সরঞ্জাম রিজার্ভেশন অ্যাপ: সংঘাত ঠেকান এবং ফেরত ট্র্যাক করুন
এমন একটি সরঞ্জাম রিজার্ভেশন অ্যাপ পরিকল্পনা করুন যা ডাবল বুকিং বন্ধ করে, ফেরত ও ক্ষতির রেকর্ড রাখে এবং ত্রুটিপূর্ণ সরঞ্জামকে রক্ষণাবেক্ষণে আটকে দেয়।
pgvector বনাম ম্যানেজড ভেক্টর ডাটাবেস: সেটআপ, স্কেলিং, ফিল্টারিং সমর্থন এবং সাধারণ অ্যাপ স্ট্যাক-এ কোনটি কেমন ফিট হয়—তুলনা ও বাস্তব পরামর্শ।
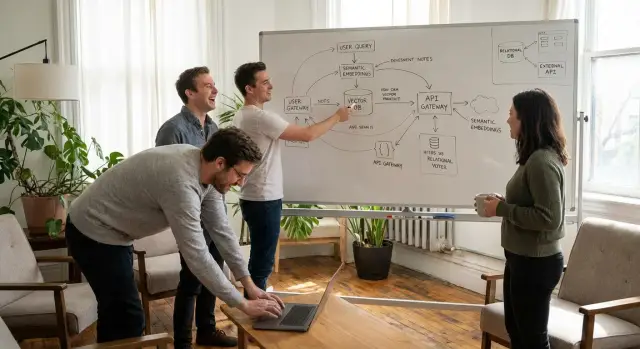
সেমান্টিক সার্চ মানুষকে সঠিক উত্তর খুঁজে পেতে সাহায্য করে এমন সময়ও যখন তারা “সঠিক” কীওয়ার্ড ব্যবহার করে না। শব্দের সঠিক মিলের বদলে এটি অর্থ মিলায়। কেউ যদি “reset my login” টাইপ করে, তারা এখনও “Change your password and sign in again” শিরোনামের একটি আর্টিকেল দেখতে চাইবে—কারণ উদ্দেশ্য একই।
কীওয়ার্ড সার্চ ব্যবসায়িক অ্যাপে ভেঙে পড়ে কারণ বাস্তব ব্যবহারকারীরা অনিয়মিত; তারা সংক্ষিপ্ত রূপ ব্যবহার করে, টাইপো করে, পণ্য নাম মিশ্রিত করে এবং অফিসিয়াল টার্মের বদলে লক্ষণ বর্ণনা করে। FAQs, সাপোর্ট টিকিট, পলিসি ডকুমেন্ট এবং অনবোর্ডিং গাইডে একই সমস্যা বিভিন্ন রূপে থাকে। একটি কীওয়ার্ড ইঞ্জিন প্রায়ই কিছুই কাজে না লাগার মত ফল দেয়, বা এমন একটি বড় তালিকা দেয় যা মানুষকে ক্লিক করে খুঁজতে বাধ্য করে।
এম্বেডিং সাধারণত ব্যবহার করা হয়। আপনার অ্যাপ প্রতিটি ডকুমেন্ট (একটি আর্টিকেল, একটি টিকিট, একটি প্রোডাক্ট নোট) কে একটি ভেক্টরে রূপান্তর করে—সংখ্যার একটি দীর্ঘ তালিকা যা অর্থ প্রকাশ করে। যখন একজন ব্যবহারকারী প্রশ্ন করে, আপনি প্রশ্নটাও এমবেড করেন এবং সবচেয়ে কাছের ভেক্টরগুলো খুঁজে বের করেন। “ভেক্টর ডাটাবেস” কেবল সেই ভেক্টরগুলো কোথায় রাখবেন এবং কীভাবে দ্রুত সার্চ করবেন তার উপায়।
সাধারণ ব্যবসায়িক স্ট্যাক-এ সেমান্টিক সার্চ চারটি জায়গায় প্রভাব ফেলে: কনটেন্ট স্টোর (নলেজ বেস, ডক্স, টিকিট সিস্টেম), এমবেডিং পাইপলাইন (ইম্পোর্টস এবং কনটেন্ট বদলে আপডেট), কুয়েরি এক্সপেরিয়েন্স (সার্চ বক্স, সাজেস্টেড উত্তর, এজেন্ট অ্যাসিস্ট), এবং গার্ডরেইলস (পারমিশন এবং মেটাডেটা যেমন টিম, কাস্টমার, প্ল্যান, ও রিজিয়ন)।
অধিকাংশ টিমের জন্য “ভালো পর্যাপ্ত” নিখুঁত হওয়ার চেয়ে ভালো। বাস্তবিক লক্ষ্য হচ্ছে প্রথম প্রচেষ্টায় প্রাসঙ্গিকতা, সেকেন্ডের মধ্যে উত্তর, এবং কনটেন্ট বাড়লে খরচ পূর্বানুমেয় রাখা। এই লক্ষ্য যন্ত্রপাতি নিয়ে তর্কের চেয়ে বেশি গুরুত্বপূর্ণ।
অধিকাংশ টিম সেমান্টিক সার্চের জন্য দুইটি প্যাটার্নের মধ্যে সিদ্ধান্ত নেয়: সব কিছু PostgreSQL-ভিত্তিক রেখে pgvector ব্যবহার করা, অথবা আপনার প্রধান ডাটাবেসের পাশেই একটি ম্যানেজড ভেক্টর ডাটাবেস যোগ করা। কোনটি সঠিক হবে তা নির্ভর করে আপনি জটিলতা কোথায় রাখতে চান।
