সরঞ্জাম রিজার্ভেশন অ্যাপ: সংঘাত ঠেকান এবং ফেরত ট্র্যাক করুন
এমন একটি সরঞ্জাম রিজার্ভেশন অ্যাপ পরিকল্পনা করুন যা ডাবল বুকিং বন্ধ করে, ফেরত ও ক্ষতির রেকর্ড রাখে এবং ত্রুটিপূর্ণ সরঞ্জামকে রক্ষণাবেক্ষণে আটকে দেয়।
দীর্ঘ-চলমান ওয়ার্কফ্লো ঘৃণ্যভাবে ব্যর্থ হতে পারে। স্পষ্ট স্টেট প্যাটার্ন, স্টেপ-স্তরের রিট্রাই, ডেড-লেটার হ্যান্ডলিং এবং অপারেটররা ভরসা করতে পারে এমন ড্যাশবোর্ড শিখুন।
দীর্ঘ-চলমান ওয়ার্কফ্লো দ্রুত অনুরোধের চেয়েও আলাদা ভাবে ব্যর্থ হয়। একটি ছোট API কল তাত্ক্ষণিকভাবে সফল বা ত্রুটিপূর্ণ হতে পারে। কিন্তু কয়েক ঘণ্টা বা দিন ধরে চলা একটি ওয়ার্কফ্লো ১০টি ধাপের মধ্যে ৯টি করে ফেললেও এক বিশৃঙ্খলা রেখে যেতে পারে: অর্ধেক তৈরি রেকর্ড, বিভ্রান্ত স্ট্যাটাস, এবং পরের সুস্পষ্ট কার্য কি তা জানা নেই।
এই কারণেই "গতকাল কাজ করছিল" গানটি এত বার শুনতে হয়। ওয়ার্কফ্লো বদলায়নি, কিন্তু পরিবেশ বদলে গেছে। দীর্ঘ-চলমান ওয়ার্কফ্লো অন্য সার্ভিসগুলোর সুস্থ থাকা, ক্রেডেনশিয়ালগুলোর বৈধ থাকা, এবং ডেটা প্রত্যাশিত আকারে থাকা—এসবের উপর নির্ভর করে।
সবচেয়ে সাধারণ ব্যর্থতার মোডগুলো হল: টাইমআউট ও ধীর ডিপেনডেন্সি (একটি পার্টনার API চলমান আছে কিন্তু আজ ৪০ সেকেন্ড নিচ্ছে), আংশিক আপডেট (রেকর্ড A তৈরি, রেকর্ড B তৈরি হয়নি, এবং নিরাপদভাবে পুনরায় চালানো যাচ্ছে না), ডিপেনডেন্সি আউটেজ (ইমেইল/SMS প্রদানকারী, পেমেন্ট গেটওয়ে, রক্ষণাবেক্ষণ উইন্ডো), হারানো কলব্যাক ও মিসড শেডিউল (একটি webhook কখনোই আসেনি, একটি টাইমার কাজ করেনি), এবং মানুষের ধাপ যা আটকে যায় (অনুমোদন কয়েক দিন ধরে আটকে থাকে, তারপর পুরোনো অনুমান নিয়ে আবার চালু হয়)।
কঠিন অংশটি হল স্টেট। একটি "দ্রুত অনুরোধ" শেষ হওয়া পর্যন্ত মেমরিতে স্টেট রাখতে পারে। একটি ওয়ার্কফ্লো পারে না। এটা ধাপগুলোর মধ্যে স্টেট পারসিস্ট করতে হবে এবং রিস্টার্ট, ডিপ্লয় বা ক্র্যাশের পর পুনরায় চালু হওয়ার জন্য প্রস্তুত থাকতে হবে। একই সাথে এটাকে একই ধাপ দুইবার ট্রিগার হওয়ার (রিট্রাই, ডুপ্লিকেট webhook, অপারেটর রিপ্লে) পরিস্থিতি সামলাতে হবে।
বাস্তবে, "বিশ্বস্ত" হওয়া মানে কখনো ব্যর্থ না হওয়া নয়; বরং predictable, explainable, recoverable এবং স্পষ্টভাবে দায়িত্ব নির্ধারিত হওয়া।
Predictable মানে হলো নির্ভরশীলতার ব্যর্থতার সময়ে ওয়ার্কফ্লো একইভাবে প্রতিক্রিয়া করে। Explainable মানে একজন অপারেটর এক মিনিটের মধ্যে উত্তর দিতে পারে, "এটি কোথায় আটকে আছে এবং কেন?" Recoverable মানে আপনি নিরাপদভাবে রিট্রাই বা চালিয়ে যেতে পারেন। Clear ownership মানে প্রতিটি আটকে থাকা আইটেমের একটি স্পষ্ট পরবর্তী কাজ আছে: অপেক্ষা, পুনরায় চেষ্টা, ডেটা ঠিক করা, বা একজন লোককে হস্তান্তর করা।
সহজ একটি উদাহরণ: একটি অনবোর্ডিং অটোমেশন একটি কাস্টমার রেকর্ড তৈরি করে, অ্যাক্সেস প্রদান করে, এবং একটি স্বাগত বার্তা পাঠায়। যদি provisioning সফল হয় কিন্তু মেসেজ পাঠানো ব্যর্থ হয় কারণ ইমেইল প্রদানকারী ডাউন, একটি নির্ভরযোগ্য ওয়ার্কফ্লো "Provisioned, message pending" রেকর্ড করবে এবং রিট্রাই নির্ধারণ করবে। এটি অন্ধভাবে provisioning পুনরায় চালাবে না।
