22 ago 2025·7 min de lectura
Depurar integraciones webhook: firmas, reintentos, reproducción y registros de eventos
Aprende a depurar integraciones webhook estandarizando firmas, manejando reintentos de forma segura, habilitando la reproducción y manteniendo registros de eventos fáciles de buscar.
Por qué las integraciones webhook se convierten en una caja negra
Un webhook es simplemente una app llamando a tu app cuando sucede algo. Un proveedor de pagos te dice “payment succeeded”, una herramienta de formularios indica “new submission” o un CRM informa “deal updated”. Parece sencillo hasta que algo falla y te das cuenta de que no hay una pantalla que abrir, ni un historial obvio, ni una forma segura de reproducir lo ocurrido.
Por eso los problemas con webhooks resultan tan frustrantes. La petición llega (o no). Tu sistema la procesa (o no). La primera señal suele ser un ticket vago como “los clientes no pueden pagar” o “el estado no se actualizó”. Si el proveedor reintenta, puedes recibir duplicados. Si cambian un campo del payload, tu parser puede romperse solo para algunas cuentas.
Síntomas comunes:
- Eventos “faltantes” donde no puedes saber si nunca se enviaron o simplemente no se procesaron
- Entregas duplicadas que crean efectos secundarios duplicados (dos facturas, dos correos, dos cambios de estado)
- Cambios en el payload (campos nuevos, campos ausentes, tipos equivocados) que fallan solo a veces
- Comprobaciones de firma que pasan en un entorno y fallan en otro
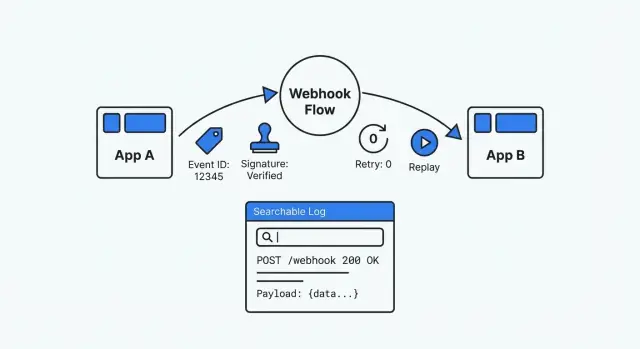
Una configuración de webhook depurable es lo opuesto a adivinar. Es trazable (puedes encontrar cada entrega y lo que hiciste con ella), repetible (puedes reproducir de forma segura un evento pasado) y verificable (puedes probar autenticidad y resultados de procesamiento). Cuando alguien pregunte “¿qué pasó con este evento?”, deberías poder responder con evidencia en minutos.
Si construyes apps en una plataforma como AppMaster, esta mentalidad importa aún más. La lógica visual cambia rápido, pero aún necesitas un historial de eventos claro y reproducción segura para que los sistemas externos nunca se vuelvan una caja negra.
Los datos mínimos que necesitas para hacer observables los webhooks
Cuando estás depurando bajo presión, necesitas lo mismo básico siempre: un registro en el que puedas confiar, buscar y reproducir. Sin eso, cada webhook se convierte en un misterio aislado.
Decide qué significa un solo “evento” webhook en tu sistema. Trátalo como un recibo: una petición entrante = un evento almacenado, aunque el procesamiento ocurra después.
Como mínimo, almacena:
- Event ID: usa el ID del proveedor cuando esté disponible; si no, genera uno.
- Datos de recepción de confianza: cuándo lo recibiste y quién lo envió (nombre del proveedor, endpoint, IP si la guardas). Mantén
received_at separado de las marcas de tiempo dentro del payload.
- Estado de procesamiento más una razón: usa un conjunto pequeño de estados (received, verified, handled, failed) y guarda una breve razón de fallo.
- Petición cruda y vista parseada: guarda el body y headers tal cual se recibieron (para auditorías y comprobaciones de firma), además de una vista JSON parseada para búsqueda y soporte.
- Claves de correlación: uno o dos campos por los que puedas buscar (order_id, invoice_id, user_id, ticket_id).
Ejemplo: un proveedor de pagos envía “payment_succeeded” pero tu cliente sigue apareciendo como no pagado. Si tu registro de eventos incluye la petición en crudo, puedes confirmar la firma y ver la cantidad exacta y la moneda. Si además incluye invoice_id, soporte puede encontrar el evento desde la factura, ver que está atascado en “failed” y dar a ingeniería una razón de error clara.
