27 nov 2025·8 min de lectura
Flujos de trabajo de larga duración: reintentos, mensajes fallidos y visibilidad
Los flujos de trabajo de larga duración pueden fallar de formas desordenadas. Aprende patrones claros de estado, contadores de reintentos, manejo de mensajes fallidos y dashboards de operadores confiables.
Qué falla en la automatización de larga duración
Los flujos de trabajo de larga duración fallan de forma distinta a las solicitudes rápidas. Una llamada API corta o bien tiene éxito o da un error al instante. Un flujo que dura horas o días puede completar 9 de 10 pasos y aun así dejar un desastre: registros creados a medias, estados confusos y ninguna acción clara siguiente.
Por eso suena tanto “funcionó ayer”. El flujo no cambió, pero su entorno sí. Los flujos de larga duración dependen de que otros servicios se mantengan saludables, de que las credenciales sigan válidas y de que los datos conserven la forma que el flujo espera.
Los modos de fallo más comunes son: timeouts y dependencias lentas (una API de un socio está operativa pero hoy tarda 40 segundos), actualizaciones parciales (registro A creado, registro B no creado y no se puede volver a ejecutar con seguridad), caídas de dependencias (proveedores de email/SMS, pasarelas de pago, ventanas de mantenimiento), callbacks perdidos y tareas programadas que no se ejecutan (un webhook nunca llega, un job de temporizador no se disparó) y pasos humanos que se atascan (una aprobación permanece días y luego reanuda con supuestos obsoletos).
La parte difícil es el estado. Una “solicitud rápida” puede mantener el estado en memoria hasta que termine. Un flujo no puede. Tiene que persistir estado entre pasos y estar listo para reanudar después de reinicios, despliegues o fallos. También debe manejar que el mismo paso se desencadene dos veces (reintentos, webhooks duplicados, reproducciones por operadores).
En la práctica, “fiable” se trata menos de no fallar nunca y más de ser predecible, explicable, recuperable y con responsabilidad clara.
Predecible significa que el flujo reacciona igual cada vez que una dependencia falla. Explicable significa que un operador puede responder, en un minuto, “¿Dónde está atascado y por qué?”. Recuperable significa que puedes reintentar o continuar sin causar daño. Responsabilidad clara significa que cada elemento atascado tiene una acción siguiente obvia: esperar, reintentar, arreglar datos o derivarlo a una persona.
Un ejemplo sencillo: una automatización de onboarding crea un registro de cliente, provisión de acceso y envía un mensaje de bienvenida. Si la provisión funciona pero el envío falla porque el proveedor de email está caído, un flujo fiable registra “Provisionado, mensaje pendiente” y programa un reintento. No reejecuta la provisión a ciegas.
Las herramientas pueden facilitar esto manteniendo la lógica del flujo y los datos persistentes cerca. Por ejemplo, AppMaster te permite modelar el estado del flujo en tus datos (vía Data Designer) y actualizarlo desde Business Processes visuales. Pero la fiabilidad viene del patrón, no de la herramienta: trata la automatización de larga duración como una serie de estados duraderos que sobreviven al tiempo, a fallos y a la intervención humana.
Define estados que la gente pueda leer
Los flujos de larga duración tienden a fallar de formas repetibles: una API de terceros se ralentiza, un humano no ha aprobado algo o un job espera detrás de una cola. Estados claros hacen esas situaciones obvias, para que no se confunda “tarda” con “está roto”.
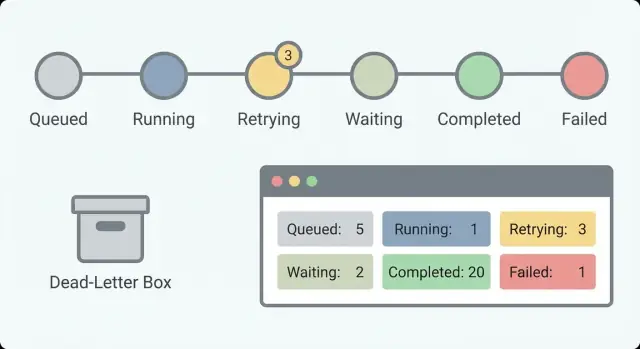
Empieza con un conjunto pequeño de estados que respondan a una pregunta: ¿qué está pasando ahora? Si tienes 30 estados, nadie los memorizará. Con unas 5 a 8, una persona de guardia puede escanear la lista y entenderla.