টুলগুলো এই কাজকে সহজ করতে পারে যদি ওয়ার্কফ্লো লজিক এবং পারসিস্টেন্ট ডেটা কাছাকাছি রাখা হয়। উদাহরণস্বরূপ, AppMaster-এ আপনি Data Designer ব্যবহার করে ওয়ার্কফ্লো স্টেট মডেল করতে পারেন এবং Business Processes থেকে আপডেট করতে পারেন। কিন্তু নির্ভরযোগ্যতা টুল নয়—প্যাটার্ন থেকে আসে: দীর্ঘ-চলমান অটোমেশনকে ধ্রুব স্টেটে বিবেচনা করুন যা সময়, ব্যর্থতা, এবং মানব হস্তক্ষেপ সহ টিকে থাকতে পারে।
দীর্ঘ-চলমান ওয়ার্কফ্লো সাধারণত পুনরাবৃত্তভাবে ব্যর্থ হয়: তৃতীয়-পক্ষ API ধীর হয়ে যায়, একজন মানুষ অনুমোদন দেয়নি, বা একটি জব কিউ-র পেছনে অপেক্ষা করছে। সুস্পষ্ট স্টেট এসব পরিস্থিতি স্পষ্ট করে তোলে, যাতে মানুষ "সময় নিচ্ছে" এবং "ভাঙা" এই বিভ্রান্তিতে পড়ে না।
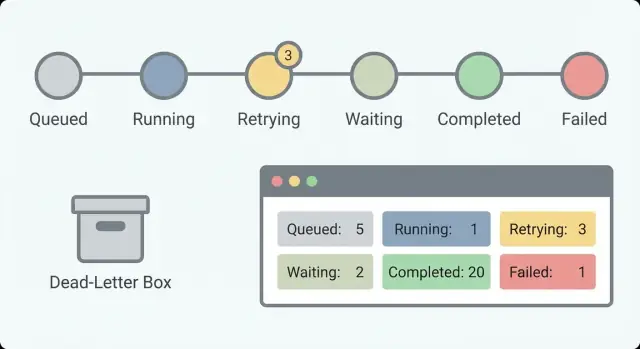
একটি ছোট সেট স্টেট দিয়ে শুরু করুন যা একটি প্রশ্নের উত্তর দেয়: এখন কি হচ্ছে? যদি আপনার ৩০টি স্টেট থাকে, কেউই সেগুলো মনে রাখবে না। প্রায় ৫-৮টি স্টেট দিয়ে একজন অন-কল ব্যক্তি একটি তালিকা স্ক্যান করে বুঝতে পারবে।
অনেক ওয়ার্কফ্লোর জন্য কার্যকর একটি বাস্তবসম্মত স্টেট সেট:
Waiting কে Running থেকে আলাদা করা গুরুত্বপূর্ণ। "Waiting for customer response" স্বাভাবিক। "6 ঘন্টা ধরে Running" অর্থ হতে পারে হ্যাং হয়ে গেছে। এই বিভাজন ছাড়া আপনি মিথ্যা অ্যালার্মের পেছনে উড়ে বেড়াবেন এবং প্রকৃত সমস্যাগুলো মিস করবেন।
শুধু একটি স্টেট নামই যথেষ্ট নয়। কয়েকটি ফিল্ড যোগ করুন যা একটি স্ট্যাটাসকে কার্যকর করে:
উদাহরণ: একটি অনবোর্ডিং ফ্লো "Waiting" দেখাতে পারে কারণ "Pending manager approval" এবং পরিবর্তনটাইম "2 দিন আগে"। এটি বলে দেয় এটি আটকা পড়েনি, তবে মনে করিয়ে দেওয়া লাগতে পারে।
স্টেট নামগুলোকে একটি API-র মতো বিবেচনা করুন। যদি আপনি প্রতিমাসে নাম পরিবর্তন করেন, ড্যাশবোর্ড, অ্যালার্ট এবং সাপোর্ট প্লেবুক দ্রুত ভুল হয়ে যাবে। নতুন মান দরকার হলে, একটি নতুন স্টেট পরিচয় করিয়ে দিন এবং পুরনোটিকে বিদ্যমান রেকর্ডগুলোর জন্য রেখে দিন।
AppMaster-এ আপনি Data Designer-এ এই স্টেটগুলো মডেল করতে পারেন এবং Business Process লজিকে এগুলো আপডেট করতে পারেন। এতে স্ট্যাটাস আপনার অ্যাপে দৃশ্যমান ও সঙ্গত থাকে, লোগে লুকানো থাকেনা।
রিট্রাই সহায়ক যতক্ষণ না তা আসল সমস্যাকে লুকিয়ে রাখে। লক্ষ্য হলো "কখনো ব্যর্থ না হওয়া" নয়—লক্ষ্য হলো "এভাবে ব্যর্থ হওয়া যাতে মানুষ বুঝতে ও ঠিক করতে পারে"। এটি একটি স্পষ্ট নিয়ম দিয়ে শুরু করা উচিত: কী রিট্রাইযোগ্য এবং কী নয়।
অধিকাংশ টিম চালিয়ে নিতে পারে এমন একটি নিয়ম: সাময়িক হওয়ার সম্ভাবনা থাকা ত্রুটিগুলো রিট্রাই করুন (নেটওয়ার্ক টাইমআউট, রেট লিমিট, সাময়িক তৃতীয়-পক্ষ আউটেজ)। স্পষ্টভাবে স্থায়ী ত্রুটিগুলো রিট্রাই করবেন না (ভুল ইনপুট, অনুপস্থিত অনুমতি, "account closed", "card declined"). যদি আপনি কোন বাইটে একটি ত্রুটি পড়ে কোন ক্যাটেগরিতে পড়ে তা না জানেন, শেখা না হওয়া পর্যন্ত এটিকে নন-রিট্রাইযোগ্য ধরে নিন।
