17 feb 2025·8 min de lectura
CI/CD para backends en Go: compilar, probar, migrar y desplegar
CI/CD para backends en Go: pasos prácticos de pipeline para compilar, probar, migrar y desplegar de forma segura en Kubernetes o VMs con entornos predecibles.
Por qué CI/CD importa para backends en Go
Las implementaciones manuales fallan de maneras aburridas y repetibles. Alguien compila en su portátil con otra versión de Go, olvida una variable de entorno, se salta una migración o reinicia el servicio equivocado. El release “funciona para mí”, pero no en producción, y solo te enteras después de que los usuarios lo noten.
El código generado no elimina la necesidad de disciplina en los releases. Cuando regenera un backend tras actualizar requisitos, puede introducir nuevos endpoints, nuevas formas de datos o nuevas dependencias incluso si nunca tocaste el código a mano. Precisamente entonces quieres que un pipeline actúe como barandilla: cada cambio pasa por las mismas comprobaciones, cada vez.
Entornos predecibles significan que tus pasos de compilación y despliegue se ejecutan en condiciones que puedes nombrar y repetir. Unas pocas reglas cubren la mayor parte:
- Fijar versiones (toolchain de Go, imágenes base, paquetes del SO).
- Compilar una vez, desplegar el mismo artefacto en todas partes.
- Mantener la configuración fuera del binario (vars de entorno o archivos de config por entorno).
- Usar la misma herramienta y proceso de migración en cada entorno.
- Hacer rollbacks reales: conservar el artefacto anterior y saber qué pasa con la base de datos.
El objetivo del CI/CD para backends en Go no es la automatización por sí misma. Es obtener releases repetibles con menos estrés: regenera, ejecuta el pipeline y confía en que lo que sale es desplegable.
Si usas un generador como AppMaster que produce backends en Go, esto importa aún más. La regeneración es una ventaja, pero solo se siente segura cuando el camino del cambio a producción es consistente, probado y predecible.
Elige tu runtime y define “predecible” desde el inicio
“Predecible” significa que la misma entrada produce el mismo resultado, sin importar dónde lo ejecutes. Para CI/CD de backends en Go eso empieza por ponerse de acuerdo en lo que debe permanecer idéntico entre dev, staging y prod.
Lo habitual no negociable es la versión de Go, la imagen base del SO, las flags de compilación y cómo se carga la configuración. Si alguno de estos cambia según el entorno, aparecen sorpresas como comportamiento TLS distinto, paquetes del sistema faltantes o bugs que solo aparecen en producción.
La deriva de entorno suele mostrarse en los mismos sitios:
- SO y librerías del sistema (versiones de distro diferentes, CA certs faltantes, diferencias de zona horaria)
- Valores de config (feature flags, timeouts, orígenes permitidos, URLs de servicios externos)
- Forma y ajustes de la base de datos (migraciones, extensiones, collation, límites de conexión)
- Manejo de secretos (dónde viven, cómo rotan, quién puede leerlos)
- Supuestos de red (DNS, firewalls, descubrimiento de servicios)
Elegir entre Kubernetes y VMs es menos sobre qué es “mejor” y más sobre qué puede operar tu equipo con calma.
Kubernetes encaja bien cuando necesitas autoescalado, rolling updates y una forma estándar de ejecutar muchos servicios. También ayuda a hacer cumplir la consistencia porque los pods arrancan desde las mismas imágenes. Las VMs pueden ser la elección correcta cuando tienes uno o pocos servicios, un equipo pequeño y quieres menos piezas en movimiento.
Puedes mantener el pipeline igual aunque los runtimes difieran estandarizando el artefacto y el contrato alrededor suyo. Por ejemplo: siempre construir la misma imagen de contenedor en CI, ejecutar los mismos pasos de prueba y publicar el mismo paquete de migraciones. Entonces solo cambia el paso de deploy: Kubernetes aplica una nueva etiqueta de imagen, mientras que las VMs tiran de la imagen y reinician un servicio.
Un ejemplo práctico: un equipo regenera un backend en Go con AppMaster y despliega a staging en Kubernetes pero usa una VM en producción por ahora. Si ambos extraen exactamente la misma imagen y cargan la configuración desde el mismo tipo de almacén de secretos, “runtime distinto” se convierte en un detalle de despliegue, no en una fuente de bugs. Si usas AppMaster, este modelo también encaja bien porque puedes desplegar a destinos cloud gestionados o exportar código fuente y ejecutar el mismo pipeline en tu propia infraestructura.
