled si soportas cancelación. Añade un resultado separado como “done with issues” cuando la mayor parte del trabajo tuvo éxito pero algunos ítems fallaron, para que los usuarios no piensen que todo se perdió.
Devuelve un ID de trabajo único inmediatamente después de que el usuario inicie la acción, y renderiza una fila o tarjeta de tarea usando ese ID. La UI debe leer el estado por ID de trabajo para que el usuario pueda refrescar, cambiar de pestaña o volver más tarde sin perder el seguimiento.
Almacena el estado del trabajo en una tabla durable de la base de datos, no solo en memoria. Guarda el estado actual, las marcas de tiempo, el valor de progreso, un mensaje corto para el usuario y un resumen de resultado o error para que la UI pueda reconstruir siempre la misma vista después de reinicios.
Usa porcentaje solo cuando puedas reportar honestamente “X de Y” ítems procesados. Si no puedes medir un denominador real, muestra progreso por pasos como “Validando”, “Importando” y “Finalizando”, y mantén el mensaje actualizado para que los usuarios sientan movimiento hacia delante.
El polling es lo más sencillo y funciona bien para la mayoría de apps; comienza con intervalos de 2–5 segundos mientras el usuario mira, y luego reduce la frecuencia para trabajos largos o pestañas en segundo plano. Las actualizaciones push pueden sentirse más instantáneas, pero necesitas una alternativa cuando la conexión cae.
Muestra que las actualizaciones están obsoletas en lugar de fingir que el trabajo sigue activo, por ejemplo con “Última actualización hace 2 minutos” y ofreciendo un refresco manual. En el backend, detecta la ausencia de heartbeats y mueve el trabajo a un estado claro con orientación, como reintentar o contactar soporte con el ID de trabajo.
Haz que la acción siguiente sea obvia: si el usuario puede seguir trabajando, irse de la página o cancelar de forma segura. Para tareas de más de un minuto, una vista dedicada de Jobs o Actividad ayuda a que los usuarios encuentren resultados más tarde en lugar de quedarse mirando un spinner.
Trátalo como un resultado válido y muestra ambas cifras claramente, por ejemplo “Imported 9,380 of 9,500. 120 failed.” Luego proporciona un pequeño resumen de errores accionable que los usuarios puedan corregir sin leer logs, y mantiene los detalles técnicos en los registros internos en lugar de mostrarlos en pantalla.
Define qué significa Cancel por tipo de trabajo y refléjalo honestamente, incluyendo un estado intermedio como “cancel requested” para que los usuarios no sigan haciendo clic. Haz que el trabajo sea idempotente cuando sea posible, limita reintentos y decide si reintentar resume el mismo trabajo o crea un nuevo ID con un historial limpio.