11 abr 2025·8 min de lectura
Configuración mínima de observabilidad para backends y APIs CRUD
Configuración mínima de observabilidad para backends con mucho CRUD: logs estructurados, métricas esenciales y alertas prácticas para detectar consultas lentas, errores y caídas temprano.
Qué problema resuelve la observabilidad en apps con mucho CRUD
Las apps de negocio centradas en CRUD suelen fallar de formas aburridas y costosas. Una página de lista se vuelve más lenta cada semana, un botón de guardar a veces agota el tiempo y el soporte reporta “500 aleatorios” que no puedes reproducir. Nada parece roto en desarrollo, pero en producción todo se siente poco fiable.
El costo real no es solo el incidente. Es el tiempo perdido adivinando. Sin señales claras, los equipos saltan entre “debe ser la base de datos”, “debe ser la red” y “debe ser ese endpoint”, mientras los usuarios esperan y la confianza cae.
La observabilidad convierte esas suposiciones en respuestas. En pocas palabras: puedes ver qué pasó y entender por qué. Se llega allí con tres tipos de señal:
- Logs: qué decidió hacer la app (con contexto útil)
- Métricas: cómo se comporta el sistema a lo largo del tiempo (latencia, tasa de errores, saturación)
- Traces (opcionales): dónde se gastó el tiempo entre servicios y la base de datos
Para apps CRUD y servicios API, se trata menos de dashboards vistosos y más de diagnóstico rápido. Cuando una llamada “Crear factura” se vuelve lenta, deberías poder decir si la demora vino de una consulta a la base de datos, una API downstream o un worker sobrecargado en minutos, no en horas.
Una configuración mínima parte de las preguntas que realmente necesitas responder en un mal día:
- ¿Qué endpoint está fallando o lento, y para quién?
- ¿Es un pico (tráfico) o una regresión (una nueva release)?
- ¿La base de datos es el cuello de botella o la app?
- ¿Esto está afectando usuarios ahora mismo o solo llenando logs?
Si construyes backends con una stack generada (por ejemplo, AppMaster generando servicios Go), la misma regla aplica: comienza pequeño, mantén las señales consistentes y solo añade métricas o alertas nuevas después de que un incidente real demuestre que habrían ahorrado tiempo.
La configuración mínima: qué necesitas y qué puedes omitir
Una configuración mínima de observabilidad tiene tres pilares: logs, métricas y alertas. Los traces son útiles, pero para la mayoría de apps CRUD son un extra.
El objetivo es sencillo. Debes saber (1) cuándo los usuarios fallan, (2) por qué fallan y (3) dónde en el sistema sucede. Si no puedes responder eso rápido, perderás tiempo adivinando y discutiendo qué cambió.
El conjunto más pequeño de señales que normalmente te lleva allí se parece a esto:
- Logs estructurados para cada petición y job en background para poder buscar por
request_id, usuario, endpoint y error.
- Unas pocas métricas centrales: tasa de peticiones, tasa de errores, latencia y tiempo de base de datos.
- Alertas ligadas al impacto en usuario (picos de errores o respuestas lentas sostenidas), no a cada advertencia interna.
También ayuda separar síntomas de causas. Un síntoma es lo que siente el usuario: 500s, timeouts, páginas lentas. Una causa es lo que lo produce: contención de locks, un pool de conexiones saturado o una consulta lenta tras añadir un filtro nuevo. Alerta sobre síntomas y usa señales de “causa” para investigar.
Una regla práctica: elige un único lugar para ver las señales importantes. Cambiar contexto entre una herramienta de logs, una de métricas y una bandeja de alertas separada te ralentiza cuando más importa.
Logs estructurados que se leen bien bajo presión
Cuando algo se rompe, el camino más rápido a una respuesta suele ser: “¿Qué petición exacta ejecutó este usuario?” Por eso un ID de correlación estable importa más que casi cualquier otro ajuste de logs.
Elige un nombre de campo (comúnmente request_id) y trátalo como obligatorio. Généralo en el borde (API gateway o primer handler), pásalo por llamadas internas e inclúyelo en cada línea de log. Para jobs en background, crea un nuevo request_id por ejecución y guarda un parent_request_id cuando un job fue disparado por una llamada API.
Logea en JSON, no en texto libre. Mantiene los logs buscables y consistentes cuando estás cansado, estresado y pasando por encima.
