19 feb 2025·8 min de lectura
Políticas de retención de datos para apps de negocio: ventanas y flujos
Aprende a diseñar políticas de retención de datos para apps de negocio con ventanas claras, archivado y flujos de eliminación o anonimización que mantienen útiles los reportes.
Qué problema resuelve realmente una política de retención
Una política de retención es un conjunto claro de reglas que tu app sigue sobre los datos: qué guardas, cuánto tiempo lo guardas, dónde vive y qué sucede cuando se acaba el tiempo. El objetivo no es “borrar todo”. Es conservar lo necesario para operar el negocio y explicar eventos pasados, mientras se elimina lo que ya no se necesita.
Sin un plan, aparecen rápidamente tres problemas. El almacenamiento crece silenciosamente hasta que empieza a costar dinero real. El riesgo de privacidad y seguridad aumenta con cada copia adicional de datos personales. Y los reportes se vuelven poco fiables cuando los registros antiguos ya no encajan con la lógica actual, o cuando la gente borra cosas ad hoc y los dashboards cambian de repente.
Una política práctica equilibra las operaciones diarias, la evidencia y la protección del cliente:
- Operaciones: la gente puede seguir haciendo su trabajo.
- Evidencia: puedes explicar una transacción más adelante.
- Clientes: no retienes datos personales más tiempo del necesario.
La mayoría de las apps de negocio tienen las mismas áreas de datos en términos generales, aunque usen nombres distintos: perfiles de usuario, transacciones, trazas de auditoría, mensajes y archivos subidos.
Una política es en parte reglas, en parte workflow y en parte herramientas. La regla puede decir: “conservar tickets de soporte por 2 años”. El workflow define qué significa eso en la práctica: mover tickets antiguos a un área de archivo, anonimizar campos de cliente y registrar lo que ocurrió. Las herramientas hacen que sea repetible y auditable.
Si construyes tu app en AppMaster, trata la retención como comportamiento del producto, no como una limpieza puntual. Los Business Processes programados pueden archivar, eliminar o anonimizar datos de la misma forma cada vez, de modo que los reportes sigan siendo consistentes y la gente confíe en los números.
Restricciones que aclarar antes de elegir cualquier ventana temporal
Antes de fijar fechas, aclara por qué conservas los datos. Las decisiones de retención suelen estar determinadas por leyes de privacidad, contratos con clientes y normas de auditoría o fiscales. Saltarte este paso y acabarás o bien guardando demasiado (más riesgo y coste) o borrando algo que luego necesites.
Empieza separando “debo conservar” de “estaría bien tener”. Los datos que debes conservar suelen incluir facturas, asientos contables y logs de auditoría necesarios para probar quién hizo qué y cuándo. Los datos “estaría bien tener” pueden ser transcripciones de chat antiguas, historial detallado de clicks o logs de eventos en crudo que solo usas para análisis ocasionales.
Los requisitos también varían por país e industria. Un portal de soporte para un proveedor de salud tiene restricciones muy distintas a una herramienta administrativa B2B. Incluso dentro de una empresa, usuarios en varios países pueden implicar reglas diferentes para el mismo tipo de registro.
Escribe las decisiones en lenguaje claro y asigna un responsable. “Guardamos tickets 24 meses” no basta. Define qué incluye, qué excluye y qué ocurre al terminar la ventana (archivar, anonimizar, borrar). Asigna una persona o equipo responsable para que las actualizaciones no se estanquen cuando cambien productos o leyes.
Obtén aprobaciones temprano, antes de que ingeniería construya algo. Legal confirma mínimos y obligaciones de eliminación. Seguridad confirma riesgos, controles de acceso y logging. Producto confirma lo que los usuarios todavía necesitan ver. Finanzas confirma necesidades de registro.
Ejemplo: puedes conservar registros de facturación 7 años, guardar tickets 2 años y anonimizar campos de perfil de usuario tras el cierre de cuenta mientras mantienes métricas agregadas. En AppMaster, esas reglas escritas pueden mapearse claramente a procesos programados y a acceso basado en roles, con menos suposiciones después.
