সরঞ্জাম রিজার্ভেশন অ্যাপ: সংঘাত ঠেকান এবং ফেরত ট্র্যাক করুন
এমন একটি সরঞ্জাম রিজার্ভেশন অ্যাপ পরিকল্পনা করুন যা ডাবল বুকিং বন্ধ করে, ফেরত ও ক্ষতির রেকর্ড রাখে এবং ত্রুটিপূর্ণ সরঞ্জামকে রক্ষণাবেক্ষণে আটকে দেয়।
অ্যাডমিন প্যানেলের ইনডেক্সিং: ব্যবহারকারীরা সবচেয়ে বেশি যে ফিল্টারগুলো ক্লিক করে সেগুলোকে অগ্রাধিকার দিন—স্ট্যাটাস, অ্যাসাইনি, তারিখ রেঞ্জ এবং টেক্সট সার্চ—বাস্তব কুয়েরি প্যাটার্নের উপর ভিত্তি করে।
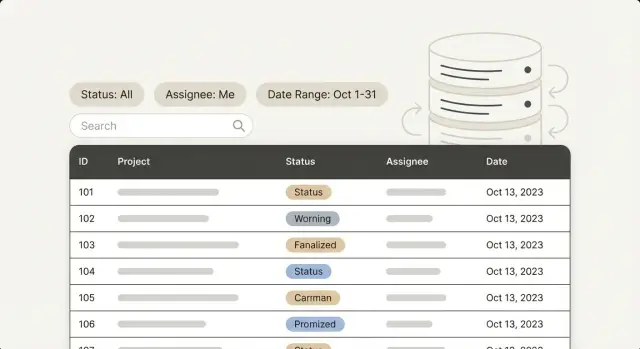
অ্যাডমিন প্যানেল সাধারণত শুরুতে দ্রুত মনে হয়। আপনি একটি লিস্ট খুলেন, স্ক্রল করেন, একটি রেকর্ড ক্লিক করেন, এবং এগিয়ে যান। ধীরগতি দেখা দেয় যখন মানুষ আসলে কাজ করার মতো ফিল্টার ব্যবহার করে: "শুধু ওপেন টিকিট", "Maya-কে অ্যাসাইন করা", "গত সপ্তাহে তৈরি", "অর্ডার আইডিতে 1047 আছে"। প্রতি ক্লিকে অপেক্ষা লাগে, এবং তালিকা আটকে থাকে বলে মনে হয়।
একই টেবিল একটি ফিল্টারের জন্য দ্রুত হতে পারে এবং অন্যটির জন্য যন্ত্রণাদায়কভাবে ধীর। একটি স্ট্যাটাস ফিল্টার হয়তো কিছুমাত্রার রো স্পর্শ করে দ্রুত ফিরিয়ে দেয়। আর একটা "দুই তারিখের মধ্যে তৈরি" ফিল্টার ডাটাবেসকে বিশাল রেঞ্জ পড়তে বাধ্য করতে পারে। অ্যাসাইনির ফিল্টার একা ঠিক থাকতে পারে, তারপর স্ট্যাটাস এবং সোর্টিংয়ের সঙ্গে মিলালে ধীরে যেতে পারে।
ইনডেক্স হল ডাটাবেস যে শর্টকাট ব্যবহার করে মিল থাকা রো খুঁজে বের করার জন্য যাতে পুরো টেবিল পড়তে না হয়। কিন্তু ইনডেক্স ফ্রি নয়। এগুলো স্থান নেয়, এবং ইনসার্ট ও আপডেট একটু ধীর করে। অতিরিক্ত ইনডেক্স যোগ করলে রাইটগুলো ধীর হতে পারে এবং আসল বাধাটি না সারেও যেতে পারে।
সবকিছু ইনডেক্স করার বদলে, তাদের অগ্রাধিকার দিন যেগুলো:\n
অ্যাডমিন প্যানেলগুলো সাধারণত একটি বিশাল রিপোর্টের কারণে ধীর হয় না। এগুলো ধীর হয় কারণ কয়েকটি স্ক্রিন সারাদিন ব্যবহার হয়, এবং সেই স্ক্রিনগুলো বারবার অনেক ছোট কুয়েরি চালায়।
Ops দল সাধারণত কয়েকটি ওয়ার্ক কিউয়েই থাকে: টিকিট, অর্ডার, ইউজার, অনুমোদন, অভ্যন্তরীণ অনুরোধ। এই পেইজগুলোতে ফিল্টারগুলো পুনরাবৃত্তি হয়:\n
অ্যাডমিন প্যানেলগুলোও ফিল্টারগুলো পূর্বানুমানযোগ্যভাবে মিলায়: "Open + Unassigned", "Pending + Assigned to me", বা "Completed in the last 30 days"। ইনডেক্স সবচেয়ে ভালো কাজ করে যখন তা বাস্তব কুয়েরি শেইপগুলোর সাথে মেলে, কেবল কলামের তালিকার সাথে নয়।
আপনি যদি AppMaster-এ অ্যাডমিন টুল বানান, এই প্যাটার্নগুলো সাধারণত সবচেয়ে বেশি ব্যবহৃত লিস্ট স্ক্রিন এবং তাদের ডিফল্ট ফিল্টার দেখে সহজেই দৃশ্যমান হয়। এতে আপনি যা বাস্তবে দৈনন্দিন কাজ চালায় তার উপর ভিত্তি করে ইনডেক্স করতে পারেন, কাগজে ভালো দেখানোর জন্য নয়।
ইনডেক্সিংকে ট্রাজির মতো বিবেচনা করুন। প্রতিটি ফিল্টার ড্রপডাউনে থাকা প্রতিটি কলাম ইনডেক্স করা শুরু করবেন না। প্রথমে সেগুলো বেছে নিন যেগুলো বারবার রান করে এবং মানুষের সবচেয়ে বেশি বিরক্ত করে।