স্টেপ (বা এক্সটার্নাল কল) অনুযায়ী রিট্রাই কাউন্টার ট্র্যাক করুন, শুধু পুরো ওয়ার্কফ্লোর জন্য একটি কেবল কাউন্টার নয়। একটি ওয়ার্কফ্লোতে দশটি ধাপ থাকতে পারে এবং শুধু একটি ধাপই অনিশ্চিত হতে পারে। স্টেপ-লেভেল কাউন্টার পরে একটি ধাপকে আগের ধাপ থেকে চেষ্টা চুরি করতে দেয় না।
উদাহরণস্বরূপ, একটি "Upload document" কল কয়েকবার রিট্রাই করা হতে পারে, যেখানে "Send welcome email" অনির্দিষ্টকাল রিট্রাই করা উচিত নয় কেবলমাত্র কারণ আপলোডটি আগে প্রচেষ্টা খেয়ে ফেলেছে।
ঝুঁকির সাথে মেলে এমন একটি ব্যাকঅফ প্যাটার্ন বেছে নিন। সাধারণ, কম-লাগতে থাকা রিট্রাই-এর জন্য স্থির বিলম্ব যথেষ্ট হতে পারে। রেট লিমিটের ক্ষেত্রে exponential backoff সাহায্য করে। এমন একটি ক্যাপ রাখুন যাতে অপেক্ষা অর্পিতভাবে বড় না হয়, এবং retry storms প্রতিরোধে একটু jitter রাখুন।
তারপর নির্ধারণ করুন কখন থামবেন। ভালো স্টপ কন্ডিশনগুলো স্পষ্ট: সর্বোচ্চ প্রচেষ্টা, সর্বোচ্চ মোট সময়, বা "নির্দিষ্ট ত্রুটি কোডের জন্য ছেড়ে দেওয়া"। একটি পেমেন্ট গেটওয়ে যদি "invalid card" দেয়, তাহলে তা তৎক্ষণাৎ থামানো উচিত এমনকি আপনি সাধারণত পাঁচবার চেষ্টা করতে দিতেও পারেন।
অপারেটররা জানতে চায় পরের কি হবে। পরের রিট্রাই সময় ও কারণ রেকর্ড করুন (উদাহরণ: "Retry 3/5 at 14:32 due to timeout"). AppMaster-এ আপনি এটি ওয়ার্কফ্লো রেকর্ডে সংরক্ষণ করতে পারেন যাতে ড্যাশবোর্ড "waiting until" দেখাতে পারে বিনা অনুমানে।
একটি ভাল রিট্রাই পলিসি একটি ট্রেইল রেখে যায়: কি ব্যর্থ হয়েছে, কতবার চেষ্টা করা হয়েছে, কখন আবার চেষ্টা হবে, এবং কখন থেমে ডেড-লেটার হ্যান্ডলিং-এ হস্তান্তর করা হবে।
ঘণ্টা বা দিন ধরে চলা ওয়ার্কফ্লোতে রিট্রাই স্বাভাবিক। ঝুঁকি হলো এমন ধাপ পুনরাবৃত্তি করা যা ইতিমধ্যে সফল হয়েছে। আইডেমপোটেন্সি হলো সেই নিয়ম যা এটিকে নিরাপদ করে: একটি স্টেপ আইডেমপোটেন্ট যদি এটি দুইবার চালানো একই প্রভাব দেয় যেমন একবার চালানো।
একটি ক্লাসিক ব্যর্থতা: আপনি কার্ড চার্জ করেছেন, তারপর ওয়ার্কফ্লো ক্র্যাশ করে "payment succeeded" সেভ না করে। রিট্রাই-এ এটি আবার চার্জ করে। এটাই ডাবল-রাইট সমস্যা: বাইরের জগত পরিবর্তিত হয়েছে, কিন্তু আপনার ওয়ার্কফ্লো স্টেট হয়নি।
সবচেয়ে নিরাপদ প্যাটার্ন হলো প্রতিটি সাইড-ইফেক্টিং স্টেপের জন্য একটি স্থায়ী idempotency key তৈরি করা, সেটি বাইরের কলের সঙ্গে পাঠানো, এবং ফলাফল ফিরে পাওয়ার সঙ্গে সঙ্গেই স্টেপের ফলাফল সংরক্ষণ করা। অনেক পেমেন্ট প্রোভাইডার ও webhook রিসিভার idempotency কী সমর্থন করে (উদাহরণস্বরূপ, OrderID দ্বারা অর্ডার চার্জ করা)। যদি স্টেপটি পুনরাবৃত্তি হয়, প্রোভাইডার মূল ফলাফল ফিরিয়ে দেয় পরিবর্তে আবারি অ্যাকশন করা।
আপনার ওয়ার্কফ্লো ইঞ্জিনের মধ্যে, প্রতিটি স্টেপ রিপ্লে করা যেতে পারে ধরেই নিন। AppMaster-এ সেটি প্রায়ই মানে হবে স্টেপ আউটপুটগুলো আপনার ডাটাবেস মডেলে সেভ করা এবং একটি ইন্টিগ্রেশন আবার কল করার আগে Business Process-এ সেগুলো যাচাই করা। যদি "Send welcome email" এর জন্য ইতোমধ্যে একটি MessageID রেকর্ড আছে, একটি রিট্রাই সেই রেকর্ড ব্যবহার করে এগোবে।