Mapea tus datos por tipo, sensibilidad y dónde viven
Las políticas fallan cuando los equipos dicen “conservar 2 años” sin saber qué incluye “eso”. Crea un mapa sencillo de los datos que tienes. No busques la perfección. Busca algo que un líder de soporte y un líder de finanzas puedan entender.
Clasifica por tipo y sensibilidad
Un conjunto de inicio práctico:
- Datos de clientes: perfiles, tickets, pedidos, mensajes
- Datos de empleados: registros de RR.HH., logs de acceso, info de dispositivos
- Datos operativos: workflows, eventos del sistema, logs de auditoría
- Datos financieros: facturas, pagos, campos fiscales
- Contenido y archivos: uploads, exportes, adjuntos
Luego marca la sensibilidad en términos simples: datos personales (nombre, email), financieros (detalles bancarios, tokens de pago), credenciales (hashes de contraseñas, claves API) o datos regulados (por ejemplo, información de salud). Si dudas, etiquétalo como “potencialmente sensible” y trátalo con cautela hasta confirmarlo.
Mapea dónde viven y quién depende de ellos
“Dónde vive” suele ser más que la base de datos principal. Anota la ubicación exacta: tablas de la base de datos, almacenamiento de archivos, logs de email/SMS, herramientas de analytics o data warehouses. También indica quién depende de cada conjunto (soporte, ventas, finanzas, dirección) y con qué frecuencia. Eso te dice qué se romperá si borras con demasiada agresividad.
Un hábito útil: documenta el propósito de cada dataset en una frase. Ejemplo: “Los tickets de soporte se conservan para resolver disputas y seguir tendencias de tiempos de respuesta.”
Si construyes con AppMaster, puedes alinear este inventario con lo que está desplegado revisando tus modelos en Data Designer, manejo de archivos e integraciones habilitadas.
Una vez que el mapa existe, la retención se vuelve una serie de decisiones pequeñas y claras en lugar de una gran suposición.
Cómo establecer ventanas de retención que la gente pueda seguir
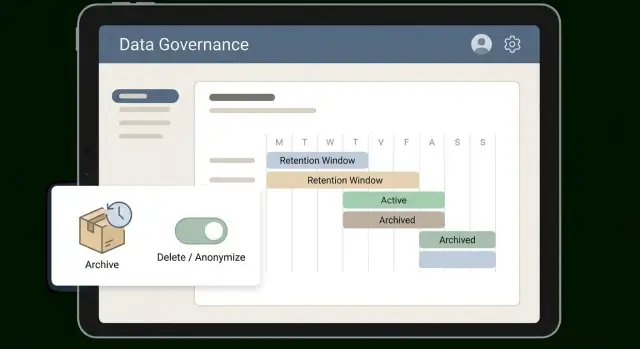
Una ventana solo funciona si es fácil de explicar y aún más fácil de aplicar. Muchos equipos funcionan bien con niveles simples que reflejan el uso de los datos: caliente (uso diario), tibio (uso ocasional), frío (conservado como prueba) y luego eliminar o anonimizar. Esos niveles convierten una política abstracta en una rutina.
Define ventanas por categoría, no un número global. Facturas y registros de pago suelen necesitar un período frío largo por impuestos y auditorías. Las transcripciones de soporte pierden valor rápido.
También decide qué inicia el conteo. “Conservar 2 años” no tiene sentido si no defines “2 años desde qué”. Escoge un disparador por categoría, como fecha de creación, última actividad del cliente, fecha de cierre del ticket o cierre de cuenta. Si los disparadores varían sin reglas claras, la gente adivinará y la retención derivará.
Escribe excepciones desde el principio para que los equipos no improvisen después. Excepciones comunes incluyen legal hold, contracargos y investigaciones por fraude. Estas deben pausar la eliminación, pero no crear copias ocultas.
