26 mar 2025·8 min de lectura
Registro de auditoría para herramientas internas: patrones claros para el historial de cambios
Registro de auditoría para herramientas internas hecho práctico: rastrea quién hizo qué y cuándo en cada cambio CRUD, almacena diffs de forma segura y muestra un feed de actividad para administradores.
Por qué las herramientas internas necesitan registros de auditoría (y dónde suelen fallar)
La mayoría de los equipos añade registros de auditoría después de que algo sale mal. Un cliente disputa un cambio, una cifra financiera se desplaza, o un auditor pregunta: "¿Quién aprobó esto?" Si solo empiezas entonces, acabas reconstruyendo el pasado a partir de pistas parciales: marcas temporales de la base de datos, mensajes de Slack y conjeturas.
Para la mayoría de las aplicaciones internas, "suficiente para cumplimiento" no significa un sistema forense perfecto. Significa que puedes responder un pequeño conjunto de preguntas de forma rápida y consistente: quién hizo el cambio, qué registro se vio afectado, qué cambió, cuándo ocurrió y de dónde vino (UI, importación, API, automatización). Esa claridad es lo que hace que un registro de auditoría sea algo en lo que la gente realmente confía.
Donde los registros de auditoría suelen fallar no suele ser la base de datos. Es la cobertura. El historial se ve bien para ediciones simples, pero aparecen huecos en cuanto el trabajo se hace a velocidad. Los culpables comunes son ediciones en masa, importaciones, jobs programados, acciones de administrador que eluden las pantallas normales (como restablecer contraseñas o cambiar roles) y eliminaciones (especialmente borrados permanentes).
Otro fallo frecuente es mezclar logs de depuración con logs de auditoría. Los logs de depuración están pensados para desarrolladores: ruidosos, técnicos y a menudo inconsistentes. Los registros de auditoría están pensados para responsabilidad: campos consistentes, redacción clara y un formato estable que puedas mostrar a no ingenieros.
Un ejemplo práctico: un gerente de soporte cambia el plan de un cliente, luego una automatización actualiza los datos de facturación más tarde. Si solo registras "cliente actualizado", no puedes saber si lo hizo una persona, un flujo de trabajo o si una importación lo sobreescribió.
Los campos del registro de auditoría que responden quién, qué y cuándo
Un buen registro de auditoría empieza con un objetivo: una persona debe poder leer una entrada y entender lo que ocurrió sin adivinar.
Quién lo hizo
Guarda un actor claro para cada cambio. La mayoría de los equipos se queda en "user id", pero las herramientas internas a menudo cambian datos por más de una puerta.
Incluye un tipo de actor e identificador de actor, para que puedas distinguir entre un miembro del personal, una cuenta de servicio o una integración externa. Si tienes equipos o tenants, también guarda el id de la organización o workspace para que los eventos nunca se mezclen.
Qué ocurrió y en qué registro
Captura la acción (create, update, delete, restore) más el objetivo. "Objetivo" debe ser a la vez legible para humanos y preciso: nombre de la tabla o entidad, id del registro y, idealmente, una etiqueta corta (como un número de orden) para escaneo rápido.
Un conjunto mínimo práctico de campos:
actor_type, actor_id (y actor_display_name si lo tienes)action y target_type, target_idhappened_at_utc (timestamp almacenado en UTC)source (pantalla, endpoint, job, import) e ip_address (solo si es necesario)reason (comentario opcional para cambios sensibles)
Cuándo ocurrió
Almacena la marca temporal en UTC. Siempre. Luego muéstrala en la hora local del visor en la UI de administración. Esto evita discusiones de "dos personas vieron horas diferentes" durante una revisión.
Si manejas acciones de alto riesgo como cambios de rol, reembolsos o exportes de datos, añade un campo "reason". Incluso una nota corta como "Aprobado por manager en ticket 1842" puede convertir una traza de auditoría de ruido a evidencia.
Elige un modelo de datos: registro de eventos vs historial versionado
La primera decisión de diseño es dónde vive la "verdad" del historial de cambios. La mayoría de los equipos acaba con uno de dos modelos: un log de eventos append-only, o tablas de historial versionadas por entidad.