যে ফিল্টার কেউ ব্যবহারই করে না তাকে অপ্টিমাইজ করা সময় নষ্ট। আসল হট-পাথগুলো খুঁজতে সংকেতগুলো মিলিয়ে দেখুন:\n
ইনডেক্স যোগ করার আগে, আপনার সাধারণ কুয়েরিগুলো তাদের আচরণ অনুযায়ী গ্রুপ করুন। বেশিরভাগ অ্যাডমিন লিস্ট কুয়েরি কয়েকটি বালতিতে পড়ে:\n
status = 'open', assignee_id = 42\n- Range filters: created_at দুই তারিখের মধ্যে\n- Sorting and pagination: ORDER BY created_at DESC এবং পেজ 2 ফেচ করা\n- Text lookups: exact match (order number), prefix match (email starts with), বা contains search\n
প্রতিটি শীর্ষ স্ক্রিনের শেইপ লিখে রাখুন, WHERE, ORDER BY, এবং pagination সহ। একই UI-র দুটি কুয়েরি ডাটাবেসে খুব ভিন্ন আচরণ করতে পারে।একটি প্রায়োরিটি টার্গেট দিয়ে শুরু করুন: ডিফল্ট লিস্ট কুয়েরি যা প্রথমে লোড হয়। তারপর 2–3টি বেশি-ফ্রিকোয়েন্সি কুয়েরি নিন। সাধারণত এটুকুই সবচেয়ে বড় বিলম্ব কমাতে যথেষ্ট হয়, ডাটাবেসকে ইনডেক্স মিউজিয়ামে রূপান্তর না করে।
উদাহরণ: একটি সাপোর্ট দল টিকিট লিস্ট খুলে যেখানে ফিল্টার status = 'open', newest অনুযায়ী সর্ট করা, অপশনাল অ্যাসাইনি ও তারিখ রেঞ্জ। প্রথমে সেই সঠিক কম্বিনেশন অপ্টিমাইজ করুন। একবার তা দ্রুত হলে, ব্যবহার অনুযায়ী পরবর্তী স্ক্রিনে এগোন।
স্ট্যাটাস হল প্রথমগুলোর মধ্যে একটি যা মানুষ যোগ করে, এবং এটি এমনভাবে ইনডেক্স করা সহজ যে বেশিরভাগ সময় সাহায্য করে না।
অধিকাংশ স্ট্যাটাস ফিল্ড কম-কার্ডিনালিটি হয়: মাত্র কয়েকটি ভ্যালু (open, pending, closed)। ইনডেক্স তখনই বেশী সহায়ক যখন এটি রো-কে ছোট একটি অংশে সংকুচিত করতে পারে। যদি 80%–95% রো একই স্ট্যাটাস শেয়ার করে, status একা ইনডেক্স করলে সাধারণত অনেক পরিবর্তন হয় না। ডাটাবেস এখনও বড় অংশ পড়তে পারে, এবং ইনডেক্স ওভারহেড যোগ করে।
আপনি সাধারণত সুবিধা অনুভব করবেন যখন:\n
status একা ইনডেক্স করা থেকে ভাল।যেসব কম্বিনেশন প্রথমে কাজে আসে:\n
status + updated_at (স্ট্যাটাস দিয়ে ফিল্টার, সাম্প্রতিক পরিবর্তন অনুযায়ী সর্ট)\n- status + assignee_id (ওয়ার্ক কিউ ভিউ)\n- status + updated_at + assignee_id (শুধু যদি সেই সঠিক ভিউটি ভারি ব্যবহৃত হয়)\n
পারশিয়াল ইনডেক্সগুলি একটি ভালো মধ্যম পথ যখন একটি স্ট্যাটাস ডোমিনেট করে। যদি "open" প্রধান ভিউ হয়, শুধুমাত্র open রো-র জন্য ইনডেক্স করুন। ইনডেক্স ছোট থাকে, এবং রাইট কস্ট কম থাকে।-- PostgreSQL example: index only open rows, optimized for newest-first lists
CREATE INDEX CONCURRENTLY tickets_open_updated_idx
ON tickets (updated_at DESC)
WHERE status = 'open';
একটি ব্যবহারিক পরীক্ষা: ধীর অ্যাডমিন কুয়েরিটি স্ট্যাটাস ফিল্টার দিয়ে এবং ছাড়া চালান। যদি দুইভাবেই ধীর হয়, তাহলে কেবল স্ট্যাটাস-অন ইনডেক্স তা বাঁচাতে পারবে না। সেক্ষেত্রে সোর্ট এবং দ্বিতীয় ফিল্টারের উপর ফোকাস করুন যা বাস্তবে লিস্টটি সংকুচিত করে।