Mantén las reglas finales cortas y comprobables:
- Chats de soporte: anonimizar 6 meses después del último mensaje salvo que estén en legal hold
- Leads de marketing: borrar 12 meses después de la última actividad si no existe contrato
- Cuentas de cliente: borrar 30 días tras el cierre; conservar facturas 7 años
- Logs de seguridad: conservar 90 días en caliente, 12 meses en frío para investigaciones
- Cualquier registro con
legal_hold=true: no eliminar hasta que se libere
Estrategias de archivado que mantienen los datos útiles y más económicos
Protege tu modelo de reporting
Mantén dashboards estables almacenando agregados y snapshots que no dependan de identificadores personales.
Un archivo no es una copia de seguridad. Las copias son para recuperar tras errores o caídas. Los archivos son deliberados: datos antiguos salen de tus tablas calientes y van a un almacenamiento más barato, pero siguen disponibles para auditorías, disputas y preguntas históricas.
La mayoría de las apps necesitan ambas cosas. Las copias son frecuentes y generales. Los archivos son selectivos y controlados, y normalmente recuperas solo lo que necesitas.
Elige almacenamiento más barato, pero aún buscable
El almacenamiento barato solo ayuda si la gente aún puede encontrar lo que necesita. Muchos equipos usan una base de datos o esquema separado optimizado para consultas de solo lectura, o exportan a archivos más una tabla de índices para búsqueda. Si tu app está modelada alrededor de PostgreSQL (incluido en AppMaster), un esquema “archive” o una base separada puede mantener las tablas de producción rápidas mientras permite reportes permitidos sobre datos archivados.
Antes de elegir el formato, define qué significa “buscable” en tu negocio. Soporte puede necesitar búsqueda por email o ID de ticket. Finanzas puede necesitar totales por mes. Auditorías pueden necesitar rastreos por ID de orden.
Decide qué archivar: registros completos o resúmenes
Los registros completos preservan el detalle, pero cuestan más y aumentan el riesgo de privacidad. Los resúmenes (totales mensuales, conteos, cambios de estado clave) son más baratos y a menudo suficientes para reportes.
Un enfoque práctico:
- Archivar registros completos para objetos críticos de auditoría (facturas, reembolsos, logs de acceso)
- Archivar resúmenes para eventos de alto volumen (clicks, vistas de página, pings de sensores)
- Mantener una pequeña porción de referencia en almacenamiento caliente (normalmente los últimos 30–90 días)
Planea campos de índice desde el inicio. Comunes: ID primaria, ID de usuario/cliente, bucket de fecha (mes), región y estado. Sin esos, los datos archivados existen pero son penosos de recuperar.
Define reglas de restauración también: quién puede pedir una restauración, quién la aprueba, dónde aterriza lo restaurado y tiempos esperados. La restauración puede ser lenta a propósito si eso reduce riesgo, pero debe ser predecible.
Eliminación vs anonimización: elegir el enfoque correcto
Haz de la retención parte del producto
Construye herramientas internas que apliquen las reglas de retención en la app, no en scripts de limpieza ad hoc.
Las políticas suelen forzar una elección: borrar registros o conservarlos removiendo detalles personales. Ambos pueden ser correctos, pero resuelven problemas distintos.
Un borrado duro elimina físicamente el registro. Encaja cuando no tienes ninguna razón legal o de negocio para conservar los datos y su conservación crea riesgo (por ejemplo, transcripciones de chat antiguas con detalles sensibles).
Un borrado suave deja la fila pero la marca como eliminada (a menudo con un timestamp deleted_at) y la oculta en pantallas y APIs normales. Es útil cuando los usuarios esperan poder restaurar o cuando sistemas aguas abajo aún referencian el registro. La desventaja es que los datos siguen existiendo, ocupan espacio y pueden filtrarse en exportes si no tienes cuidado.
