সরঞ্জাম রিজার্ভেশন অ্যাপ: সংঘাত ঠেকান এবং ফেরত ট্র্যাক করুন
এমন একটি সরঞ্জাম রিজার্ভেশন অ্যাপ পরিকল্পনা করুন যা ডাবল বুকিং বন্ধ করে, ফেরত ও ক্ষতির রেকর্ড রাখে এবং ত্রুটিপূর্ণ সরঞ্জামকে রক্ষণাবেক্ষণে আটকে দেয়।
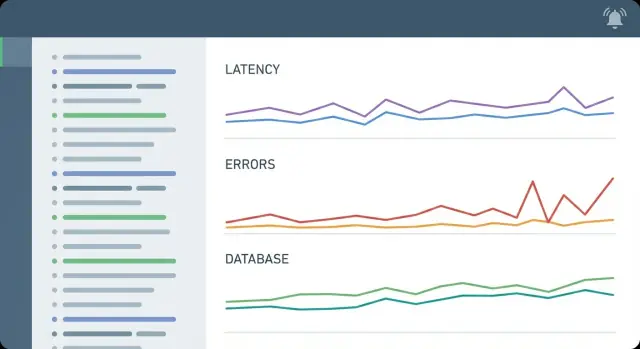
CRUD-ভিত্তিক ব্যাকএন্ডের জন্য ন্যূনতম অবজার্ভেবিলিটি: স্ট্রাকচারড লগ, মূল মেট্রিক্স, এবং বাস্তবসম্মত এলার্ট যাতে ধীর কুয়েরি, এরর এবং আউটেজ দ্রুত ধরা যায়।
CRUD-ভিত্তিক ব্যবসায়িক অ্যাপগুলো সাধারণত বিরক্তিকর, ব্যয়বহুল উপায়ে ফেল করে। একটি লিস্ট পেজ প্রতি সপ্তাহে ধীর হয়ে যায়, একটি সেভ বাটন মাঝে মাঝে টাইমআউট করে, এবং সাপোর্ট “র্যান্ডম 500s” রিপোর্ট করে যা আপনি পুনর্নির্মাণ করতে পারেন না। ডেভেলপমেন্টে কিছু ভাঙছে বলে মনে হয় না, কিন্তু প্রোডাকশন অনবিশ্বাস্য মনে হয়।
বাস্তব খরচ শুধু ইনসিডেন্ট নয়—এটা অনুমান করতে ব্যয় হওয়া সময়ও। স্পষ্ট সিগন্যাল না থাকলে টিমগুলো ঘোরে: “এটা নিশ্চয়ই ডাটাবেস,” “এটা নেটওয়ার্ক,” বা “এটা ঐ একটি এন্ডপয়েন্ট,” আর ব্যবহারকারীরা অপেক্ষা করে এবং বিশ্বাস কমে যায়।
অবজার্ভেবিলিটি সেই অনুমানগুলোকে উত্তরেই পরিণত করে। সহজভাবে: আপনি কি ঘটেছিল তা দেখে বুঝতে পারেন কেন ঘটেছে। সেটা অর্জন করা যায় তিন ধরনের সিগন্যাল দিয়ে:
CRUD অ্যাপ ও API সার্ভিসের জন্য এটি জটিল ড্যাশবোর্ডের চেয়ে দ্রুত ডায়াগনোসিসের ব্যাপার। যখন “Create invoice” কল ধীর হয়ে যায়, মিনিটের মধ্যে বলে দেওয়া উচিত বিলম্ব ডাটাবেস কুয়েরি থেকে এসেছে নাকি ডাউনস্ট্রিম API থেকে, অথবা ওভারলোডেড ওয়ার্কার থেকে।
একটা ন্যূনতম সেটআপ শুরু করার জন্য সেই প্রশ্নগুলো থেকে শুরু করুন যেগুলোর উত্তর একটি খারাপ দিনে আপনার দরকার:
যদি আপনি জেনারেটেড স্ট্যাক দিয়ে ব্যাকএন্ড তৈরি করেন (উদাহরণস্বরূপ, AppMaster থেকে Go সার্ভিস জেনারেট করা), একই নিয়ম প্রযোজ্য: ছোট থেকে শুরু করুন, সিগন্যাল কনসিস্টেন্ট রাখুন, এবং কোনো নতুন মেট্রিক বা এলার্ট যোগ করবেন কেবল তখনই যখন বাস্তব কোনো ইনসিডেন্ট প্রমাণ করে এটি সময় বাঁচাতো।
একটি ন্যূনতম অবজার্ভেবিলিটি সেটআপের তিনটি স্তম্ভ আছে: লগ, মেট্রিক্স, এবং এলার্টস। ট্রেসিং উপকারী, কিন্তু অধিকাংশ CRUD-ভিত্তিক ব্যবসায়িক অ্যাপের জন্য তা একটি বোনাস।
লক্ষ্য সরল: আপনি জানতে পারবেন (1) কবে ব্যবহারকারীরা ব্যর্থ হচ্ছে, (2) কেন তারা ব্যর্থ হচ্ছে, এবং (3) সিস্টেমের কোথায় এটা ঘটছে। যদি আপনি দ্রুত সেই উত্তরগুলো না পেতে পারেন, আপনি অনুমান করে সময় নষ্ট করবেন এবং কী পরিবর্তিত হয়েছে তা নিয়ে তর্ক করবেন।
সিগন্যালের সবচেয়ে ছোট সেট যা সাধারণত আপনাকে সেখানে নিয়ে যায়, সেটা এমনঃ
