30 nov 2025·8 min de lectura
Errores en el diseño drag-and-drop de procesos y cómo refactorizar
Los errores en el diseño drag-and-drop pueden hacer que los flujos sean difíciles de cambiar y fáciles de romper. Aprende antipatrones comunes y pasos prácticos para refactorizar.
Por qué los flujos drag-and-drop salen mal
Los editores de procesos visuales parecen seguros porque puedes ver todo el diagrama. Pero el diagrama aún puede mentir. Un flujo puede verse ordenado y fallar en producción cuando aparecen usuarios reales, datos reales y problemas de tiempo reales.
Muchos problemas vienen de tratar el diagrama como una lista de verificación en lugar de lo que realmente es: un programa. Los bloques siguen conteniendo lógica. Siguen creando estado, ramificándose, reintentando y provocando efectos secundarios. Cuando esas partes no se hacen explícitas, las ediciones “pequeñas” pueden cambiar el comportamiento en silencio.
Un antipatrón de flujo es una forma mala y repetible que sigue causando problemas. No es un solo bug. Es un hábito, como ocultar estado importante en variables definidas en una esquina del diagrama y usadas en otra, o dejar que el flujo crezca hasta que nadie pueda razonar sobre él.
Los síntomas son familiares:
- La misma entrada produce resultados diferentes en distintas ejecuciones
- Depurar se convierte en adivinanza porque no puedes saber dónde cambió un valor
- Pequeñas ediciones rompen caminos no relacionados
- Las correcciones añaden más ramas en lugar de reducirlas
- Las fallas dejan actualizaciones parciales (algunos pasos tuvieron éxito, otros no)
Empieza por lo barato y visible: nombres más claros, agrupación más estricta, eliminar rutas muertas y hacer obvio los inputs y outputs de cada paso. En plataformas como AppMaster, eso suele significar mantener un Business Process enfocado, de modo que cada bloque haga un trabajo y pase datos de forma abierta.
Luego planifica refactorizaciones más profundas para problemas estructurales: desenredar flujos espagueti, centralizar decisiones y añadir compensaciones para éxitos parciales. El objetivo no es un diagrama más bonito. Es un flujo que se comporte igual cada vez y que sea seguro de cambiar cuando cambien los requisitos.
Estado oculto: la fuente silenciosa de sorpresas
Muchas fallas en flujos visuales comienzan con un problema invisible: estado del que dependes pero que nunca nombras claramente.
Estado es cualquier cosa que tu flujo necesite recordar para comportarse correctamente. Eso incluye variables (como customer_id), banderas (como is_verified), temporizadores y reintentos, y también estado fuera del diagrama: una fila de base de datos, un registro CRM, el estado de un pago o un mensaje que ya fue enviado.
El estado oculto aparece cuando esa “memoria” vive en un lugar que no esperas. Ejemplos comunes son configuraciones de nodo que silenciosamente se comportan como variables, valores predeterminados implícitos que nunca configuraste a propósito, o efectos secundarios que cambian datos sin hacerlo obvio. Un paso que “verifica” algo pero también actualiza un campo de estado es una trampa clásica.
Suele funcionar hasta que haces una pequeña edición. Mueves un nodo, reutilizas un subflujo, cambias un predeterminado o añades una nueva rama. De repente el flujo empieza a comportarse “aleatoriamente” porque una variable se sobrescribe, una bandera nunca se reinició o un sistema externo devuelve un valor ligeramente distinto.
Dónde se oculta el estado (incluso en diagramas que parecen limpios)
El estado tiende a esconderse en:
- Configuraciones de nodo que actúan como variables (IDs hardcodeados, estados por defecto)
- Salidas implícitas de pasos anteriores (“usar último resultado”)
- Pasos de “lectura” que también escriben (actualizaciones en BD, cambios de estado)
- Sistemas externos (pagos, proveedores de email/SMS, CRMs) que recuerdan acciones pasadas
- Temporizadores y reintentos que siguen ejecutándose después de que una rama cambie
La regla que previene la mayoría de las sorpresas
Haz el estado explícito y nombrado. Si un valor importa más adelante, guárdalo en una variable claramente nombrada, asígnalo en un solo lugar y resétalo cuando hayas terminado.