Un conjunto práctico de estados que funciona en muchos flujos:
- En cola (creado pero no iniciado)
- En ejecución (haciendo trabajo activamente)
- En espera (pausado por un temporizador, callback o entrada humana)
- Completado (terminado)
- Fallado (detenido con un error)
Separar En espera de En ejecución importa. “Esperando la respuesta del cliente” es saludable. “En ejecución durante 6 horas” puede ser un bloqueo. Sin esta separación, perseguirás falsas alarmas y te perderás las reales.
Qué almacenar con cada estado
Un nombre de estado no basta. Añade algunos campos que conviertan un estado en algo accionable:
- Estado actual y hora del último cambio de estado
- Estado anterior
- Una razón breve legible por humanos para fallos o pausas
- Un contador de reintentos opcional o número de intento
Ejemplo: un flujo de onboarding podría mostrar “En espera” con la razón “Pendiente aprobación del gerente” y último cambio “hace 2 días”. Eso indica que no está colgado, pero podría necesitar un recordatorio.
Mantén los estados estables
Trata los nombres de estado como una API. Si los renombras cada mes, los dashboards, alertas y guías de soporte se vuelven confusos rápido. Si necesitas un nuevo significado, considera introducir un estado nuevo y dejar el antiguo para los registros existentes.
En AppMaster puedes modelar estos estados en Data Designer y actualizarlos desde la lógica de Business Processes. Así el estado se mantiene visible y consistente en tu aplicación en vez de estar enterrado en logs.
Reintentos que se detienen a tiempo
Los reintentos ayudan hasta que ocultan el problema real. El objetivo no es “nunca fallar”. El objetivo es “fallar de una manera que la gente pueda entender y arreglar”. Eso empieza con una regla clara de qué es retryable y qué no.
Una regla que la mayoría de equipos puede aceptar: reintenta errores que probablemente sean temporales (timeouts de red, límites de tasa, cortes breves de terceros). No reintentes errores claramente permanentes (entrada inválida, permisos faltantes, “cuenta cerrada”, “tarjeta declineada”). Si no sabes en qué categoría cae un error, trátalo como no retryable hasta aprender más.
Haz que los reintentos sean por paso, no por flujo
Registra contadores de reintentos por paso (o por llamada externa), no solo un contador único para todo el flujo. Un flujo puede tener diez pasos y solo uno ser inestable. Los contadores por paso evitan que un paso posterior “robe” intentos de uno anterior.
Por ejemplo, una llamada “Subir documento” puede reintentarse unas pocas veces, mientras que “Enviar email de bienvenida” no debe seguir intentando indefinidamente solo porque la subida consumió intentos antes.
Backoff, condiciones de paro y acciones siguientes claras
Elige un patrón de backoff que coincida con el riesgo. Retrasos fijos pueden estar bien para reintentos simples y de bajo coste. El backoff exponencial ayuda cuando puedes estar golpeando límites de tasa. Añade un tope para que las esperas no crezcan sin control y un poco de jitter para evitar tormentas de reintentos.
Entonces decide cuándo detenerte. Buenas condiciones de paro son explícitas: intentos máximos, tiempo total máximo o “abandonar para ciertos códigos de error”. Una pasarela de pago que devuelve “tarjeta inválida” debería parar inmediatamente incluso si normalmente permitirías cinco intentos.
Los operadores también necesitan saber qué pasará después. Registra la próxima hora de reintento y la razón (por ejemplo, “Reintento 3/5 a las 14:32 por timeout”). En AppMaster puedes guardar eso en el registro del flujo para que un dashboard muestre “esperando hasta” sin adivinar.
Una buena política de reintentos deja rastro: qué falló, cuántas veces se intentó, cuándo volverá a intentar y cuándo dejará de intentarlo y pasar al manejo de mensajes fallidos.
Idempotencia y protección contra duplicados
En flujos que duran horas o días, los reintentos son normales. El riesgo es repetir un paso que ya funcionó. La idempotencia es la regla que hace esto seguro: un paso es idempotente si ejecutarlo dos veces tiene el mismo efecto que ejecutarlo una vez.
Un fallo clásico: cobras una tarjeta y luego el flujo falla antes de guardar “pago exitoso”. En el reintento cobras de nuevo. Eso es un problema de doble escritura: el mundo exterior cambió pero el estado del flujo no.
El patrón más seguro es crear una clave de idempotencia estable para cada paso con efectos secundarios, enviarla con la llamada externa y guardar el resultado del paso tan pronto como lo recibas. Muchos proveedores de pago y receptores de webhooks soportan claves de idempotencia (por ejemplo, cobrar una orden usando OrderID). Si el paso se repite, el proveedor devuelve el resultado original en vez de repetir la acción.