pgvector হলো একটি PostgreSQL এক্সটেনশন যা ভেক্টর ডেটা টাইপ ও ইনডেক্স যোগ করে, ফলে আপনি একটি সাধারণ টেবিলে এমবেডিং সংরক্ষণ করে SQL দিয়ে সাদৃশ্য অনুসন্ধান চালাতে পারেন। বাস্তবে আপনার ডকুমেন্ট টেবিলে টেক্সট, মেটাডেটা (customer_id, status, visibility) এবং একটি এমবেডিং কলাম থাকতে পারে। সার্চ হয় “কুয়েরি এমবেড করো, তারপর যাদের এমবেডিং কাছাকাছি তাদের রিটার্ন করো।”
একটি managed ভেক্টর ডাটাবেস হলো হোস্টেড সার্ভিস যা মূলত এমবেডিং-এর জন্য নির্মিত। এটি সাধারণত ভেক্টর ইনসার্ট এবং সাদৃশ্য অনুসন্ধানের API দেয়, সঙ্গে অপারেশনাল ফিচার যা না থাকলে আপনাকে নিজে বানাতে হত।
দুই অপশনই একই মূল কাজ করে: একটি আইডি ও মেটাডেটা নিয়ে এমবেডিং সংরক্ষণ করা, একটি কুয়েরির জন্য নিকটতম প্রতিবেশী খোঁজা, এবং শীর্ষ মিলগুলো রিটার্ন করা যাতে আপনার অ্যাপ প্রাসঙ্গিক আইটেম দেখাতে পারে।
কী পার্থক্য করে তা হলো রেকর্ডের সিস্টেম। যদিও আপনি একটি managed ভেক্টর ডাটাবেস ব্যবহার করেন, আপনি প্রায়ই PostgreSQL-এ ব্যবসায়িক ডেটা রাখেন: অ্যাকাউন্ট, পারমিশন, বিলিং, ওয়ার্কফ্লো স্টেট, এবং অডিট লগস। ভেক্টর স্টোরটি হবে একটি রিট্রিভাল লেয়ার, পুরো অ্যাপ চালানোর জায়গা নয়।
একটি সাধারণ আর্কিটেকচার এই রকম: অথরিটেটিভ রেকর্ড রাখুন Postgres-এ, এমবেডিং সংরক্ষণ করুন বা Postgres-এ (pgvector) বা ভেক্টর সার্ভিসে রাখুন, সাদৃশ্য অনুসন্ধান চালিয়ে মিলিত IDs নিয়ে আসুন, তারপর পূর্ণ রো Postgres-থেকে ফেচ করুন।
যদি আপনি AppMaster-র মত প্ল্যাটফর্মে অ্যাপ বানান, PostgreSQL ইতিমধ্যেই স্ট্রাকচার্ড ডেটা ও পারমিশনের জন্য একটি প্রাকৃতিক ঘর। প্রশ্ন হলো এমবেডিং সার্চও সেখানে রাখবেন নাকি একটি বিশেষায়িত সার্ভিসে রেখে Postgres-কে সোর্স অফ ট্রুথ রাখবেন।
টিমগুলো প্রায়ই ফিচারের উপর ভিত্তি করে নির্বাচন করে এবং পরে দৈনন্দিন কাজ দেখে বিস্মিত হয়। বাস্তব সিদ্ধান্ত হলো আপনি জটিলতা কোথায় রাখতে চান: আপনার বিদ্যমান Postgres সেটআপের ভিতরে, না কি আলাদা সার্ভিসে।
pgvector দিয়ে, আপনি সেই ডাটাবেসেই ভেক্টর সার্চ যোগ করছেন যা আপনি ইতিমধ্যেই চলাচল করেন। সেটআপ সাধারণত সরল, কিন্তু এটি এখনও ডাটাবেস কাজ—শুধু অ্যাপ কোড নয়।
একটি সাধারণ pgvector সেটআপে এক্সটেনশন সক্রিয় করা, এমবেডিং কলাম যোগ করা, আপনার কুয়েরি প্যাটার্নের সাথে মেলে এমন একটি ইনডেক্স তৈরি করা (এবং পরে টিউন করা), কন্টেন্ট বদলে গেলে এমবেডিং কিভাবে আপডেট হবে তা ঠিক করা এবং সাদৃশ্য কুয়েরিতে আপনার সাধারণ ফিল্টারও প্রয়োগ করার কাজ থাকে।
ম্যানেজড ভেক্টর ডাটাবেসে একেবারে একটি নতুন সিস্টেম তৈরি করতে হয় আপনার প্রধান ডাটাবেসের পাশে। এতে কম SQL থাকতে পারে, কিন্তু একীভূতকরণ বাড়ে।
একটি সাধারণ managed সেটআপে একটি ইনডেক্স তৈরি করা (ডাইমেনশন ও ডিস্ট্যান্স মেট্রিক নির্ধারণ), API কী সংরক্ষনে সিক্রেট সেট করা, ইনজেশান জব বানিয়ে এমবেডিং ও মেটাডেটা পুশ করা, অ্যাপ রেকর্ড ও ভেক্টর রেকর্ডের মধ্যে একটি স্থায়ী ID ম্যাপিং বজায় রাখা, এবং নেটওয়ার্ক অ্যাকসেস লকডাউন করে কেবল আপনার ব্যাকএন্ডই কুয়েরি চালাতে পারবে তা নিশ্চিত করা থাকে।