Por ejemplo, en el Business Process Editor de AppMaster, trata cada salida importante como una variable de primera clase, no como algo que “sabes” que está disponible porque un nodo corrió antes. Un pequeño cambio como renombrar status a payment_status, y asignarlo solo después de una respuesta de pago confirmada, puede ahorrar horas de debugging cuando el flujo cambie el mes siguiente.
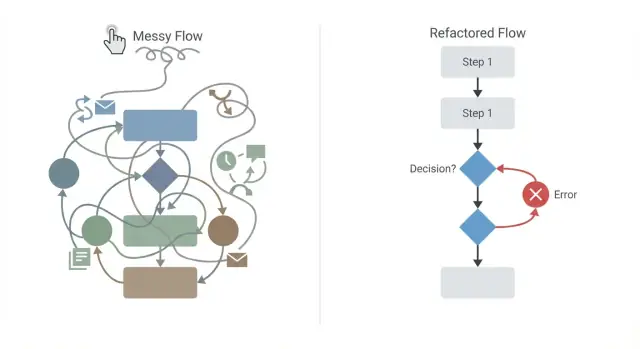
Flujos espagueti: cuando el diagrama se vuelve ilegible
Un flujo espagueti es un proceso visual donde los conectores se cruzan por todas partes, los pasos regresan en lugares sorprendentes y las condiciones están anidadas tan profundo que nadie puede explicar el camino feliz sin hacer zoom y desplazar. Si tu diagrama parece un mapa de metro dibujado en una servilleta, ya estás pagando el precio.
Esto hace que las revisiones sean poco fiables. La gente pasa por alto casos límite, las aprobaciones tardan más y un cambio en una esquina puede romper algo muy lejos. Durante un incidente, es difícil responder preguntas básicas como “¿qué paso se ejecutó por último?” o “¿por qué entramos a esta rama?”.
El espagueti suele crecer por buenas intenciones: copiar-pegar una rama que funciona “solo una vez”, añadir arreglos rápidos bajo presión, apilar manejo de excepciones como condiciones anidadas, volver atrás a pasos anteriores en vez de crear un subproceso reutilizable, o mezclar reglas de negocio, formateo de datos y notificaciones dentro del mismo bloque.
Un ejemplo común es el onboarding. Empieza limpio y luego crece ramas separadas para pruebas gratuitas, referencias de socios, revisión manual y manejo “VIP”. Después de unas pocas iteraciones, el diagrama tiene múltiples retrocesos a “Recopilar docs” y varios lugares distintos que envían el correo de bienvenida.
Un objetivo más sano es simple: un camino principal para el caso común, más rutas laterales claras para excepciones. En herramientas como el Business Process Editor de AppMaster, eso suele significar extraer lógica repetida a un subproceso reutilizable, nombrar ramas por intención (“Necesita revisión manual”) y mantener los bucles explícitos y limitados.
Sobrecarga de decisiones y reglas duplicadas
Un patrón común es una larga cadena de nodos de condición: verifica A, luego verifica A de nuevo más tarde, luego verifica B en tres lugares distintos. Empieza como “solo una regla más” y termina con un flujo que es un laberinto donde pequeños cambios tienen grandes efectos secundarios.
El riesgo mayor son las reglas dispersas que poco a poco discrepan. Un camino aprueba una solicitud porque el score de crédito es alto. Otro camino bloquea la misma solicitud porque un paso anterior aún trata “número de teléfono faltante” como bloqueo. Ambas decisiones pueden ser “razonables” localmente, pero juntas producen resultados inconsistentes.