request_id, ব্যবহারকারী, এন্ডপয়েন্ট, এবং এরর দিয়ে সার্চ করতে পারেন।আরও একটি সহায়ক নিয়ম: লক্ষণ এবং কারণ আলাদা রাখুন। লক্ষণ হলো ব্যবহারকারী যা অনুভব করে: 500s, টাইমআউট, ধীর পেজ। কারণ হলো যা তা সৃষ্টি করে: লক কনটেনশন, স্যাচুরেটেড কানেকশন পুল, বা নতুন ফিল্টার যোগ করার পর ধীর কুয়েরি। লক্ষণে এলার্ট দিন এবং তদন্তে “কারণ” সিগন্যাল ব্যবহার করুন।
একটি ব্যবহারিক নিয়ম: গুরুত্বপূর্ণ সিগন্যাল দেখার জন্য একটি মাত্র জায়গা বাছুন। লোগ টুল, মেট্রিক টুল, এবং আলাদা এলার্ট ইনবক্সের মধ্যে কনটেক্সট-সুইচিং ইনসিডেন্টে আপনাকে ধীর করে দেয়।
কিছু ভেঙে পড়লে দ্রুত উত্তর পাওয়ার সবচেয়ে দ্রুত পথ সাধারণত: “এই ব্যবহারকারী কোন এক্স্যাক্ট রিকোয়েস্ট করেছিল?” এজন্যে একটি স্থিতিশীল কোরিলেশন ID প্রায় সব অন্য লগ টিউনের চেয়েও বেশি গুরুত্বপূর্ণ।
একটি ফিল্ড নাম বাছুন (সাধারণত request_id) এবং এটিকে বাধ্যতামূলক হিসেবে বিবেচনা করুন। এটিকে এজে (API গেটওয়ে বা প্রথম হ্যান্ডলার) জেনারেট করুন, অভ্যন্তরীণ কলগুলোর মাধ্যমে পাস করুন, এবং প্রতিটি লগ লাইনে অন্তর্ভুক্ত করুন। ব্যাকগ্রাউন্ড জবগুলোর জন্য, প্রতিটি জব রান-এ একটি নতুন request_id তৈরি করুন এবং যদি জবটি কোনো API কল দ্বারা ট্রিগার হয়ে থাকে তাহলে parent_request_id সংরক্ষণ করুন।
লগগুলো JSON-এ রাখুন, ফ্রি টেক্সট নয়। এতে লগ খোঁজার যোগ্য ও কনসিস্টেন্ট থাকে যখন আপনি ক্লান্ত, চাপাপ্রাপ্ত, এবং স্কিমিং করে পড়ছেন।
CRUD-ভিত্তিক API সার্ভিসের জন্য একটি সাধারণ ফিল্ড সেট বেশিরভাগ ক্ষেত্রে পর্যাপ্ত:
timestamp, level, service, envrequest_id, route, method, statusduration_ms, db_query_counttenant_id বা account_id (নিরাপদ শনাক্তকারী, ব্যক্তিগত ডেটা নয়)লগগুলো আপনাকে সংকুচিতভাবে বলতে সাহায্য করবে “কোন ক্লায়েন্ট এবং কোন স্ক্রিন,” কিন্তু তা ডেটা লিকে পরিণত করা উচিত নয়। ডিফল্টভাবে নাম, ইমেইল, ফোন নম্বর, ঠিকানা, টোকেন, বা পুরো রিকোয়েস্ট বডি লগ করা এড়িয়ে চলুন। যদি গভীরে ডিবাগ লাগলে, কেবল অন-ডিমান্ড এবং রিড্যাকশন সহ লগ করুন।
CRUD সিস্টেমে দুটি ফিল্ড দ্রুত মূল্য দান করে: duration_ms এবং db_query_count. এগুলো ধীর হ্যান্ডলার ও আকস্মিক N+1 প্যাটার্নগুলো ট্রেসিং যোগ করার আগেই ধরতে সাহায্য করে।
লেভেলগুলোর সংজ্ঞা করুন যাতে সবাই একইভাবে ব্যবহার করে:
info: প্রত্যাশিত ইভেন্ট (রিকোয়েস্ট সম্পন্ন, জব শুরু)warn: অস্বাভাবিক কিন্তু উদ্ধারযোগ্য (ধীর রিকোয়েস্ট, রিট্রাই সফল)error: ব্যর্থ রিকোয়েস্ট বা জব (একসেপশন, টাইমআউট, খারাপ ডিপেন্ডেন্সি)যদি আপনি AppMaster-এর মত প্ল্যাটফর্ম দিয়ে ব্যাকএন্ড তৈরি করেন, জেনারেটেড সার্ভিসগুলোর মধ্যে একই ফিল্ড নাম রাখুন যাতে “request_id দিয়ে সার্চ” সব জায়গায় কাজ করে।