Opción 1: Log de eventos (tabla append-only de acciones)
Un log de eventos es una única tabla que registra cada acción como una nueva fila. Cada fila guarda quién lo hizo, cuándo pasó, qué entidad tocó y una carga útil (a menudo JSON) que describe el cambio.
Este modelo es sencillo de añadir y flexible cuando tu modelo de datos evoluciona. También mapea de forma natural a un feed de actividad de administración porque el feed es básicamente "eventos más recientes primero."
Opción 2: Historial versionado (versiones por entidad)
Un enfoque de historial versionado crea tablas de historia por entidad, como Order_history o User_versions, donde cada actualización crea una nueva instantánea completa (o un conjunto estructurado de campos cambiados) con un número de versión.
Esto facilita los informes puntuales ("¿cómo era este registro el martes pasado?"). También puede parecer más claro para los auditores, porque la línea de tiempo de cada registro es autocontenida.
Una forma práctica de elegir:
- Elige un log de eventos si quieres un solo lugar para buscar, feeds de actividad fáciles y baja fricción cuando aparecen nuevas entidades.
- Elige historial versionado si necesitas líneas de tiempo frecuentes a nivel de registro, vistas punto-en-el-tiempo o diffs por entidad sencillos.
- Si el almacenamiento es una preocupación, los logs de eventos con diffs por campo suelen ser más ligeros que instantáneas completas.
- Si el objetivo principal es reporting, las tablas de versiones pueden ser más simples de consultar que parsear payloads de eventos.
Pase lo que pase, mantén las entradas de auditoría inmutables: sin actualizaciones, sin borrados. Si algo estuvo mal, añade una nueva entrada que explique la corrección.
También considera añadir un correlation_id (o id de operación). Una acción de usuario a menudo dispara múltiples cambios (por ejemplo, "Desactivar usuario" actualiza el usuario, revoca sesiones y cancela tareas pendientes). Un id de correlación compartido te permite agrupar esas filas en una operación legible.
La auditoría fiable empieza con una regla: cada escritura pasa por una sola vía que también escribe un evento de auditoría. Si algunas actualizaciones ocurren en un job en background, una importación o una pantalla de edición rápida que elude el flujo normal de guardado, tus logs tendrán agujeros.
Para creaciones, registra el actor y la fuente (UI, API, importación). Las importaciones son donde los equipos suelen perder el "quién", así que guarda un valor explícito de "realizado por" incluso si los datos vinieron de un archivo o integración. También es útil almacenar los valores iniciales (ya sea un snapshot completo o un pequeño conjunto de campos clave) para poder explicar por qué existe un registro.
Las actualizaciones son más complicadas. Puedes registrar solo los campos cambiados (pequeño, legible y rápido), o almacenar una instantánea completa después de cada guardado (simple de consultar después, pero pesado). Un punto intermedio práctico es almacenar diffs para ediciones normales y snapshots solo para objetos sensibles (como permisos, datos bancarios o reglas de precios).
Las eliminaciones no deben borrar la evidencia. Prefiere un borrado suave (una bandera is_deleted más una entrada de auditoría). Si debes hacer un hard delete, escribe primero el evento de auditoría e incluye una instantánea del registro para que puedas probar qué se eliminó.
Trata la restauración como su propia acción. "Restaurar" no es lo mismo que "Actualizar", y separarlo facilita mucho las revisiones y las comprobaciones de cumplimiento.
Para ediciones en masa, evita una única entrada vaga como "actualizados 500 registros." Necesitas suficiente detalle para responder "¿qué registros cambiaron?" más tarde. Un patrón práctico es un evento padre más eventos hijos por registro:
- Evento padre: actor, herramienta/pantalla, filtros usados y tamaño del lote
- Evento hijo por registro: id del registro, antes/después (o campos cambiados) y resultado (éxito/fallo)
- Opcional: un campo reason compartido (actualización de política, limpieza, migración)
Ejemplo: un líder de soporte cierra masivamente 120 tickets. La entrada padre captura el filtro "status=open, older than 30 days," y cada ticket recibe una entrada hija mostrando status open -> closed.
Almacena qué cambió sin crear un problema de privacidad o de almacenamiento
Cubre cada ruta de escritura
Enruta UI, API, importaciones y jobs a través de un único flujo Write + Audit.