La anonimización conserva el evento o transacción pero elimina o reemplaza cualquier dato que identifique a una persona. Hecha correctamente, no se puede revertir. La pseudonimizaciòn es diferente: reemplazas identificadores (como email) por un token pero mantienes un mapeo separado que permite re-identificar. Eso ayuda en investigaciones de fraude, pero no es lo mismo que anonimizar.
Sé explícito sobre datos relacionados, porque aquí es donde las políticas fallan. Borrar un registro pero dejar adjuntos, miniaturas, cachés, índices de búsqueda o copias para analytics puede derrotar silenciosamente el propósito.
También necesitas prueba de que la eliminación ocurrió. Guarda un recibo simple de eliminación: qué se eliminó o anonimizó, cuándo se ejecutó, qué workflow lo corrió y si terminó con éxito. En AppMaster, eso puede ser tan simple como un Business Process escribiendo una entrada de auditoría cuando el job finaliza.
Cómo mantener el valor de los reportes mientras eliminas datos personales
Los reportes se rompen cuando borras o anonimizas registros con los que tus dashboards esperan hacer joins a través del tiempo. Antes de cambiar nada, escribe qué números deben permanecer comparables mes a mes. Si no, acabarás depurando “¿por qué cambió el gráfico del año pasado?” después del hecho.
Empieza con una lista corta de métricas que deben seguir siendo precisas:
- Ingresos y reembolsos por día, semana, mes
- Uso del producto: usuarios activos, conteos de eventos, adopción de funciones
- Métricas SLA: tiempo de respuesta, tiempo de resolución, uptime
- Funnel y tasas de conversión
- Volumen de soporte: tickets, categorías, antigüedad del backlog
Luego rediseña lo que almacenas para reporting de modo que no requiera identificadores personales. La forma más segura es la agregación. En lugar de conservar cada fila cruda para siempre, guarda totales diarios, cohortes semanales y conteos que no puedan rastrearse hasta una persona. Por ejemplo, puedes conservar “tickets creados por día por categoría” y “tiempo medio de primera respuesta por semana” aunque luego elimines el contenido original del ticket.
Mantén claves analíticas estables sin guardar identidades
Algunos reportes necesitan agrupar comportamiento a lo largo del tiempo. Usa una clave analítica sustituta que no sea identificable directamente (por ejemplo, un UUID aleatorio usado solo para analytics) y elimina o protege cualquier mapeo al ID real del usuario una vez que termine la ventana de retención.
También separa tablas operativas de tablas de reporting cuando puedas. Los datos operativos cambian y se borran. Las tablas de reporting deberían ser snapshots append-only o agregados.
Define qué cambia después de la anonimización
La anonimización tiene consecuencias. Documenta qué cambiará para que los equipos no se sorprendan:
- El drill-down por usuario puede dejar de funcionar después de cierta fecha
- Los segmentos históricos pueden quedar como “desconocido” si atributos se eliminan
- La deduplicación puede cambiar si quitas email o teléfono
- Algunas auditorías pueden seguir requiriendo timestamps e IDs no personales
Si construyes en AppMaster, trata la anonimización como un workflow: escribe primero los agregados, verifica las salidas de los reportes y luego anonimiza campos en los registros fuente.
Paso a paso: implementar la política como workflows reales
Entrega un dataset de extremo a extremo
Prototipa la retención en un dataset primero y luego reutiliza el mismo patrón en el resto de tu app.
Una política de retención funciona solo cuando se convierte en comportamiento normal del software. Trátala como cualquier otra característica: define entradas, define acciones y haz visibles los resultados.
Comienza con una matriz de una página. Para cada tipo de dato, registra la ventana de retención, el disparador y qué sucede después (conservar, archivar, eliminar, anonimizar). Si la gente no puede explicarlo en un minuto, no se seguirá.
Añade estados de ciclo de vida claros para que los registros no “desaparezcan misteriosamente”. La mayoría de apps se apañan con tres: active, archived y pending delete. Guarda el estado en el propio registro, no solo en una hoja de cálculo.