Un conjunto simple de campos es suficiente para la mayoría de servicios API CRUD:
timestamp, level, service, envrequest_id, route, method, statusduration_ms, db_query_counttenant_id o account_id (identificadores seguros, no datos personales)
Los logs deben ayudarte a acotar “qué cliente y qué pantalla”, sin convertirse en una fuga de datos. Evita por defecto nombres, correos, teléfonos, direcciones, tokens o cuerpos completos de petición. Si necesitas más detalle, regístralo solo bajo demanda y con redacción.
Dos campos rinden rápido en sistemas CRUD: duration_ms y db_query_count. Detectan handlers lentos y patrones N+1 incluso antes de añadir tracing.
Define niveles de log para que todos los usen igual:
info: eventos esperados (petición completada, job iniciado)warn: inusual pero recuperable (petición lenta, retry exitoso)error: petición o job fallido (excepción, timeout, dependencia mala)
Si construyes backends con una plataforma como AppMaster, mantiene los mismos nombres de campo entre servicios generados para que “buscar por request_id” funcione en todas partes.
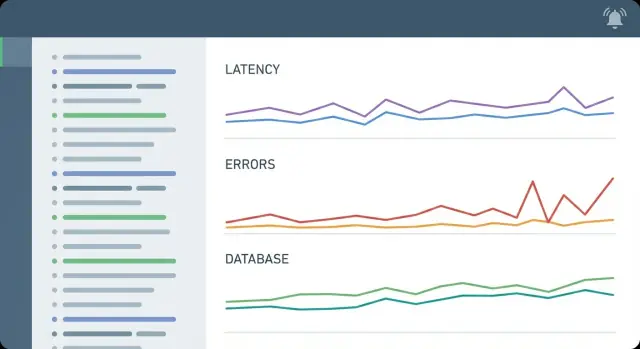
Métricas clave que importan para backends y APIs CRUD
La mayoría de incidentes en apps CRUD tienen una forma familiar: uno o dos endpoints se vuelven lentos, la base de datos se estresa y los usuarios ven spinners o timeouts. Tus métricas deben dejar esa historia obvia en minutos.
Un conjunto mínimo suele cubrir cinco áreas:
- Tráfico: peticiones por segundo (por ruta o al menos por servicio) y tasa de peticiones por clase de estado (2xx, 4xx, 5xx)
- Errores: tasa de 5xx, conteo de timeouts y una métrica separada para “errores de negocio” devueltos como 4xx (para no alertar por errores de usuario)
- Latencia (percentiles): p50 para la experiencia típica y p95 (a veces p99) para detectar “algo está mal”
- Saturación: CPU y memoria, además de saturación específica de la app (utilización de workers, presión de threads/goroutines si la expones)
- Presión en la base de datos: p95 de duración de consultas, conexiones en uso vs máximo del pool y tiempo de espera por locks (o conteos de queries esperando por locks)
Dos detalles hacen que las métricas sean mucho más accionables.
Primero, separa las peticiones interactivas del trabajo en background. Un email sender lento o un bucle de reintentos de webhooks puede acaparar CPU, conexiones DB o red saliente y hacer que la API parezca “aleatoriamente lenta”. Controla colas, reintentos y duración de jobs como series temporales propias, aunque corran en el mismo backend.
Segundo, siempre adjunta metadatos de versión/build a dashboards y alertas. Cuando despliegas un backend generado (por ejemplo, tras regenerar código desde una herramienta sin código como AppMaster), quieres responder una pregunta rápido: ¿subió la tasa de errores o la p95 justo después de esta release?
Una regla simple: si una métrica no puede decirte qué hacer después (revertir, escalar, arreglar una consulta o parar un job), no pertenece a tu conjunto mínimo.
Señales de base de datos: la causa usual del dolor CRUD
Conecta UI con la salud del backend
Envía apps web y móviles junto al backend para que las señales de impacto al usuario se mapeen a pantallas reales.
En apps CRUD, la base de datos suele ser donde “se siente lento” y se vuelve dolor real para el usuario. Una configuración mínima debería dejar claro cuando el cuello de botella es PostgreSQL (no el código API) y de qué tipo es el problema.
Qué medir primero en PostgreSQL
No necesitas docenas de dashboards. Comienza con señales que explican la mayoría de incidentes:
- Tasa de queries lentas y tiempo de consulta p95/p99 (más las queries lentas principales)
- Esperas por locks y deadlocks (quién bloquea a quién)
- Uso de conexiones (conexiones activas vs límite del pool, conexiones fallidas)
- Presión de disco y I/O (latencia, saturación, espacio libre)
- Lag de replicación (si usas réplicas de lectura)
Separa tiempo de app vs tiempo de BD
Añade un histograma de tiempo de consultas en la capa API y etiquétalo con el endpoint o caso de uso (por ejemplo: GET /customers, “search orders”, “update ticket status”). Esto muestra si un endpoint es lento porque ejecuta muchas consultas pequeñas o una grande.