একটি বাস্তবসম্মত ডুপ্লিকেট-সেফ পদ্ধতি:
ডুপ্লিকেট তখনও ঘটে, বিশেষ করে ইনবাউন্ড webhook বা যখন একজন ইউজার একই বাটন দুবার চাপেন। ইভেন্ট টাইপ অনুযায়ী নীতি নির্ধারণ করুন: একদম মিলের ডুপ্লিকেট (একই idempotency কী) উপেক্ষা করুন, সামঞ্জস্যপূর্ণ আপডেট মার্জ করুন (যেমন প্রোফাইল ফিল্ডে last-write-wins), অথবা অর্থ বা কমপ্লায়েন্স ঝুঁকি থাকলে পর্যালোচনার লক্ষ্যে ফ্ল্যাগ করুন।
ডেড-লেটার হলো একটি ওয়ার্কফ্লো আইটেম যা ব্যর্থ হয়েছে এবং সাধারণ পথ থেকে সরিয়ে রাখা হয়েছে যাতে এটি অন্যসবকে ব্লক না করে। এটি আপনি সচেতনভাবে রেখে দেন। লক্ষ্য হলো কি ঘটেছিল বোঝা সহজ করা, সিদ্ধান্ত নেওয়া যে এটি ঠিক করা যাবে কি না, এবং নিরাপদে পুনরায় প্রক্রিয়া করা।
সবচেয়ে বড় ভুল হলো শুধুমাত্র একটি ত্রুটি বার্তা সংরক্ষণ করা। যখন কেউ পরে ডেড-লেটার দেখে, তাদের কাছে সমস্যা পুনরুত্পাদন করার জন্য পর্যাপ্ত কন্টেক্সট থাকা উচিত, অনুমান না করে।
একটি ব্যবহারযোগ্য ডেড-লেটার এন্ট্রি ধারণ করে:
শ্রেণীবিভাগ ডেড-লেটারগুলোকে কার্যকর করে তোলে। একটি সংক্ষিপ্ত ক্যাটেগরি অপারেটরকে সঠিক পরবর্তী ধাপ বেছে নিতে সাহায্য করে। সাধারণ গ্রুপগুলো হল: permanent error (লজিক রুল, ভুল স্টেট), data issue (মিসিং ফিল্ড, খারাপ ফরম্যাট), dependency down (টাইমআউট, রেট লিমিট, আউটেজ), এবং auth/permission (মেয়াদোত্তীর্ণ টোকেন, প্রত্যাখ্যাত ক্রেডেনশিয়াল)।
পুনরায় প্রক্রিয়াকরণ নিয়ন্ত্রিত হওয়া উচিত। উদ্দেশ্য হলো পুনরাবৃত্ত ক্ষতি এড়ানো, যেমন দ্বিগুণ চার্জ করা বা ইমেইল স্প্যাম করা। কে রিট্রাই করতে পারবে, কখন রিট্রাই করা যাবে, কি পরিবর্তন করা যাবে (কিছু নির্দিষ্ট ফিল্ড সম্পাদনা, অনুপস্থিত ডকুমেন্ট সংযুক্ত করা, টোকেন রিফ্রেশ করা), এবং কি অচল থাকা উচিত (request ID এবং downstream idempotency কী) — এগুলো নির্ধারণ করুন।
ডেড-লেটার আইটেমগুলো স্থায়ী শনাক্তকারী দ্বারা সার্চযোগ্য করুন। যখন একজন অপারেটর "order 18422" টাইপ করে সঠিক স্টেপ, ইনপুট এবং প্রচেষ্টা ইতিহাস দেখতে পারে, fixes দ্রুত এবং সঙ্গত হবে।
AppMaster-এ এটি নির্মাণ করলে ডেড-লেটারকে প্রথম-শ্রেণীর ডেটাবেস মডেল হিসেবে বিবেচনা করুন এবং স্টেট, প্রচেষ্টা এবং শনাক্তকারী ফিল্ড হিসেবে সংরক্ষণ করুন। এভাবে আপনার অভ্যন্তরীণ ড্যাশবোর্ড প্রশ্ন, ফিল্টার এবং নিয়ন্ত্রিত রি-প্রসেস ট্রিগার করতে পারবে।
দীর্ঘ-চলমান ওয়ার্কফ্লো ধীর, বিভ্রান্তিকর ভাবে ব্যর্থ হতে পারে: একটি স্টেপ ইমেইল উত্তর অপেক্ষা করছে, একটি পেমেন্ট প্রোভাইডার টাইমআউট করছে, বা একটি webhook দ্বিগুণ এসেছে। যদি আপনি দেখতে না পান ওয়ার্কফ্লো עכשיו কি করছে, আপনি অনুমান করতে বাধ্য হবেন। ভালো দৃশ্যমানতা "ভাঙা" হওয়া থেকে একটি স্পষ্ট উত্তরে নিয়ে আসে: কোন ওয়ার্কফ্লো, কোন স্টেপ, কি স্টেট, এবং পরবর্তী কি করা উচিত।
