14 abr 2025·8 min de lectura
Indexación para paneles de administración: optimiza primero los filtros principales
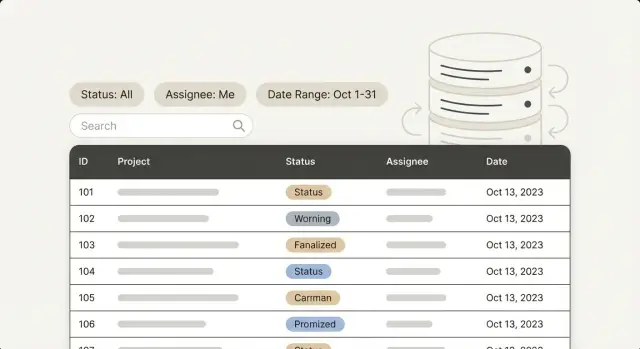
Indexación para paneles de administración: optimiza los filtros que más usan los usuarios: estado, asignado, rangos de fechas y búsqueda de texto, basándote en patrones reales de consultas.
Por qué los filtros del panel de administración se vuelven lentos
Los paneles de administración suelen empezar sintiéndose rápidos. Abres una lista, navegas, haces clic en un registro y sigues. La lentitud aparece cuando la gente filtra como realmente trabaja: "Solo tickets abiertos", "Asignado a Maya", "Creado la semana pasada", "ID de pedido contiene 1047". Cada clic provoca una espera y la lista empieza a sentirse pesada.
La misma tabla puede ser rápida para un filtro y dolorosamente lenta para otro. Un filtro por estado puede tocar un pequeño subconjunto de filas y devolver resultados rápido. Un filtro "creado entre dos fechas" puede obligar a la base de datos a leer un rango enorme. Un filtro por asignado puede ir bien por sí solo y luego ralentizarse cuando lo combinas con estado más ordenación.
Los índices son el atajo que usa la base de datos para encontrar filas coincidentes sin leer toda la tabla. Pero los índices no son gratis. Ocupan espacio y hacen que las inserciones y actualizaciones sean algo más lentas. Añadir demasiados puede ralentizar las escrituras y aun así no solucionar el verdadero cuello de botella.
En lugar de indexarlo todo, prioriza los filtros que:
- se usan constantemente
- tocan muchas filas
- generan esperas perceptibles
- pueden mejorarse de forma segura con índices simples y bien alineados
Esto se mantiene deliberadamente estrecho. Las primeras quejas de rendimiento en listas administrativas casi siempre provienen de los mismos cuatro tipos de filtros: estado, asignado, rangos de fecha y campos de texto. Una vez entiendes por qué se comportan distinto, los siguientes pasos quedan claros: mira los patrones reales de consultas, añade el índice más pequeño que los coincida y verifica que mejoraste el camino lento sin crear nuevos problemas.
Los patrones de consulta detrás del trabajo real en administración
Los paneles de administración rara vez se vuelven lentos por un gran informe único. Se vuelven lentos porque unas pocas pantallas se usan todo el día y esas pantallas ejecutan muchas consultas pequeñas una y otra vez.
Los equipos de operaciones suelen vivir en un puñado de colas de trabajo: tickets, pedidos, usuarios, aprobaciones, solicitudes internas. En estas páginas, los filtros se repiten:
- Estado, porque refleja el flujo de trabajo (Nuevo, Abierto, Pendiente, Hecho)
- Asignado, porque los equipos necesitan "mis elementos" y "sin asignar"
- Rangos de fechas, porque siempre hay alguien que pregunta "¿qué pasó la semana pasada?"
- Búsqueda, ya sea para saltar a un elemento conocido (número de pedido, email) o para escanear texto (notas, vistas previas)
El trabajo que hace la base de datos depende de la intención:
- "Navegar por lo más nuevo" es un patrón de escaneo. Suele ser "mostrar los últimos elementos, tal vez filtrados por estado, ordenados por created_at" y está paginado.