অধিকাংশ অ্যাডমিন প্যানেলে, অ্যাসাইনি হলো রেকর্ডে রাখা একটি ইউজার ID: একটি ফরেইন কি যেমন assignee_id। এটা একটি ক্লাসিক equality ফিল্টার, এবং সাধারণত একটি সিম্পল ইনডেক্স দিয়ে দ্রুত সুবিধা দেয়।
অ্যাসাইনি অন্যান্য ফিল্টারের সাথেও আসে কারণ এটি মানুষের কাজ করার উপায়কে মেলে। একটি সাপোর্ট লিড হয়তো "Assigned to Alex" ফিল্টার করবে এবং তারপর "Open" দিয়ে সংকুচিত করবে। যদি এই ভিউটি ধীর হয়, প্রায়ই একক-কলাম ইনডেক্সের চেয়ে বেশি দরকার হয়।
একটি ভাল শুরু হল একটি কম্পোজিট ইনডেক্স যা সাধারণ ফিল্টার কম্বোকে মেলে:\n
(assignee_id, status) "my open items"-এর জন্য\n- (assignee_id, status, updated_at) যদি লিস্টটি সাম্প্রতিক কার্যকলাপ অনুযায়ী সর্ট করা হয়\n
কম্পোজিট ইনডেক্সে অর্ডার গুরুত্বপূর্ণ। প্রথমে equality ফিল্টারগুলো রাখুন (অften assignee_id, তারপর status), এবং সোর্ট বা রেঞ্জ কলামটি শেষে রাখুন (updated_at)। এটি ডাটাবেসকে দক্ষভাবে ব্যবহার করার অনুরূপ।Unassigned আইটেমগুলো একটি সাধারণ গটচ। অনেক সিস্টেমে "unassigned" কে NULL হিসেবে রাখা হয়, এবং ম্যানেজাররা এর জন্য ফিল্টার করে। ডাটাবেস ও কুয়েরি শেইপ অনুযায়ী, NULL ভ্যালুগুলো প্ল্যানকে পরিবর্তন করতে পারে যার ফলে একটি ইনডেক্স যে অ্যাসাইন্ড আইটেমের জন্য ভালো কাজ করে সে ইনডেক্স আনঅ্যাসাইনড জন্য কাজ না করতে পারে।
যদি unassigned একটি প্রধান ওয়ার্কফ্লো হয়, একটি স্পষ্ট পন্থা বেছে নিয়ে সেটা টেস্ট করুন:\n
assignee_id কে nullable রাখুন, তবে নিশ্চিত করুন WHERE assignee_id IS NULL টেস্ট করা হয়েছে এবং প্রয়োজনে ইনডেক্স করা হয়েছে।\n- একটি ডেডিকেটেড ভ্যালু (যেমন একটি বিশেষ "Unassigned" ইউজার) ব্যবহার করুন যদি এটি আপনার ডাটা মডেলের সাথে মানায়।\n- যদি আপনার ডাটাবেস সাপোর্ট করে, unassigned রো-র জন্য একটি partial index যোগ করুন।আপনি যদি AppMaster-এ অ্যাডমিন প্যানেল বানান, এটি সহায়ক হবে যদি আপনি টিম সবচেয়ে বেশি যে ফিল্টার ও সোর্ট ব্যবহার করে তা লগ করে, তারপর সেই প্যাটার্নগুলোকে কিছু ভাল চয়েস করা ইনডেক্স দিয়ে মিরর করুন, সব ফিল্ডকে ইনডেক্স করার পরিবর্তে।
তারিখ ফিল্টার সাধারণত দ্রুত প্রিসেট হিসেবে আসে যেমন "last 7 days" বা "last 30 days", সাথে একটি কাস্টম পিকার। এগুলো সহজ দেখায়, কিন্তু বড় টেবিলে ভিন্ন ধরনের ডাটাবেস কাজ ট্রিগার করতে পারে।
প্রথমে স্পষ্ট হোন কোন টাইমস্ট্যাম্প কলাম মানুষ আসলে বোঝায়। ব্যবহার করুন:\n
created_at "নতুন আইটেম" ভিউর জন্য\n- updated_at "সাম্প্রতিকভাবে পরিবর্তিত" ভিউর জন্যওই কলামে একটি সাধারন btree ইনডেক্স দিন। না হলে, প্রতিটা "last 30 days" ক্লিক ফুল টেবিল স্ক্যানে পরিণত হতে পারে।