প্রতি স্টেপ থেকে একই ছোট সেট ফিল্ড ইমিট করা শুরু করুন যাতে অপারেটর দ্রুত স্ক্যান করতে পারে:
এসব ফিল্ড সহজ কাউন্টারগুলোকে সমর্থন করে যা স্বাস্থ্যের রূপরেখা দেয়। দীর্ঘ-চলমান ওয়ার্কফ্লোর ক্ষেত্রে সংখ্যা গুরুত্বপূর্ণ—আপনি ট্রেন্ড খুঁজছেন: কাজ কিউ-তে জমা হচ্ছে, রিট্রাই বাড়ছে, বা অপেক্ষা যা শেষ হয় না।
স্টার্টেড, কমপ্লিটেড, ফেইলড, রিট্রাইং, এবং ওয়েইটিং সময়ের উপর ট্র্যাক করুন। একটি ছোট waiting সংখ্যা স্বাভাবিক হতে পারে (মানব অনুমোদন)। একটি বাড়তে থাকা waiting কাউন্ট সাধারণত বোঝায় কিছু আটকে গেছে। একটি বাড়তে থাকা retrying কাউন্ট প্রায়ই কোন প্রোভাইডার সমস্যা বা একই ত্রুটিতে বারবার আঘাত করা বাগের ইঙ্গিত দেয়।
অ্যালার্টগুলো অপারেটর অভিজ্ঞতার সাথে মিলিয়ে রাখুন। "ত্রুটি ঘটেছে" টাইপের অ্যালার্টের বদলে লক্ষণগুলোর উপর অ্যালার্ট দিন: বাড়তে থাকা ব্যাকলগ (started minus completed ক্রমাগত বাড়ছে), প্রত্যাশিত সময়ের চেয়ে বেশি সময় ধরে waiting-এ আটকে থাকা, একটি নির্দিষ্ট স্টেপের জন্য উচ্চ রিট্রাই রেট, অথবা রিলিজ/কনফিগ পরিবর্তনের পর ব্যর্থতার উত্থান।
প্রতি ওয়ার্কফ্লোর জন্য একটি ইভেন্ট ট্রেইল রাখুন যাতে "কি ঘটেছিল?" এক ভিউ-তে উত্তরযোগ্য হয়। একটি ব্যবহারযোগ্য ট্রেইলে থাকবে টাইমস্ট্যাম্প, স্টেট ট্রানজিশন, ইনপুট ও আউটপুট সারাংশ (সম্পূর্ণ সংবেদনশীল পে-লোড নয়), এবং রিট্রাই বা ব্যর্থতার কারণ। উদাহরণ: "Charge card: retry 3/5, timeout from provider, next attempt in 10m."
করেলেশন ID হচ্ছে গ্লু। যদি একজন কাস্টমার বলে "আমার পেমেন্ট দ্বিগুণ চার্জ হয়েছে", আপনাকে আপনার ওয়ার্কফ্লো ইভেন্টগুলো payment provider-এর চার্জ ID এবং আপনার অভ্যন্তরীণ order ID-এর সাথে জোড়া লাগাতে হবে। AppMaster-এ আপনি Business Process লজিকে করেলেশন ID জেনারেট ও পাস করে এটিকে স্ট্যান্ডার্ডাইজ করতে পারেন যাতে ড্যাশবোর্ড ও লোগ মিলেমিশে যায়।
যখন একটি ওয়ার্কফ্লো ঘণ্টা বা দিন ধরে চলে, ব্যর্থতা স্বাভাবিক। যা স্বাভাবিক ব্যর্থতাকে আউটেজে পরিণত করে তা হলো একটি ড্যাশবোর্ড যা কেবল "Failed" বলেই থেমে থাকে। লক্ষ্য হলো অপারেটরকে দ্রুত তিনটি প্রশ্নের উত্তর দিতে সাহায্য করা: কি হচ্ছে, কেন হচ্ছে, এবং তারা নিরাপদভাবে পরবর্তী কি করতে পারে।
একটি ওয়ার্কফ্লো তালিকায় শুরু করুন যা প্রয়োজনীয় কয়েকটি আইটেম খুঁজে বের করতে সহজ করে। ফিল্টারগুলো প্যানিক ও চ্যাট নয়েজ কমায় কারণ কেউই ভিউ দ্রুত সরু করে নিতে পারে।
উপকারী ফিল্টারগুলোর মধ্যে আছে স্টেট, আয়ু (শুরু সময় ও বর্তমান স্টেটে থাকা সময়), মালিক (টিম/কাস্টমার/দায়িত্বশীল অপারেটর), টাইপ (ওয়ার্কফ্লো নাম/ভারশন), এবং প্রাধ্যতাসূচক ক্ষেত্র যদি গ্রাহক-সম্মুখী ধাপ থাকে।
পরবর্তী, স্ট্যাটাসের পাশে "কেন" দেখান—লগে লুকিয়ে রাখার পরিবর্তে। একটি স্ট্যাটাস পিল তখনই সাহায্য করে যদি তা শেষ ত্রুটি বার্তা, একটি সংক্ষিপ্ত ত্রুটি ক্যাটেগরি, এবং সিস্টেম পরবর্তী কি করবে সেটা দেখায়। দুইটি ফিল্ড বেশিরভাগ কাজ করে: last error এবং next retry time। যদি next retry ফাঁকা থাকে, স্পষ্টভাবে দেখান ওয়ার্কফ্লো কি mennes-এর অপেক্ষায় আছে, পজ করা আছে, না স্থায়ীভাবে ব্যর্থ।