- "Encontrar un elemento específico" es un patrón de búsqueda. El administrador ya tiene un ID, email, número de ticket o referencia y espera que la base de datos salte directamente a un pequeño conjunto de filas.
Los paneles de administración también combinan filtros de formas previsibles: "Abierto + Sin asignar", "Pendiente + Asignado a mí" o "Completado en los últimos 30 días". Los índices funcionan mejor cuando coinciden con esas formas reales de consulta, no cuando solo coinciden con una lista de columnas.
Si construyes herramientas administrativas en AppMaster, estos patrones suelen ser visibles con solo mirar las pantallas de lista más usadas y sus filtros por defecto. Eso facilita indexar lo que realmente impulsa el trabajo diario, no lo que luce bien en papel.
Cómo elegir qué indexar primero
Trata la indexación como triaje. No empieces indexando cada columna que aparece en un desplegable de filtros. Empieza con las pocas consultas que se ejecutan constantemente y que más molestan a la gente.
Encuentra los filtros que la gente realmente usa
Optimizar un filtro que nadie toca es esfuerzo desperdiciado. Para encontrar los caminos calientes reales, combina señales:
- Analítica de UI: qué pantallas reciben más vistas, qué filtros se hacen clic con más frecuencia
- Logs de base de datos o API: consultas más frecuentes y el pequeño porcentaje más lento
- Feedback interno: "la búsqueda es lenta" suele apuntar a una pantalla específica
- La lista de aterrizaje por defecto: qué se ejecuta en cuanto un administrador abre el panel
En muchos equipos, esa vista por defecto es algo como "Tickets abiertos" o "Pedidos nuevos". Se ejecuta cada vez que alguien refresca, cambia de pestaña o vuelve tras responder.
Antes de añadir un índice, agrupa tus consultas comunes por cómo se comportan. La mayoría de consultas de listas administrativas caen en unos pocos grupos:
- Filtros por igualdad:
status = 'open', assignee_id = 42
- Filtros por rango:
created_at entre dos fechas
- Ordenación y paginación:
ORDER BY created_at DESC y obtener la página 2
- Búsquedas de texto: coincidencia exacta (número de pedido), prefijo (email empieza por), o búsqueda por contenido
Escribe la forma de cada pantalla principal, incluyendo WHERE, ORDER BY y paginación. Dos consultas que parecen similares en la UI pueden comportarse muy distinto en la base de datos.
Elige un primer lote pequeño
Comienza con un objetivo prioritario: la consulta de lista por defecto que carga primero. Luego elige 2 o 3 consultas más de alta frecuencia. Eso suele ser suficiente para reducir las mayores demoras sin convertir la base de datos en un museo de índices.
Ejemplo: un equipo de soporte abre una lista de Tickets filtrada a status = 'open', ordenada por lo más nuevo, con opcional asignado y rango de fechas. Optimiza primero exactamente esa combinación. Una vez esté rápida, pasa a la siguiente pantalla según uso.
Indexando el filtro de estado sin pasarse
El estado es uno de los primeros filtros que la gente añade y uno de los más fáciles de indexar de forma ineficaz.
La mayoría de campos de estado tienen baja cardinalidad: pocos valores (open, pending, closed). Un índice ayuda más cuando puede reducir los resultados a una pequeña porción de la tabla. Si el 80%–95% de filas comparten el mismo estado, un índice solo en status rara vez cambia mucho. La base de datos aún tiene que leer una gran parte de filas y el índice añade sobrecarga.
Normalmente notarás el beneficio cuando:
- un estado es raro (por ejemplo, escalado)
- el estado se combina con otra condición que reduce mucho el conjunto de resultados
- estado más orden coincide con una vista común de lista
Un patrón común es "muéstrame elementos abiertos, los más recientes primero." En ese caso, indexar el filtro y la ordenación juntos suele superar a indexar status por sí solo.