CRUD-ভিত্তিক অ্যাপগুলোর বেশিরভাগ ইনসিডেন্টে একই ধাঁচ দেখা যায়: এক-দুই এন্ডপয়েন্ট ধীর হয়, ডাটাবেস স্ট্রেস পায়, এবং ব্যবহারকারীরা স্পিনার বা টাইমআউট দেখে। আপনার মেট্রিক্সগুলোকে কয়েক মিনিটের মধ্যে সেই গল্পটি স্পষ্ট করে দিতে হবে।
একটি ন্যূনতম সেট সাধারণত পাঁচটি ক্ষেত্র কভার করে:
দুটি বিশদ জিনিস মেট্রিক্সকে অনেক বেশি কার্যকর করে তোলে।
প্রথমত, ইন্টারেক্টিভ API রিকোয়েস্টগুলোকে ব্যাকগ্রাউন্ড কাজ থেকে আলাদা রাখুন। ধীর ইমেইল সেন্ডার বা webhook রিট্রাই লুপ CPU, DB কানেকশন, বা আউটগোয়িং নেটওয়ার্ককে স্টার্ভ করে API-কে “র্যান্ডমলি ধীর” করে তুলতে পারে। কিউ, রিট্রাই, এবং জব ডিউরেশনকে আলাদা টাইম সিরিজ হিসেবে ট্র্যাক করুন, যদিও তারা একই ব্যাকএন্ডে চলছে।
দ্বিতীয়ত, ড্যাশবোর্ড ও এলার্টসে সর্বদা ভার্সন/বিল্ড মেটাডেটা যোগ করুন। যখন আপনি একটি নতুন জেনারেটেড ব্যাকএন্ড ডিপ্লয় করবেন (উদাহরণস্বরূপ, AppMaster-এর মত নো-কোড টুল থেকে কোড রিজেনারেট করে), আপনি দ্রুত একটি প্রশ্নের উত্তর দিতে চাইবেন: কি রিলিজের পরে এরর রেট বা p95 ল্যাটেন্সি বৃদ্ধি পেয়েছে?
একটি সাধারণ নিয়ম: যদি কোনো মেট্রিক আপনাকে পরবর্তী কী করা উচিত তা বলে না (রোলব্যাক, স্কেল, কুয়েরি ফিক্স, অথবা জব বন্ধ), তবে এটা আপনার ন্যূনতম সেটে থাকা উচিত নয়।
CRUD-ভিত্তিক অ্যাপে ডাটাবেস প্রায়ই সেই জায়গা যেখানে “এটা ধীর লাগছে” বাস্তব ব্যবহারকারী ব্যথায় পরিণত হয়। একটি ন্যূনতম সেটআপ বোঝায় যখন বটলনেক PostgreSQL, নয় কি তা এবং কী ধরনের DB সমস্যা।
আপনাকে দরকার নেই অসংখ্য ড্যাশবোর্ড। শুরু করুন এমন সিগন্যাল দিয়ে যা বেশিরভাগ ইনসিডেন্ট ব্যাখ্যা করে:
API লেয়ারে একটি কুয়েরি টাইমিং হিস্টোগ্রাম যোগ করুন এবং এটিকে এন্ডপয়েন্ট বা ইউজ কেস দিয়ে ট্যাগ করুন (উদাহরণ: GET /customers, “search orders”, “update ticket status”)। এটা দেখায় একটি এন্ডপয়েন্ট কি অনেক ছোট কুয়েরি চালায় নাকি একটি বড় কুয়েরি চলাচ্ছে।
CRUD স্ক্রিনগুলো প্রায়ই N+1 কুয়েরি ট্রিগার করে: একটি লিস্ট কুয়েরি, তারপর প্রতিটি সারির জন্য সম্পর্কিত ডেটা আনতে আলাদা কুয়েরি। এমন এন্ডপয়েন্টগুলো দেখুন যেখানে রিকোয়েস্ট সংখ্যা সমান থাকে কিন্তু প্রতিটি রিকোয়েস্টে DB কুয়েরি সংখ্যা বাড়ছে। যদি আপনি মডেল ও বিজনেস লজিক থেকে ব্যাকএন্ড জেনারেট করেন, এখানেই সাধারণত ফেচ প্যাটার্ন টিউন করেন।
যদি আপনার কাছে ইতিমধ্যে ক্যাশ থাকে, হিট রেট ট্র্যাক করুন। ভালো চার্ট পেতে কেবলমাত্র ক্যাশ যোগ করবেন না।
স্কিমা পরিবর্তন ও মাইগ্রেশনকে ঝুঁকি উইন্ডো হিসেবে দেখুন। কখনো শুরু ও শেষ রেকর্ড করুন, তারপর ওই উইন্ডোর সময় লক, কুয়েরি সময়, এবং কানেকশন এরর স্পাইক দেখুন।
এলার্টগুলো একটি বাস্তব ব্যবহারকারী সমস্যাকে নির্দেশ করা উচিত, কোনো ব্যস্ত চার্ট নয়। CRUD-ভিত্তিক অ্যাপগুলোর জন্য, ব্যবহারকারী যা অনুভব করে তা মনিটর করা শুরু করুন: এরর ও ধীরতা।