Detecta patrones N+1 temprano
Las pantallas CRUD suelen disparar N+1: una consulta de lista y luego una por fila para datos relacionados. Observa endpoints donde la tasa de peticiones se mantiene pero el conteo de queries por petición sube. Si generas backends desde modelos y lógica, aquí es donde ajustas el patrón de fetch.
Si ya tienes cache, mide la tasa de aciertos. No añadas cache solo para mejorar gráficos.
Trata cambios de esquema y migraciones como una ventana de riesgo. Registra cuándo comienzan y terminan, luego vigila picos en locks, tiempo de consultas y errores de conexión durante esa ventana.
Alertas que despiertan a la persona correcta por la razón correcta
Reduce la deuda técnica con el tiempo
Regenera código conforme cambian los requisitos manteniendo la implementación limpia y escalable.
Las alertas deben señalar un problema real de usuario, no un gráfico ocupado. Para apps CRUD, comienza vigilando lo que los usuarios sienten: errores y lentitud.
Si solo añades tres alertas al principio, hazlas:
- aumento en la tasa de 5xx
- p95 de latencia sostenida
- una caída repentina en peticiones exitosas
Después añade un par de alertas de “causa probable”. Los backends CRUD fallan de formas previsibles: la base de datos se queda sin conexiones, una cola de background se acumula o un endpoint en particular empieza a hacer timeouts y arrastra toda la API.
Umbrales: línea base + margen, no conjeturas
Fijar números duros como “p95 > 200ms” rara vez funciona en todos los entornos. Mide una semana normal y pon la alerta justo por encima con margen de seguridad. Por ejemplo, si p95 suele estar entre 350-450ms en horas laborales, alerta a 700ms por 10 minutos. Si 5xx es típicamente 0.1-0.3%, notifica al 2% por 5 minutos.
Mantén umbrales estables. No los afines cada día. Afínalos después de un incidente, cuando puedas ligar cambios a resultados reales.
Usa dos severidades para que la gente confíe en la señal:
- Pager cuando los usuarios están bloqueados o los datos están en riesgo (5xx altos, timeouts de API, pool de conexiones DB casi agotado).
- Crear un ticket cuando está degradándose pero no es urgente (crecimiento lento de p95, backlog de colas, uso de disco en tendencia al alza).
Silencia alertas durante cambios esperados como ventanas de deploy y mantenimiento planeado.
Haz las alertas accionables. Incluye “qué verificar primero” (endpoint principal, conexiones DB, deploy reciente) y “qué cambió” (nueva release, actualización de esquema). Si construyes en AppMaster, nota qué backend o módulo fue regenerado y desplegado recientemente, porque suele ser la pista más rápida.
SLOs simples para apps de negocio (y cómo moldean las alertas)
Una configuración mínima es más fácil cuando decides qué significa “suficientemente bueno”. Eso es lo que hacen los SLOs: objetivos claros que convierten el monitoreo vago en alertas específicas.
Empieza con SLIs que correspondan a lo que siente el usuario: disponibilidad (pueden completar peticiones), latencia (qué tan rápido terminan las acciones) y tasa de errores (con qué frecuencia fallan las peticiones).
Define SLOs por grupo de endpoints, no por ruta. Para apps CRUD eso mantiene las cosas legibles: lecturas (GET/list/search), escrituras (create/update/delete) y auth (login/refresh token). Evita cientos de SLOs pequeños que nadie mantiene.
Ejemplos de SLOs que encajan con expectativas típicas:
- App CRUD interna (portal admin): 99.5% de disponibilidad por mes, 95% de lecturas bajo 800 ms, 95% de escrituras bajo 1.5 s, tasa de errores bajo 0.5%.
- API pública: 99.9% de disponibilidad por mes, 99% de lecturas bajo 400 ms, 99% de escrituras bajo 800 ms, tasa de errores bajo 0.1%.
El presupuesto de errores es el tiempo “malo” permitido dentro del SLO. Un SLO de disponibilidad mensual del 99.9% significa que puedes permitirte unos ~43 minutos de downtime al mes. Si lo consumes temprano, pausa cambios riesgosos hasta recuperar estabilidad.