CI/CD ও মাইগ্রেশনও ভিন্ন হয়। pgvector আপনার বিদ্যমান মাইগ্রেশন ও রিভিউ প্রসেসে সহজে ফিট করে। managed সার্ভিসে চেঞ্জগুলো কোড প্লাস অ্যাডমিন সেটিংসে যায়, তাই কনফিগারেশন পরিবর্তন এবং রিইনডেক্সিং-এর জন্য স্পষ্ট প্রক্রিয়া চাই।
ওনারশিপও প্রায়ই সিদ্ধান্তকে অনুসরণ করে। pgvector-এ কাজটি অ্যাপ ডেভ এবং যেই জনা Postgres পরিচালনা করে তার উপর চলে (কখনো কখনো DBA)। একটি managed সার্ভিস প্রায়ই প্ল্যাটফর্ম টিমের আওতায় থাকে, অ্যাপ ডেভ ইনজেশান ও কুয়েরি লজিক হ্যান্ডল করে। তাই এই সিদ্ধান্ত প্রযুক্তির চেয়ে টিম স্ট্রাকচারের ব্যাপারও।
সেমান্টিক সার্চ তখনই সাহায্য করে যখন এটি ব্যবহারকারী কী দেখতে পারবে তা সম্মান করে। বাস্তব ব্যবসায়িক অ্যাপে প্রতিটি রেকর্ডের পাশেই এমবেডিং থাকে: org_id, user_id, role, status (open, closed), এবং visibility (public, internal, private)। যদি আপনার সার্চ লেয়ার সেই মেটাডেটায় পরিষ্কারভাবে ফিল্টার করতে না পারে, আপনি বিভ্রান্তিকর ফল পাবেন বা, খারাপ হলে, তথ্য লিক হবে।
সবচেয়ে বড় বাস্তবিক পার্থক্য হলো ভেক্টর সার্চের আগে বনাম পরে ফিল্টার করা। পরে ফিল্টার করা সহজ শোনালেও এটি দুইভাবে ব্যর্থ হয়। প্রথমত, সেরা মিলগুলো অপসারণ হতে পারে এবং আপনার কাছে খারাপ ফল বাকি থাকতে পারে। দ্বিতীয়ত, পাইপলাইনের কোনো অংশ যদি লগ, ক্যাশ, বা আনফিল্টারড ফলাফল এক্সপোজ করে, তাহলে নিরাপত্তার ঝুঁকি বাড়ে।
pgvector-এ ভেক্টরগুলো PostgreSQL-এ মেটাডেটার পাশে থাকে, তাই আপনি একই SQL কুয়েরিতে পারমিশন প্রয়োগ করে Postgres-কে তা প্রয়োগ করতে দিতে পারেন।
যদি আপনার অ্যাপ ইতিমধ্যে Postgres ব্যবহার করে, pgvector সরলতার দিক থেকে জয়ী হতে পারে: সার্চ “আরও একটি কুয়েরি” মাত্র। আপনি টিকিট, কাস্টমার এবং সদস্যপদ জুড়ে JOIN করতে পারবেন, এবং Row Level Security ব্যবহার করে ডাটাবেস নিজে অননুমোদিত রো ব্লক করবে।
একটি সাধারণ প্যাটার্ন হলো org ও status ফিল্টার দিয়ে প্রার্থী সেট সংকুচিত করা, তারপর বাকি অংশে ভেক্টর সাদৃশ্য চালানো, প্রয়োজনে সঠিক আইডেন্টিফায়ারের জন্য কীওয়ার্ড মেলাও মিশিয়ে নেওয়া।
অধিকাংশ managed ভেক্টর ডাটাবেস মেটাডেটা ফিল্টার সাপোর্ট করে, কিন্তু ফিল্টার ভাষা সীমিত হতে পারে এবং JOIN নেই। সাধারণত আপনি প্রতিটি ভেক্টর রেকর্ডে মেটাডেটা ডেনরমালাইজ করবেন এবং অ্যাপ্লিকেশনে পারমিশন চেক পুনরায় বাস্তবায়ন করবেন।
বিজনেস অ্যাপে হাইব্রিড সার্চ চাইলে সাধারণত সবকিছু একসঙ্গে কাজ করা দরকার: হার্ড ফিল্টার (org, role, status, visibility), কীওয়ার্ড ম্যাচ (এক্স্যাক্ট টার্ম যেমন ইনভয়েস নম্বর), ভেক্টর সাদৃশ্য (অর্থ), এবং র্যাঙ্কিং নিয়ম (নতুন বা ওপেন আইটেমকে বুস্ট করা)।
উদাহরণ: AppMaster-এ তৈরি একটি সাপোর্ট পোর্টাল টিকিট ও পারমিশন PostgreSQL-এ রাখলে “এজেন্ট শুধু তাদের org-এর আইটেম দেখে” enforcing করা সোজা হয়, তবুও টিকিট সারাংশ ও রিপ্লাই-এ সেমান্টিক মিল পাওয়া যায়।
