08 feb 2025·6 min de lectura
App de gestión de incidentes para equipos de TI: flujos y postmortems
Diseña y construye una app interna de gestión de incidentes para TI con flujos de severidad, propiedad clara, cronogramas y postmortems en una sola herramienta.
Qué problema resuelve realmente una app interna de incidentes
Cuando ocurre una caída, la mayoría de los equipos toman lo que esté a mano: un hilo de chat, una cadena de emails, quizá una hoja de cálculo que alguien actualiza cuando tiene un minuto. Bajo presión, esa configuración falla siempre de las mismas maneras: la propiedad se vuelve difusa, las marcas temporales desaparecen y las decisiones se pierden en el scroll.
Una app sencilla de gestión de incidentes arregla lo básico. Te da un único lugar donde vive el incidente, con un propietario claro, un nivel de severidad con el que todos están de acuerdo y una línea de tiempo de qué pasó y cuándo. Ese registro único importa porque las mismas preguntas aparecen en cada incidente: ¿Quién lidera? ¿Cuándo empezó? ¿Cuál es el estado actual? ¿Qué ya se intentó?
Sin ese registro compartido, los traspasos desperdician tiempo. Soporte dice una cosa a los clientes mientras ingeniería hace otra. Los managers piden actualizaciones que alejan a los respondedores de la resolución. Después, nadie puede reconstruir la línea de tiempo con confianza y el postmortem se convierte en conjeturas.
El objetivo no es reemplazar tu monitorización, chat o sistema de tickets. Las alertas pueden seguir viniendo de otros sitios. La idea es capturar la traza de decisiones y mantener a las personas alineadas.
Operaciones de TI y los ingenieros on-call lo usan para coordinar la respuesta. Soporte lo usa para dar actualizaciones precisas y rápidas. Los managers lo usan para ver el progreso sin interrumpir a los respondedores.
Escenario de ejemplo: una caída P1 desde la alerta hasta el cierre
A las 9:12 AM, la monitorización marca un pico de errores 500 en el portal de clientes. Un agente de soporte también reporta: “Fallan los inicios de sesión para la mayoría de usuarios.” El responsable on-call de TI abre un incidente P1 en la app y adjunta la primera alerta más una captura de pantalla del soporte.
Con un P1, el comportamiento cambia rápido. El owner del incidente incorpora al responsable de backend, al responsable de base de datos y a un enlace de soporte. Se pausa trabajo no esencial. Se detienen despliegues planeados. El equipo acuerda una cadencia de actualizaciones (por ejemplo, cada 15 minutos). Empieza una llamada compartida, pero el registro del incidente sigue siendo la fuente de verdad.
A las 9:18 AM alguien pregunta: “¿Qué cambió?” La línea de tiempo muestra un despliegue a las 8:57 AM, pero no dice qué se desplegó. El responsable de backend decide hacer rollback igual. Los errores bajan y luego vuelven. Ahora el equipo sospecha de la base de datos.
La mayoría de las demoras aparecen en unos pocos sitios previsibles: traspasos poco claros (“pensé que tú lo estabas revisando”), contexto perdido (cambios recientes, riesgos conocidos, owner actual) y actualizaciones dispersas entre chat, tickets y correo.
A las 9:41 AM, el responsable de base de datos encuentra una consulta que se salió de control iniciada por un job programado. Desactivan el job, reinician el servicio afectado y confirman la recuperación. La severidad se reduce a P2 para seguimiento.
Un buen cierre no es “ya funciona.” Es un registro limpio: línea de tiempo minuto a minuto, la causa raíz final, quién tomó cada decisión, qué se pausó y trabajo de seguimiento con owners y fechas de entrega. Así es como un P1 estresante se convierte en aprendizaje en lugar de dolor repetido.
Modelo de datos: la estructura más simple que aún funciona
Una buena herramienta de incidentes es principalmente un buen modelo de datos. Si los registros son vagos, la gente discutirá qué es el incidente, cuándo empezó y qué sigue abierto.