অপারেটর ক্রিয়াগুলো ডিফল্টভাবে নিরাপদ হওয়া উচিত। মানুষকে প্রথমে নিম্ন-ঝুঁকির পথে পরিচালিত করুন এবং ঝুঁকিপূর্ণ কাজগুলো স্পষ্ট করুন:
"Force continue"-এ বেশিরভাগ ক্ষতি ঘটে। যদি আপনি এটি অফার করেন, ঝুঁকি সরল ভাষায় লিখে দিন: "এটি payment verification স্কিপ করবে এবং unpaid order তৈরি করতে পারে।" আর দেখান কোন ডেটা লেখা হবে যদি এটি এগোয়।
অপারেটর যা করেন সবকিছু অডিট করুন। কে করল, কখন করল, আগে/পরের স্টেট, এবং কারণ নোট রেকর্ড করুন। AppMaster-এ অভ্যন্তরীণ টুল তৈরি করলে এই অডিট ট্রেইলকে একটি প্রথম-শ্রেণীর টেবিল হিসেবে সংরক্ষণ করুন এবং ওয়ার্কফ্লো ডিটেইল পেজে দেখান যাতে হ্যান্ডঅফগুলো পরিষ্কার থাকে।
এই প্যাটার্ন ওয়ার্কফ্লোগুলোকে predictable রাখে: প্রতিটি আইটেম সবসময় একটি স্পষ্ট স্টেট-এ থাকে, প্রতিটি ব্যর্থতার জন্য একটি জায়গা আছে, এবং অপারেটররা অনুমান না করেই কাজ করতে পারে।
Step 1: স্টেট এবং অনুমোদিত ট্রানজিশন নির্ধারণ করুন। একটি ছোট সেট লিখে রাখুন (উদাহরণ: Queued, Running, Waiting on external, Succeeded, Failed, Dead-letter) এবং কোন মুভ গুলো লিগ্যাল তা ঠিক করুন যাতে কাজ লিম্বোতে না পড়ে।
Step 2: কাজগুলোকে ছোট স্টেপে ভেঙে ফেলুন, স্পষ্ট ইনপুট ও আউটপুটসহ। প্রতিটি স্টেপ একটি সুস্পষ্ট ইনপুট নেবে এবং একটি আউটপুট (বা একটি পরিষ্কার ত্রুটি) উৎপন্ন করবে। যদি মানব সিদ্ধান্ত বা বাইরের API কল প্রয়োজন হয়, সেটি আলাদা স্টেপ করুন যাতে এটি থামতে ও পুনরায় শুরু করতে পারে।
Step 3: প্রতিটি স্টেপে একটি রিট্রাই পলিসি যোগ করুন। প্রচেষ্টার সীমা, চেষ্টা-মাঝে বিলম্ব, এবং কখন কখন আর রিট্রাই করা উচিত নয় (ভুল ডেটা, অনুমতি না থাকা, প্রয়োজনীয় ফিল্ড অনুপস্থিত) নির্ধারণ করুন। স্টেপ-প্রতি retry কাউন্টার সংরক্ষণ করুন যাতে অপারেটররা ঠিক জানতে পারে কি আটকে আছে।
Step 4: প্রতিটি স্টেপের পরে অগ্রগতি পারসিস্ট করুন। একটি স্টেপ শেষ হলে নতুন স্টেট এবং মূল আউটপুট সংরক্ষণ করুন। প্রসেস রিস্টার্ট হলে এটি শেষ সম্পন্ন স্টেপ থেকে চালিয়ে যাবে, পুনরায় শুরু করবে না।
Step 5: রিট্রাই শেষ হলে ডেড-লেটারে রুট করুন এবং পুনরায় প্রক্রিয়াকরণ সমর্থন করুন। যখন রিট্রাই শেষ হয়ে যায়, আইটেমটিকে ডেড-লেটার স্টেটে সরান এবং সম্পূর্ণ কন্টেক্সট রাখুন: ইনপুট, শেষ ত্রুটি, স্টেপ নাম, প্রচেষ্টা গণনা, এবং টাইমস্ট্যাম্প। পুনরায় প্রক্রিয়া করে সাবধানে করুন: আগে ডেটা বা কনফিগ ঠিক করুন, তারপর নির্দিষ্ট স্টেপ থেকে পুনরায় কিউ করুন।
Step 6: ড্যাশবোর্ড ফিল্ড ও অপারেটর অ্যাকশন নির্ধারণ করুন। একটি ভালো ড্যাশবোর্ডের উত্তর হবে "কি ব্যর্থ হয়েছে, কোথায়, এবং আমি পরবর্তী কি করতে পারি?" AppMaster-এ আপনি এটি ওয়ার্কফ্লো টেবিল দ্বারা ব্যাকডেড করে একটি সাধারণ অ্যাডমিন ওয়েব অ্যাপ হিসেবে তৈরি করতে পারেন।
শামিল করতে প্রয়োজনীয় কী ফিল্ড ও অ্যাকশন:
কর্মচারী অনবোর্ডিং ভাল টেস্ট: এটিতে অনুমোদন, বাহ্যিক সিস্টেম, এবং অফলাইন মানুষ মিশে থাকে। একটি সাধারণ ফ্লো হতে পারে: HR নতুন নিয়োগ ফর্ম জমা করে, ম্যানেজার অনুমোদন দেয়, IT অ্যাকাউন্ট তৈরি করে, এবং নতুন কর্মচারীকে স্বাগত বার্তা পাঠানো হয়।
স্টেটগুলো পড়তে সহজ করুন। যখন কেউ রেকর্ড খুলবে, তাদের তাত্ক্ষণিকভাবে বোঝা উচিত "Waiting for approval" এবং "Retrying account setup" এর মধ্যে পার্থক্য। এক লাইন স্পষ্টতা এক ঘন্টার অনুমানও বাঁচাতে পারে।
UI-তে দেখানোর জন্য একটি স্পষ্ট স্টেট সেট:
নেটওয়ার্ক বা তৃতীয়-পক্ষ API-র উপরে নির্ভরশীল ধাপগুলোতে রিট্রাই থাকা উচিত: অ্যাকাউন্ট provisioning (ইমেইল, SSO, Slack), ইমেইল/SMS পাঠানো, এবং অভ্যন্তরীন API কল সবই রিট্রাইয়ের প্রার্থী। রিট্রাই কাউন্টার দৃশ্যমান রাখুন এবং এটিকে ক্যাপ করুন (উদাহরণ: সর্বোচ্চ ৫ বার বাড়তে দাও, এবং দেরি বাড়াও), তারপর থামাও।
ডেড-লেটার হ্যান্ডলিং তাদের জন্য যেখানে সমস্যা নিজে ঠিক হবে না: ফর্মে কোনো ম্যানেজার নেই, ইমেইল ঠিকানা ভুল, বা অ্যাক্সেস অনুরোধ নীতির সঙ্গে সংঘর্ষ। যখন আপনি একটি রান ডেড-লেটার করবেন, কনটেক্সট সংরক্ষণ করুন: কোন ফিল্ড প্রমাণীকরণে ব্যর্থ হয়েছে, শেষ API রেসপন্স, এবং কে ওভাররাইড অনুমোদন দিতে পারে।
অপারেটরদের একটি ছোট সেট সরল অ্যাকশন থাকা উচিত: ডেটা ঠিক করা (ম্যানেজার যোগ করা, ইমেইল ঠিক করা), একটি ব্যর্থ ধাপ পুনরায় চালানো (পূর্ণ ওয়ার্কফ্লো নয়), বা পরিষ্কারভাবে ক্যানসেল করা (প্রয়োজনে আংশিক সেটআপ আনডো করা)।
AppMaster ব্যবহার করে আপনি এটি Business Process Editor-এ মডেল করতে পারেন, রিট্রাই কাউন্টার ডেটাতে রাখতে পারেন, এবং ওয়েব UI বিল্ডারে একটি অপারেটর স্ক্রীন তৈরি করতে পারেন যা স্টেট, শেষ ত্রুটি, এবং ব্যর্থ স্টেপ রিট্রাই করার বোতাম দেখায়।
অধিকাংশ নির্ভরযোগ্যতা সমস্যাই পূর্বানুমেয়: একটি ধাপ দু'বার চলে, রাত ২টায় রিট্রাই স্টর্ম, বা একটি "স্টাক" আইটেমে কি শেষ হয়েছে তা বোঝার কোন সূত্র নেই। একটি চেকলিস্ট এটিকে অনুমানভিত্তিক না হয়ে নিয়ন্ত্রিত রাখে।
সামান্য চেক যা বেশিরভাগ সমস্যা আগে ধরবে:
আপনি যদি একটিই জিনিস উন্নত করতে পারেন, দৃশ্যমানতা উন্নত করুন। বহু "ওয়ার্কফ্লো বাগ" আসলে "আমরা দেখতে পাই না এটা কি করছে" সমস্যা। আপনার ড্যাশবোর্ডে দেখা উচিত কি শেষ হলো, পরের কি হবে, এবং কখন।
একটি ব্যবহারিক অপারেটর ভিউতে থাকবে বর্তমান স্টেট, শেষ ত্রুটি বার্তা, প্রচেষ্টা গণনা, পরের রিট্রাই সময়, এবং একটি স্পষ্ট অ্যাকশন (এখন রিট্রাই করুন, চিহ্নিত হিসেবে সমাধান করুন, অথবা ম্যানুয়াল রিভিউ-এ পাঠান)। ডিফল্টভাবে অ্যাকশানগুলো নিরাপদ রাখুন: পুরো ওয়ার্কফ্লো নয়, একটি কেবল একটি স্টেপ পুনরায় চালান।
পরবর্তী ধাপ:
এটিকে একটি জীবন্ত চেকলিস্ট হিসেবে বিবেচনা করুন। প্রত্যেকবার আপনি একটি নতুন স্টেপ যোগ করলে, প্রোডাকশনে যাওয়ার আগে এই চেকগুলো চালান।
দীর্ঘ-চলমান ওয়ার্কফ্লো ঘণ্টাখানি বা দিনের মধ্যে সফলভাবে চলতে পারে এবং শেষে ব্যর্থ হয়ে আংশিক পরিবর্তন রেখে দিতে পারে। এগুলো চলাকালীন তৃতীয়-পক্ষের আপটাইম, ক্রেডেনশিয়াল, ডেটার কাঠামো এবং মানুষের প্রতিক্রিয়ার মতো পরিবর্তনশীল জিনিসগুলোর উপর নির্ভর করে।