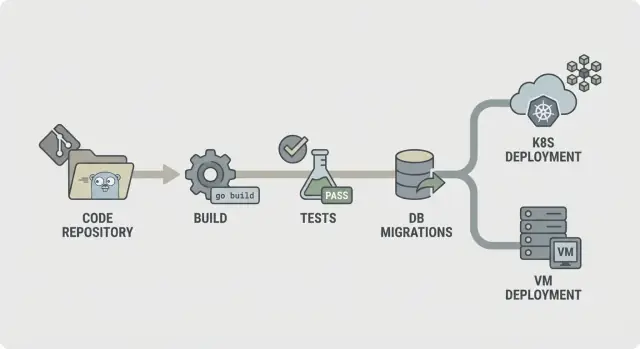
Un mapa de pipeline simple que cualquiera pueda explicar
Un pipeline predecible es fácil de describir: revisar el código, compilarlo, demostrar que funciona, enviar exactamente lo que probaste y luego desplegarlo de la misma manera cada vez. Esa claridad importa aún más cuando tu backend se regenera (por ejemplo, con AppMaster), porque los cambios pueden tocar muchos archivos a la vez y quieres feedback rápido y consistente.
Un flujo directo de CI/CD para backends en Go se ve así:
- Lint y comprobaciones básicas
- Compilación
- Pruebas unitarias
- Comprobaciones de integración
- Empaquetado (artefactos inmutables)
- Migrar (paso controlado)
- Desplegar
Estructúralo para que los fallos paren pronto. Si el lint falla, nada más debería ejecutarse. Si la compilación falla, no deberías gastar tiempo arrancando bases de datos para comprobaciones de integración. Esto mantiene los costes bajos y hace que el pipeline se sienta rápido.
No todos los pasos tienen que ejecutarse en cada commit. Una división común es:
- Cada commit/PR: lint, build, pruebas unitarias
- Rama main: comprobaciones de integración, empaquetado
- Tags de release: migrar, desplegar
Decide qué mantienes como artefactos. Normalmente es el binario compilado o la imagen de contenedor (lo que despliegas), además de logs de migración e informes de pruebas. Conservarlos facilita rollbacks y auditorías porque puedes señalar exactamente qué se probó y se promovió.
Paso a paso: etapa de build que sea estable y repetible
Una etapa de build debe responder a una pregunta: ¿podemos producir el mismo binario hoy, mañana y en otro runner? Si eso no es cierto, cada paso posterior (pruebas, migraciones, deploy) será más difícil de confiar.
Empieza fijando el entorno. Usa una versión de Go fija (por ejemplo, 1.22.x) y una imagen de runner fija (distro Linux y versiones de paquetes). Evita tags “latest”. Pequeños cambios en libc, Git o la toolchain de Go pueden crear fallos de “funciona en mi máquina” que son dolorosos de depurar.
El cache de módulos ayuda, pero solo cuando lo tratas como un impulso de velocidad, no como fuente de verdad. Cachea la caché de build de Go y la de descarga de módulos, pero úsala con una clave basada en go.sum (o límpiala en main cuando las deps cambien) para que nuevas dependencias siempre desencadenen una descarga limpia.
Añade una puerta rápida antes de la compilación. Que sea veloz para que los desarrolladores no la eludan. Un conjunto típico es comprobaciones de gofmt, go vet y (si sigue siendo rápido) staticcheck. También falla si faltan archivos generados o están obsoletos, que es un problema común en codebases regenerados.
Compila de forma reproducible e incorpora información de versión. Flags como -trimpath ayudan, y puedes usar -ldflags para inyectar el SHA del commit y la hora de build. Produce un único artefacto nombrado por servicio. Eso hace fácil rastrear qué está corriendo en Kubernetes o en una VM, especialmente cuando tu backend se regenera.
Paso a paso: pruebas que detecten problemas antes del despliegue
Make deployments less stressful
Create services that pass smoke checks: predictable config, stable artifacts, clean restarts.
Las pruebas solo ayudan si se ejecutan igual cada vez. Prioriza feedback rápido primero y luego añade comprobaciones más profundas que aún terminen en un tiempo predecible.
Comienza con pruebas unitarias en cada commit. Establece un timeout estricto para que una prueba bloqueada falle ruidosamente en lugar de colgar todo el pipeline. También decide qué significa “cobertura suficiente” para tu equipo. La cobertura no es un trofeo, pero un umbral mínimo ayuda a evitar deriva lenta en la calidad.