Mantén las entidades centrales cercanas a cómo ya hablan los equipos de TI:
- Incident: el contenedor de lo que pasó
- Service: lo que opera el negocio (API, base de datos, VPN, facturación)
- User: respondedores y stakeholders
- Update: notas cortas de estado a lo largo del tiempo
- Task: trabajo concreto durante el incidente (y después)
- Postmortem: un informe ligado al incidente, con acciones
Para evitar confusiones más tarde, da al Incident algunos campos estructurados que siempre se llenen. El texto libre ayuda, pero no debe ser la única fuente de verdad. Un mínimo práctico es: un título claro, impacto (qué experimentan los usuarios), servicios afectados, hora de inicio, estado actual y severidad.
Las relaciones importan más que campos extra. Un incidente debe tener muchas actualizaciones y muchas tareas, además de un enlace muchos-a-muchos a services (porque las caídas a menudo afectan múltiples sistemas). Un postmortem debe ser uno-a-uno con un incidente, para que haya una única historia final.
Ejemplo: un incidente “Errores en Checkout” enlaza con los Services “Payments API” y “PostgreSQL”, tiene actualizaciones cada 15 minutos y tareas como “Rollback de deploy” y “Agregar guard de reintentos”. Más tarde, el postmortem captura la causa raíz y crea tareas a más largo plazo.
Niveles de severidad y objetivos de respuesta
Cuando la gente está estresada, necesita etiquetas simples que signifiquen lo mismo para todos. Define P1 a P4 en lenguaje llano y muestra la definición justo al lado del campo de severidad.
- P1 (Crítico): Servicio central caído o probable pérdida de datos. Muchos usuarios bloqueados.
- P2 (Alto): Característica importante rota, pero hay workaround o radio de impacto limitado.
- P3 (Medio): Incidente no urgente, grupo pequeño afectado, impacto mínimo al negocio.
- P4 (Bajo): Error cosmético o menor, programar para más tarde.
Los objetivos de respuesta deben leerse como compromisos. Una línea base simple (ajusta a tu realidad):
| Severity | First response (ack) | First update | Update frequency |
|---|
| P1 | 5 min | 15 min | every 30 min |
| P2 | 15 min | 30 min | every 60 min |
| P3 | 4 hours | 1 business day | daily |
| P4 | 2 business days | 1 week | weekly |
Mantén las reglas de escalado mecánicas. Si un P2 falla en su cadencia de actualización o el impacto crece, el sistema debería sugerir revisar la severidad. Para evitar oscilaciones, limita quién puede cambiar la severidad (a menudo el owner del incidente o el incident commander), permitiendo aún que cualquiera solicite una revisión en un comentario.
Una matriz de impacto rápida también ayuda a decidir la severidad con rapidez. Captúrala como unos pocos campos obligatorios: usuarios afectados, riesgo de ingresos, seguridad/ cumplimiento, y si existe un workaround.
Estados de flujo que guían a la gente bajo estrés
Soporta la respuesta en movimiento
Permite que los responsables on-call publiquen actualizaciones y cambien estado desde el teléfono.
Durante un incidente, la gente no necesita más opciones. Necesita un conjunto pequeño de estados que dejen claro el siguiente paso.
Empieza con los pasos que ya sigues en un buen día y mantén la lista corta. Si tienes más de 6 o 7 estados, los equipos discutirán el nombre en vez de arreglar el problema.
Un conjunto práctico:
- New: alerta recibida, aún no confirmada
- Acknowledged: alguien la acepta, respuesta inicial en marcha
- Investigating: confirmar impacto, acotar causa probable
- Mitigating: acciones en curso para reducir el impacto
- Monitoring: servicio estable, vigilando reaparición
- Resolved: servicio restaurado, listo para revisión
Cada estado necesita reglas claras de entrada y salida. Por ejemplo:
- No puedes mover a Acknowledged hasta que haya un owner y la siguiente acción esté escrita en una frase.
- No puedes mover a Mitigating hasta que exista al menos una tarea concreta de mitigación (rollback, feature flag off, capacidad añadida).