সার্চ কোয়ালিটি হচ্ছে প্রাসঙ্গিকতা (ফলাফলগুলো কতটা দরকারি) এবং গতি (কীটা ইন্টারঅ্যাকশন-অনুভব করে)। pgvector বা managed ভেক্টর ডাটাবেস—দুটোর ক্ষেত্রেই সাধারণত আপনি আনুমানিক সার্চ ব্যবহার করে কিছুটা রিলেভেন্স-হারানো বদলে লেটেন্সি কমান। এই ট্রেডঅফ ব্যবসায়িক অ্যাপে ঠিক আছে, যতক্ষণ আপনি বাস্তব কুয়েরি দিয়ে এটি মাপেন।
উচ্চ স্তরে আপনি তিন জিনিস টিউন করেন: এমবেডিং মডেল (“অর্থ” কেমন দেখায়), ইনডেক্স সেটিংস (ইঞ্জিন কত খুঁটিয়ে সার্চ করে), এবং র্যাঙ্কিং লেয়ার (ফিল্টার, সাম্প্রতিকতা, অথবা জনপ্রিয়তা যোগ করার পরে ফলাফল কেমন সাজে)।
PostgreSQL-এ pgvector দিয়ে আপনি সাধারণত IVFFlat বা HNSW-এর মত ইনডেক্স বেছে নেন। IVFFlat দ্রুত এবং নির্মাণে লঘু, কিন্তু আপনাকে কতগুলো “লিস্ট” ব্যবহার হবে তা টিউন করতে হবে এবং সাধারণত যথেষ্ট ডেটা থাকা ভালো। HNSW সাধারণত কম লেটেন্সিতে ভালো রিকল দেয়, কিন্তু বেশি মেমরি নিতে পারে এবং তৈরিতে সময় লাগে। Managed সিস্টেমগুলো একই রকম বিকল্প দেয়, শুধু নাম ও ডিফল্ট আলাদা।
কিছু কৌশল প্রত্যাশার চেয়ে বেশি কাজ করে: জনপ্রিয় কুয়েরি ক্যাশ করা, ব্যাচ ওয়ার্ক করা (উদাহরণস্বরূপ পরের পৃষ্ঠা প্রিফেচ করা), এবং দুটি ধাপের ফ্লো বিবেচনা করা—দ্রুত ভেক্টর সার্চ করে শীর্ষ 20–100 র্যাঙ্কিং পরে ব্যবসায়িক সিগন্যাল যেমন সাম্প্রতিকতা বা কাস্টমার টিয়ার দিয়ে পুনঃর্যাঙ্ক করা। এছাড়া নেটওয়ার্ক হপ খেয়াল রাখুন—যদি সার্চ আলাদা সার্ভিসে থাকে, প্রতিটি কুয়েরি আরেকটি রাউন্ড ট্রিপ হয়।
গুণমান মাপার জন্য ছোট এবং স্পষ্ট শুরু করুন। 20–50 বাস্তব ব্যবহারকারীর প্রশ্ন সংগ্রহ করুন, “ভাল” উত্তর কী তা সংজ্ঞায়িত করুন, এবং শীর্ষ 3 ও শীর্ষ 10 হিট রেট, মিডিয়ান ও p95 লেটেন্সি, নো-গুড-রেজাল্টের শতাংশ, এবং পারমিশন ও ফিল্টার যুক্ত করলে কেমন গুণমান কমে সেটি ট্র্যাক করুন।
এখানেই সিদ্ধান্ত তাত্ত্বিক থেকে বাস্তবে বদলে যায়। সেরা অপশন হলো যেটা আপনার রিলেভেন্স টার্গেট মাপক এবং ব্যবহারকারী মেনে নেয় এমন লেটেন্সিতে পৌঁছায়—এবং যেটা টিউন করা আপনার টিম বজায় রাখতে পারে।
অনেক টিম pgvector দিয়ে শুরু করে কারণ এটি সবকিছু এক جا রাখে: অ্যাপ ডেটা ও এমবেডিং। ব্যবসায়িক অনেক অ্যাপের জন্য একটি একক PostgreSQL নোড যথেষ্ট, বিশেষ করে যদি আপনার কাছে দশ হাজার থেকে কয়েক লক্ষ পর্যন্ত ভেক্টর থাকে এবং সার্চ টপ ট্রাফিক না হয়।
আপনি সাধারণত সীমায় পৌঁছান যখন সেমান্টিক সার্চ হয়ে ওঠে একটি কোর ইউজার অ্যাকশন (প্রতিটি পেজে, প্রতিটি টিকিটে, চ্যাটে), বা যখন আপনি মিলিয়ন-লেভেলের ভেক্টর রাখেন এবং পিক সময়ে টাইট রেসপন্স টাইম দরকার।
সাধারণ লক্ষণগুলো যখন একক Postgres স্ট্রেইন হচ্ছে: p95 সার্চ লেটেন্সি লেখার ক্রিয়াকলাপ চলাকালীন বেড়ে যায়, দ্রুত ইনডেক্স বনাম গ্রহণযোগ্য লেখার গতি মধ্যে পছন্দ করতে হয়, মেইনটেন্যান্স কাজ রাতের শিডিউল করা লাগে, এবং সার্চের জন্য আলাদা স্কেলিং প্রয়োজন যা বাকি DB-এর থেকে আলাদা।