Usa los SLOs para decidir qué merece una alerta vs un trend en dashboard. Alerta cuando se queme presupuesto de errores rápido (los usuarios están fallando activamente), no cuando una métrica está un poco peor que ayer.
Si construyes backends rápido (por ejemplo, con AppMaster generando un servicio Go), los SLOs mantienen el foco en impacto al usuario incluso cuando la implementación cambia por debajo.
Paso a paso: construye una observabilidad mínima en un día
Envía una app CRUD que perdure
Construye una herramienta interna o portal de administración y mantiene el rendimiento predecible con una pila consistente.
Empieza con la porción del sistema que más tocan los usuarios. Escoge las llamadas API y jobs que, si están lentos o rotos, hacen que toda la app parezca caída.
Anota tus endpoints y trabajos de background principales. Para una app CRUD de negocio, suele ser login, list/search, create/update y uno o dos jobs de import/export. Si construiste el backend con AppMaster, incluye tus endpoints generados y cualquier Business Process que corra en horarios o webhooks.
Un plan de un día
- Hora 1: Elige tus 5 endpoints principales y 1-2 jobs de fondo. Anota qué significa “bien”: latencia típica, tasa de error esperada, tiempo normal de BD.
- Horas 2-3: Añade logs estructurados con campos consistentes:
request_id, user_id (si está disponible), endpoint, status_code, latency_ms, db_time_ms y un error_code corto para fallos conocidos.
- Horas 3-4: Añade métricas centrales: peticiones por segundo, p95 de latencia, tasa 4xx, tasa 5xx y tiempos de BD (duración de queries y saturación del pool si lo tienes).
- Horas 4-6: Construye tres dashboards: una vista general (salud de un vistazo), una vista detalle de API (desglose por endpoint) y una vista de base de datos (queries lentas, locks, uso de conexiones).
- Horas 6-8: Añade alertas, provoca una falla controlada y confirma que la alerta es accionable.
Mantén las alertas pocas y enfocadas. Quieres alertas que apunten al impacto en usuario, no a “algo cambió”.
Alertas para comenzar (5-8 en total)
Un conjunto inicial sólido: p95 de API demasiado alta, tasa sostenida de 5xx, pico repentino de 4xx (a menudo auth o cambios de validación), fallos de jobs en background, queries DB lentas, conexiones DB cerca del límite y poco espacio en disco (si autohospedas).
Luego escribe un pequeño runbook por alerta. Una página basta: qué comprobar primero (panels del dashboard y campos de logs clave), causas probables (locks en DB, índice faltante, índice incorrecto, servicio downstream caído) y la primera acción segura (reiniciar un worker atascado, revertir un cambio, pausar un job pesado).
Errores comunes que hacen ruidosa o inútil la monitorización
La forma más rápida de desperdiciar una configuración mínima es tratar el monitoreo como una casilla que marcar. Las apps CRUD fallan de formas previsibles (consultas DB lentas, timeouts, releases malos), así que tus señales deben centrarse en eso.
El fallo más común es la fatiga de alertas: demasiadas alertas, poca acción. Si haces paging por cada pico, la gente deja de confiar en las alertas en la segunda semana. Una buena regla: una alerta debe apuntar a una solución probable, no solo a “algo cambió”.
Otro error clásico es no tener IDs de correlación. Si no puedes enlazar un log de error, una petición lenta y una consulta DB a una misma petición, pierdes horas. Asegura que cada petición tenga request_id (y que se incluya en logs, traces si los tienes, y en respuestas cuando sea seguro).
Qué suele crear ruido
Los sistemas ruidosos suelen compartir los mismos problemas:
- Una alerta mezcla 4xx y 5xx, así que errores de cliente y fallos de servidor se ven iguales.
- Las métricas solo rastrean promedios, ocultando la latencia de cola (p95 o p99) donde los usuarios sienten el dolor.
- Los logs incluyen datos sensibles por accidente (passwords, tokens, cuerpos de petición completos).
- Las alertas saltan por síntomas sin contexto (CPU alta) en lugar de impacto en usuario (tasa de errores, latencia).
- Los despliegues son invisibles, así que las regresiones parecen fallos aleatorios.
Las apps CRUD son especialmente vulnerables a la “trampa del promedio”. Una sola consulta lenta puede hacer que el 5% de peticiones sean dolorosas mientras el promedio se ve bien. La latencia en la cola más la tasa de errores dan una imagen más clara.
Añade marcadores de deploy. Si haces shipping desde CI o regeneras código con AppMaster, registra la versión y el tiempo de despliegue como evento y en tus logs.