Usa las transiciones para forzar los campos que la gente olvida. Una regla común: no puedes cerrar un incidente sin un resumen corto de causa raíz y al menos un ítem de seguimiento. Si se permite “RCA: TBD”, tiende a quedarse así.
La página del incidente debe responder tres preguntas de un vistazo: quién lo posee, cuál es la próxima acción y cuándo se publicó la última actualización.
Reglas de asignación y escalado
Cuando un incidente es ruidoso, la forma más rápida de perder tiempo es la propiedad difusa. Tu app debe dejar una persona claramente responsable, pero facilitar que otros ayuden.
Un patrón simple que funciona:
- Primary owner: conduce la respuesta, publica actualizaciones, decide pasos siguientes
- Helpers: toman tareas (diagnóstico, rollback, comunicaciones) y reportan
- Approver: un líder que puede autorizar acciones riesgosas
La asignación debe ser explícita y auditable. Registra quién puso el owner, quién lo aceptó y cada cambio posterior. “Aceptado” importa, porque asignar a alguien que está dormido u offline no es propiedad real.
La asignación on-call vs basada en equipo suele depender de la severidad. Para P1/P2, por defecto usa la rotación on-call para asegurar un owner nombrado. Para severidades menores, la asignación por equipo puede funcionar, pero aún exige un owner primario en un plazo corto.
Planea vacaciones y ausencias en tu proceso humano, no solo en sistemas. Si la persona asignada está marcada como no disponible, enruta a un on-call secundario o al líder del equipo. Mantenlo automático, pero visible para corregir rápido.
El escalado debe dispararse tanto por severidad como por silencio. Un punto de partida útil:
- P1: escalar si no hay aceptación de owner en 5 minutos
- P1/P2: escalar si no hay actualización en 15 a 30 minutos
- Cualquier severidad: escalar si el estado queda en “Investigating” más allá del objetivo de respuesta
Cronogramas, actualizaciones y notificaciones
Una fuente de verdad para TI
Saca la coordinación de incidentes del scroll del chat y ponla en un único sistema.
Una buena línea de tiempo es memoria compartida. Durante un incidente, el contexto desaparece rápido. Si capturas los momentos correctos en un solo sitio, los traspasos son más sencillos y el postmortem estará en gran parte escrito antes de que alguien abra un documento.
Qué debe capturar la línea de tiempo
Mantén la línea de tiempo con criterio. No la conviertas en un registro de chat. La mayoría de los equipos dependen de unas pocas entradas: detección, reconocimiento, pasos clave de mitigación, restauración y cierre.
Cada entrada necesita marca temporal, autor y una breve descripción en lenguaje llano. Alguien que se incorpore tarde debería poder leer cinco entradas y entender qué sucede.
Tipos de actualizaciones que mantienen claridad
Diferentes actualizaciones sirven a diferentes audiencias. Ayuda cuando las entradas tienen un tipo, como nota interna (detalles crudos), actualización para clientes (redacción segura), decisión (por qué elegir la opción A) y traspaso (qué debe saber la siguiente persona).
Los recordatorios deben seguir la severidad, no la preferencia personal. Si el temporizador suena, primero avisa al owner actual y luego escala si se repite la omisión.
Las notificaciones deben ser dirigidas y predecibles. Un conjunto pequeño de reglas suele ser suficiente: notificar en creación, cambio de severidad, restauración y actualizaciones vencidas. Evita notificar a toda la compañía por cada cambio.
Postmortems que generan seguimiento real
Asegura el modelo de datos
Diseña incidentes, servicios, actualizaciones, tareas y postmortems con un esquema estructurado.
Un postmortem tiene dos tareas: explicar lo ocurrido en lenguaje claro y hacer que la misma falla sea menos probable la próxima vez.
Mantén el informe breve y fuerza la salida en acciones. Una estructura práctica incluye: resumen, impacto al cliente, causa raíz, arreglos aplicados y seguimientos.