pgvector-এ স্কেলিং মানে প্রায়ই কুয়েরি লোডের জন্য রিড রিপ্লিকা যোগ করা, টেবিল পার্টিশন করা, ইনডেক্স টিউন করা, এবং ইনডেক্স বিল্ড ও স্টোরেজ বৃদ্ধির চারপাশে পরিকল্পনা করা। এটা করা যায়, কিন্তু চলমান কাজ হয়ে ওঠে। আপনি ডিজাইন-চয়েসও পাবেন—এম্বেডিং একই টেবিলে রাখবেন নাকি আলাদা করে বুট করবেন যাতে ব্লোট ও লক কনটেনশন কমে।
Managed ভেক্টর ডাটাবেস ওয়েন্ডরকে অনেক কিছু হ্যান্ডল করতে দেয়। তারা প্রায়ই কনpute ও স্টোরেজ আলাদাভাবে স্কেল করার সুবিধা, বিল্ট-ইন শার্ডিং, এবং সহজ হাই-অ্যাভেলিবিলিটি দেয়। ট্রেডঅফ হলো দুইটি সিস্টেম (Postgres + ভেক্টর স্টোর) অপারেট করা এবং মেটাডাটা ও পারমিশন সিঙ্কে রাখার কাজ।
খরচ টিমকে পারফরম্যান্সের চেয়ে বেশীই চমকে দেয়। বড় চালকরা হলেন স্টোরেজ (ভেক্টর ও ইনডেক্স দ্রুত বেড়ে যায়), পিক কুয়েরি ভলিউম (প্রায়ই বিল নির্ধারণ করে), আপডেট ফ্রিকোয়েন্সি (রিইমবেডিং ও আপসর্ট), এবং ডেটা মুভমেন্ট (আপনি যখন ফিল্টারিংয়ের জন্য অতিরিক্ত কল করেন)।
pgvector বনাম managed সার্ভিসের সিদ্ধান্ত হলে ভাবুন কোন ব্যথা আপনি পছন্দ করবেন: Postgres টিউনিং ও ক্ষমতা পরিকল্পনা নিজেরা করা, না কি সহজ স্কেলিংয়ের জন্য বেশি খরচ দিয়ে আরেকটি নির্ভরযোগ্যতা যোগ করা।
সিকিউরিটি ডিটেইল অনেক সময় স্পিডিং বেঞ্চমার্কের চেয়ে দ্রুত সিদ্ধান্ত নেয়। শীঘ্রই জিজ্ঞেস করুন: ডেটা কোথায় থাকবে, কে তা দেখতে পারবে, এবং আউটেজ হলে কি হবে।
শুরু করুন ডেটা রেসিডেন্সি ও অ্যাকসেস দিয়ে। এমবেডিংও অর্থ বহন করে এবং অনেক টিম কভার হাইলাইটিং-এর জন্য র কাঁচা স্নিপেটও রাখে। পরিষ্কার করুন কোন সিস্টেম কাঁচা টেক্সট (টিকিট, নোট, ডকুমেন্ট) রাখবে এবং কোনটা শুধুই এমবেডিং রাখবে। এছাড়া নির্ধারণ করুন কোম্পানির মধ্যে কে সরাসরি স্টোর কুয়েরি করতে পারবে এবং প্রোডাকশন ও অ্যানালাইটিক্স অ্যাক্সেসের মধ্যে কঠোর বিভাজন কি দরকার কি না।
নিচের প্রশ্নগুলো যেকোন অপশনের জন্য জিজ্ঞাসা করুন:
মাল্টি-টেন্যান্ট বিভাজন লোকেরা প্রায়ই উপেক্ষা করে। যদি একজন গ্রাহক কখনই অন্যকে প্রভাবিত করতে না পারে, আপনাকে প্রতিটি কুয়েরিতে শক্তিশালী টেন্যান্ট স্কোপিং লাগবে। PostgreSQL-এ এটি Row Level Security ও সতর্ক কুয়েরি প্যাটার্ন দিয়ে বাধ্য করা যায়। Managed ভেক্টর DB-তে সাধারণত namespace বা collection ব্যবহার করে এবং অ্যাপ্লিকেশন লজিকে নির্ভর করতে হয়।
সার্চ ডাউনটাইমের পরিকল্পনা করুন। যদি ভেক্টর স্টোর ডাউন হয়, ব্যবহারকারীরা কি দেখবে? নিরাপদ ডিফল্ট হলো কীওয়ার্ড সার্চে fallback করা, অথবা কেবল সাম্প্রতিক আইটেম দেখানো—নজরে করে পেজ ভেঙে পড়ার চেয়ে।
উদাহরণ: AppMaster-এ তৈরি একটি সাপোর্ট পোর্টালে আপনি টিকিট PostgreSQL-এ রাখেন এবং সেমান্টিক সার্চকে একটি অপশনাল ফিচার হিসেবে বিবেচনা করতে পারেন। যদি এমবেডিং লোড করতে ব্যর্থ হয়, পোর্টাল এখনও টিকিট তালিকা দেখাতে এবং নির্দিষ্ট কীওয়ার্ড সার্চ চালাতে সক্ষম হওয়া উচিত যতক্ষণ আপনি ভেক্টর সার্ভিস রিকভার করেন।