শুরুতে আপনি যদি কেবল তিনটি এলার্ট যোগ করেন, সেগুলো করুনঃ
তারপর কিছু “সম্ভাব্য কারণ” এলার্ট যোগ করুন। CRUD ব্যাকএন্ডগুলো প্রিডিক্টেবল উপায়ে ব্যর্থ হয়: ডাটাবেস কানেকশন শেষ হয়ে যায়, ব্যাকগ্রাউন্ড কিউ জমে যায়, অথবা একটি একক এন্ডপয়েন্ট টাইমআউট হয়ে সামগ্রিক API-কে ধীর করে দেয়।
“p95 > 200ms” ধরনের হার্ডকোড সংখ্যা সাধারণত পরিবেশভেদে কাজ করে না। একটি স্বাভাবিক সপ্তাহ পরিমাপ করুন, তারপর এলার্টটিকে স্বাভাবিকের একটু উপরে একটি সেফটি মার্জিন দিয়ে সেট করুন। উদাহরণস্বরূপ, যদি প95 ল্যাটেন্সি সাধারণত ব্যবসায়িক সময়ে 350-450ms হয়, 700ms-এ 10 মিনিটের জন্য এলার্ট দিন। যদি 5xx সাধারণত 0.1-0.3% হয়, 2%-এ 5 মিনিটের জন্য পেজ করুন।
থ্রেশহোল্ডগুলো স্থিতিশীল রাখুন; প্রতিদিন সেগুলো টিউন করবেন না। একটি ইনসিডেন্টের পর টিউন করুন, যখন আপনি পরিবর্তনের সাথে বাস্তব আউটকাম যুক্ত করতে পারেন।
দুটি সেভারিটি ব্যবহার করুন যাতে মানুষ সিগন্যালকে বিশ্বাস করে:
ডিপ্লয় উইন্ডো ও পরিকল্পিত মেইনটেন্যান্সের সময় এলার্ট সাইলেন্স করুন।
এলার্টগুলোকে কর্মযোগ্য করে তুলুন। “প্রথমে কি চেক করবেন” (শীর্ষ এন্ডপয়েন্ট, DB কানেকশন, সাম্প্রতিক ডিপ্লয়) এবং “কি পরিবর্তিত হয়েছে” (নতুন রিলিজ, স্কিমা আপডেট) অন্তর্ভুক্ত করুন। যদি আপনি AppMaster ব্যবহার করেন, নোট করুন কোন ব্যাকএন্ড বা মডিউলটি সম্প্রতি রিজেনারেট এবং ডিপ্লয় করা হয়েছে—কারণ সেটাই প্রায়শই সবচেয়ে দ্রুত লিড দেয়।
একটি ন্যূনতম সেটআপ সহজ হয় যখন আপনি সিদ্ধান্ত নেন “ভালো পর্যাপ্ত” মানে কী। SLOs সেটাই করে: স্পষ্ট টার্গেট যা অস্পষ্ট মনিটরিংকে নির্দিষ্ট এলার্টে পরিণত করে।
শুরু করুন এমন SLIs থেকে যা ব্যবহারকারীর অনুভূতির সাথে মিল রাখে: অ্যাভিলেবিলিটি (ব্যবহারকারী রিকোয়েস্ট সম্পন্ন করতে পারে কি না), ল্যাটেন্সি (কত দ্রুত অ্যাকশন শেষ হয়), এবং এরর রেট (কত ঘন ঘন রিকোয়েস্ট ব্যর্থ হয়)।
এন্ডপয়েন্ট গ্রুপ প্রতি SLO সেট করুন, রুট প্রতি নয়। CRUD-ভিত্তিক অ্যাপের জন্য গ্রুপ করলে পড়তে সুবিধা হয়: রিডস (GET/list/search), রাইটস (create/update/delete), এবং অথ (login/token refresh)। এতে শত শত ছোট SLO এড়ানো যায় যেগুলো কেউ রক্ষণাবেক্ষণ করে না।
টিপিক্যাল উদাহরণ SLOs:
এরর বাজেট হলো SLO-র ভেতরের অনুমোদিত “খারাপ সময়”। মাসিক 99.9% অ্যাভিলেবিলিটি SLO মানে প্রায় 43 মিনিট ডাউনটাইম মাসে অনুমোদিত। যদি সেটা আগেভাগে খরচ হয়ে যায়, ঝুঁকিপূর্ণ পরিবর্তনগুলো স্থগিত করুন যতক্ষণ না স্থিতিশীলতা ফিরে আসে।
SLOs ব্যবহার করুন সিদ্ধান্ত নেবার জন্য কি এলার্ট পাবেন বনাম কি কেবল ড্যাশবোর্ড ট্রেন্ড। যখন আপনি এরর বাজেট দ্রুত পোড়াচ্ছেন তখন এলার্ট দিন (ব্যবহারকারীরা সক্রিয়ভাবে ব্যর্থ হচ্ছে), কেবলমাত্র metric কিছুটা খারাপ হলে না।