Los seguimientos son el punto clave. No los dejes como un párrafo final. Convierte cada seguimiento en una tarea rastreada con owner y fecha de entrega, aunque la fecha sea “próxima sprint”. Esa es la diferencia entre “debemos mejorar la monitorización” y “Alex añade una alerta de saturación de conexiones DB para el viernes”.
Las etiquetas hacen que los postmortems sean útiles luego. Añade 1 a 3 temas a cada incidente (falta de monitorización, despliegue, capacidad, proceso). Tras un mes, podrás responder preguntas básicas como si la mayoría de los P1 vienen de releases o de alertas faltantes.
La evidencia debe ser fácil de adjuntar, no obligatoria. Soporta campos opcionales para capturas, fragmentos de logs y referencias a sistemas externos (IDs de tickets, hilos de chat, números de caso con proveedores). Manténlo ligero para que la gente realmente lo complete.
Paso a paso: construir el mini-sistema como una app interna
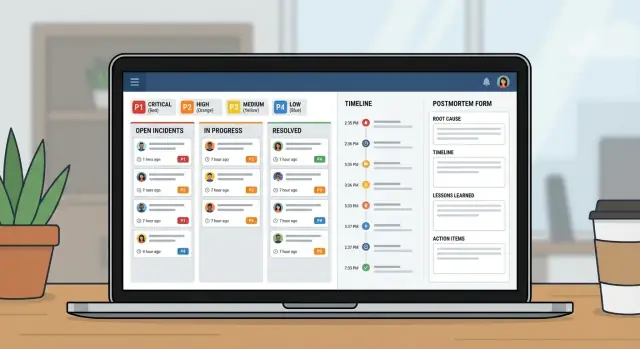
Trátalo como un pequeño producto, no como una hoja de cálculo con columnas extras. Una buena app de incidentes son en realidad tres vistas: qué está pasando ahora, qué hacer a continuación y qué aprender después.
Empieza diseñando las pantallas que la gente abrirá bajo presión:
- Queue: incidentes abiertos con un par de filtros (Open, Needs update, Waiting on vendor, Closed)
- Incident page: severidad, owner, estado actual, línea de tiempo, tareas y la última actualización
- Postmortem page: impacto, causa raíz, ítems de acción, owners
Construye el modelo de datos y los permisos juntos. Si todos pueden editar todo, el historial se vuelve un desastre. Un enfoque común: acceso amplio de lectura para TI, cambios controlados de estado/severidad, respondedores pueden añadir actualizaciones y un owner claro para la aprobación del postmortem.
Luego añade reglas de flujo que prevengan incidentes medio rellenados. Los campos obligatorios deben depender del estado. Puedes permitir “New” solo con título y reporter, pero exigir que “Mitigating” incluya un resumen de impacto y exigir que “Resolved” incluya un resumen de causa raíz más al menos un seguimiento.
Finalmente, prueba reproduciendo 2 o 3 incidentes pasados. Que una persona actúe como incident commander y otra como respondedora. Verás rápido qué estados son confusos, qué campos la gente se salta y dónde necesitas mejores valores por defecto.
Errores comunes y cómo evitarlos
Evita incidentes a medio rellenar
Requiere un owner, la siguiente acción y la causa raíz antes de que el incidente pueda avanzar.
La mayoría de los sistemas de incidentes fallan por razones simples: la gente no recuerda las reglas bajo estrés y la app no captura los hechos que necesitas más tarde.
Error 1: Demasiadas severidades o estados
Si tienes seis niveles de severidad y diez estados, la gente adivinará. Mantén severidades en 3 o 4 y estados centrados en lo que alguien debe hacer a continuación.
Error 2: Sin un owner único
Cuando todos “lo vigilan”, nadie lo conduce. Exige un owner nombrado antes de que el incidente pueda avanzar y haz los traspasos explícitos.
Error 3: Líneas de tiempo en las que no puedes confiar
Si “qué pasó cuándo” depende del historial de chat, los postmortems serán discusiones. Captura automáticamente marcas de tiempo de apertura, reconocimiento, mitigación y resolución, y mantén las entradas de la línea de tiempo breves.