Una etapa de pruebas estable suele incluir:
- Ejecutar
go test ./... con timeout por paquete y un timeout global del job.
- Tratar cualquier prueba que alcance el timeout como un bug real para arreglar, no como “CI inestable”.
- Fijar expectativas de cobertura para paquetes críticos (auth, billing, permissions), no necesariamente para todo el repo.
- Añadir el race detector para código que maneja concurrencia (colas, cachés, workers fan-out).
El race detector es valioso, pero puede ralentizar mucho las builds. Un buen compromiso es ejecutarlo en pull requests y builds nocturnos, o solo en paquetes seleccionados, en lugar de cada push.
Las pruebas inestables deberían hacer fallar la build. Si debes aislar una prueba, mantenla visible: muévela a un job separado que aún corra y reporte en rojo, y exige un responsable y una fecha límite para arreglarla.
Almacena la salida de las pruebas para que depurar no requiera reejecutarlo todo. Guarda logs crudos y un informe simple (pasa/falla, duración y pruebas lentas principales). Eso facilita detectar regresiones, especialmente cuando cambios regenerados tocan muchos archivos.
Comprobaciones de integración con dependencias reales, sin builds lentas
Keep code clean on regen
Avoid technical debt by regenerating the app cleanly as your schema and endpoints evolve.
Las pruebas unitarias te dicen que el código funciona aislado. Las comprobaciones de integración te dicen que el servicio completo sigue comportándose correctamente cuando arranca, se conecta a servicios reales y procesa peticiones reales. Esta es la red de seguridad que atrapa problemas que solo aparecen cuando todo está conectado.
Usa dependencias efímeras para lo que el código necesite arrancar o responder peticiones clave. Un PostgreSQL temporal (y Redis, si lo usas) levantado solo para el job suele ser suficiente. Mantén las versiones cercanas a producción, pero no intentes copiar todos los detalles de producción.
Una buena etapa de integración es intencionalmente pequeña:
- Arranca el servicio con vars de entorno parecidas a producción (pero secretos de prueba)
- Verifica un health check (por ejemplo,
/health devuelve 200)
- Llama uno o dos endpoints críticos y verifica códigos de estado y forma de respuesta
- Confirma que puede alcanzar PostgreSQL (y Redis si hace falta)
Para comprobaciones de contrato API, céntrate en los endpoints cuya rotura dolería más. No necesitas una suite e2e completa. Unas pocas verdades de request/response bastan: campos requeridos rechazados con 400, auth requerida devuelve 401, y una petición happy-path devuelve 200 con las claves JSON esperadas.
Para mantener las pruebas de integración lo bastante rápidas para ejecutarse con frecuencia, limita el alcance y controla el reloj. Prefiere una base de datos con un dataset mínimo. Ejecuta solo unas pocas peticiones. Establece timeouts estrictos para que un arranque atascado falle en segundos, no en minutos.
Si regenera tu backend (por ejemplo con AppMaster), estas comprobaciones tienen más peso. Confirman que el servicio regenerado aún arranca correctamente y sigue hablando la API que tu app web o móvil espera.
Migraciones de base de datos: orden seguro, gates y la realidad del rollback
Empieza por elegir dónde se ejecutan las migraciones. Ejecutarlas en CI es útil para atrapar errores pronto, pero CI normalmente no debería tocar producción. La mayoría de equipos ejecuta migraciones durante el despliegue (como un paso dedicado) o como un job de “migrate” separado que debe terminar antes de que arranque la nueva versión.
Una regla práctica: compila y prueba en CI, luego ejecuta migraciones lo más cerca posible de producción, con credenciales de producción y límites similares a producción. En Kubernetes, eso suele ser un Job puntual. En VMs, puede ser un comando scriptado en el paso de release.
El orden importa más de lo que la gente espera. Usa archivos con timestamps (o números secuenciales) y aplica “en orden, exactamente una vez”. Haz las migraciones idempotentes cuando puedas, para que un reintento no cree duplicados ni falle a medias.
Mantén la estrategia de migración simple:
- Prefiere cambios aditivos primero (nuevas tablas/columnas, columnas nullable, nuevos índices).
- Despliega código que pueda manejar tanto el esquema viejo como el nuevo durante una release.