Por qué las comprobaciones duplicadas causan conflictos
Cuando la misma regla se repite por el diagrama, la gente actualiza una copia y se olvida de las otras. Con el tiempo obtienes comprobaciones que se parecen pero no son iguales: una dice “country = US”, otra dice “country in (US, CA)” y una tercera usa “currency = USD” como sustituto. El flujo sigue corriendo, pero deja de ser predecible.
Un buen refactor es consolidar decisiones en un único paso de decisión claramente nombrado que produzca un conjunto pequeño de resultados. En herramientas como el Business Process Editor de AppMaster, eso suele significar agrupar comprobaciones relacionadas en un solo bloque de decisión y hacer que las ramas tengan sentido.
Mantén los resultados simples, por ejemplo:
- Aprobado
- Necesita información
- Rechazado
- Revisión manual
Luego enruta todo a través de ese único punto de decisión en lugar de esparcir mini-decisiones por todo el flujo. Si una regla cambia, la actualizas una vez.
Un ejemplo concreto: un flujo de verificación de registro comprueba el formato de email en tres lugares (antes del OTP, después del OTP y antes de crear la cuenta). Mueve toda la validación a una sola decisión “Validar solicitud”. Si es “Necesita información”, enruta a un solo paso de mensaje que diga exactamente qué falta, en lugar de fallar después con un error genérico.
Falta de pasos de compensación tras éxitos parciales
Refactoriza con un backend real
Construye backend y flujo juntos para que el estado y los efectos secundarios permanezcan visibles.
Uno de los errores más caros es asumir que cada flujo o bien tiene éxito completamente o bien falla por completo. Los flujos reales a menudo tienen éxito a medias. Si un paso posterior falla, te quedas con un desastre: dinero cobrado, mensajes enviados, registros creados, pero sin una manera limpia de deshacerlo.
Ejemplo: cobras la tarjeta de un cliente y luego intentas crear la orden. El pago se procesa, pero la creación de la orden falla porque un servicio de inventario hace timeout. Ahora soporte recibe el correo enojado, finanzas ve el cargo y tu sistema no tiene una orden correspondiente para cumplir.
La compensación es la ruta de “deshacer” (o “hacer seguro”) que se ejecuta cuando algo falla después de un éxito parcial. No necesita ser perfecta, pero sí intencional. Enfoques típicos incluyen revertir la acción (reembolso, cancelar, borrar un borrador), convertir el resultado en un estado seguro (marcar “Pago capturado, cumplimiento pendiente”), enrutar a revisión manual con contexto y usar comprobaciones de idempotencia para que los reintentos no cobren o envíen duplicados.
Dónde colocas la compensación importa. No ocultes toda la limpieza en una sola caja de “error” al final del diagrama. Colócala cerca del paso riesgoso, cuando aún tengas los datos necesarios (ID de pago, token de reserva, ID de petición externa). En herramientas como AppMaster, eso suele significar guardar esos IDs justo después de la llamada y ramificar inmediatamente por éxito vs fallo.
Una regla útil: cada paso que hable con un sistema externo debe responder dos preguntas antes de continuar: “¿Qué cambiamos?” y “¿Cómo deshacemos o contenemos esto si el siguiente paso falla?”
Manejo débil de errores alrededor de llamadas externas
Muchas fallas aparecen en el momento en que tu flujo sale de tu sistema. Las llamadas externas fallan de maneras desordenadas: respuestas lentas, outages temporales, peticiones duplicadas y éxitos parciales. Si tu diagrama asume “la llamada tuvo éxito” y sigue adelante, los usuarios acabarán viendo datos faltantes, cargos duplicados o notificaciones enviadas en el momento equivocado.
Empieza marcando los pasos que pueden fallar por razones que no controlas: APIs externas, pagos y reembolsos (por ejemplo, Stripe), mensajes (email/SMS, Telegram), operaciones de archivos y servicios en la nube.