Lista de comprobación rápida: observabilidad mínima
Pon a prueba tu checklist de incidentes
Prototipa tus 5 endpoints principales rápidamente y valida tus alertas mínimas con tráfico real.
Tu configuración está funcionando cuando puedes responder pocas preguntas rápido, sin hurgar dashboards 20 minutos. Si no puedes obtener un “sí/no” rápido, te falta una señal clave o tus vistas están demasiado dispersas.
Comprobaciones rápidas para un incidente
Deberías poder hacer la mayoría en menos de un minuto:
- ¿Puedes decir si los usuarios están fallando ahora mismo (sí/no) desde una sola vista de errores (5xx, timeouts, jobs fallidos)?
- ¿Puedes detectar el grupo de endpoints más lento y su p95 de latencia, y ver si está empeorando?
- ¿Puedes separar tiempo de app vs tiempo de BD para una petición (tiempo del handler, tiempo de consulta DB, llamadas externas)?
- ¿Puedes ver si la base de datos está cerca del límite de conexiones o de CPU, y si las queries están en cola?
- Si una alerta disparó, ¿sugiere una acción siguiente (revertir, escalar, chequear conexiones DB, inspeccionar un endpoint), no solo “latencia alta"?
Los logs deben ser seguros y útiles a la vez. Necesitan suficiente contexto para seguir una petición fallida entre servicios, pero no deben filtrar datos personales.
Comprobación de sanidad de logs
Elige un fallo reciente y abre sus logs. Confirma que tienes request_id, endpoint, código de estado, duración y un mensaje de error claro. También confirma que no estás registrando tokens crudos, contraseñas, datos completos de pago o campos personales.
Si construyes backends CRUD con AppMaster, apunta a una única “vista de incidente” que combine estas comprobaciones: errores, p95 de latencia por endpoint y salud de la BD. Eso por sí solo cubre la mayoría de las caídas reales en apps de negocio.
Ejemplo: diagnosticar una pantalla CRUD lenta con las señales correctas
Añade características comunes con seguridad
Usa auth e integraciones integradas para evitar pegamento personalizado que complique la monitorización.
Un portal interno de administración va bien toda la mañana y luego se vuelve notablemente lento en la hora punta. Los usuarios se quejan de que abrir la lista de “Orders” y guardar ediciones tarda 10-20 segundos.
Comienzas con señales top. El dashboard de API muestra que la p95 de latencia para endpoints de lectura subió de ~300 ms a 4-6 s, mientras la tasa de errores se mantuvo baja. Al mismo tiempo, el panel de la base de datos muestra conexiones activas cerca del límite del pool y un aumento en esperas por locks. La CPU de los nodos backend parece normal, así que no es un problema de cómputo.
Luego eliges una petición lenta y la sigues por los logs. Filtra por el endpoint (por ejemplo, GET /orders) y ordena por duración. Toma un request_id de una petición de 6 segundos y búscalo en todos los servicios. Ves que el handler terminó rápido, pero la línea de log de la query DB con ese mismo request_id muestra una consulta de 5.4 segundos con rows=50 y un gran lock_wait_ms.
Ahora puedes afirmar la causa con confianza: la lentitud está en la ruta de base de datos (consulta lenta o contención por locks), no en la red o la CPU del backend. Eso es lo que compra una configuración mínima: acotar la búsqueda más rápido.
Arreglos típicos, por orden de seguridad:
- Añadir o ajustar un índice para el filtro/orden usado en la pantalla de lista.
- Eliminar consultas N+1 fetchando datos relacionados en una sola consulta o un join.
- Ajustar el pool de conexiones para no asfixiar la BD bajo carga.
- Añadir cache solo para datos de lectura estables (y documentar las reglas de invalidación).
Cierra el ciclo con una alerta dirigida. Haz paging solo cuando la p95 de latencia del grupo de endpoints se mantenga por encima del umbral durante 10 minutos y el uso de conexiones DB esté por encima (por ejemplo) del 80%. Esa combinación evita ruido y detecta antes este incidente la próxima vez.
Próximos pasos: manténlo mínimo y mejora con incidentes reales
Una configuración mínima de observabilidad debería sentirse aburrida el primer día. Si empiezas con demasiados dashboards y alertas, los afinarás para siempre y aún así perderás los problemas reales.
Trata cada incidente como feedback. Después del arreglo, pregunta: ¿qué habría hecho esto más rápido de detectar y más fácil de diagnosticar? Añade solo eso.