Las combinaciones que suelen dar retorno primero:
status + updated_at (filtrar por estado, ordenar por cambios recientes)status + assignee_id (vistas de colas de trabajo)status + updated_at + assignee_id (solo si esa vista exacta se usa mucho)
Los índices parciales son un buen punto medio cuando un estado domina. Si "open" es la vista principal, indexa solo las filas abiertas. El índice se mantiene más pequeño y el costo en escrituras es menor.
-- PostgreSQL example: index only open rows, optimized for newest-first lists
CREATE INDEX CONCURRENTLY tickets_open_updated_idx
ON tickets (updated_at DESC)
WHERE status = 'open';
Una prueba práctica: ejecuta la consulta administrativa lenta con y sin el filtro de estado. Si es lenta en ambos casos, un índice solo en estado no la salvará. Enfócate en la ordenación y el segundo filtro que realmente reduce la lista.
Filtrado por asignado: índices de igualdad y combinaciones comunes
Haz que los filtros comunes se sientan instantáneos
Crea herramientas internas que combinen estado, asignado y filtros de fecha con orden consistente.
En la mayoría de paneles, el asignado es un ID de usuario almacenado en el registro: una clave foránea como assignee_id. Ese es un filtro por igualdad clásico y suele ser una victoria rápida con un índice simple.
El asignado también aparece con otros filtros porque refleja cómo trabaja la gente. Un líder de soporte puede filtrar a "Asignado a Alex" y luego acotar a "Abierto" para ver qué queda por atender. Si esa vista es lenta, a menudo necesitas más que un índice de columna única.
Un buen punto de partida es un índice compuesto que refleje la combinación común:
(assignee_id, status) para "mis elementos abiertos"(assignee_id, status, updated_at) si la lista también se ordena por actividad reciente
El orden importa en los índices compuestos. Coloca primero los filtros de igualdad (a menudo assignee_id, luego status) y deja la columna de orden o rango al final (updated_at). Eso coincide con lo que la base de datos puede usar de forma eficiente.
Los elementos sin asignar son una trampa común. Muchos sistemas representan "sin asignar" como NULL en assignee_id, y los gestores filtran mucho por ello. Dependiendo de tu BD y forma de consulta, los NULL pueden cambiar el plan suficiente como para que un índice que funciona bien para asignados sea inútil para sin asignar.
Si sin asignar es un flujo importante, elige un enfoque claro y pruébalo:
- Mantén
assignee_id nullable, pero asegúrate de probar e indexar WHERE assignee_id IS NULL cuando haga falta.
- Usa un valor dedicado (como un usuario especial "Unassigned") solo si encaja en tu modelo de datos.
- Añade un índice parcial para filas sin asignar si la BD lo soporta.
Si construyes un panel en AppMaster, ayuda registrar los filtros y órdenes exactos que usa tu equipo y reflejar esos patrones con un pequeño conjunto de índices bien escogidos en vez de indexar cada campo disponible.
Rangos de fecha: índices que coincidan con cómo filtra la gente
Diseña datos y UI juntos
Diseña datos, UI y lógica juntos para que las mejoras de rendimiento estén ligadas al uso real.
Los filtros por fecha suelen aparecer como presets rápidos como "últimos 7 días" o "últimos 30 días", además de un selector personalizado con fecha de inicio y fin. Parecen simples, pero en tablas grandes pueden desencadenar trabajos muy distintos en la base de datos.
Primero, aclara sobre qué columna de timestamp habla la gente. Usa:
created_at para vistas de "nuevos elementos"updated_at para vistas de "cambios recientes"
Pon un índice btree normal en esa columna. Sin él, cada clic en "últimos 30 días" puede convertirse en un escaneo completo de la tabla.
Los rangos preset suelen verse como created_at >= now() - interval '30 days'. Eso es una condición de rango y un índice en created_at puede usarse de forma eficiente. Si la UI además ordena por lo más reciente, hacer que el índice coincida con la dirección del ORDER BY (por ejemplo, created_at DESC en PostgreSQL) puede ayudar en listas de mucho uso.
Cuando los rangos se combinan con otros filtros (status, assignee), sé selectivo. Los índices compuestos son geniales cuando la combinación es común; de lo contrario, añaden coste en escrituras sin devolver beneficios.