- Solo entonces elimina o endurece restricciones (drop columns, NOT NULL).
- Haz operaciones largas seguras (por ejemplo, crear índices en modo concurrente cuando esté soportado).
Añade una puerta de seguridad antes de que nada corra. Esto puede ser un bloqueo en la DB para que solo una migración corra a la vez, además de una política como “no cambios destructivos sin aprobación”. Por ejemplo, falla el pipeline si una migración contiene DROP TABLE o DROP COLUMN a menos que se apruebe manualmente.
El rollback es la verdad dura: muchos cambios de esquema no son reversibles. Si borras una columna, no puedes recuperar los datos. Planea rollbacks pensando en arreglos hacia adelante: mantén una down migration solo cuando sea realmente segura, y confía en backups más una migración de corrección cuando no lo sea.
Acompaña cada migración con un plan de recuperación: qué hacer si falla a medias y qué hacer si la app necesita revertir. Si generas backends en Go (por ejemplo con AppMaster), trata las migraciones como parte del contrato de release para que código regenerado y esquema permanezcan sincronizados.
Empaquetado y configuración: artefactos en los que puedas confiar
From idea to Go API
Turn your API, logic, and database design into production-ready Go source code.
Un pipeline solo se siente predecible cuando lo que despliegas es siempre lo que probaste. Eso se reduce al empaquetado y la configuración. Trata la salida de build como un artefacto sellado y mantén todas las diferencias de entorno fuera de él.
El empaquetado suele tomar una de dos rutas. Una imagen de contenedor es la opción por defecto si despliegas a Kubernetes, porque fija la capa del SO y hace los rollouts consistentes. Un bundle para VMs puede ser igual de fiable cuando necesitas VMs, siempre que incluya el binario compilado más el conjunto pequeño de archivos que necesita en runtime (por ejemplo: CA certs, plantillas o assets estáticos), y lo despliegues de la misma manera siempre.
La configuración debe ser externa, no incrustada en el binario. Usa variables de entorno para la mayoría de ajustes (puertos, host DB, feature flags). Usa un archivo de config solo cuando los valores sean largos o estructurados, y mantenlo específico por entorno. Si usas un servicio de config, trátalo como una dependencia: permisos bloqueados, logs de auditoría y un plan de fallback claro.
Los secretos son la línea que no cruzas. No van en el repo, en la imagen ni en los logs de CI. Evita imprimir connection strings al arrancar. Guarda secretos en el almacén de secretos de tu CI e inyéctalos en tiempo de despliegue.
Para que los artefactos sean trazables, incorpora identidad en cada build: etiqueta artefactos con versión más el hash del commit, incluye metadata de build (versión, commit, hora) en un endpoint de info y registra la etiqueta del artefacto en tu log de despliegue. Haz fácil responder “¿qué está corriendo?” desde un comando o un dashboard.
Si generas backends en Go (por ejemplo con AppMaster), esta disciplina importa aún más: la regeneración es segura cuando tus reglas de nombrado de artefactos y configuración hacen que cada release sea reproducible.
Desplegar a Kubernetes o VMs sin sorpresas
La mayoría de fallos de despliegue no son “mal código”. Son entornos que no coinciden: config diferente, secretos faltantes o un servicio que arranca pero no está listo. La meta es simple: desplegar el mismo artefacto en todas partes y cambiar solo la configuración.
Kubernetes: trata los despliegues como rollouts controlados
En Kubernetes, apunta a un rollout controlado. Usa rolling updates para reemplazar pods gradualmente y añade readiness y liveness checks para que la plataforma sepa cuándo enviar tráfico y cuándo reiniciar un contenedor atascado. Requests y limits importan también, porque un servicio Go que funciona en un runner grande de CI puede ser OOM-killado en un nodo pequeño.
Mantén config y secretos fuera de la imagen. Construye una imagen por commit y luego inyecta ajustes específicos de entorno en tiempo de despliegue (ConfigMaps, Secrets o tu gestor de secretos). Así, staging y producción ejecutan los mismos bits.
VMs: systemd te da la mayor parte de lo que necesitas
Si despliegas a máquinas virtuales, systemd puede ser tu “mini-orquestador”. Crea un unit file con un working directory claro, un archivo de entorno y una política de restart. Haz los logs previsibles enviando stdout/stderr a tu colector de logs o a journald, para que los incidentes no se conviertan en búsquedas por SSH.