Dos trampas son especialmente comunes: falta de timeouts y reintentos ciegos. Sin timeout, una petición lenta puede congelar todo el proceso. Con reintentos pero sin reglas, puedes empeorar las cosas, como enviar el mismo mensaje tres veces o crear duplicados en un sistema de terceros.
Aquí es donde la idempotencia importa. En términos simples, una acción idempotente es segura de ejecutar otra vez. Si el flujo repite un paso, no debería crear un segundo cargo, una segunda orden o un segundo mensaje de bienvenida.
Una solución práctica es almacenar una clave de petición y un estado antes de llamar. En el Business Process Editor de AppMaster, eso puede ser tan simple como escribir un registro como "payment_attempt: key=XYZ, status=pending" y luego actualizarlo a "success" o "failed" tras la respuesta. Si el flujo llega al paso otra vez, comprueba ese registro primero y decide qué hacer.
Un patrón fiable se ve así:
- Fija un timeout y límites de reintento (y define qué errores son reintentables)
- Guarda una clave de petición y el estado actual antes de la llamada
- Haz la llamada externa
- En caso de éxito, escribe el resultado y marca el estado como completado
- En caso de fallo, registra el error y enruta a una vía de recuperación amigable para el usuario
Pasos sobrecargados y responsabilidades poco claras
Lanza workflows con web y móvil
Construye apps de extremo a extremo donde flujos, UI y datos permanezcan sincronizados.
Un error común es construir un único paso que silenciosamente hace cuatro trabajos: validar entrada, calcular valores, escribir en la base de datos y notificar a las personas. Parece eficiente, pero hace que los cambios sean riesgosos. Cuando algo falla, no sabes qué parte lo provocó y no puedes reutilizarlo de forma segura en otro lugar.
Cómo detectar un paso sobrecargado
Un paso está sobrecargado cuando su nombre es vago (como “Handle order”) y no puedes describir su salida en una sola frase. Otra señal es una larga lista de entradas que solo son usadas por “alguna parte” del paso.
Los pasos sobrecargados a menudo mezclan:
- Validación y mutación (guardar/actualizar)
- Reglas de negocio y presentación (formateo de mensajes)
- Varias llamadas externas en un solo lugar
- Varios efectos secundarios sin un orden claro
- Criterios de éxito poco claros (¿qué significa “hecho”?)
Refactoriza en bloques pequeños con contratos claros
Divide el paso grande en bloques más pequeños y nombrados donde cada bloque tenga un trabajo y una entrada/salida claras. Un patrón de nombres simple ayuda: verbos para pasos (Validar dirección, Calcular total, Crear factura, Enviar confirmación) y sustantivos para objetos de datos.
Usa nombres consistentes para inputs y outputs también. Por ejemplo, prefiere “OrderDraft” (antes de guardar) y “OrderRecord” (después de guardar) en lugar de “order1/order2” o “payload/result”. Hace el diagrama legible incluso meses después.
Cuando repitas un patrón, extráelo a un subflujo reutilizable. En el Business Process Editor de AppMaster, esto suele verse como mover “Validar -> Normalizar -> Persistir” a un bloque compartido usado por múltiples flujos.
Ejemplo: un flujo de onboarding que “crea usuario, asigna permisos, envía email y registra auditoría” puede convertirse en cuatro pasos más un subflujo reutilizable “Escribir evento de auditoría”. Eso hace las pruebas más simples, las ediciones más seguras y las sorpresas más raras.
Cómo refactorizar un flujo desordenado paso a paso
Arregla flujos enredados rápidamente
Prototipa un flujo de onboarding con una puerta de decisión y subprocesos reutilizables.
La mayoría de los problemas de flujo vienen de añadir “solo una regla más” o un conector hasta que nadie puede predecir qué ocurre. Refactorizar es hacer el flujo legible otra vez y hacer visibles todos los efectos secundarios y casos de fallo.
Empieza dibujando el camino feliz como una línea clara de inicio a fin. Si la meta principal es “aprobar una orden”, esa línea debe mostrar solo los pasos esenciales cuando todo sale bien.