যদি আপনি দ্রুত ব্যাকএন্ড তৈরি করেন (উদাহরণ: AppMaster থেকে Go সার্ভিস জেনারেট করা), SLOs ব্যবহার করে ব্যবহারকারী প্রভাব উপর ফোকাস রাখুন এমনকি যখন ইমপ্লিমেন্টেশন পরিবর্তিত হচ্ছে।
ব্যবহারকারীরা সবচেয়ে বেশি যেটি স্পর্শ করে সেই সিস্টেমের অংশ দিয়ে শুরু করুন। টপ API কলগুলো ও জবগুলো বাছুন যেগুলো ধীর বা ভাঙলে পুরো অ্যাপই ডাউন মনে হবে।
আপনার টপ এন্ডপয়েন্ট ও ব্যাকগ্রাউন্ড কাজগুলো লিখে নিন। CRUD ব্যবসায়িক অ্যাপের জন্য সাধারণত সেটা হলো লগইন, লিস্ট/search, create/update, এবং এক বা দুটো এক্সপোর্ট/ইম্পোর্ট জব। যদি আপনি AppMaster দিয়ে ব্যাকএন্ড বানিয়েছেন, আপনার জেনারেটেড এন্ডপয়েন্ট এবং যে কোনো Business Process ফ্লো যা শিডিউলে বা webhook-এ চলে সেগুলো অন্তর্ভুক্ত করুন।
request_id, user_id (যদি থাকে), endpoint, status_code, latency_ms, db_time_ms, এবং একটি ছোট error_code পরিচিত ব্যর্থতাগুলোর জন্য।এলার্টগুলো Few and focused রাখুন। আপনি এমন এলার্ট চান যা ব্যবহারকারীর প্রভাব দেখায়, “কাউকে কিছু পরিবর্তিত হয়েছে” না।
একটি শক্তিশালী শুরু সেট: API p95 ল্যাটেন্সি অত্যাধিক, স্থায়ী 5xx রেট, 4xx-এ হঠাৎ স্পাইক (সাধারণত অথ বা ভ্যালিডেশন পরিবর্তন), ব্যাকগ্রাউন্ড জব ব্যর্থতা, DB ধীর কুয়েরি, DB কানেকশন প্রায় লিমিট, এবং নীচু ডিস্ক স্পেস (যদি self-hosted)।
তারপর প্রতিটি এলার্টের জন্য একটি ছোট রানবুক লিখুন। এক পৃষ্ঠা যথেষ্ট: প্রথমে কি চেক করবেন (ড্যাশবোর্ড প্যানেল ও কী লগ ফিল্ড), সম্ভাব্য কারণ (DB লক, অনুপযুক্ত ইনডেক্স, অনুকরণ ডাউনস্ট্রিম), এবং প্রথম নিরাপদ কাজ (জব রিস্টার্ট, চেঞ্জ রোলব্যাক, ভারী জব পজ করা)।
নূনতম অবজার্ভেবিলিটি সেটআপকে অপচয় করার দ্রুত পথ হলো মনিটরিংকে একটি চেকবক্স হিসেবে বিবেচনা করা। CRUD-ভিত্তিক অ্যাপগুলো সাধারণত কয়েকটি পূর্বানুমানযোগ্য উপায়ে ব্যর্থ হয় (ধীর DB কল, টাইমআউট, খারাপ রিলিজ), তাই আপনার সিগন্যালগুলো ঐ বিষয়গুলিতেই ফোকাসেড রাখুন।
সবচেয়ে সাধারণ ব্যর্থতা হলো এলার্ট ফ্যাটিগ: অতিরিক্ত এলার্ট, অল্প অ্যাকশন। আপনি যদি প্রতিটি स्पাইক-এ পেজ দেন, মানুষ দ্বিতীয় সপ্তাহের মধ্যে এলার্ট বিশ্বাস করা বন্ধ করে দেয়। একটি ভাল নিয়ম: একটি এলার্ট সম্ভবত একটি সম্ভাব্য ফিক্স নির্দেশ করা উচিত, কেবল “কিছু পরিবর্তিত” না।
আরেকটি ক্লাসিক ভুল হলো কোরিলেশন ID বাদ দেওয়া। যদি আপনি একটি এরর লগ, একটি ধীর রিকোয়েস্ট, এবং একটি DB কুয়েরি এক রিকোয়েস্টের সাথে ট্যাগ করতে না পারেন, আপনি ঘন্টা নষ্ট করবেন। নিশ্চিত করুন প্রতিটি রিকোয়েস্ট request_id পায় (এবং এটি লগ, ট্রেসে যদি থাকে, এবং নিরাপদ হলে রেসপন্সেও)।
শোরগোলপূর্ণ সিস্টেমগুলো সাধারণত একই সমস্যাগুলো শেয়ার করে:
CRUD অ্যাপগুলো বিশেষভাবে "গড়ের ফাঁদ"-এর প্রতি সংবেদনশীল। একটি একক ধীর কুয়েরি 5% অনুরোধকে কষ্টদায়ক করে তুলতে পারে যখন গড় ঠিক থাকে। টেইল ল্যাটেন্সি প্লাস এরর রেট একটি পরিষ্কার চিত্র দেয়।
ডিপ্লয় মার্কার যোগ করুন। আপনি CI থেকে শিপ করুন বা AppMaster-এর মত প্ল্যাটফর্ম থেকে কোড জেনারেট করুন—ভার্সন ও ডিপ্লয় সময় ইভেন্ট হিসেবে এবং লগেও রেকর্ড করুন।
আপনার সেটআপ কাজ করছে যখন আপনি দ্রুত কয়েকটি প্রশ্নের উত্তর পেতে পারেন, ড্যাশবোর্ড খুঁটিয়ে দেখতে 20 মিনিট ব্যয় না করে। যদি আপনি তাত্ক্ষণিকভাবে “হ্যাঁ/না” না পেতে পারেন, আপনি একটি মূল সিগন্যাল মিস করছেন বা আপনার ভিউগুলো খুব বিভক্ত।
আপনার অধিকাংশ কাজ এক মিনিটের মধ্যে করা উচিত:
handler time, DB query time, বাহ্যিক কল)?লগগুলো একই সাথে নিরাপদ ও কার্যকর হওয়া উচিত। একটা ব্যর্থ রিকোয়েস্ট এক সার্ভিস থেকে অন্য সার্ভিস পর্যন্ত অনুসরণ করার জন্য পর্যাপ্ত প্রসঙ্গ থাকা দরকার, কিন্তু ব্যক্তিগত ডেটা লিক না হওয়াই জরুরি।
একটি সাম্প্রতিক ব্যর্থতা বাছুন এবং তার লগ খুলুন। নিশ্চিত করুন আপনার কাছে আছে request_id, এন্ডপয়েন্ট, স্ট্যাটাস কোড, ডিউরেশন, এবং একটি পরিষ্কার এরর মেসেজ। এছাড়াও নিশ্চিত করুন আপনি কাঁচা টোকেন, পাসওয়ার্ড, সম্পূর্ণ পেমেন্ট ডিটেইল, বা ব্যক্তিগত ফিল্ড লগ করছেন না।
আপনি যদি CRUD-ভিত্তিক ব্যাকএন্ড AppMaster দিয়ে তৈরি করেন, একটি একক “ইনসিডেন্ট ভিউ” লক্ষ্য করুন যা এই চেকগুলো মিলায়: এরর, এন্ডপয়েন্ট অনুযায়ী p95 ল্যাটেন্সি, এবং DB হেলথ। সেটাই বেশি বাস্তব ইনসিডেন্ট কভার করে।
একটি ইন্টার্নাল অ্যাডমিন পোর্টাল সকালে ঠিক ছিল, তারপর ব্যস্ত সময়ে খুব ধীর হয়ে যায়। ব্যবহারকারীরা অভিযোগ করে “Orders” লিস্ট খোলা ও এডিট সেভ করা 10-20 সেকেন্ড নিচ্ছে।
আপনি টপ-লেভেল সিগন্যাল দিয়ে শুরু করেন। API ড্যাশবোর্ড দেখায় রিড এন্ডপয়েন্টগুলোর p95 ল্যাটেন্সি প্রায় 300 ms থেকে 4-6 s-এ লাফিয়েছে, অথচ এরর রেট কমই আছে। একই সময়ে ডাটাবেস প্যানেল দেখায় একটিভ কানেকশন পুল লিমিটের কাছে এবং লক ওয়েট বাড়ছে। ব্যাকএন্ড নোডগুলোর CPU স্বাভাবিক, তাই এটা কণ্ঠকাঠিন্য সমস্যা নয়।
এরপর আপনি একটি ধীর রিকোয়েস্ট বাছেন এবং লগে তার পথে অনুসরণ করেন। GET /orders দিয়ে ফিল্টার করে ডিউরেশন অনুযায়ী সাজান। 6-সেকেন্ড রিকোয়েস্ট থেকে একটি request_id নিয়ে সার্ভিস জুড়ে সার্চ করুন। আপনি দেখেন হ্যান্ডলার দ্রুত শেষ করেছে, কিন্তু ঐ একই request_id-এর মধ্যে DB কুয়েরি লগ লাইনটি 5.4 সেকেন্ড দেখাচ্ছে, rows=50 এবং বড় lock_wait_ms সহ।
এবার আপনি নিশ্চিতভাবে কারণ বলতে পারেন: ধীরতা ডাটাবেস পাথে (ধীর কুয়েরি বা লক কনটেনশন) আছে, নেটওয়ার্ক বা ব্যাকএন্ড CPU নয়। এটা একটি ন্যূনতম সেটআপ আপনাকে দেয়: অনুসন্ধান দ্রুত সংকুচিত করা।