নিরাপদ উপায় হল একটি ছোট পাইলট চালানো যা আপনার বাস্তব অ্যাপের মত দেখায়—ডেমো নোটবুক নয়।
প্রথমে লিখে ফেলুন আপনি কী সার্চ করবেন এবং কোনগুলো ফিল্টার বাধ্যতামূলক। “আমাদের ডকস সার্চ” অস্বচ্ছ। বরং লিখুন: “হেল্প আর্টিকেল, টিকিট রিপ্লাই, ও PDF ম্যানুয়াল সার্চ করো—কিন্তু শুধু সেই আইটেমগুলো দেখাও যা ব্যবহারকারী দেখতে পারবে।” পারমিশন, টেন্যান্ট ID, ভাষা, প্রোডাক্ট এরিয়া, এবং “শুধু পাবলিশড কনটেন্ট” ফিল্টারই প্রায়ই বিজয়ী নির্ধারণ করে।
পরবর্তীতে একটি এমবেডিং মডেল ও রিফ্রেশ প্ল্যান বেছে নিন। নির্ধারণ করুন কী এমবেড করা হবে (পুরো ডকুমেন্ট, chunks, না দুটোই) এবং কত ঘনঘন আপডেট হবে (প্রতি এডিটে, নাইটলি, না শুধুই পাবলিশে)। কনটেন্ট যদি ঘনঘন বদলে যায়, তাহলে পুনঃএম্বেডিং কত কষ্টদায়ক তা মাপুন, শুধু কুয়েরির গতি নয়।
তারপর আপনার ব্যাকএন্ডে একটি পাতলা সার্চ API তৈরি করুন। এটি সোজা রাখুন: একটি এন্ডপয়েন্ট যা একটি কুয়েরি ও ফিল্টার ফিল্ড নেয়, শীর্ষ ফলাফল রিটার্ন করে, এবং কী ঘটেছে তা লগ করে। AppMaster ব্যবহার করলে আপনি ইনজেশন ও আপডেট ফ্লো ব্যাকএন্ড সার্ভিস হিসেবে এবং একটি Business Process হিসেবে বাস্তবায়ন করতে পারবেন—যা আপনার এমবেডিং প্রদানকারীকে কল করে, ভেক্টর ও মেটাডেটা লেখে এবং অ্যাক্সেস নিয়ম এনফোর্স করে।
বাস্তব ব্যবহারকারী ও কাজ নিয়ে দুই সপ্তাহের পাইলট চালান। কয়েকটি সাধারণ প্রশ্ন ব্যবহার করুন, “উত্তর পাওয়ার হার” ও প্রথম উপকারী ফলাফল পাওয়ার সময় ট্র্যাক করুন, খারাপ ফলাফল সাপ্তাহিক পর্যালোচনা করুন, রিইমবেডিং ভলিউম ও কুয়েরি লোড মনিটর করুন, এবং মেটাডেটা অনুপস্থিতি বা স্টেল ভেক্টর—এমন ফেলিওর কেস পরীক্ষা করুন।
শেষে প্রমাণের ভিত্তিতে সিদ্ধান্ত নিন। যদি pgvector গুণমান ও ফিল্টারিং প্রয়োজন মেটায় এবং অপস কাজ স্বল্প থাকে—তবে রাখুন। যদি স্কেলিং ও রিলায়েবিলিটি বড় উদ্বেগ হয়—managed সার্ভিস বিবেচনা করুন। অথবা একটি হাইব্রিড অপশন চালান (PostgreSQL মেটাডেটা ও পারমিশন, ভেক্টর সার্ভিস রিট্রিভাল) যদি তা আপনার স্ট্যাকের সাথে ভালো ফিট করে।
প্রথম ডেমো কাজ করলে বেশিরভাগ ভুল পরে আসে। একটি দ্রুত প্রুফ-অফ-কনসেপ্ট সুন্দর লাগতে পারে, তারপর বাস্তব ব্যবহারকারী, বাস্তব ডেটা ও বাস্তব নিয়ম যোগ করলে ভেঙে পড়ে।
সবচেয়ে সাধারণ এমন কয়েকটি ভুল:
একটি সহজ “day-2” টেস্ট এইগুলো আগে ধরবে: একটি নতুন পারমিশন নিয়ম যোগ করুন, 20টি আইটেম আপডেট করুন, 5টি মুছুন, তারপর একই 10টি মূল্যায়ন প্রশ্ন আবার জিজ্ঞেস করুন। AppMaster-এ তৈরি করলে এই চেকগুলো আপনার ব্যবসায়িক লজিক ও DB মডেলের সাথে প্ল্যান করুন, পরে নয়।
একটি মধ্য-আকারের SaaS কোম্পানি একটি সাপোর্ট পোর্টাল চালায় যেখানে মূল কনটেন্ট টাইপ দুটি: কাস্টমার টিকিট ও হেল্প সেন্টার আর্টিকেল। তারা চায় একটি সার্চ বক্স যা অর্থ বুঝে—তাই “can’t log in after changing phone” টাইপ করলে সঠিক আর্টিকেল এবং অনুরূপ পুরানো টিকিটগুলো দেখানো উচিত।