Luego trabaja en pasadas pequeñas:
- Redibuja el camino feliz como una sola ruta hacia adelante con nombres de pasos consistentes (verbo + objeto)
- Enumera cada efecto secundario (envío de emails, cobro de tarjetas, creación de registros) y haz de cada uno un paso explícito
- Para cada efecto secundario, añade su ruta de fallo justo al lado, incluyendo compensación cuando ya cambiaste algo
- Reemplaza condiciones repetidas con un punto de decisión único y enruta desde allí
- Extrae trozos repetidos en subflujos y renombra variables para que su significado sea obvio (
payment_status es mejor que flag2)
Una forma rápida de detectar complejidad oculta es preguntar: “Si este paso corre dos veces, ¿qué se rompe?” Si la respuesta es “podríamos cobrar dos veces” o “podríamos enviar dos emails”, necesitas estado más claro y comportamiento idempotente.
Ejemplo: un flujo de onboarding crea una cuenta, asigna un plan, cobra con Stripe y envía un mensaje de bienvenida. Si el cobro tiene éxito pero el mensaje falla, no quieres un usuario pagado sin acceso. Añade una rama de compensación cercana: marca al usuario como pending_welcome, reintenta el envío y si los reintentos fallan, reembolsa y revierte el plan.
En AppMaster, esta limpieza es más fácil cuando mantienes el Business Process Editor con flujos superficiales: pasos pequeños, nombres de variables claros y subflujos para “Cobrar pago” o “Enviar notificación” que puedas reutilizar en todas partes.
Trampas comunes al refactorizar
Refactorizar flujos visuales debe facilitar entender el proceso y hacerlo más seguro de cambiar. Pero algunas correcciones añaden nueva complejidad, sobre todo bajo presión de tiempo.
Una trampa es mantener rutas antiguas “por si acaso” sin un switch claro, un marcador de versión o una fecha de jubilación. La gente sigue probando la ruta antigua, soporte la sigue refiriendo y pronto mantienes dos procesos. Si necesitas un despliegue gradual, hazlo explícito: nombra la nueva ruta, complétala con una decisión visible y planifica cuándo se eliminará la antigua.
Las banderas temporales son otra fuga lenta. Una bandera creada para debugging o una migración de una semana a menudo se vuelve permanente, y cada cambio nuevo tiene que considerarla. Trata las banderas como elementos perecederos: documenta por qué existen, nombra un propietario y fija una fecha de eliminación.
Una tercera trampa es añadir excepciones puntuales en lugar de cambiar el modelo. Si sigues insertando nodos de “caso especial”, el diagrama crece lateralmente y las reglas se vuelven imposibles de predecir. Cuando la misma excepción aparece dos veces, normalmente significa que el modelo de datos o los estados del proceso necesitan una actualización.
Finalmente, no ocultes reglas de negocio dentro de nodos no relacionados solo para que funcione. Es tentador, sobre todo en editores visuales, pero después nadie encuentra la regla.
Señales de alarma:
- Dos rutas que hacen el mismo trabajo con pequeñas diferencias
- Banderas con significado poco claro (como “temp2” o “useNewLogic”)
- Excepciones que solo una persona puede explicar
- Reglas repartidas en muchos nodos sin una fuente de verdad clara
- Nodos de “arreglo” añadidos tras fallos en lugar de mejorar el paso anterior
Ejemplo: si los clientes VIP necesitan una aprobación distinta, no añadas comprobaciones ocultas en tres sitios. Añade una decisión clara “Tipo de cliente” una vez y enruta desde allí.
Lista rápida antes de lanzar
Detén las comprobaciones duplicadas
Centraliza las reglas una vez para que aprobaciones y rechazos sean consistentes en todos los caminos.
La mayoría de los problemas aparecen justo antes del lanzamiento: alguien ejecuta el flujo con datos reales y el diagrama hace algo que nadie puede explicar.