Una secuencia de implementación práctica:
- Crea la matriz de retención y guárdala donde producto, legal y ops puedan encontrarla.
- Añade campos de ciclo de vida (estado más fechas como
archived_at y delete_after) y actualiza pantallas y APIs para respetarlos.
- Implementa jobs programados (diarios es común): un job archiva, otro purga o anonimiza lo que pasó la fecha límite.
- Añade una vía de excepción: quién puede pausar la eliminación, por cuánto tiempo y qué motivo debe registrarse.
- Prueba en una copia tipo producción y luego compara reportes clave (conteos, totales, funnels) antes y después.
Ejemplo: los tickets de soporte pueden permanecer activos 90 días, luego pasar a archivados por 18 meses y después anonimizarse. El workflow marca tickets como archivados, mueve adjuntos grandes a almacenamiento barato, conserva IDs y timestamps y reemplaza nombres y emails por valores anónimos.
En AppMaster, los estados de ciclo de vida pueden residir en Data Designer y la lógica de archivo/purga puede ejecutarse como Business Processes programados. La meta es ejecuciones repetibles con logs claros que sean fáciles de auditar.
Errores comunes que causan pérdida de datos o reportes rotos
La mayoría de fallos de retención no vienen de la ventana elegida. Ocurren cuando la eliminación toca las tablas equivocadas, deja archivos relacionados o cambia claves que dependen los reportes.
Un escenario frecuente: un equipo de soporte borra “tickets antiguos” pero olvida adjuntos almacenados en una tabla o en un file store separado. Más tarde, un auditor pide evidencia de un reembolso. El texto del ticket existe, pero las capturas ya no.
Otras trampas comunes:
- Borrar un registro principal pero dejar tablas secundarias (adjuntos, comentarios, logs de auditoría) huérfanas
- Purgar eventos crudos que finanzas, seguridad o cumplimiento aún necesitan para conciliar totales
- Confiar en soft delete para siempre, de modo que la base sigue creciendo y los datos “eliminados” siguen apareciendo en exportes
- Cambiar identificadores durante la anonimización (como
user_id) sin actualizar dashboards, joins y consultas guardadas
- No tener un responsable para excepciones y legal holds, de modo que la gente se salta las reglas
Otro fallo frecuente son reportes construidos sobre claves por persona. Sobreescribir email y nombre suele estar bien. Reemplazar el ID interno puede dividir silenciosamente el historial de una persona en varias identidades, y métricas como usuarios activos mensuales o lifetime value se desviarán.
Dos correcciones ayudan a la mayoría de equipos. Primero, define claves de reporting que nunca cambien (por ejemplo, un ID de cuenta interno) y mantenlas separadas de campos personales que se anonimizarán o borrarán. Segundo, implementa la eliminación como un workflow completo que recorra todos los datos relacionados, incluidos archivos y logs. En AppMaster, esto suele mapearse bien a un Business Process que parte de un usuario o cuenta, recopila dependencias y luego borra o anonimiza en un orden seguro.
Finalmente, decide quién puede pausar la eliminación por legal holds y cómo se registra esa pausa. Si nadie se encarga de las excepciones, la política se aplicará de manera inconsistente.
Comprobaciones rápidas antes de activar cualquier cosa
Construye un portal listo para retención
Lanza un portal de clientes con ciclos de vida de datos previsibles, auditoría y reportes estables.
Antes de ejecutar jobs de eliminación o archivado, haz una comprobación de realidad. La mayoría de fallos ocurren porque nadie sabe quién posee los datos, dónde hay copias o cómo los reportes dependen de ellos.
Una política necesita responsabilidad clara y un plan comprobable, no solo un documento.
Checklist previa al lanzamiento
- Asigna un responsable para cada dataset (una persona que pueda aprobar cambios y responder preguntas).
- Confirma que cada categoría de datos tiene una ventana de retención y un disparador (ejemplo: “90 días tras cierre de ticket” o “2 años tras último login”).