Un conjunto práctico de reglas:
- Si la mayoría de vistas filtran por status y luego por fecha,
(status, created_at) puede ayudar.
- Si el status es opcional pero la fecha siempre está presente, mantiene un índice simple en
created_at y evita demasiados compuestos.
- No crees todas las combinaciones. Cada índice nuevo incrementa almacenamiento y enlentece escrituras.
La zona horaria y los límites generan muchos bugs de "registros faltantes". Si los usuarios seleccionan fechas (no horas), decide cómo interpretar la fecha final. Un patrón seguro es inicio inclusivo y fin exclusivo: created_at >= start y created_at < end_next_day. Almacena timestamps en UTC y convierte la entrada del usuario a UTC antes de consultar.
Ejemplo: un admin selecciona del 10 al 12 de enero y espera ver elementos de todo el 12. Si tu consulta usa <= '2026-01-12 00:00', perderás casi todo lo de ese día. El índice está bien, pero la lógica de límites es la errónea.
Campos de texto: búsqueda exacta vs búsqueda por contenido
La búsqueda de texto es donde muchos paneles se ralentizan, porque la gente espera que una caja encuentre todo. La primera solución es separar dos necesidades distintas: coincidencia exacta (rápida y predecible) frente a búsqueda por contenido (flexible pero más pesada).
Coincidencia exacta incluye ID de pedido, número de ticket, email, teléfono o una referencia externa. Son perfectos para índices normales. Si los administradores suelen pegar un ID o email, un índice simple más una consulta por igualdad puede hacerlo instantáneo.
Búsqueda por contenido es cuando alguien escribe un fragmento como "refund" o "john" y espera coincidencias en nombres, notas y descripciones. A menudo se implementa con LIKE %term%. El wildcard inicial impide que un índice btree normal reduzca la búsqueda, así que la BD escanea muchas filas.
Una forma práctica de construir búsqueda sin sobrecargar la BD:
- Prioriza la búsqueda de coincidencia exacta (ID, email, username) y déjala clara.
- Para búsqueda "empieza por" (
term%), un índice estándar puede ayudar y suele ser suficiente para nombres.
- Añade búsqueda por contenido solo cuando los logs o quejas muestren que es necesaria.
- Cuando la añadas, usa la herramienta correcta (full-text de PostgreSQL o índices trigram) en lugar de esperar que un índice normal arregle
LIKE %term%.
Las reglas de entrada importan más de lo que muchos equipos esperan. Reducen carga y hacen resultados consistentes:
- Establece longitud mínima para búsqueda por contenido (por ejemplo, 3+ caracteres).
- Normaliza mayúsculas/minúsculas o usa comparaciones insensibles a mayúsculas de forma consistente.
- Recorta espacios al inicio y al final y colapsa espacios repetidos.
- Trata emails e IDs como exactos por defecto, incluso si se introducen en una caja de búsqueda general.
- Si un término es demasiado amplio, pide al usuario que sea más específico en lugar de ejecutar una consulta enorme.
Un pequeño ejemplo: un gerente busca "ann" para encontrar un cliente. Si el sistema ejecuta LIKE %ann% en notas, nombres y direcciones, puede escanear miles de registros. Si primero compruebas campos exactos (email o ID de cliente) y luego recurres a un índice de texto más inteligente solo cuando haga falta, la búsqueda se mantiene rápida sin convertir cada consulta en un ejercicio pesado para la BD.
Un flujo paso a paso para añadir índices con seguridad
Construye tu panel de administración más rápido
Construye un panel de administración rápido con flujos reales, filtros y paginación en minutos.
Los índices son fáciles de añadir y fáciles de lamentar. Un flujo seguro te mantiene enfocado en los filtros que tus administradores usan y evita índices "quizá útiles" que ralentizan escrituras después.