En AppMaster, un enfoque práctico es una tabla “WebhookEvent” en el Data Designer, con un Business Process que actualiza el estado a medida que cada paso completa. La herramienta no es lo importante. Lo importante es el registro consistente.
Estandariza la estructura del evento para que los registros sean legibles
Si cada proveedor envía una forma de payload distinta, tus registros siempre se verán desordenados. Un envoltorio de evento estable hace la depuración más rápida porque puedes buscar los mismos campos cada vez, incluso cuando los datos cambian.
Un envoltorio útil típicamente incluye:
id (id único del evento)type (nombre claro del evento como invoice.paid)created_at (cuando ocurrió el evento, no cuando lo recibiste)data (el payload de negocio)version (por ejemplo v1)
Aquí hay un ejemplo simple que puedes registrar y almacenar tal cual:
{
"id": "evt_01H...",
"type": "payment.failed",
"created_at": "2026-01-25T10:12:30Z",
"version": "v1",
"correlation": {"order_id": "A-10492", "customer_id": "C-883"},
"data": {"amount": 4990, "currency": "USD", "reason": "insufficient_funds"}
}
Elige un estilo de nombres (snake_case o camelCase) y apégate a él. Sé estricto también con los tipos: no conviertas amount en string a veces y en número otras veces.
Versionar es tu red de seguridad. Cuando necesites cambiar campos, publica v2 mientras mantienes v1 funcionando un tiempo. Evita incidentes de soporte y facilita la depuración de actualizaciones.
Verificación de firmas que sea consistente y testeable
Las firmas impiden que tu endpoint webhook sea una puerta abierta. Sin verificación, cualquiera que conozca tu URL puede enviar eventos falsos y atacantes pueden intentar modificar peticiones reales.
El patrón más común es una firma HMAC con un secreto compartido. El emisor firma el body crudo de la petición (lo ideal) o una cadena canónica. Tú recomputas el HMAC y comparas. Muchos proveedores incluyen una marca de tiempo en lo que firman para que las peticiones capturadas no puedan reproducirse después.
Una rutina de verificación debe ser aburrida y consistente:
- Lee el body crudo exactamente como se recibió (antes de parsear JSON).
- Recalcula la firma usando el algoritmo del proveedor y tu secreto.
- Compara con una función de tiempo constante.
- Rechaza timestamps antiguos (usa una ventana corta, como unos minutos).
- Fallar cerrado: si falta algo o está mal formado, trátalo como inválido.
Hazlo testeable. Pon la verificación en una función pequeña y escribe tests con muestras conocidas buenas y malas. Un sumidero común de tiempo es firmar el JSON parseado en lugar de los bytes crudos.
Planea la rotación de secretos desde el día uno. Soporta dos secretos activos durante las transiciones: intenta el más nuevo primero y luego falla hacia el anterior.
Cuando la verificación falle, registra lo suficiente para depurar sin filtrar secretos: nombre del proveedor, timestamp (y si fue demasiado antiguo), versión de la firma, request/correlation ID, y un hash corto del body crudo (no el body en sí).
Reintentos e idempotencia sin efectos secundarios duplicados
Construye un libro mayor de eventos Webhook
Modela eventos, estados y cargas útiles en crudo en AppMaster para que cada entrega sea buscable.
Los reintentos son normales. Los proveedores reintentan por timeouts, fallos de red o respuestas 5xx. Incluso si tu sistema hizo el trabajo, el proveedor puede no haber recibido tu respuesta a tiempo, así que el mismo evento puede volver a aparecer.
Decide desde el principio qué respuestas significan “reintentar” vs “detener”. Muchos equipos usan reglas como:
- 2xx: aceptado, dejar de reintentar
- 4xx: problema de configuración o de la petición, normalmente dejar de reintentar
- 408/429/5xx: fallo temporal o límite de tasa, reintentar
Idempotencia significa que puedes manejar el mismo evento más de una vez sin repetir efectos secundarios (cobrar dos veces, crear pedidos duplicados, enviar dos correos). Trata los webhooks como entrega al menos una vez (at-least-once).
Un patrón práctico es almacenar el ID único de cada evento entrante con el resultado del procesamiento. En una entrega repetida:
- Si fue exitoso, devuelve 2xx y no hagas nada.
- Si falló, reintenta el procesamiento interno (o devuelve un estado que invite a reintentar).
- Si está en progreso, evita trabajo en paralelo y devuelve una respuesta corta de “aceptado”.
Para reintentos internos, usa backoff exponencial y limita los intentos. Tras el tope, mueve el evento a un estado “requiere revisión” con el último error. En AppMaster, esto encaja bien con una pequeña tabla para IDs de eventos y estados, más un Business Process que programa reintentos y encamina fracasos repetidos.