Dentro del motor de flujos, asume que cada paso puede ser reproducido. En AppMaster eso a menudo significa guardar las salidas de paso en tu modelo de datos y verificarlas en tu Business Process antes de llamar a una integración de nuevo. Si “Enviar email de bienvenida” ya tiene un MessageID registrado, un reintento debe reutilizar ese registro y continuar.
Un enfoque práctico a prueba de duplicados:
- Genera una clave de idempotencia por paso usando datos estables (ID del flujo + nombre del paso + ID de la entidad de negocio).
- Escribe un registro “paso iniciado” antes de la llamada externa.
- Tras el éxito, guarda la respuesta (ID de transacción, ID de mensaje, estado) y marca el paso como “hecho”.
- En un reintento, busca el resultado almacenado y reutilízalo en lugar de repetir la llamada.
- Para casos inciertos, añade una regla de ventana temporal (por ejemplo, “si iniciado y sin resultado después de 10 minutos, consulta el estado del proveedor antes de reintentar”).
Los duplicados aún ocurren, especialmente con webhooks entrantes o cuando un usuario pulsa el mismo botón dos veces. Decide la política por tipo de evento: ignora duplicados exactos (misma clave de idempotencia), fusiona actualizaciones compatibles (por ejemplo, último en escribir vence para un campo de perfil) o márcalo para revisión cuando esté involucrado dinero o riesgo de cumplimiento.
Manejo de mensajes fallidos sin perder contexto
Prevent double writes
Store idempotency keys and step results in your data model to prevent duplicates.
Un mensaje fallido (dead-letter) es un elemento del flujo que falló y se movió fuera de la ruta normal para que no bloquee al resto. Lo conservas a propósito. El objetivo es facilitar entender qué pasó, decidir si es reparable y reprocesarlo de forma segura.
El mayor error es guardar solo un mensaje de error. Cuando alguien vea el dead-letter más tarde, necesita suficiente contexto para reproducir el problema sin adivinar.
Una entrada de dead-letter útil incluye:
- Identificadores estables (customer ID, order ID, request ID, workflow instance ID)
- Entradas originales (o una instantánea segura), más valores derivados clave
- Dónde falló (nombre del paso, estado, último paso exitoso)
- Intentos (contador de reintentos, marcas de tiempo, próximo reintento si aplica)
- Detalles del error (mensaje, código, stack trace si está disponible y payload de respuesta de la dependencia)
La clasificación hace los dead letters accionables. Una categoría breve ayuda a los operadores a elegir el siguiente paso correcto. Grupos comunes: error permanente (regla de lógica, estado inválido), problema de datos (campo faltante, formato incorrecto), dependencia caída (timeout, límite de tasa, corte) y auth/permisos (token expirado, credenciales rechazadas).
El reproceso debe ser controlado. El objetivo es evitar daños repetidos, como cobrar dos veces o spammear emails. Define reglas sobre quién puede reintentar, cuándo reintentar, qué puede cambiar (editar campos específicos, adjuntar un documento faltante, refrescar un token) y qué debe permanecer fijo (request ID y claves de idempotencia downstream).
Haz que los elementos de dead-letter sean buscables por identificadores estables. Cuando un operador pueda escribir “order 18422” y ver el paso exacto, entradas y historial de intentos, las correcciones serán rápidas y consistentes.
Si lo construyes en AppMaster, trata el dead-letter como un modelo de base de datos de primera clase y guarda estado, intentos e identificadores como campos. Así tu panel interno podrá consultar, filtrar y disparar una acción controlada de reproceso.
Visibilidad que te ayuda a diagnosticar problemas
Set retries the safe way
Create step-scoped retries, backoff, and stop rules in a visual Business Process.
Los flujos de larga duración pueden fallar de formas lentas y confusas: un paso espera una respuesta por email, una pasarela de pago hace timeout o un webhook llega dos veces. Si no puedes ver qué hace el flujo ahora, acabarás adivinando. Buena visibilidad convierte “está roto” en una respuesta clara: qué flujo, qué paso, qué estado y qué hacer a continuación.