Estandariza temprano, aunque hoy tengas solo un servicio. Usa los mismos nombres de campo en logs y los mismos nombres de métricas en todas partes para que los nuevos servicios coincidan con el patrón sin discusión. También hace que los dashboards sean reutilizables.
Una disciplina pequeña de releases rinde rápido:
- Añade un marcador de deploy (versión, entorno, commit/build ID) para ver si los problemas comenzaron tras una release.
- Escribe un pequeño runbook para las 3 alertas principales: qué significa, primeras comprobaciones y quién lo posee.
- Mantén un dashboard “dorado” con lo esencial para cada servicio.
Si construyes backends con AppMaster, ayuda planear campos de observabilidad y métricas clave antes de generar servicios, para que cada nueva API salga con logs estructurados y señales de salud consistentes por defecto. Si quieres un único lugar para empezar a construir esos backends, AppMaster (appmaster.io) está diseñado para generar backend, web y apps móviles listas para producción manteniendo la implementación consistente conforme cambian los requisitos.
Elige una mejora siguiente a la vez, basada en lo que realmente dolió:
- Añadir temporización de queries DB (y registrar las consultas más lentas con contexto).
- Afinar alertas para que apunten al impacto en usuario, no solo a picos de recursos.
- Hacer un dashboard más claro (renombrar gráficos, añadir umbrales, eliminar paneles sin uso).
Repite ese ciclo tras cada incidente real. En unas semanas tendrás monitorización que encaje con tu app CRUD y el tráfico de tu API en lugar de una plantilla genérica.
FAQ
Empieza con observabilidad cuando los problemas en producción tarden más en explicarse que en solucionarse. Si ves “500s aleatorios”, páginas de lista lentas o timeouts que no puedes reproducir, un pequeño conjunto de logs consistentes, métricas y alertas te ahorrará horas de adivinación.
El monitoreo te dice que algo está mal, mientras que la observabilidad te ayuda a entender por qué pasó, usando señales con contexto que puedas correlacionar. Para APIs CRUD, el objetivo práctico es un diagnóstico rápido: qué endpoint, qué usuario/tenant y si el tiempo se gastó en la app o en la base de datos.
Empieza con logs estructurados por petición, un puñado de métricas centrales y unas pocas alertas enfocadas en impacto al usuario. El tracing puede esperar en muchas apps CRUD si ya registras duration_ms, db_time_ms (o similar) y un request_id estable que puedas buscar en todas partes.
Usa un único campo de correlación como request_id e inclúyelo en cada línea de log de la petición y en cada ejecución de jobs en background. Généralo en el borde (gateway o primer handler), pásalo en llamadas internas y asegúrate de poder buscar logs por ese ID para reconstruir rápidamente una petición fallida o lenta.
Registra timestamp, level, service, env, route, method, status, duration_ms, y identificadores seguros como tenant_id o account_id. Evita por defecto datos personales, tokens y cuerpos completos de petición; si necesitas más detalle, añádelo solo para errores específicos con redacción.
Mide tasa de peticiones, tasa de 5xx, percentiles de latencia (al menos p50 y p95) y saturación básica (CPU/memoria y cualquier presión de workers o colas). Añade tiempo de base de datos y uso del pool de conexiones pronto, porque muchos incidentes CRUD son por contención en la base de datos o agotamiento del pool.
Porque muestran la cola lenta que realmente sufren los usuarios. Los promedios pueden verse bien mientras que p95 es terrible para una fracción significativa de peticiones, que es exactamente cómo las pantallas CRUD se sienten “aleatoriamente lentas” sin errores obvios.
Vigila la tasa de queries lentas y los percentiles de tiempo de consulta, esperas por locks/deadlocks y el uso de conexiones frente al límite del pool. Esas señales te dicen si la base de datos es el cuello de botella y si el problema es rendimiento de consultas, contención o falta de conexiones bajo carga.
Comienza con alertas en síntomas que ven los usuarios: tasa sostenida de 5xx, p95 de latencia sostenida y una caída repentina en peticiones exitosas. Añade alertas orientadas a causas solo después (por ejemplo, conexiones DB cerca del límite o backlog de jobs) para que la señal de on-call siga siendo confiable y accionable.
Adjunta metadatos de versión/build a logs, dashboards y alertas y registra marcadores de despliegue para ver cuándo se envió un cambio. Con backends generados (como servicios Go generados por AppMaster), esto es especialmente importante porque la regeneración y redeploy suelen ser frecuentes y querrás confirmar rápidamente si una regresión empezó justo después de una release.