Los registros de auditoría se convierten en basura rápido cuando o bien almacenan demasiado (cada registro completo, para siempre) o demasiado poco (solo "usuario editado"). El objetivo es un registro que sea defendible para cumplimiento y legible por un administrador.
Un valor por defecto práctico es almacenar un diff por campo para la mayoría de las actualizaciones. Guarda solo los campos que cambiaron, con los valores "before" y "after". Esto mantiene el almacenamiento bajo y hace que el feed de actividad sea fácil de escanear: "Status: Pending -> Approved" es más claro que un gran blob.
Mantén snapshots completos para los momentos que importan: creaciones, eliminaciones y transiciones importantes del flujo de trabajo. Una snapshot es más pesada, pero te protege cuando alguien pregunta "¿Cómo era exactamente el perfil del cliente antes de que se eliminara?".
Los datos sensibles necesitan reglas de enmascaramiento, o tu tabla de auditoría se convierte en una segunda base de datos llena de secretos. Reglas comunes:
- Nunca almacenes contraseñas, tokens de API o claves privadas (registra solo "changed")
- Enmascara datos personales como email/teléfono (almacena valores parciales o hasheados)
- Para notas o campos de texto libre, guarda una vista previa corta y una bandera "changed"
- Registra referencias (
user_id, order_id) en lugar de copiar objetos relacionados completos
Los cambios de esquema también pueden romper el historial de auditoría. Si un campo se renombra o elimina más tarde, guarda un fallback seguro como "unknown field" más la clave original del campo. Para campos eliminados, conserva el último valor conocido pero márcalo como "field removed from schema" para que el feed siga siendo honesto.
Finalmente, haz las entradas amigables para humanos. Guarda etiquetas de visualización ("Assigned to") junto con claves crudas ("assignee_id"), y formatea valores (fechas, moneda, nombres de estado).
Patrón paso a paso: implementa auditoría en los flujos de tu app
Una traza fiable no se trata de registrar más. Se trata de usar un patrón repetible en todas partes para no acabar con huecos como "la importación masiva no se registró" o "las ediciones móviles se ven anónimas."
1) Modelo de datos de auditoría una vez
Empieza en tu modelo de datos y crea un pequeño conjunto de tablas que puedan describir cualquier cambio.
Mantenlo simple: una tabla para el evento, una para los campos cambiados y un contexto de actor pequeño.
- audit_event: id, entity_type, entity_id, action (create/update/delete/restore), created_at, request_id
- audit_event_item: id, audit_event_id, field_name, old_value, new_value
- actor_context (o campos en audit_event): actor_type (user/system), actor_id, actor_email, ip, user_agent
2) Añade un sub-proceso compartido "Write + Audit"
Crea un sub-proceso reutilizable que:
- Acepte el nombre de la entidad, id de la entidad, acción y los valores antes/después.
- Escriba el cambio de negocio en la tabla principal.
- Cree un registro en
audit_event.
- Calcule los campos cambiados e inserte filas en
audit_event_item.
La regla es estricta: cada ruta de escritura debe llamar a este mismo sub-proceso. Eso incluye botones de UI, endpoints de API, automatizaciones programadas e integraciones.
3) Genera actor y tiempo en el servidor
No confíes en el navegador para el "quién" y el "cuándo." Lee el actor desde tu sesión de autenticación y genera marcas temporales en el servidor. Si una automatización se ejecuta, pon actor_type a system y guarda el nombre del job como la etiqueta del actor.
4) Prueba con un escenario concreto
Elige un registro concreto (como un ticket de cliente): créalo, edita dos campos (status y assignee), elimínalo y luego restáuralo. Tu feed de auditoría debería mostrar cinco eventos, con dos items de actualización bajo el evento de edición, y el actor y la marca temporal poblados de la misma forma cada vez.