প্রিসেট রেঞ্জগুলো সাধারণত দেখতে হয় created_at \u003e= now() - interval '30 days' এর মত। সেটি একটি রেঞ্জ কন্ডিশন, এবং created_at-এ ইনডেক্স দক্ষভাবে ব্যবহার করা যায়। যদি UI এছাড়াও newest first সর্ট করে, তবে সোর্ট ডিরেকশন ম্যাচ করা (উদাহরণস্বরূপ PostgreSQL-এ created_at DESC) ভারি ব্যবহৃত লিস্টে সাহায্য করতে পারে।
যখন তারিখ রেঞ্জ অন্য ফিল্টারের সাথে মিলায় (status, assignee), তখন নির্বাচনী হোন। কম্পোজিট ইনডেক্স সাধারণত ভালো যখন কম্বোটা সাধারণ। নাহলে, সেগুলো রাইট কস্ট বাড়ায় কিন্তু সুবিধা কম দেয়।
কিছু ব্যবহারিক নিয়ম:\n
(status, created_at) সাহায্য করতে পারে।\n- যদি স্ট্যাটাস ঐচ্ছিক কিন্তু তারিখ সর্বদা থাকে, একটি সহজ created_at ইনডেক্স রাখুন এবং অনেক কম্পোজিট এড়িয়ে চলুন।\n- প্রতিটি কম্বিনেশন তৈরি করবেন না। প্রতিটি নতুন ইনডেক্স স্টোরেজ বাড়ায় এবং রাইট ধীর করে।টাইমজোন এবং বাউন্ডারি অনেক "কঠিন রেকর্ড মিলছে না" বাগ সৃষ্টি করে। ব্যবহারকারীরা যদি তারিখ (টাইম নয়) পিক করে, তাহলে কীভাবে এন্ড-ডেট ব্যাখ্যা করবেন তা সিদ্ধান্ত নিন। একটি নিরাপদ প্যাটার্ন হলো ইনক্লুসিভ স্টার্ট এবং এক্সক্লুসিভ এন্ড: created_at \u003e= start এবং created_at \u003c end_next_day। টাইমস্ট্যাম্প UTC-তে স্টোর করুন এবং ইউজারের ইনপুটকে UTC-এ রূপান্তর করে কুয়েরি চালান।
উদাহরণ: একটি অপস অ্যাডমিন Jan 10 থেকে Jan 12 পছন্দ করে এবং Jan 12-এর সব রেকর্ড দেখতে চায়। যদি আপনার কুয়েরি \u003c= '2026-01-12 00:00' ব্যবহার করে, আপনি Jan 12 এর প্রায় সবকিছু বাদ দেবেন। ইনডেক্স ঠিক ছিল, কিন্তু বাউন্ডারি লজিক ভুল ছিল।
টেক্সট সার্চ অনেক অ্যাডমিন প্যানেল ধীর করে, কারণ মানুষ আশা করে একটি বক্স সব কিছু খুঁজে পাবে। প্রথম সমাধান হলো দুইটি আলাদা চাহিদা আলাদা করা: এক্সেক্ট ম্যাচ (দ্রুত এবং পূর্বানুমানযোগ্য) বনাম কন্টেইনস সার্চ (ফ্লেক্সিবল, কিন্তু ভারি)।
Exact match ফিল্ডগুলোর মধ্যে আছে order ID, ticket number, email, phone, বা একটি external reference। এগুলো সাধারণত সাধারণ ডাটাবেস ইনডেক্সের জন্য পারফেক্ট। যদি অ্যাডমিনরা প্রায়ই একটি ID বা ইমেইল পেস্ট করে, একটি সহজ ইনডেক্স এবং equality কুয়েরি তা তাত্ক্ষণিক বানাতে পারে।
Contains search হলো যখন কেউ একটি অংশ টাইপ করে যেমন "refund" বা "john" এবং নাম, নোট, বিবরণে মিল আশা করে। সাধারণত এটি LIKE %term% হিসেবে ইমপ্লিমেন্ট করা হয়। লিডিং ওয়াইল্ডকার্ডের কারণে একটি সাধারণ B-tree ইনডেক্স ম্যাচটিকে সংকোচন করতে পারে না, তাই ডাটাবেস অনেক রো স্ক্যান করে।
লোড ছাড়াই খোঁজ বানানোর বাস্তব উপায়গুলো:\n