Empieza haciendo que cada paso emita el mismo pequeño conjunto de campos para que los operadores puedan escanear rápido:
- ID del flujo (y tenant/cliente si aplica)
- Nombre del paso y versión del paso
- Estado actual (en ejecución, en espera, reintentando, fallado, completado)
- Duración (tiempo en el paso y tiempo total en el flujo)
- IDs de correlación para sistemas externos (ID de pago, ID de mensaje, ID de ticket)
Esos campos soportan contadores básicos que muestran la salud de un vistazo. Para flujos de larga duración, los conteos importan más que errores aislados porque buscas tendencias: trabajo acumulándose, picos de reintentos o esperas que nunca terminan.
Haz seguimiento de iniciados, completados, fallados, reintentando y en espera a lo largo del tiempo. Un número pequeño en espera puede ser normal (aprobaciones humanas). Un conteo de espera en aumento suele indicar algo bloqueado. Un aumento en reintentos apunta a un proveedor con problemas o a un bug que repite el mismo error.
Las alertas deben coincidir con la experiencia del operador. En lugar de “ocurrió un error”, alerta sobre síntomas: una acumulación creciente (iniciados menos completados sigue subiendo), demasiados flujos atascados en espera más allá del tiempo esperado, alta tasa de reintentos en un paso específico o un pico de fallos justo después de un despliegue o cambio de configuración.
Mantén una traza de eventos por cada flujo para que “¿qué pasó?” se responda en una vista. Una traza útil incluye marcas de tiempo, transiciones de estado, resúmenes de entradas y salidas (no payloads sensibles completos) y la razón de reintentos o fallo. Ejemplo: “Cobrar tarjeta: reintento 3/5, timeout del proveedor, próximo intento en 10m”.
Los IDs de correlación son el pegamento. Si un cliente dice “me cobraron dos veces”, necesitas conectar tus eventos del flujo con el ID de cargo del proveedor y tu ID interno de orden. En AppMaster puedes estandarizar esto en la lógica de Business Processes generando y pasando IDs de correlación por llamadas API y pasos de mensajería para que dashboard y logs coincidan.
Dashboards y acciones pensadas para operadores
Cuando un flujo dura horas o días, los fallos son normales. Lo que convierte fallos normales en incidentes es un dashboard que solo dice “Falló” y nada más. El objetivo es ayudar a un operador a responder tres preguntas rápido: qué ocurre, por qué ocurre y qué puede hacer con seguridad a continuación.
Empieza con una lista de flujos que facilite encontrar los pocos elementos que importan. Los filtros reducen el pánico y el ruido porque cualquiera puede acotar la vista rápidamente.
Filtros útiles: estado, antigüedad (tiempo desde inicio y tiempo en estado actual), responsable (equipo/cliente/operador responsable), tipo (nombre/versión del flujo) y prioridad si tienes pasos orientados al cliente.
Luego, muestra el “por qué” junto al estado en vez de ocultarlo en logs. Una etiqueta de estado solo ayuda si va acompañada del último mensaje de error, una categoría corta de error y lo que el sistema planea hacer después. Dos campos hacen la mayor parte del trabajo: último error y próxima hora de reintento. Si la próxima hora de reintento está en blanco, deja claro si el flujo está esperando a un humano, pausado o falló permanentemente.
Las acciones de operador deben ser seguras por defecto. Guía a la gente hacia acciones de bajo riesgo primero y deja las acciones de alto riesgo claramente marcadas:
- Reintentar ahora (usa las mismas reglas de reintento)
- Pausar/reanudar
- Cancelar (con motivo requerido)
- Mover a dead-letter
- Forzar continuación (solo si puedes indicar qué se omitirá y qué puede romper)
“Forzar continuación” es donde ocurre la mayoría de los daños. Si la ofreces, describe el riesgo en lenguaje llano: “Esto omite la verificación de pago y puede crear una orden impaga”. También muestra qué datos se escribirán si continúa.
Audita todo lo que hacen los operadores. Registra quién lo hizo, cuándo, el estado antes/después y la nota del motivo. Si construyes herramientas internas en AppMaster, guarda esta traza de auditoría como una tabla de primera clase y muéstrala en la página de detalle del flujo para mantener los traspasos limpios.
Paso a paso: un patrón simple y fiable de flujo
Turn patterns into software
Generate production-ready backend, web, and native mobile apps from one no-code project.
Este patrón mantiene los flujos predecibles: cada elemento siempre está en un estado claro, cada fallo tiene un lugar al que ir y los operadores pueden actuar sin adivinar.
Paso 1: Definir estados y transiciones permitidas. Anota un conjunto pequeño de estados que una persona entienda (por ejemplo: En cola, En ejecución, En espera de externo, Completado, Fallado, Dead-letter). Luego decide qué movimientos son legales para que el trabajo no derive en limbo.