প্রথাগত ফিক্স গুলো, সুরক্ষার দিক থেকে অল্প ঝুঁকিযুক্ত থেকে বেশি ঝুঁকিযুক্তঃ
ফিডব্যাক ক্লোজ করুন একটি লক্ষ্যমাত্রিক এলার্ট দিয়ে। কেবল তখনই পেজ করুন যখন একটি এন্ডপয়েন্ট গ্রুপের p95 ল্যাটেন্সি আপনার থ্রেশহোল্ডের উপরে 10 মিনিট ধরে থাকে এবং DB কানেকশন ইউসেজ প্রায় (উদাহরণস্বরূপ) 80%। ওই সংমিশ্রণ নয়েজ এড়ায় এবং পরবর্তীতে দ্রুত ধরবে।
একটি ন্যূনতম অবজার্ভেবিলিটি সেটআপ প্রথম দিনে বিরক্তিকর লাগা উচিত। যদি আপনি শুরুতেই অনেক ড্যাশবোর্ড ও এলার্ট বানান, আপনি সেগুলো সারাজীবন টিউন করবেন এবং তবুও সত্যিকারের বিষয় মিস করবেন।
প্রতিটি ইনসিডেন্টকে ফিডব্যাক হিসেবে নিন। ফিক্স শিপ হওয়ার পরে জিজ্ঞাসা করুন: কি থাকলে এটা দ্রুত খুঁজে পাওয়া যেত এবং সহজে ডায়াগনোসিস হত? কেবল সেইটুকুই যোগ করুন।
শুরুতেই স্ট্যান্ডার্ডাইজ করুন, এমনকি যদি আজকে কেবল একটা সার্ভিস থাকে। একই ফিল্ড নাম লগে এবং একই মেট্রিক নাম প্রত্যেক জায়গায় ব্যবহার করুন যাতে নতুন সার্ভিসগুলো বিতর্ক ছাড়াই প্যাটার্ন মেনে চলে। এভাবে ড্যাশবোর্ড পুনরায় ব্যবহারযোগ্য হয়।
একটি ছোট রিলিজ শৃঙ্খলা দ্রুত ফল দেয়:
আপনি যদি AppMaster দিয়ে ব্যাকএন্ড বানান, তবে observability ফিল্ড ও কোর মেট্রিক আগে থেকে প্ল্যান করা সুবিধা দেয় যাতে প্রতিটি নতুন API কনসিস্টেন্ট স্ট্রাকচারড লগ এবং হেলথ সিগন্যাল নিয়ে শিপ করে। যদি আপনি একটি শুরু করার জায়গা চান, AppMaster (appmaster.io) এমনভাবে ডিজাইন করা হয়েছে যাতে এটি প্রোডাকশন-রেডি ব্যাকএন্ড, ওয়েব, এবং মোবাইল অ্যাপ জেনারেট করে এবং ইমপ্লিমেন্টেশন পরিবর্তন হলে কনসিস্টেন্সি বজায় রাখে।
একটি সময়ে একটি উন্নতি বাছুন, বাস্তবে যা কষ্ট দিয়েছে তার উপরে ভিত্তি করে:
প্রতি বাস্তব ইনসিডেন্টের পরে সেই চক্রটি পুনরাবৃত্তি করুন। কয়েক সপ্তাহে আপনার কাছে এমন মনিটরিং হবে যা আপনার CRUD অ্যাপ এবং API ট্রাফিকের সাথে মানানসই, একটি জেনেরিক টেমপ্লেট নয়।
প্রোডাকশনে সমস্যা ব্যাখ্যা করতে যেখানে সময় লাগে তার চেয়ে সমস্যাটি ঠিক করতে সময় কম লাগে—এসবক্ষেত্রে observability যোগ করা শুরু করুন। যদি আপনি “র্যান্ডম 500s,” ধীর লিস্ট পেজ, বা রিক্রিয়েট করতে না পারা টাইমআউট দেখেন, একটি ছোট সেট কনসিস্টেন্ট লগ, মেট্রিক্স, এবং এলার্টস ঘণ্টার উপর ঘণ্টা ভাঙচুর করা সময় বাঁচাবে।
মনিটরিং আপনাকে বলে দেয় কি ভুল হয়েছে; অবজার্ভেবিলিটি আপনাকে বোঝায় কেন সেটা হলো — প্রাসঙ্গিক কনটেক্সট-সমৃদ্ধ সিগন্যাল ব্যবহার করে যেগুলো আপনি সম্পর্কিত করতে পারবেন। CRUD API-গুলির বাস্তব লক্ষ্য হল দ্রুত ডায়াগনোসিস: কোন এন্ডপয়েন্ট, কোন ব্যবহারকারী/টেন্যান্ট, এবং সময়টা অ্যাপে না ডাটাবেসে কেটে গেছে কিনা।