term%) এর জন্য স্ট্যান্ডার্ড ইনডেক্স সাহায্য করতে পারে এবং নামের জন্য প্রায়ই যথেষ্ট দ্রুত মনে হয়।\n- কন্টেইনস সার্চ কেবল তখন যোগ করুন যখন লগ বা অভিযোগ দেখায় এটা দরকার।\n- যখন আপনি কন্টেইনস যোগ করেন, সঠিক টুল ব্যবহার করুন (PostgreSQL full-text search বা trigram ইনডেক্স) LIKE %term%-কে সাধারণ ইনডেক্সে ভরসা না করে।ইনপুট নিয়ম আশা করা তে বেশি গুরুত্বপূর্ণ। এগুলো লোড কমায় এবং ফলাফল কনসিস্টেন্ট করে:\n
একটি ছোট উদাহরণ: একটি সাপোর্ট ম্যানেজার "ann" সার্চ করে একজন কাস্টমার খুঁজতে। যদি আপনার সিস্টেম LIKE %ann% চালায় নোট, নাম, ঠিকানায়, এটি হাজার мың রেকর্ড স্ক্যান করতে পারে। যদি আপনি প্রথমে এক্সেক্ট ফিল্ডগুলো (ইমেইল বা কাস্টমার ID) চেক করেন, তারপর প্রয়োজনে স্মার্ট টেক্সট ইনডেক্সfallback দেন, সার্চ দ্রুত থাকে এবং প্রতিটি কুয়েরি ডাটাবেসের জন্য ভারী হয়ে ওঠে না।
ইনডেক্স যোগ করা সহজ এবং পরে অনুশোচনা করাও সহজ। একটি নিরাপদ কর্মপ্রবাহ আপনাকে অ্যাডমিনদের উপর নির্ভরশীল ফিল্টারগুলোতে ফোকাস রাখতে সাহায্য করে, এবং "সম্ভবত উপকারী" ইনডেক্সগুলো এড়াতে সাহায্য করে যা পরে রাইট ধীর করে।
বাস্তব ব্যবহার দিয়ে শুরু করুন। শীর্ষ কুয়েরিগুলো টানুন দুটি উপায়ে:\n
অ্যাডমিন প্যানেলের জন্য, এগুলো সাধারণত ফিল্টার ও সোর্ট সহ লিস্ট পেইজ।
পরের ধাপে, কুয়েরি শেইপটি ঠিকভাবে ক্যাপচার করুন যেমনটি ডাটাবেস এটা দেখে। সঠিক WHERE এবং ORDER BY লিখে রাখুন, সোর্ট দিক ও সাধারণ কম্বিনেশনসহ (উদাহরণ: status = 'open' AND assignee_id = 42 ORDER BY created_at DESC)। ছোট পার্থক্যগুলি কোন ইনডেক্স সাহায্য করবে তা বদলে দিতে পারে।
একটি সিম্পল লুপ ব্যবহার করুন:\n
পেজিনেশন আলাদা পরীক্ষা দাবি করে। অফসেট-ভিত্তিক পেজিনেশন (OFFSET 20000) যত গভীরে যান তত ধীর হয়ে যায়, এমনকি ইনডেক্স থাকলেও। যদি ব্যবহারকারীরা নিয়মিত খুব গভীর পেজে যায়, কার্সর-স্টাইল পেজিনেশন বিবেচনা করুন ("show items before this timestamp/id") যাতে ইনডেক্স বড় টেবিলে ধারাবাহিক কাজ করতে পারে।
সবশেষে, একটি ছোট নথি রাখুন যাতে মাস-পরে আপনার ইনডেক্স তালিকা বোঝা যায়: ইনডেক্স নাম, টেবিল, কলাম (এবং অর্ডার), এবং এটি কোন কুয়েরি সাপোর্ট করে।
অ্যাডমিন প্যানেলকে ধীর মনে করার দ্রুততম উপায় হল ইনডেক্স যোগ করা ছাড়া এটা পরীক্ষা না করা — কিভাবে মানুষ আসলে ফিল্টার, সর্ট ও পেজ করে। ইনডেক্সগুলোর খরচ আছে এবং প্রতিটি ইনসার্ট ও আপডেটকে কাজ বাড়ায়।
এই প্যাটার্নগুলো অধিকাংশ সমস্যা তৈরি করে:\n
LIKE '%term%' এর মত কন্টেইনস সার্চ ঠিক হবে আশা করা\n- UI পরিবর্তনের পরে পুরনো ইনডেক্স রেখে দেওয়াএকটি সাধারণ সিনারিও: সাপোর্ট টিম টিকিটগুলো Status = Open দিয়ে ফিল্টার করে, updated time অনুযায়ী সর্ট করে, এবং পেজিং করে। আপনি যদি কেবল status-এ ইনডেক্স যোগ করেন, ডাটাবেস এখনও সব open টিকিটগুলো সংগ্রহ করে সেগুলোকে সর্ট করতে পারে। একটি ইনডেক্স যা ফিল্টার ও সোর্ট একসাথে মেলে পেজ 1 দ্রুত ফিরিয়ে দিতে পারে।
অ্যাডমিন UI পরিবর্তনের আগে ও পরে একটি সংক্ষিপ্ত রিভিউ করুন:\n