অপশনগুলো বাস্তবে কি চান তা পরিষ্কার করে দেয়: প্রতিটি কাস্টমার কেবল তাদের নিজস্ব টিকিটই দেখবে, এজেন্টরা স্ট্যাটাস (open, pending, solved) দিয়ে ফিল্টার করতে পারবে, এবং ফলাফল টাইপিং করলে সাজেশন হিসেবে আসা উচিত—অতএব রিয়েলটাইম অনুভব করা জরুরি।
যদি পোর্টাল ইতিমধ্যেই টিকিট ও আর্টিকেল PostgreSQL-এ রাখে (AppMaster-এর মত স্ট্যাক হলে কমন), pgvector যোগ করা একটি পরিষ্কার প্রথম ধাপ হতে পারে। আপনি এমবেডিং, মেটাডেটা এবং পারমিশন এক জায়গায় রাখেন, তাই “শুধু customer_123-এর টিকিট” হল শুধু একটি WHERE ক্লজ।
এটি ভাল কাজ করে যদি আপনার ডেটাসেট মধ্যম (দশ থেকে কয়েক লক্ষ আইটেম), আপনার টিম Postgres ইনডেক্স ও কুয়েরি প্ল্যান টিউন করতে আরামদায়ক, এবং আপনি কম মুভিং-পার্টস চান।
ট্রেডঅফ হলো ভেক্টর সার্চ ট্রানজেকশনাল ওয়ার্কলোডের সাথে প্রতিযোগিতা করতে পারে। ব্যবহার বাড়লে আপনাকে অতিরিক্ত ক্ষমতা, সাবধানে ইনডেক্সিং, বা এমনকি টিকিট লেখাকে রক্ষা করতে আলাদা Postgres ইনস্ট্যান্স বিবেচনা করতে হতে পারে।
Managed ভেক্টর ডাটাবেসে আপনি সাধারণত এমবেডিং এবং একটি ID রাখেন, অথচ “সত্য” (টিকিট স্ট্যাটাস, customer_id, পারমিশন) PostgreSQL-এ রাখেন। দলগুলো বাস্তবে হয় প্রায়ই প্রথমে Postgres-এ ফিল্টার করে যোগ্য IDs বের করে তারপর সার্চ করে, অথবা আগে সার্চ করে এবং ফলাফল দেখানোর আগে পারমিশন রি-চেক করে।
এই অপশনটি জেতেন যখন গ্রোথ অনিশ্চিত বা টিম পারফরম্যান্স নার্স করতে চাই না। কিন্তু পারমিশন ফ্লোতে সতর্কতা না নিলে কাস্টমারদের মধ্যে রেজাল্ট লিকের ঝুঁকি থাকে।
প্রায়োগিক সিদ্ধান্ত হলো: যদি এখনই টাইট ফিল্টারিং ও সহজ অপ্স চান তবে pgvector দিয়ে শুরু করুন; আর যদি দ্রুত বৃদ্ধি বা ভারী কুয়েরি ভলিউম আশা করেন, বা সার্চ আপনার মূল ডাটাবেসকে ধীর করতে পারেন না—তখন managed ভেক্টর DB পরিকল্পনা করুন।
আপনি আটকে গেলে বৈশিষ্ট্য নিয়ে আলোচনা বন্ধ করে প্রথম দিনের জন্য আপনার অ্যাপকে কী করতে হবে তা লিখে ফেলুন। বাস্তব প্রয়োজনসমূহ প্রায়ই একটি ছোট পাইলটের সময় প্রকাশ পায়।
নিচের প্রশ্নগুলো সাধারণত বেঞ্চমার্কের চেয়ে দ্রুত বিজয়ী নির্ধারণ করে:
পরিবর্তনের জন্যও পরিকল্পনা করুন। এমবেডিং সেট-অ্যান্ড-ফরগেট নয়। টেক্সট বদলায়, মডেল বদলে যায়, এবং রিলেভেন্স ড্রিফ্ট হয় যতক্ষণ না কেউ অভিযোগ করে। পূর্বনির্ধারিত করুন কিভাবে আপডেট হ্যান্ডল করবেন, ড্রিফট কীভাবে সনাক্ত করবেন, এবং কী মনিটর করবেন (কুয়েরি লেটেন্সি, এরর রেট, ছোট টেস্ট সেটে রিকল, এবং “কোন ফলাফল নেই” সার্চ)।
আপনি যদি সার্চের চারপাশের পূর্ণ ব্যবসায়িক অ্যাপ দ্রুত নির্মাণ করতে চান, AppMaster (appmaster.io) ব্যবহার করা বাস্তবিক উপযোগী হতে পারে: এটি PostgreSQL ডেটা মডেলিং, ব্যাকএন্ড লজিক এবং ওয়েব/মোবাইল UI একটিমাত্র নো-কোড ওয়ার্কফ্লোতে দেয়, এবং আপনি কোর অ্যাপ ও পারমিশন স্থাপনের পরে সেমান্টিক সার্চ অ্যাড করতে পারবেন।