- Prueba que puedes encontrar el mismo registro en todos lados donde aparece: base de datos, almacenamiento de archivos, exportes, logs, copias de analytics y backups.
- Verifica que los archivos siguen siendo útiles: conserva campos mínimos para búsqueda y joins (IDs, fechas, estado) y documenta lo que se elimina.
- Asegúrate de poder producir evidencia: qué se eliminó o anonimizó, cuándo se ejecutó y qué regla siguió.
Una validación sencilla es una ejecución en seco: toma un pequeño lote (por ejemplo, los casos antiguos de un cliente), corre el workflow en un entorno de prueba y compara reportes clave antes y después.
Cómo debería verse la “evidencia”
Guarda la prueba de forma que no reintroduzca datos personales:
- Logs de ejecución con timestamps, nombre de regla y conteos
- Una tabla de auditoría inmutable con IDs de registros y la acción tomada (eliminado o anonimizado)
- Una lista corta de excepciones para items en legal hold
- Un snapshot de reportes mostrando las métricas que esperas que permanezcan estables
Si construyes sobre AppMaster, estas comprobaciones se mapean directamente a la implementación: campos de retención en Data Designer, jobs programados en Business Process Editor y salidas de auditoría claras.
Ejemplo: plan de retención para un portal de clientes que sigue reportando bien
Configura tu matriz de retención
Mapea tus tablas y archivos en Data Designer y luego alinea cada conjunto de datos a ventanas de retención claras.
Imagina un portal de clientes que guarda tickets de soporte, facturas y reembolsos, y logs de actividad cruda (logins, vistas de página, llamadas API). La meta es reducir riesgo y coste de almacenamiento sin romper facturación, auditorías o reportes de tendencias.
Empieza separando datos que debes conservar de datos que solo usas para soporte diario.
Un calendario de retención simple podría ser:
- Tickets de soporte: conservar contenido completo 18 meses tras el cierre del ticket
- Facturas y registros de pago: conservar 7 años
- Logs de actividad cruda: conservar 30 días
- Eventos de auditoría de seguridad (cambios admin, actualizaciones de permisos): conservar 12 meses
Añade un paso de archivo para tickets antiguos. En lugar de conservar cada mensaje para siempre en las tablas principales, mueve los tickets cerrados mayores de 18 meses a un área de archivo con un pequeño resumen buscable: ID de ticket, fechas, área de producto, tags, código de resolución y un extracto corto de la última nota del agente. Eso mantiene contexto sin conservar todos los detalles personales.
Para cuentas cerradas, elige anonimización sobre eliminación cuando aún necesites tendencias. Reemplaza identificadores personales (nombre, email, dirección) por tokens aleatorios, pero conserva campos no identificativos como tipo de plan y totales mensuales. Guarda métricas de uso agregadas (DAU, tickets por mes, ingresos por mes) en una tabla de reporting separada que nunca almacene datos personales.
El reporting mensual cambiará, pero no debería empeorar si lo planeas:
- Las tendencias de volumen de tickets se mantienen porque provienen de tags y códigos de resolución, no del texto completo
- El reporte de ingresos se mantiene estable porque las facturas permanecen
- Tendencias a largo plazo pueden venir de agregados, no de logs en crudo
- Las cohortes pueden pasar de identidad a tokens a nivel de cuenta
En AppMaster, los pasos de archivo y anonimización pueden ejecutarse como Business Processes programados, de modo que la política se ejecute igual cada vez.
Próximos pasos: convierte la política en automatización repetible
Una política funciona cuando la gente puede seguirla y el sistema la hace cumplir de forma consistente. Empieza con una matriz simple de retención: cada dataset, responsable, ventana, disparador, acción siguiente (archivar, eliminar, anonimizar) y firma de aprobación. Revísala con legal, seguridad, finanzas y el equipo de soporte.
No automatices todo a la vez. Elige un dataset end-to-end, idealmente algo común como tickets de soporte o logs de login. Haz real el workflow, ejecútalo durante una semana y confirma que los reportes coinciden con lo que el negocio espera. Luego expande al siguiente dataset usando el mismo patrón.