স্টেট সেট ছোট ও পড়তে সহজ রাখুন যাতে অপারেটর এক নজরে বুঝতে পারে। একটি সাধারণ ডিফল্ট সেট হতে পারে: queued, running, waiting, succeeded, এবং failed। "Waiting"-কে স্পষ্টভাবে "running" থেকে আলাদা রাখুন যাতে স্বাস্থ্যবান বিরতি ও হ্যাঙ্গ আলাদা করা যায়।
স্ট্যাটাসকে কার্যকর করতে যথেষ্ট তথ্য সংরক্ষণ করুন: বর্তমান স্টেট, সর্বশেষ স্টেট পরিবর্তন সময়, পূর্বের স্টেট এবং অপেক্ষা বা ব্যর্থতার একটি সংক্ষিপ্ত কারণ। রিট্রাই থাকলে, একটি চেষ্টা গণনা ও পরের নির্ধারিত রিট্রাই সময়ও সংরক্ষণ করুন যাতে কেউ অটোমেটিকভাবে না অনুমান করে।
এটি ভুল অ্যালার্ম ও মিসড ইনসিডেন্ট প্রতিরোধ করে। “Waiting for approval” বা “waiting for a webhook” স্বাভাবিক হতে পারে, আর “running for six hours” সমস্যার ইঙ্গিত দিতে পারে—তাই আলাদা স্টেট থাকা জরুরি।
অস্থায়ী ত্রুটিগুলো রিট্রাই করুন—যেমন টাইমআউট, রেট লিমিট, সাময়িক আউটেজ। পরিষ্কারভাবে স্থায়ী ত্রুটিগুলো—যেমন ভুল ইনপুট, অনুপযুক্ত অনুমতি, বা declined payment—রিট্রাই করবেন না। বারবার চেষ্টা করলে সময় নষ্ট হয় এবং পাশাপাশিই দুষ্পরিণতিও ঘটতে পারে।
স্টেপ-স্তরের রিট্রাই একমাত্র সঠিক পদ্ধতি: একটি ফ্লয়ি ইন্টিগ্রেশন পুরো ওয়ার্কফ্লোর সবগুলো চেষ্টা খেয়ে ফেলবে না। এতে বুঝতেও সহজ হয় কোন স্টেপ ফেল হচ্ছে, কতবার চেষ্টা হয়েছে, এবং অন্য স্টেপগুলো কোন অবস্থায় আছে।
ঝুঁকি অনুযায়ী একটি সহজ ব্যাকঅফ নীতি নিন; অস্বীমিতভাবে অপেক্ষা বাড়বে না এমন একটি ক্যাপ রাখুন। স্টপ কন্ডিশন স্পষ্ট রাখুন—যেমন সর্বোচ্চ প্রচেষ্টা, সর্বোচ্চ মোট সময়, বা নির্দিষ্ট ত্রুটি কোডের জন্য তৎক্ষণাৎ ছেড়ে দেওয়া। ব্যর্থতার কারণ এবং পরের রিট্রাই কখন হবে তাও রেকর্ড করুন।
প্রতিটি সাইড-ইফেক্টিং স্টেপকে দ্বৈত-নিষ্পত্তির জন্য ডিজাইন করুন। একটি স্থায়ী idempotency key তৈরি করুন, "স্টেপ শুরু" রেকর্ড লেখার পরে বাইরের কল করুন এবং সফল হলে রেসপন্স সাথে সাথেই স্টোর করুন—এভাবে পুনরায় চালালে বহিষ্কৃত কার্যটি পুনরায় ঘটবে না।
ডেড-লেটার আইটেমটি তখনই তৈরি করা উচিত যখন রিট্রাই শেষ হয়ে যায় এবং অতি-প্রাথমিক পথ ব্লক না করেই সেটিকে আলাদা রাখা দরকার। ডেড-লেটার এন্ট্রিতে পর্যাপ্ত কনটেক্সট রাখুন: শনাক্তকারী, ইনপুট (বা একটি নিরাপদ স্ন্যাপশট), কোথায় ব্যর্থ হয়েছে, চেষ্টা-ইতিহাস, এবং নির্ভরশীল সার্ভিসের ত্রুটির উত্তর—শুধু একটি vagueness-মূলক বার্তা নয়।
দ্রুত ব্যবহারযোগ্য ড্যাশবোর্ডে থাকা উচিত: কোথায় আছে, কেন আছে, এবং পরবর্তী কি হবে—স্থির ফিল্ড যেমন ওয়ার্কফ্লো আইডি, বর্তমান স্টেপ, স্টেট, স্টেটে থাকা সময়, শেষ ত্রুটি, এবং করেলেশন আইডি। অপারেটররা সাধারণত নিরাপদ অ্যাকশন পাবে—যেমন এক স্টেপ রিট্রাই, পজ/রিজিউম—এবং ঝুঁকিপূর্ণ কাজ স্পষ্টভাবে লেবেল করা থাকবে।



বিনামূল্যের পরিকল্পনা সহ অ্যাপমাস্টারের সাথে পরীক্ষা করুন।
আপনি যখন প্রস্তুত হবেন তখন আপনি সঠিক সদস্যতা বেছে নিতে পারেন৷