Empieza con el uso real. Extrae las consultas principales de dos maneras:
- las consultas más frecuentes
- las consultas más lentas
Para paneles administrativos, suelen ser páginas de lista con filtros y orden. A continuación, captura la forma exacta de la consulta tal como la ve la base de datos. Anota el WHERE y el ORDER BY precisos, incluyendo la dirección del orden y las combinaciones comunes (por ejemplo: status = 'open' AND assignee_id = 42 ORDER BY created_at DESC). Pequeñas diferencias pueden cambiar qué índice ayuda.
Usa un bucle simple:
- Elige una consulta lenta y un cambio de índice para probar.
- Añade o ajusta un solo índice.
- Vuelve a medir con los mismos filtros y el mismo orden.
- Comprueba que las inserciones y actualizaciones no se hayan vuelto visiblemente más lentas.
- Mantén el cambio solo si mejora claramente la consulta objetivo.
La paginación merece su propia comprobación. La paginación basada en offset (OFFSET 20000) suele empeorar al avanzar, incluso con índices. Si los usuarios saltan a páginas muy profundas, considera paginación por cursor ("mostrar elementos anteriores a este timestamp/id") para que el índice haga un trabajo consistente en tablas grandes.
Finalmente, conserva un pequeño registro para que la lista de índices siga entendible meses después: nombre del índice, tabla, columnas (y orden) y la consulta que soporta.
Errores comunes de indexación en paneles administrativos
Evita la proliferación de índices
Itera rápidamente en pantallas de administración y mantiene tu lista de índices pequeña y con propósito.
La forma más rápida de hacer que un panel se sienta lento es añadir índices sin comprobar cómo la gente filtra, ordena y pagina realmente. Los índices cuestan espacio y añaden trabajo a cada insert y update.
Errores que aparecen con más frecuencia
Estos patrones causan la mayoría de problemas:
- Indexar cada columna "por si acaso".
- Crear un índice compuesto con el orden de columnas equivocado.
- Ignorar ordenación y paginación.
- Esperar que un índice normal arregle búsquedas
LIKE '%term%'.
- Dejar índices antiguos tras cambios en la UI.
Un escenario común: un equipo de soporte filtra tickets por Status = Open, ordena por updated_at y pagina resultados. Si solo añades un índice en status, la BD puede aún tener que reunir todos los tickets abiertos y ordenarlos. Un índice que coincida con filtro y orden juntos puede devolver la página 1 rápidamente.
Antes y después de cambios en la UI administrativa, haz una revisión corta:
- Enumera los filtros principales y el orden por defecto, luego confirma que hay un índice que coincida con el patrón
WHERE + ORDER BY.
- Busca wildcards iniciales (
LIKE '%term%') y decide si la búsqueda por contenido es realmente necesaria.
- Busca índices duplicados u overlapping.
- Rastrea índices no usados durante un tiempo y elimínalos cuando estés seguro de que no hacen falta.
Si construyes paneles en AppMaster sobre PostgreSQL, haz esta revisión parte del despliegue de nuevas pantallas. Los índices correctos suelen derivar directamente de los filtros y órdenes que tu UI usa.
Comprobaciones rápidas y siguientes pasos
Antes de añadir más índices, confirma que los que ya tienes están ayudando a los filtros exactos que la gente usa todos los días. Un buen panel administrativo se siente instantáneo en los caminos comunes, no en búsquedas ocasionales.
Algunas comprobaciones que detectan la mayoría de problemas:
- Abre las combinaciones de filtros más comunes (estado, asignado, rango de fechas y orden por defecto) y confirma que siguen rápidas a medida que la tabla crece.
- Para cada vista lenta, verifica que la consulta use un índice que coincida tanto con
WHERE como con ORDER BY, no solo con una parte.
- Mantén la lista de índices lo suficientemente pequeña como para explicar en una frase para qué sirve cada índice.
- Observa acciones con muchas escrituras (crear, actualizar, cambio de estado). Si esas se han vuelto más lentas después de indexar, quizá tienes demasiados o índices superpuestos.
- Decide qué significa "buscar" en tu UI: coincidencia exacta, prefijo o contiene. Tu plan de índices tiene que coincidir con esa elección.