Herramientas de reproducción que ayudan a soporte a arreglar rápido
Los reintentos son automáticos. La reproducción es intencional.
Una herramienta de replay convierte “creemos que se envió” en una prueba repetible con el mismo payload exacto. También es segura solo cuando se cumplen dos cosas: idempotencia y una pista de auditoría. La idempotencia evita cargos dobles, envíos dobles o correos duplicados. La pista de auditoría muestra qué se reprodujo, quién lo hizo y qué pasó.
Reproducción de un solo evento vs por rango de tiempo
La reproducción de un solo evento es el caso común de soporte: un cliente, un evento fallido, reenviarlo tras una corrección. La reproducción por rango de tiempo es para incidentes: una caída del proveedor en una ventana específica y necesitas reenviar todo lo que falló.
Mantén la selección simple: filtra por tipo de evento, rango de tiempo y estado (failed, timed out o delivered pero no reconocido), luego reproduce un evento o un lote.
Medidas de seguridad que evitan accidentes
La reproducción debe ser potente, pero no peligrosa. Unas pocas guardas ayudan:
- Acceso basado en roles
- Límites de tasa por destino
- Nota obligatoria de motivo almacenada con el registro de auditoría
- Aprobación opcional para reproducir lotes grandes
- Modo dry-run que valida sin enviar
Después de reproducir, muestra los resultados junto al evento original: éxito, sigue fallando (con el último error) o ignorado (duplicado detectado vía idempotencia).
Registros de eventos útiles durante incidentes
Alerta sobre picos de fallos en webhooks
Envía alertas por Telegram o email cuando los fallos de webhook aumenten o los eventos queden atascados en failed.
Cuando un webhook falla durante un incidente, necesitas respuestas en minutos. Un buen log cuenta una historia clara: qué llegó, qué hiciste con ello y dónde se detuvo.
Almacena la petición cruda exactamente como se recibió: timestamp, path, método, headers y body crudo. Ese payload crudo es tu verdad base cuando los proveedores cambian campos o tu parser malinterpreta datos. Enmascara valores sensibles antes de guardar (headers Authorization, tokens y cualquier dato personal o de pago que no necesites).
Los datos crudos no son suficientes. Guarda también una vista parseada y buscable: tipo de evento, ID externo del evento, identificadores de cliente/cuenta, IDs de objetos relacionados (invoice_id, order_id) y tu ID de correlación interno. Esto permite a soporte encontrar “todos los eventos del cliente 8142” sin abrir cada payload.
Durante el procesamiento, conserva una pequeña línea de tiempo de pasos con wording consistente, por ejemplo: “validated signature”, “mapped fields”, “checked idempotency”, “updated records”, “queued follow-ups”.
La retención importa. Conserva suficiente historial para cubrir retrasos reales y disputas, pero no acapares indefinidamente. Considera eliminar o anonimizar payloads crudos primero mientras mantienes metadatos ligeros por más tiempo.
Paso a paso: construye una canalización de webhook depurable
Configura un webhook de pagos
Conecta pagos Stripe y maneja eventos de éxito y fallo con una tabla de eventos clara.
Construye el receptor como una pequeña canalización con puntos de control claros. Cada petición se convierte en un evento almacenado, cada ejecución de procesamiento en un intento, y cada fallo en algo buscable.
Canalización del receptor
Trata el endpoint HTTP solo como intake. Haz el trabajo mínimo al inicio y mueve el procesamiento a un worker para que los timeouts no se conviertan en comportamiento misterioso.
- Captura headers, body crudo, timestamp de recepción y proveedor.
- Verifica la firma (o almacena un estado claro de “failed verification”).
- Encola el procesamiento con clave por un ID de evento estable.
- Procesa en un worker con checks de idempotencia y acciones de negocio.
- Registra el resultado final (success/failure) y un mensaje de error útil.
En la práctica, querrás dos registros principales: una fila por evento webhook y una fila por intento de procesamiento.
Un modelo sólido de evento incluye: event_id, provider, received_at, signature_status, payload_hash, payload_json (o payload crudo), current_status, last_error, next_retry_at. Los registros de intentos pueden guardar: attempt_number, started_at, finished_at, http_status (si aplica), error_code, error_text.
Una vez que los datos existen, añade una pequeña página de administración para que soporte pueda buscar por event ID, customer ID o rango de tiempo, y filtrar por estado. Mantenla aburrida y rápida.