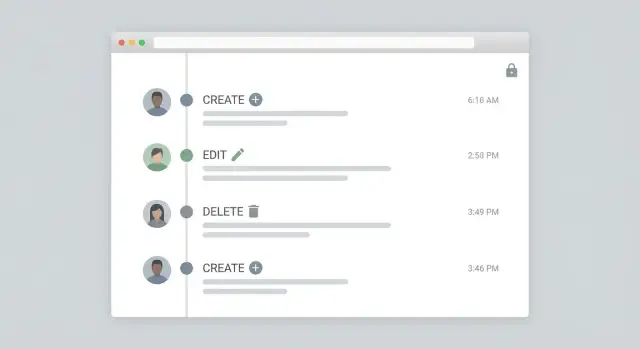
Construye un feed de actividad de administración que la gente pueda usar
Modela tus datos de auditoría rápidamente
Diseña tablas y relaciones de auditoría visualmente pensando en PostgreSQL.
Un registro de auditoría solo es útil si alguien puede leerlo rápido durante una revisión o un incidente. El objetivo del feed de administración es simple: responder "¿qué pasó?" de un vistazo y luego permitir una mirada más profunda sin ahogar a la gente en JSON crudo.
Empieza con un diseño tipo timeline: lo más reciente primero, una fila por evento y verbos claros como Created, Updated, Deleted, Restored. Cada fila debe mostrar el actor (persona o sistema), el objetivo (tipo de registro más un nombre legible) y la hora.
Un formato práctico por fila:
- Verb + objeto: "Updated Customer: Acme Co."
- Actor: "Maya (Support)" o "System: Nightly Sync"
- Hora: timestamp absoluto (con zona horaria)
- Resumen del cambio: "status: Pending -> Approved, limit: 5,000 -> 7,500"
- Tags: Updated, Deleted, Integration, Job
Mantén el "qué cambió" compacto. Muestra 1-3 campos en línea y ofrece un panel de profundización (drawer/modal) que revele detalles completos: valores antes/después, fuente de la petición (web, mobile, API) y cualquier campo de reason/comment.
El filtrado es lo que hace el feed usable después de la primera semana. Enfócate en filtros que respondan preguntas reales:
- Actor (usuario o sistema)
- Tipo de objeto (Customers, Orders, Permissions)
- Tipo de acción (Create/Update/Delete/Restore)
- Rango de fechas
- Búsqueda de texto (nombre del registro o ID)
Los enlaces importan, pero solo cuando esté permitido. Si el visor tiene acceso al registro afectado, muestra una acción "View record". Si no, muestra un placeholder seguro (por ejemplo, "Restricted record") mientras mantienes la entrada de auditoría visible.
Haz las acciones del sistema obvias. Etiqueta jobs programados e integraciones de forma distintiva para que los administradores puedan distinguir "Dana lo eliminó" de "Nightly billing sync lo actualizó."
Permisos y reglas de privacidad para los datos de auditoría
Separa humanos de automatizaciones
Rastrea personal, jobs del sistema e integraciones con tipos de actor claros.
Los registros de auditoría son evidencia, pero también datos sensibles. Trata la auditoría como un producto separado dentro de tu app: reglas de acceso claras, límites definidos y manejo cuidadoso de la información personal.
Decide quién puede ver qué. Una división común es: administradores del sistema ven todo; managers de departamento ven eventos para su equipo; propietarios de registros ven eventos asociados a registros que ya pueden acceder (y nada más). Si expones un feed de actividad, aplica las mismas reglas a cada fila, no solo a la pantalla.
La visibilidad a nivel de fila importa especialmente en herramientas multi-tenant o cross-department. Tu tabla de auditoría debería llevar las mismas claves de scope que los datos de negocio (tenant_id, department_id, project_id), para que puedas filtrar de forma consistente. Ejemplo: un manager de soporte debería ver cambios en tickets de su cola, pero no ajustes salariales en RRHH, incluso si ambos ocurren en la misma app.
Una política simple que funciona en la práctica:
- Admin: acceso completo a auditoría entre tenants y departamentos
- Manager: acceso limitado por
department_id o project_id
- Propietario del registro: acceso solo a los registros que ya puede ver
- Auditor/compliance: solo lectura, exportación permitida, edición bloqueada
- Resto: sin acceso por defecto
La privacidad es la otra mitad. Guarda lo suficiente para probar lo que pasó, pero evita convertir el log en una copia de tu base de datos. Para campos sensibles (SSNs, notas médicas, detalles de pago), prefiere la redacción: registra que el campo cambió sin almacenar el valor antiguo/nuevo. Puedes loggear "email changed" mientras enmascaras el valor real, o almacenar una huella hasheada para verificación.