Aún puedes hacer rollouts seguros sin un cluster. Un blue/green simple funciona: mantén dos directorios (o dos VMs), cambia el balanceador y deja la versión anterior lista para rollback rápido. Canary es similar: envía una porción pequeña de tráfico a la nueva versión antes de confirmar.
Antes de marcar un despliegue como “hecho”, ejecuta la misma comprobación de humo post-despliegue en todas partes:
- Confirma que el endpoint de health devuelve OK y que las dependencias son alcanzables
- Ejecuta una pequeña acción real (por ejemplo, crear y leer un registro de prueba)
- Verifica que la versión/ID de build del servicio coincida con el commit
- Si la comprobación falla, revierte y alerta
Si regeneras backends (por ejemplo, un backend Go generado con AppMaster), este enfoque se mantiene estable: compila una vez, despliega el artefacto y deja que la config de entorno maneje las diferencias, no scripts ad-hoc.
Errores comunes que hacen los pipelines poco fiables
Build the whole product stack
Generate backend, web app, and native mobile apps from one platform when you need them.
La mayoría de releases rotos no los provoca el “mal código”. Ocurren cuando el pipeline se comporta distinto en cada ejecución. Si quieres que CI/CD para backends en Go se sienta tranquilo y predecible, evita estos patrones.
Patrones de error que causan fallos sorpresa
Ejecutar migraciones automáticamente en cada despliegue sin guardias es clásico. Una migración que bloquee una tabla puede tumbar un servicio con mucho tráfico. Pon las migraciones detrás de un paso explícito, exige aprobación para producción y asegúrate de poder reejecutarlas con seguridad.
Usar tags latest o imágenes base sin fijar versión es otra forma fácil de crear fallos misteriosos. Fija imágenes Docker y versiones de Go para que tu entorno de build no derive.
Compartir una base de datos entre entornos “temporalmente” tiende a volverse permanente, y es así como los datos de prueba se filtran a staging y scripts de staging tocan producción. Separa bases de datos (y credenciales) por entorno, incluso si el esquema es el mismo.
Faltar de health checks y readiness checks permite que un deploy “termine” mientras el servicio está roto, y el tráfico se enrute demasiado pronto. Añade checks que reflejen comportamiento real: ¿puede la app arrancar, conectar a la base de datos y servir una petición?
Por último, la falta de propiedad clara sobre secretos, config y accesos convierte los releases en adivinanzas. Alguien debe ser responsable de cómo se crean, rotan e inyectan los secretos.
Un fallo realista: un equipo hace merge, el pipeline despliega y una migración automática se ejecuta primero. Completa en staging (datos pequeños), pero timeouts en producción (datos grandes). Con imágenes fijadas, separación de entornos y un paso de migración con gate, el despliegue se habría detenido de forma segura.
Si generas backends en Go (por ejemplo con AppMaster), estas reglas importan aún más porque la regeneración puede tocar muchos archivos a la vez. Entradas predecibles y gates explícitos evitan que cambios “grandes” se conviertan en releases riesgosos.
Lista rápida de comprobación para un CI/CD predecible
One artifact, multiple environments
Keep build once, deploy everywhere by exporting source or using managed deployment targets.
Usa esto como chequeo rápido para CI/CD de backends en Go. Si puedes responder cada punto con un “sí” claro, los releases serán más sencillos.
- Bloquea el entorno, no solo el código. Fija la versión de Go y la imagen del contenedor de build, y usa la misma configuración local y en CI.
- Haz que el pipeline funcione con 3 comandos simples. Un comando construye, otro ejecuta pruebas y otro produce el artefacto desplegable.
- Trata las migraciones como código de producción. Exige logs para cada ejecución de migración y deja por escrito qué significa “rollback” para tu app.
- Produce artefactos inmutables y trazables. Compila una vez, etiqueta con el SHA del commit y promueve entre entornos sin recompilar.
- Despliega con comprobaciones que fallen rápido. Añade readiness/liveness y una prueba de humo corta que corra en cada despliegue.
Mantén el acceso a producción limitado y auditable. CI debería desplegar usando una cuenta de servicio dedicada, los secretos gestionados centralmente y cualquier acción manual en producción debe dejar rastro claro (quién, qué, cuándo).
Un ejemplo realista y próximos pasos para empezar esta semana
Un pequeño equipo de ops de cuatro personas hace releases una vez a la semana. Regeneran su backend en Go con frecuencia porque el equipo de producto sigue refinando workflows. Su objetivo es simple: menos arreglos nocturnos y releases que no sorprendan a nadie.