Paso 2: Dividir el trabajo en pasos pequeños con entradas y salidas claras. Cada paso debe aceptar una entrada bien definida y producir una salida (o un error claro). Si necesitas una decisión humana o una llamada a una API externa, conviértelo en su propio paso para que pueda pausar y reanudar limpiamente.
Paso 3: Añadir una política de reintentos por paso. Elige un límite de intentos, un retraso entre intentos y razones de parada que nunca reintentarían (datos inválidos, permiso denegado, campos obligatorios faltantes). Guarda un contador de reintentos por paso para que los operadores vean exactamente qué está atascado.
Paso 4: Persistir el progreso después de cada paso. Tras completar un paso, guarda el nuevo estado y las salidas clave. Si el proceso se reinicia, debe continuar desde el último paso confirmado, no empezar de nuevo.
Paso 5: Enrutar a un registro de dead-letter y soportar reprocesos. Cuando los reintentos se agotan, mueve el ítem a un estado de dead-letter y conserva todo el contexto: entradas, último error, nombre del paso, contador de intentos y marcas de tiempo. El reproceso debe ser deliberado: arregla datos o configuración primero y luego reencola desde un paso específico.
Paso 6: Definir campos del dashboard y acciones de operador. Un buen dashboard responde “qué falló, dónde y qué puedo hacer después?”. En AppMaster puedes construir esto como una app administrativa sencilla respaldada por tus tablas de flujo.
Campos y acciones clave para incluir:
- Estado actual y paso actual
- Conteo de reintentos y próxima hora de reintento
- Último mensaje de error (breve) y categoría de error
- “Re-ejecutar paso” y “Re-encolar flujo”
- “Enviar a dead-letter” y “Marcar como resuelto”
Ejemplo: flujo de onboarding con paso de aprobación humana
Make workflows resumable
Model durable workflow states and persist progress after every step without writing code.
El onboarding de empleados es una buena prueba de estrés. Mezcla aprobaciones, sistemas externos y personas que están fuera de línea. Un flujo simple: RRHH envía un formulario de nueva contratación, el gerente aprueba, TI crea cuentas y el nuevo empleado recibe un mensaje de bienvenida.
Haz los estados legibles. Cuando alguien abra el registro, debe ver de inmediato la diferencia entre “Esperando aprobación” y “Reintentando configuración de cuentas”. Una línea de claridad puede ahorrar una hora de adivinanzas.
Un conjunto claro de estados para UI:
- Borrador (RRHH aún edita)
- Esperando aprobación del gerente
- Provisionando cuentas (con contador de reintentos)
- Notificando al nuevo empleado
- Completado (o Cancelado)
Los reintentos pertenecen a pasos que dependen de redes o APIs de terceros. Provisionar cuentas (email, SSO, Slack), enviar email/SMS y llamar APIs internas son buenos candidatos a reintentos. Mantén visible el contador de reintentos y ponle un tope (por ejemplo, reintentar hasta cinco veces con retrasos crecientes y luego parar).
El manejo de dead-letter es para problemas que no se arreglan solos: no hay gerente en el formulario, dirección de email inválida o una solicitud de acceso que entra en conflicto con la política. Cuando pones un run en dead-letter, guarda contexto: qué campo falló la validación, la última respuesta de la API y quién puede aprobar una excepción.
Los operadores deben tener un conjunto pequeño de acciones sencillas: corregir datos (añadir gerente, corregir email), re-ejecutar un paso fallido (no todo el flujo) o cancelar limpiamente (y deshacer provisiones parciales si es necesario).
Con AppMaster puedes modelar esto en Business Process Editor, mantener contadores de reintentos en datos y construir una pantalla de operador en el web UI builder que muestre estado, último error y un botón para reintentar el paso fallido.
Lista de comprobación y siguientes pasos
La mayoría de los problemas de fiabilidad son previsibles: un paso se ejecuta dos veces, reintentos a las 2 a.m., o un ítem “atascado” sin pista de qué pasó. Una lista de comprobación evita que se convierta en adivinanza.
Comprobaciones rápidas que atrapan la mayoría de problemas temprano:
- ¿Puede una persona no técnica leer cada estado y entenderlo (Esperando pago, Enviando email, Esperando aprobación, Completado, Fallado)?
- ¿Están los reintentos acotados con límites claros (intentos máximos, tiempo máximo) y cada intento incrementa un contador visible?