Configura alertas sobre patrones, no sobre fallos puntuales. Por ejemplo: “proveedor falló 10 veces en 5 minutos” o “evento atascado en failed”.
Expectativas del emisor
Si controlas el lado que envía, estandariza tres cosas: siempre incluye un event ID, siempre firma el payload de la misma manera y publica una política de reintentos en lenguaje claro. Evita idas y venidas interminables cuando un socio diga “lo enviamos” y tu sistema no muestre nada.
Ejemplo: webhook de pagos de 'failed' a 'fixed' con reproducción
Un patrón común es un webhook de Stripe que hace dos cosas: crea un registro Order y luego envía un recibo por email/SMS. Suena simple hasta que un evento falla y nadie sabe si el cliente fue cobrado, si el pedido existe o si el recibo se envió.
Aquí hay una falla realista: rotas tu secreto de firma de Stripe. Durante unos minutos, tu endpoint todavía verifica con el secreto antiguo, así que Stripe entrega eventos pero tu servidor los rechaza con un 401/400. El dashboard muestra “webhook failed”, mientras tus logs solo dicen “invalid signature”.
Los buenos logs hacen la causa obvia. Para el evento fallido, el registro debería mostrar un ID de evento estable más suficiente detalle de verificación para localizar la discordancia: versión de la firma, timestamp de la firma, resultado de verificación y una razón de rechazo clara (secreto equivocado vs deriva de timestamp). Durante la rotación, también ayuda registrar qué secreto se intentó (por ejemplo “current” vs “previous”), no el secreto en crudo.
Una vez que el secreto se corrige y tanto “current” como “previous” son aceptados por una ventana corta, aún debes manejar el backlog. Una herramienta de replay convierte eso en una tarea rápida:
- Encuentra el evento por event_id.
- Confirma que la razón del fallo está resuelta.
- Reproduce el evento.
- Verifica idempotencia: la Order se crea una sola vez, el recibo se envía una sola vez.
- Añade el resultado de la reproducción y los timestamps al ticket.
Errores comunes y cómo evitarlos
Reduce la deuda técnica en integraciones
Cambia la lógica rápido y regenera código Go, Vue y móvil limpio conforme evolucionan tus integraciones.
La mayoría de problemas con webhooks parecen misteriosos porque los sistemas solo registran el error final. Trata cada entrega como un pequeño informe de incidente: qué llegó, qué decidiste y qué pasó después.
Unos cuantos errores aparecen repetidos:
- Registrar solo excepciones en lugar del ciclo de vida completo (received, verified, queued, processed, failed, retried)
- Guardar payloads y headers completos sin enmascarar, y luego descubrir que capturaste secretos o datos personales
- Tratar reintentos como eventos nuevos, provocando cargos dobles o mensajes duplicados
- Devolver 200 OK antes de que el evento esté almacenado de forma duradera, de modo que los dashboards se vean verdes mientras el trabajo falla después
Soluciones prácticas:
- Almacena un registro mínimo y buscable de la petición más los cambios de estado.
- Enmascara campos sensibles por defecto y restringe el acceso a payloads crudos.
- Haz cumplir la idempotencia a nivel de base de datos, no solo en el código.
- Acepta solo después de que el evento esté almacenado de forma segura.
- Construye la reproducción como un flujo soportado, no como un script ad-hoc.
Si usas AppMaster, estas piezas encajan de forma natural en la plataforma: una tabla de eventos en el Data Designer, un Business Process impulsado por estados para verificación y procesamiento, y una UI de administración para búsqueda y reproducción.
Lista rápida de verificación y próximos pasos
Apunta a lo mismo básico cada vez:
- Cada evento tiene un event_id único y guardas el payload crudo tal como se recibió.
- La verificación de firma se ejecuta en cada petición y las fallas incluyen una razón clara.
- Los reintentos son previsibles y los handlers son idempotentes.
- La reproducción está restringida a roles autorizados y deja una pista de auditoría.
- Los logs son buscables por event_id, provider id, estado y tiempo, con un breve resumen de “qué pasó”.
Faltar a uno solo de estos puede seguir convirtiendo una integración en una caja negra. Si no almacenas el payload crudo, no puedes probar qué envió el proveedor. Si las fallas de firma no son específicas, perderás horas discutiendo de quién fue la culpa.
Si quieres construir esto rápido sin programar cada componente a mano, AppMaster (appmaster.io) puede ayudarte a ensamblar el modelo de datos, los flujos de procesamiento y la UI de administración en un solo lugar, mientras sigue generando código fuente real para la app final.