Un siguiente paso práctico es escribir tus caminos dorados como frases sencillas, por ejemplo: "Los agentes de soporte filtran tickets abiertos, asignados a mí, últimos 7 días, ordenados por lo más nuevo." Usa esas frases para diseñar un pequeño conjunto de índices que los soporten claramente.
Si aún estás en las primeras etapas, ayuda modelar tus datos y filtros por defecto antes de crear demasiadas pantallas. Con AppMaster (appmaster.io) puedes iterar en vistas administrativas rápido y luego añadir los pocos índices que coincidan con lo que tu equipo realmente usa cuando el uso real haga obvios los caminos calientes.
FAQ
Empieza por las consultas que se ejecutan constantemente: la vista de lista por defecto que ven los administradores al abrir el panel, más los 2–3 filtros que usan todo el día. Mide frecuencia y dolor (las más lentas y las más usadas), y añade índices solo cuando reduzcan claramente la espera en esos patrones de consulta.
Porque distintos filtros obligan a trabajar de formas muy diferentes. Algunos filtros reducen a un pequeño conjunto de filas; otros obligan a leer un rango grande o a ordenar muchos resultados. Una consulta puede aprovechar un índice y otra puede terminar escaneando y ordenando mucha información.
No siempre. Si la mayoría de filas comparten el mismo estado, un índice solo en status suele no ahorrar mucho trabajo. Es más útil cuando un estado es raro, o cuando indexas status junto con el orden o con otro filtro que realmente reduzca el conjunto de resultados.
Usa un índice compuesto que refleje lo que la gente hace: filtrar por status y ordenar por actividad reciente. En PostgreSQL, un índice parcial puede ser una buena solución cuando un estado domina, porque mantiene el índice pequeño y centrado en el flujo común.
Un índice simple en assignee_id suele ser una buena mejora, porque es un filtro por igualdad. Si la vista "mis elementos abiertos" es un flujo clave, un índice compuesto que empiece por assignee_id y luego incluya status (y opcionalmente la columna de orden) suele ir mejor que índices de una sola columna.
Sin asignar suele almacenarse como NULL, y WHERE assignee_id IS NULL puede comportarse distinto a WHERE assignee_id = 123. Si las colas sin asignar importan, prueba esa consulta y diseña una estrategia de índices que la soporte —por ejemplo, un índice parcial para filas sin asignar si tu BD lo permite.
Añade un índice btree en la columna de timestamp que la gente realmente filtra: normalmente created_at para "nuevos" y updated_at para "cambios recientes". Sin ese índice, cada clic en "últimos 30 días" puede convertirse en un escaneo completo de la tabla. Si además ordenas por lo más reciente, hacer que el índice coincida con la dirección del orden puede ayudar.
La mayoría de errores por registros faltantes vienen de los límites de fecha, no de los índices. Un patrón fiable es start inclusivo y end exclusivo: convertir las fechas de usuario a UTC y consultar >= start y < end_next_day, así no eliminas por error los registros del día final.
Porque una búsqueda por "contiene" como LIKE %term% no puede usar un índice btree normal para saltar a las coincidencias, así que suele escanear muchas filas. Trata las búsquedas exactas (ID, email, número de orden) como ruta rápida, y añade búsqueda por contenido solo cuando sea necesaria usando herramientas adecuadas (full-text, trigram) en vez de esperar que un índice normal arregle LIKE %term%.
Agregar demasiados índices aumenta el almacenamiento y enlentece inserts y updates, y aún puedes fallar si el índice no coincide con el patrón WHERE + ORDER BY. Un bucle más seguro es cambiar un índice a la vez, volver a medir la consulta lenta exacta y conservar solo las modificaciones que mejoren claramente el camino crítico.
Si construyes pantallas de administración en AppMaster, registra los filtros y órdenes que más usa tu equipo y añade un pequeño conjunto de índices que reflejen esas vistas reales en lugar de indexar todo campo disponible.