Un cambio típico un viernes: añaden un nuevo campo a customers (cambio de esquema) y actualizan la API que lo escribe (cambio de código). El pipeline trata esto como un solo release. Compila un artefacto, ejecuta pruebas contra ese artefacto exacto y solo entonces aplica migraciones y despliega. Así, la base de datos nunca queda por delante del código que la espera, y el código no se despliega sin su esquema coincidente.
Cuando se incluye un cambio de esquema, el pipeline añade una puerta de seguridad. Verifica que la migración sea aditiva (por ejemplo, añadir una columna nullable) y marca acciones riesgosas (como dropear una columna o reescribir una tabla grande). Si la migración es riesgosa, el release se detiene antes de producción. El equipo reescribe la migración para hacerla más segura o programa una ventana planificada.
Si las pruebas fallan, nada avanza. Lo mismo si las migraciones fallan en preproducción. El pipeline no debería intentar forzar cambios “solo esta vez”.
Un conjunto simple de próximos pasos que funciona para la mayoría de equipos:
- Empieza con un entorno (un despliegue dev que puedas resetear con seguridad).
- Haz que el pipeline siempre produzca un artefacto de build versionado.
- Ejecuta migraciones automáticamente en dev, pero exige aprobación en producción.
- Añade staging solo después de que dev sea estable unas semanas.
- Añade un gate de producción que requiera tests en verde y un despliegue exitoso en staging.
Si generas backends con AppMaster, mantén la regeneración dentro de las mismas etapas del pipeline: regenerar, compilar, probar, migrar en un entorno seguro y luego desplegar. Trata el código generado como cualquier otra fuente. Cada release debe ser reproducible desde una versión taggeada, con los mismos pasos cada vez.
FAQ
Pincha tu versión de Go y el entorno de compilación para que las mismas entradas siempre produzcan el mismo binario o imagen. Eso elimina las diferencias de “funciona en mi máquina” y facilita reproducir y arreglar fallos.
La regeneración puede cambiar endpoints, modelos de datos y dependencias incluso si nadie editó el código a mano. Un pipeline hace que esos cambios pasen por las mismas comprobaciones cada vez, de modo que regenerar sea seguro y no arriesgado.
Compila una vez y promueve ese mismo artefacto por dev, staging y prod. Si reconstruyes por ambiente, puedes terminar publicando algo que nunca probaste, aunque el commit sea el mismo.
Ejecuta puertas rápidas en cada pull request: formato, comprobaciones estáticas básicas, compilación y pruebas unitarias con timeouts. Manténlo lo bastante rápido para que la gente no lo esquive, y lo bastante estricto para que los cambios rotos se detengan pronto.
Usa una etapa de integración pequeña que arranque el servicio con configuración similar a producción y que hable con dependencias reales como PostgreSQL. La meta es detectar “compila pero no arranca” y roturas claras de contrato sin convertir CI en una suite de horas.
Trata las migraciones como un paso controlado de release, no como algo que ocurre implícitamente en cada despliegue. Ejecútalas con logs claros y un bloqueo de ejecución única, y sé honesto sobre el rollback: muchos cambios de esquema requieren arreglos hacia adelante o restauraciones desde backups, no un simple deshacer.
Usa readiness checks para que el tráfico llegue a pods nuevos solo cuando el servicio esté realmente listo, y liveness checks para reiniciar contenedores atascados. También define requests y limits realistas para que un servicio que pasa CI no sea OOM-killado en producción.
Un unit file de systemd junto con un script de release consistente suele ser suficiente para despliegues tranquilos en VMs. Mantén el mismo modelo de artefacto que con contenedores cuando sea posible y añade una pequeña comprobación de humo post-despliegue para que un “reinicio correcto” no oculte un servicio roto.
Nunca metas secretos en el repo, en el artefacto de build o en los logs. Inyecta secretos en tiempo de despliegue desde un almacén de secretos gestionado, limita quién puede leerlos y haz de la rotación una tarea rutinaria en lugar de una emergencia.
Incluye la regeneración dentro de las mismas etapas del pipeline que cualquier otro cambio: regenerar, compilar, probar, empaquetar, y luego migrar y desplegar con gates. Si usas AppMaster para generar tu backend en Go, esto te permite moverte rápido sin adivinar qué cambió, y probar el flujo sin código para regenerar y publicar con más confianza.