সিউক্তি করে বললে: স্ট্রাকচারড রিকোয়েস্ট লগ, কয়েকটি কোর মেট্রিক্স, এবং কিছু ইউজার-ইমপ্যাক্ট এলার্ট দিয়ে শুরু করুন। ট্রেসিং অনেক CRUD অ্যাপের জন্য অপেক্ষা করতে পারে যদি আপনার কাছে ইতিমধ্যে duration_ms, db_time_ms (বা সমতুল্য) এবং খুঁজে পাওয়া যায় এমন একটি স্থিতিশীল request_id থাকে।
একটি একক কোরিলেশন ফিল্ড যেমন request_id ব্যবহার করুন এবং তা প্রতিটি রিকোয়েস্ট লগ লাইনে এবং প্রতিটি ব্যাকগ্রাউন্ড জব রান-এ অন্তর্ভুক্ত করুন। এটিকে edge-এ জেনারেট করুন, অভ্যন্তরীণ কলগুলোর মাধ্যমে পাঠান, এবং নিশ্চিত করুন ওই ID দিয়েই লগ সার্চ করে একটি ব্যর্থ বা ধীর রিকোয়েস্ট দ্রুত পুনর্গঠন করা যায়।
স্ট্রাকচারড লগে অন্তর্ভুক্ত করুন: timestamp, level, service, env, route, method, status, duration_ms, এবং নিরাপদ শনাক্তকারী যেমন tenant_id বা account_id। ডিফল্টভাবে ব্যক্তিগত ডেটা, টোকেন এবং পুরো রিকোয়েস্ট বডি লগ করা থেকে বিরত থাকুন; যদি গভীরে যেতে হয়, তা শুধু নির্দিষ্ট ত্রুটির জন্য রিড্যাকশন দিয়ে করুন।
রিকোয়েস্ট রেট, 5xx রেট, ল্যাটেন্সি পার্সেন্টাইল (কমপক্ষে p50 এবং p95), এবং বেসিক স্যাচুরেশন (CPU/memory এবং কোনো ওয়ার্কার বা কিউ প্রেসার)। ডাটাবেস সময় এবং কানেকশন পুল ইউসেজ শুধু শুরুতেই যোগ করুন, কারণ অনেক CRUD আউটেজ আসলে ডাটাবেস কনটেনশন বা পুল এক্সহস্টশনের কারণে হয়।
কারণ এরা ব্যবহারকারীরা আসলে অনুভব করে এমন স্লো টেইলকে লুকিয়ে রাখে। অ্যাভারেজগুলি ঠিক থাকা সত্ত্বেও p95 বা p99 অনেক অনুরোধের জন্য ভয়ানক হতে পারে—এটা ঠিক সেই অনুভূতি যা CRUD স্ক্রিনগুলোকে “র্যান্ডমলি ধীর” বানায়।
ক্রমাবলীর পর্যবেক্ষণ করুন: ধীর কুয়েরির হার ও p95/p99 কুয়েরি সময় (সাথে শীর্ষ ধীর কুয়েরিগুলো), লক ওয়েট ও ডেডলক, কানেকশন ইউসেজ (এক্টিভ কানেকশন বনাম পুল লিমিট), এবং ডিস্ক/আইও চাপ। এগুলো বলতে সাহায্য করে ডাটাবেস কি বোতলনেক নাকি কোয়েরি পারফরম্যান্স/কনটেনশন সমস্যা।
প্রথমত ব্যবহারকারী-লক্ষণে ভিত্তি করে এলার্ট দিন: দীর্ঘস্থায়ী 5xx রেট, পুসিত p95 ল্যাটেন্সি, অথবা সফল রিকোয়েস্টে হঠাৎ পতন। তারপরে “সম্ভাব্য কারণ” এলার্ট যোগ করুন (যেমন DB কানেকশন প্রায় লিমিটে, জব ব্যাকলগ বৃদ্ধি) যাতে অন কল সিগন্যাল বিশ্বাসযোগ্য ও কর্মযোগ্য থাকে।
লগ, ড্যাশবোর্ড, এবং এলার্টে ভার্সন/বিল্ড মেটাডেটা লাগান এবং ডিপ্লয় মার্কার রেকর্ড করুন যাতে আপনি জানেন কখন চেঞ্জ শিপ হয়েছে। জেনারেটেড ব্যাকএন্ড (যেমন AppMaster-জেনারেটেড Go সার্ভিস) এর ক্ষেত্রে এটা বিশেষভাবে জরুরি, কারণ কোড রিজেনারেশন ও রিডিপ্লয় প্রায়ই হয় এবং আপনাকে দ্রুত যাচাই করতে হবে রিগ্রেশনটি রিলিজের পরে কি শুরু হয়েছে কিনা।



বিনামূল্যের পরিকল্পনা সহ অ্যাপমাস্টারের সাথে পরীক্ষা করুন।
আপনি যখন প্রস্তুত হবেন তখন আপনি সঠিক সদস্যতা বেছে নিতে পারেন৷