- ¿Se guarda el progreso tras cada paso para que un reinicio continúe desde el último punto confirmado?
- ¿Es cada paso idempotente o está protegido contra duplicados con una clave de solicitud, un bloqueo o un chequeo de “ya hecho”?
- Cuando algo va a dead-letter, ¿conserva suficiente contexto para arreglar y re-ejecutar con seguridad (datos de entrada, nombre del paso, marcas de tiempo, último error y una acción controlada de re-ejecución)?
Si solo puedes mejorar una cosa, mejora la visibilidad. Muchos “bugs de flujo” son en realidad “no podemos ver qué está haciendo”. Tu dashboard debe mostrar qué pasó último, qué pasará después y cuándo. Una vista práctica para operadores incluye estado actual, último mensaje de error, contador de intentos, próxima hora de reintento y una acción clara (reintentar ahora, marcar como resuelto o enviar a revisión manual). Mantén las acciones seguras por defecto: re-ejecutar un paso, no todo el flujo.
Siguientes pasos:
- Dibuja primero tu modelo de estados (estados, transiciones y cuáles son terminales).
- Escribe reglas de reintentos por paso: qué errores reintentan, cuánto esperar y cuándo parar.
- Decide cómo evitarás duplicados: claves de idempotencia, restricciones únicas o guardias de “comprobar y actuar”.
- Define el esquema del registro de dead-letter para que humanos puedan diagnosticar y re-ejecutar con confianza.
- Implementa el flujo y el dashboard de operadores en una herramienta como AppMaster, luego prueba con fallos forzados (timeouts, entradas malas, cortes de terceros).
Trátalo como una lista viva. Cada vez que añadas un paso nuevo, corre estas comprobaciones antes de que llegue a producción.
FAQ
Los flujos de trabajo de larga duración pueden completar la mayor parte del proceso y fallar al final, dejando cambios parciales. Además dependen de elementos que pueden cambiar mientras se ejecutan: disponibilidad de terceros, credenciales, formato de datos y tiempos de respuesta humanos.
Mantén el conjunto de estados pequeño y legible para que un operador lo entienda de un vistazo. Un buen conjunto por defecto es: en cola, en ejecución, en espera, completado y fallado; separa claramente “en espera” de “en ejecución” para distinguir pausas saludables de bloqueos.
Guarda lo suficiente para que el estado sea accionable: el estado actual, cuándo cambió por última vez, cuál fue el estado anterior y una breve razón cuando esté en espera o haya fallado. Si hay reintentos, registra también el conteo de intentos y la próxima hora planificada de reintento.
Evita falsas alarmas y errores no detectados. “Esperando aprobación” o “esperando un webhook” puede ser normal, mientras que “en ejecución durante seis horas” puede indicar un bloqueo. Tratar estos casos como estados distintos mejora las alertas y la toma de decisiones.
Reintenta errores que probablemente sean temporales, como timeouts, límites de tasa o cortes breves. No reintentes errores claramente permanentes: datos inválidos, permisos faltantes o un pago rechazado; repetir solo desperdicia intentos y puede causar efectos secundarios.
Los reintentos por paso evitan que una integración inestable consuma todos los intentos del flujo entero. También facilitan el diagnóstico porque ves exactamente qué paso falla, cuántas veces se intentó y si otros pasos funcionan correctamente.
Elige un backoff que se ajuste al riesgo y ponle un tope para que las esperas no crezcan indefinidamente. Define reglas explícitas para detenerse: número máximo de intentos, tiempo total máximo o códigos de error que nunca deben reintentarse. Registra la razón y la próxima hora de reintento para dejar claro el siguiente paso.
Asume que cualquier paso puede ejecutarse dos veces y evita daños. Una práctica común es usar una clave de idempotencia estable por paso, escribir un registro “paso iniciado” antes de la llamada externa y guardar el resultado inmediatamente para que reintentos posteriores reutilicen la respuesta en lugar de repetir la acción.
Un registro de mensajes fallidos debe permitir reproducir y corregir el problema: identificadores estables, entradas originales o una instantánea segura, dónde falló (nombre del paso, último paso exitoso), historial de intentos y la respuesta de la dependencia, no solo un mensaje genérico.
Los paneles más útiles muestran dónde está el flujo, por qué está ahí y qué sucederá a continuación: ID del flujo, paso actual, estado, tiempo en el estado, último error y IDs de correlación. Ofrece acciones seguras por defecto, como reintentar un solo paso o pausar/resumir, y etiqueta explícitamente las acciones de alto riesgo.