Haz un walkthrough en voz alta. Si el camino feliz necesita una historia larga, probablemente el flujo tiene estado oculto, reglas duplicadas o demasiadas ramas que deberían agruparse.
Una verificación rápida previa al envío
- Explica el camino feliz en una sola frase: disparador, pasos principales, línea de meta
- Haz que cada efecto secundario sea su propio paso visible (cobrar, enviar mensajes, actualizar registros, crear tickets)
- Para cada efecto secundario, decide qué pasa en caso de fallo y cómo deshacer un éxito parcial (reembolsar, cancelar, revertir o marcar para revisión manual)
- Revisa variables y banderas: nombres claros, un lugar obvio donde se establece cada una y sin predeterminados misteriosos
- Busca lógica copiada y pegada: la misma comprobación en múltiples ramas o el mismo mapeo repetido con pequeñas variaciones
Una prueba simple que detecta la mayoría de los problemas
Ejecuta el flujo con tres casos: un éxito normal, un fallo probable (como un rechazo de pago) y un caso borde raro (datos opcionales faltantes). Observa cualquier paso que “funcione a medias” y deje el sistema a medio hacer.
En una herramienta como el Business Process Editor de AppMaster, esto suele convertirse en un refactor limpio: extraer comprobaciones repetidas a un paso compartido, hacer efectos secundarios nodos explícitos y añadir una ruta de compensación clara junto a cada llamada riesgosa.
Un ejemplo realista: refactor del flujo de onboarding
Imagina un flujo de onboarding que hace tres cosas: verifica la identidad del usuario, crea su cuenta e inicia una suscripción de pago. Suena simple, pero a menudo se convierte en un flujo que “usualmente funciona” hasta que algo falla.
La versión desordenada
La primera versión crece paso a paso. Se añade una casilla “Verified”, luego una bandera “NeedsReview”, luego más banderas. Comprobaciones como “si verificado” aparecen en varios lugares porque cada nueva función añade su propia rama.
Pronto el flujo se ve así: verificar identidad, crear usuario, cobrar tarjeta, enviar email de bienvenida, crear workspace, luego retroceder para volver a chequear verificación porque un paso posterior depende de ello. Si el cobro tiene éxito pero la creación del workspace falla, no hay rollback. El cliente está facturado pero su cuenta está medio creada, y siguen los tickets de soporte.
El refactor
Un diseño más limpio empieza haciendo el estado visible y controlado. Reemplaza banderas dispersas por un único estado explícito de onboarding (por ejemplo: Draft, Verified, Subscribed, Active, Failed). Luego pon la lógica de “¿seguimos?” en un punto de decisión único.
Objetivos de refactor que suelen arreglar el dolor rápido:
- Una puerta de decisión que lea el estado explícito y dirija el siguiente paso
- No hay comprobaciones repetidas en todo el diagrama, solo bloques de validación reutilizables
- Compensación por éxitos parciales (reembolsar pago, cancelar suscripción, borrar borrador de workspace)
- Una ruta clara de fallo que registre la razón y luego pare de forma segura
Después de eso, modela los datos y el flujo juntos. Si “Subscribed” es verdadero, guarda el subscription ID, payment ID y la respuesta del proveedor en un solo lugar para que la compensación pueda ejecutarse sin adivinar.
Finalmente, prueba los casos de fallo a propósito: timeouts de verificación, cobro exitoso pero fallo en email, errores en la creación de workspace y eventos webhook duplicados.
Si construyes estos flujos en AppMaster, ayuda mantener la lógica de negocio en Business Processes reutilizables y dejar que la plataforma regenere código limpio conforme cambian los requisitos, para que las ramas antiguas no perduren. Si quieres prototipar el refactor rápidamente (con backend, web y móvil en un solo lugar), AppMaster en appmaster.io está diseñado para este tipo de construcción de flujo de trabajo de extremo a extremo.