Evita cerrar con notas vagas de causa raíz como “problema de red”. Exige una causa raíz clara y al menos un paso concreto siguiente.
Checklist de lanzamiento y siguientes pasos
Antes de desplegarlo en toda la organización de TI, prueba lo básico bajo estrés. Si la gente no encuentra el botón correcto en los primeros dos minutos, volverán a los hilos de chat y las hojas de cálculo.
Céntrate en un conjunto corto de comprobaciones de lanzamiento: roles y permisos, definiciones claras de severidad, propiedad forzada, reglas de recordatorio y una vía de escalado cuando se fallen los objetivos de respuesta.
Pilota con un equipo y unos pocos servicios que generen alertas frecuentes. Úsalo durante dos semanas y ajusta según incidentes reales.
Si quieres construir esto como una única herramienta interna sin unir hojas de cálculo y apps separadas, AppMaster (appmaster.io) es una opción. Permite crear un modelo de datos, reglas de flujo y interfaces web/móvil en un solo lugar, lo que encaja bien con una cola de incidentes, la página de incidentes y el seguimiento de postmortems.
FAQ
Reemplaza las actualizaciones dispersas con un único registro compartido que responde rápido a lo esencial: quién es el responsable, qué ven los usuarios, qué se ha intentado y cuál es el siguiente paso. Eso reduce el tiempo perdido en traspasos, mensajes contradictorios y pausas para pedir resúmenes.
Abre el incidente en cuanto creas que hay impacto real en clientes o negocio, aunque la causa sea incierta. Puedes abrirlo con un título provisional y “impacto desconocido” y luego completar los detalles conforme confirmes la severidad y el alcance.
Manténlo pequeño y estructurado: un título claro, un resumen de impacto, servicio(s) afectado(s), hora de inicio, estado actual, severidad y un único owner. Añade actualizaciones y tareas según avance la situación, pero no dependas del texto libre para los hechos principales.
Usa de 3 a 4 niveles con significados claros que no den lugar a debates. Un buen predeterminado es: P1 para caída crítica o riesgo de pérdida de datos, P2 para impacto mayor con algún workaround o alcance limitado, P3 para problemas de menor impacto y P4 para fallos cosméticos o menores.
Haz que los objetivos se sientan como compromisos: tiempo para reconocer, tiempo para la primera actualización y cadencia de actualizaciones. Luego dispara recordatorios y escalados cuando se incumpla la cadencia, porque el “silencio” suele ser la verdadera falla durante un incidente.
Apunta a unos seis: New, Acknowledged, Investigating, Mitigating, Monitoring y Resolved. Cada estado debe dejar claro el siguiente paso, y las transiciones deben forzar lo que la gente olvida bajo estrés, por ejemplo exigir un owner antes de Acknowledged o una causa raíz antes de cerrar.
Exige un owner primario que sea responsable de conducir la respuesta y publicar actualizaciones. Registra la aceptación explícita para no “asignar” a alguien que está fuera de línea, y haz que los traspasos sean eventos registrados para que la siguiente persona no reemprenda la investigación desde cero.
Captura solo los momentos que importan: detección, reconocimiento, decisiones clave, pasos de mitigación, restauración y cierre, cada uno con marca temporal y autor. Trátalo como memoria compartida, no como una transcripción de chat, para que quien llegue tarde pueda ponerse al día en minutos.
Manténlo corto y orientado a la acción: qué pasó, impacto al cliente, causa raíz, qué se cambió durante la mitigación y tareas de seguimiento con owners y fechas. El informe sirve, pero las tareas rastreadas son las que evitan repetir el mismo incidente.
Sí. Si modelas incidentes, actualizaciones, tareas, servicios y postmortems como datos reales y aplicas reglas de flujo en la app, puedes evitar depender de hojas de cálculo y apps separadas. AppMaster (appmaster.io) permite crear ese modelo de datos, pantallas web/móvil y validaciones basadas en estado en un mismo lugar.