Mantén los eventos de seguridad separados de los cambios de registros de negocio. Intentos de login, resets de MFA, creación de API keys y cambios de rol deben ir a un stream security_audit con acceso más restrictivo y retención más larga. Las ediciones de negocio (actualizaciones de estado, aprobaciones, cambios de flujo) pueden vivir en un stream general de auditoría.
Cuando alguien solicita la eliminación de datos personales, no borres todo el historial de auditoría. En su lugar:
- Elimina o anonimiza los datos del perfil de usuario
- Reemplaza identificadores de actor en los logs con un seudónimo estable (por ejemplo, "deleted-user-123")
- Redacta los valores almacenados que sean datos personales
- Conserva marcas temporales, tipos de acción y referencias de registro para cumplimiento
Retención, integridad y rendimiento para cumplimiento
Un registro de auditoría útil no es solo "registramos eventos." Para cumplimiento, necesitas demostrar tres cosas: conservaste los datos el tiempo suficiente, no fueron cambiados después y puedes recuperarlos rápido cuando alguien lo solicite.
Retención: decide una política que puedas explicar
Empieza con una regla simple que coincida con tu riesgo. Muchos equipos eligen 90 días para resolución diaria, 1 a 3 años para cumplimiento interno y más tiempo solo para registros regulados. Anota qué reinicia el contador (a menudo: tiempo del evento) y qué se excluye (por ejemplo, logs que incluyen campos que no deberías conservar).
Si tienes múltiples entornos, establece retenciones distintas por entorno. Los logs de producción suelen necesitar la retención más larga; los de test a menudo no necesitan ninguno.
Integridad: dificulta la manipulación
Trata los logs de auditoría como append-only. No actualices filas y no permitas que admins normales las borren. Si un borrado es realmente necesario (solicitud legal, limpieza de datos), registra esa acción también como su propio evento.
Un patrón práctico:
- Solo el servidor escribe eventos de auditoría, nunca el cliente
- Sin permisos UPDATE/DELETE en la tabla de auditoría para roles normales
- Un rol separado "break glass" para purgas raras
- Un snapshot de exportación periódica almacenado fuera de la base de datos principal
Exportes, rendimiento y monitorización
Los auditores suelen pedir CSV o JSON. Planea una exportación que filtre por rango de fechas y tipo de objeto (como Invoice, User, Ticket) para no estar consultando la BD en el peor momento.
Para rendimiento, indexa según cómo buscas:
created_at (consultas por rango de tiempo)object_type + object_id (historial completo de un registro)actor_id (quién hizo qué)
Vigila fallos silenciosos. Si la escritura de auditoría falla, pierdes evidencia y a menudo no lo notas. Añade una alerta simple: si la app procesa escrituras pero los eventos de auditoría caen a cero durante un periodo, notifica a los responsables y registra el error de forma visible.
Errores comunes que hacen inútiles los registros de auditoría
Estandariza eventos de auditoría
Usa procesos de negocio drag and drop para registrar quién hizo qué y por qué.
La forma más rápida de perder tiempo es recopilar muchas filas que no responden a las preguntas reales: quién cambió qué, cuándo y desde dónde.
Una trampa común es apoyarse solo en triggers de base de datos. Los triggers pueden registrar que una fila cambió, pero a menudo pierden el contexto de negocio: qué pantalla usó el usuario, qué petición lo causó, qué rol tenía y si fue una edición normal o una regla automatizada.
Errores que más rompen cumplimiento y usabilidad diaria:
- Registrar payloads completos y sensibles (resets de contraseña, tokens, notas privadas) en lugar de un diff mínimo e identificadores seguros.
- Permitir que gente edite o borre registros de auditoría "para corregir" la historia.
- Olvidar rutas de escritura no UI como importaciones CSV, integraciones y jobs en background.
- Usar nombres de acción inconsistentes como "Updated," "Edit," "Change," "Modify," de modo que el feed suene como ruido.
- Registrar solo el object ID, sin el nombre legible del objeto en el momento del cambio (los nombres cambian después).
Estandariza tu vocabulario de eventos temprano (por ejemplo: user.created, user.updated, invoice.voided, access.granted) y exige que cada ruta de escritura emita un evento. Trata los datos de auditoría como write-once: si alguien hizo un cambio incorrecto, registra una nueva acción correctora en lugar de reescribir la historia.