WHERE + ORDER BY প্যাটার্নকে মেলে।\n- লিডিং ওয়াইল্ডকার্ড (LIKE '%term%') আছে কিনা দেখুন এবং সিদ্ধান্ত নিন কন্টেইনস সার্চ সত্যিই দরকার কি না।\n- ডুপ্লিকেট বা ওভারল্যাপিং ইনডেক্স খুঁজুন।\n- কিছু সময় ধরে অপ্রয়োজনীয় ইনডেক্স ট্র্যাক করুন, তারপর নিশ্চিত হয়ে সেগুলো সরান।আপনি যদি AppMaster-এ PostgreSQL ব্যবহার করে অ্যাডমিন প্যানেল তৈরি করেন, নতুন স্ক্রিন শিপ করার সময় এই রিভিউটি অন্তর্ভুক্ত করুন। সঠিক ইনডেক্সগুলো প্রায়ই সরাসরি আপনার UI-র ফিল্টার ও সোর্ট অর্ডার থেকে আসে।
আরও ইনডেক্স যোগ করার আগে, নিশ্চিত করুন আপনার যেগুলো ইতিমধ্যে আছে সেগুলোই প্রতিদিন মানুষ যে ফিল্টারগুলো ব্যবহার করে সেগুলোতে সাহায্য করছে। একটি ভাল অ্যাডমিন প্যানেল সাধারণ পথগুলোতে তাত্ক্ষণিক মনে হবে, দুর্লভ ওয়ান-অফ সার্চে নয়।
কয়েকটি চেক যা বেশিরভাগ সমস্যা ধরবে:\n
WHERE এবং ORDER BY দুটোকে মেলে, কেবল একটাকে নয়।\n- ইনডেক্স তালিকাকে ছোট রাখুন যাতে আপনি প্রত্যেকটির উদ্দেশ্য এক বাক্যে ব্যাখ্যা করতে পারেন।\n- যদি ইনডেক্সিংয়ের পরে ক্রিয়েট/আপডেট ধীর হয়ে থাকে, সম্ভবত আপনার অনেক বা ওভারল্যাপিং ইনডেক্স আছে।\n- UI-তে "search" দ্বারা আপনি কী বোঝান তা নির্ধারণ করুন: exact match, prefix, বা contains। আপনার ইনডেক্স পরিকল্পনা সেই সিদ্ধান্তের সাথে মেলে।একটি বাস্তবধর্মী পরবর্তী ধাপ হচ্ছে আপনার গোল্ডেন পাথগুলো সাধারণ বাক্যে লিখে রাখা, যেমন: "Support agents filter open tickets, assigned to me, last 7 days, sorted by newest." এই বাক্যগুলো ব্যবহার করে এমন একটি ছোট ইনডেক্স সেট ডিজাইন করুন যা স্পষ্টভাবে সেগুলোকে সাপোর্ট করে।
আপনি যদি এখনও বিল্ডিংয়ের প্রথম দিকে থাকেন, ডেটা ও ডিফল্ট ফিল্টারগুলো মডেল করা সাহায্য করবে অনেক স্ক্রিন তৈরির আগে। AppMaster (appmaster.io) দিয়ে আপনি অ্যাডমিন ভিউ দ্রুত ইটারেট করতে পারেন, তারপর বাস্তব ব্যবহার থেকে হট-পাথগুলো স্পষ্ট হলে কিছু ইনডেক্স যোগ করুন।
Start with the queries that run constantly: the default list view admins see first, plus the 2–3 filters they click all day. Measure frequency and pain (slowest and most-used), then index only what clearly reduces wait time on those exact query shapes.
Because different filters force different amounts of work. Some filters narrow to a small set of rows, while others touch a big range or require sorting large result sets, so one query can use an index well and another can still end up scanning and sorting a lot of data.
Not always. If most rows share the same status, an index on status alone often doesn’t cut much work. It helps more when the status is rare, or when you match the real view by indexing status together with the sort or another filter that truly shrinks the results.