Mantén la automatización observable. Un monitoreo básico suele cubrir:
- Fallos de jobs (¿corrió y finalizó el archivado o la purga?)
- Crecimiento de archivos (tendencia de uso de almacenamiento)
- Backlog de eliminación (items elegibles pero no procesados)
- Desvío en reportes (métricas clave cambiando tras ejecuciones de retención)
Planifica también el lado visible para usuarios. Decide qué pueden pedir los usuarios (exportar, eliminación, corrección), quién lo aprueba y qué hace el sistema. Da a soporte un guion interno corto: qué datos se ven afectados, cuánto tarda y qué no se puede recuperar después de la eliminación.
Si quieres implementarlo sin escribir código personalizado, AppMaster (appmaster.io) es una opción práctica para automatizar retención porque puedes modelar campos de ciclo de vida en Data Designer y ejecutar Business Processes programados de archivado y anonimización con logging de auditoría. Empieza con un dataset, hazlo aburrido y fiable, y luego repite el patrón en el resto de la app.
FAQ
Una política de retención evita el crecimiento descontrolado de datos y la costumbre riesgosa de “conservarlo todo”. Establece reglas predecibles sobre qué se guarda, por cuánto tiempo y qué ocurre al final, de modo que no se acumulen costos, riesgos de privacidad ni sorpresas en los reportes con el tiempo.
Parte de la pregunta por qué existen los datos y quién los necesita: operaciones, auditorías/impuestos y protección del cliente. Elige ventanas simples por tipo de dato (facturas, tickets, logs, archivos) y obtén aprobaciones tempranas de legal, seguridad, finanzas y producto para no construir workflows que luego haya que deshacer.
Define un disparador claro por categoría, como la fecha de cierre del ticket, la última actividad o la cancelación de la cuenta. Si el disparador es vago, distintos equipos lo interpretarán distinto y la retención derivará, hasta que “2 años” acabe significando cinco cosas distintas.
Usa un flag o estado de legal hold que pause archivado/anonimización/eliminación para registros específicos, y haz que esa retención sea visible y auditables. El objetivo es pausar el flujo normal sin crear copias ocultas que nadie pueda rastrear o explicar después.
Una copia de seguridad sirve para recuperación ante desastres o errores, es amplia y frecuente. Un archivo es una migración deliberada de datos antiguos fuera de las tablas calientes hacia un almacenamiento más barato y controlado que sigue siendo recuperable para auditorías, disputas y consultas históricas.
Elimina cuando no exista razón legal o de negocio para conservar los datos y su mera existencia aumenta el riesgo. Anonimiza cuando necesites conservar el evento o transacción para tendencias o pruebas, pero puedas quitar los campos personales de forma irreversible.
El borrado suave (soft delete) sirve para restaurar y evitar referencias rotas, pero no es una eliminación real. Las filas soft-deleted siguen ocupando espacio y pueden filtrarse en exportes o vistas administrativas si no filtras consistentemente en todas partes.
Protege los reportes almacenando métricas a largo plazo como agregados o snapshots que no requieran identificadores personales. Antes de sobrescribir campos que usa un dashboard (por ejemplo, email), rediseña el modelo de reporting para que las gráficas históricas no cambien tras aplicar la retención.
Trata la retención como una característica de producto: campos de ciclo de vida en los registros, jobs programados para archivar y luego purgar/anonimizar, y entradas de auditoría que prueben lo que ocurrió. En AppMaster esto se mapea claramente a campos en Data Designer y Business Processes programados que ejecutan lo mismo cada vez.
Haz una prueba en pequeño con una copia tipo producción y compara totales clave antes y después. Asegúrate también de que puedes rastrear un registro en todos los lugares donde existe (tablas, almacenamiento de archivos, exportes, logs) y de capturar un recibo de eliminación/anonimización con timestamp, nombre de regla y conteos.