Checklist rápido y siguientes pasos
Antes de darlo por terminado, ejecuta algunas comprobaciones rápidas. Un buen registro de auditoría es aburrido en el mejor sentido: completo, consistente y fácil de leer cuando algo sale mal.
Usa esta checklist en un entorno de test con datos realistas:
- Cada create, update, delete, restore y bulk edit produce exactamente un evento de auditoría por registro afectado (sin huecos, sin duplicados).
- Cada evento incluye actor (usuario o sistema), timestamp (UTC), acción y una referencia estable del objeto (tipo + ID).
- La vista de "qué cambió" es legible: nombres de campos claros, valores old/new mostrados y campos sensibles enmascarados o resumidos.
- Los administradores pueden filtrar el feed por rango de fechas, actor, acción y objeto, y pueden exportar resultados para revisiones.
- El log es difícil de manipular: solo escritura para la mayoría de roles y los cambios al propio log se bloquean o se auditan por separado.
Si estás construyendo herramientas internas con AppMaster (appmaster.io), una forma práctica de mantener alta la cobertura es enrutar acciones de UI, endpoints de API, importaciones y automatizaciones a través del mismo patrón Business Process que escribe tanto el cambio de datos como el evento de auditoría. Así, tu traza CRUD se mantiene consistente incluso cuando las pantallas y workflows cambian.
Empieza pequeño con un flujo que importe (tickets, aprobaciones, cambios de facturación), deja el feed legible y luego expande hasta que cada ruta de escritura emita un evento de auditoría predecible y buscable.
FAQ
Agrega registros de auditoría tan pronto como la herramienta pueda cambiar datos reales. La primera disputa o solicitud de auditoría suele ocurrir antes de que creas que estás “listo”, y rellenar el historial después es principalmente conjetura.
Un registro de auditoría útil puede responder quién lo hizo, qué registro se tocó, qué cambió, cuándo ocurrió y de dónde vino (UI, API, importación o job). Si no puedes responder a una de esas preguntas rápidamente, el registro no será confiable.
Los logs de depuración son para desarrolladores y suelen ser ruidosos e inconsistentes. Los registros de auditoría son para responsabilidad: necesitan campos estables, redacción clara y un formato que siga siendo legible para no ingenieros con el tiempo.
La cobertura suele fallar cuando los cambios ocurren fuera de la pantalla de edición normal. Ediciones en masa, importaciones, jobs programados, atajos de administrador y eliminaciones son los lugares comunes donde el equipo olvida emitir eventos de auditoría.
Almacena un tipo de actor y un identificador de actor, no solo un user id. De ese modo puedes distinguir claramente a un miembro del personal de un job del sistema, una cuenta de servicio o una integración externa, y evitar la ambigüedad de “alguien lo hizo”.
Almacena las marcas temporales en UTC en la base de datos y luego muéstralas en la zona horaria local del visor en la UI de administración. Esto evita disputas por zonas horarias y hace las exportaciones consistentes entre equipos y sistemas.
Usa un registro de eventos append-only cuando quieras un único lugar para buscar y un feed de actividad sencillo. Usa historial versionado cuando necesites vistas puntuales frecuentes de un solo registro; en muchas apps, un log de eventos con diffs por campo cubre la mayoría de necesidades con menos almacenamiento.
Prefiere eliminaciones blandas y registra explícitamente la acción de eliminar. Si debes hacer un hard delete, escribe primero el evento de auditoría e incluye una instantánea o campos clave para poder probar qué fue eliminado más tarde.
Un valor práctico es almacenar diffs por campo para las actualizaciones y snapshots para creaciones y eliminaciones. Para campos sensibles, registra que el valor cambió sin almacenar el secreto y redacta o enmascara datos personales para que el log no se convierta en una copia de tu base de datos.
Crea un único flujo compartido “write + audit” y fuerza a que cada escritura lo use, incluidos botones de UI, endpoints de API, importaciones y jobs en background. En AppMaster, los equipos suelen implementar esto como un Business Process reutilizable que realiza el cambio de datos y escribe el evento de auditoría en el mismo flujo para evitar huecos.