Use a composite index that matches what people actually do, like filtering by status and sorting by recent activity. In PostgreSQL, a partial index can be a clean win when one status dominates, because it keeps the index small and focused on the common workflow.
A simple index on assignee_id is often a quick win, because it’s an equality filter. If “my open items” is a core workflow, a composite index that starts with assignee_id and then includes status (and optionally the sort column) usually performs better than separate single-column indexes.
Unassigned is often stored as NULL, and WHERE assignee_id IS NULL can behave differently from WHERE assignee_id = 123. If unassigned queues matter, test that query specifically and add an index strategy that supports it, often a partial index targeted to unassigned rows if your database supports it.
Add a btree index on the timestamp people actually filter on, usually created_at for “new items” and updated_at for “recently changed.” If you also sort by newest, an index that matches the sort direction can help, but keep composites limited to the few combinations you know are heavily used.
Most missing-record bugs come from date boundaries, not indexes. A reliable pattern is inclusive start and exclusive end, converting user-selected dates to UTC and querying \u003e= start and \u003c end_next_day, so you don’t accidentally drop everything that happened later on the end date.
Because a “contains” query like LIKE %term% can’t use a normal btree index to jump to matches, so it scans lots of rows. Treat exact lookup (ID, email, order number) as a first-class fast path, and only add true contains search when needed using a search method designed for it.
Adding too many indexes increases storage and makes inserts and updates slower, and you can still miss the real bottleneck if the index doesn’t match the WHERE + ORDER BY pattern. A safer loop is to change one index at a time, re-measure the exact slow query, and keep only changes that clearly improve the hot path.
If you build admin screens in AppMaster, log the exact filters and sorts your team uses most, then add a small set of indexes that mirror those real views instead of indexing every available field.



বিনামূল্যের পরিকল্পনা সহ অ্যাপমাস্টারের সাথে পরীক্ষা করুন।
আপনি যখন প্রস্তুত হবেন তখন আপনি সঠিক সদস্যতা বেছে নিতে পারেন৷