সেমান্টিক সার্চ সেই সব ক্ষেত্রে ব্যবহারকারী শব্দগুলো ডকুমেন্টের সঠিক ওয়ার্ডের সাথে মেলে না তবুও কাজে লাগার মত ফলাফল দেয়। এটি টাইপো, সংক্ষিপ্ত লেখা, বা লক্ষণের বর্ণনা—যা সহায়তা পোর্টাল, অভ্যন্তরীণ টুল ও জ্ঞানভিত্তিক সাইটে সাধারণ—এসব পরিস্থিতিতে বিশেষভাবে সহায়ক।
যখন আপনি কম কম্পোনেন্ট রাখতে চান, SQL-ভিত্তিক ফিল্টার দরকার এবং আপনার ডেটাসেট ও ট্রাফিক এখনও সীমিত—সেটাই হলো pgvector-এর আদর্শ ব্যবহার। vectors ও মেটাডেটা একই PostgreSQL কুয়েরিতে থাকায় এটি নিরাপদ ও ত্বরান্বিত ফিল্টারিং দেয়।
যদি আপনি ভেক্টর সংখ্যা বা কুয়েরি ভলিউম দ্রুত বাড়বে বলে মনে করেন, বা সার্চের স্কেলিং ও অ্যাভেলিবিলিটি প্রধান উদ্বেগ এবং আপনি সেটি আপনার প্রধান ডেটাবেসের বাইরে রাখতে চান—তখন managed vector database বিবেচনা করা ঠিক। এতে অপারেশন সহজ হতে পারে কিন্তু ইনটেসগ্রেশন ও পারমিশন হ্যান্ডলিং বাড়ে।
এম্বেডিং হলো টেক্সটকে এমন একটি সংখ্যার তালিকায় রূপান্তর করা যা অর্থ/মত প্রকাশ করে। ভেক্টর স্টোর (বা PostgreSQL-এ pgvector) সেই ভেক্টরগুলো রাখে এবং দ্রুত খুঁজে দেয় কোন ভেক্টরগুলো প্রশ্নের সাথে সবচেয়ে কাছাকাছি—এভাবেই আপনি “ইনটেন্ট অনুযায়ী মিল” ফলাফল পান।
ভেক্টর সার্চের পরে ফিল্টার করা খারাপ কারণ সেটি প্রায়ই সেরা মিলগুলো বাদ দিয়ে দেয় এবং ব্যবহারকারীদের খারাপ বা শূন্য ফলাফল দেয়। এছাড়া লগ, ক্যাশ বা ডিবাগিংয়ে আনফিল্টারড ডেট এক্সপোজ হওয়ার ঝুঁকি বাড়ে। তাই টেন্যান্ট ও রোল ফিল্টার যত সম্ভব আগে প্রয়োগ করা উচিত।
pgvector-এ আপনি সেই একই SQL কুয়েরিতে পারমিশন, JOIN এবং Row Level Security প্রয়োগ করতে পারেন যা সাদৃশ্য খোঁজে; ফলে “নিষিদ্ধ সারি কখনই দেখাবেন না” নিশ্চিত করা সহজ হয় কারণ PostgreSQL-ই তা বলবৎ করে।
বেশিরভাগ managed vector DB মেটাডেটা ফিল্টার সাপোর্ট করে, কিন্তু JOIN-গুলো নেই এবং ফিল্টার ভাষা সীমিত হতে পারে। সাধারণত আপনি পারমিশন-সংক্রান্ত মেটাডেটা প্রতিটি ভেক্টর রেকর্ডে ডেনরমালাইজ করবেন এবং চূড়ান্ত অথোরাইজেশন চেক অ্যাপ্লিকেশনে করবেন।
আপনি সাধারণত ডকুমেন্টগুলোকে ছোট অংশে ভাগ করে এমবেড করেন—এটাই chunking। এতে প্রতিটি ভেক্টর একটি নির্দিষ্ট ধারণা প্রতিনিধিত্ব করে, ফলাফল আরও নির্ভুল হয়। ছোট আইটেমে সম্পূর্ণ ডকুমেন্ট এমবেডিং কাজ করতে পারে, কিন্তু বড় পেজ, টিকিট বা PDF-এ chunking প্রায়ই প্রয়োজন।
প্রকাশ বা সম্পাদনার সময় পুনঃএম্বেড করার পরিকল্পনা রাখুন এবং সোর্স রেকর্ড ডিলিট হলে ভেক্টরও মুছুন। না হলে আপনি পুরনো বা অনুপস্থিত টেক্সটে ইঙ্গিত দেয় এমন স্টেলে ফলাফল পরিবেশন করবেন।
নিরাপদ উপায় হল একটি বাস্তব-পর্দার পাইলট চালানো: বাস্তব কুয়েরি ও হার্ড ফিল্টার সহ, রিলেভেন্স ও লেটেন্সি পরিমাপ করা এবং যেমন মেটাডেটা অনুপস্থিতি বা পুরনো ভেক্টর—এই ধরনের ফলক কেস টেস্ট করা। সেই প্রমাণভিত্তিক ফলাফলে সিদ্ধান্ত নিন।



বিনামূল্যের পরিকল্পনা সহ অ্যাপমাস্টারের সাথে পরীক্ষা করুন।
আপনি যখন প্রস্তুত হবেন তখন আপনি সঠিক সদস্যতা বেছে নিতে পারেন৷


