সরঞ্জাম রিজার্ভেশন অ্যাপ: সংঘাত ঠেকান এবং ফেরত ট্র্যাক করুন
এমন একটি সরঞ্জাম রিজার্ভেশন অ্যাপ পরিকল্পনা করুন যা ডাবল বুকিং বন্ধ করে, ফেরত ও ক্ষতির রেকর্ড রাখে এবং ত্রুটিপূর্ণ সরঞ্জামকে রক্ষণাবেক্ষণে আটকে দেয়।
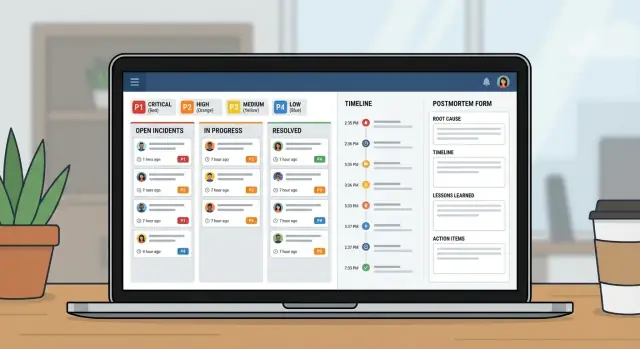
একটি অভ্যন্তরীণ টুলে সেভারিটি ওয়ার্কফ্লো, স্পষ্ট মালিকানা, টাইমলাইন এবং পোস্টমরটেম একসাথে রেখে IT টিমের জন্য ইনসিডেন্ট ম্যানেজমেন্ট অ্যাপ পরিকল্পনা ও তৈরি করুন।
আউটেজ হলে বেশিরভাগ টিম যা খোলা থাকে তাই ধরতে যায়: একটি চ্যাট থ্রেড, একটি ইমেইল চেইন, বা কেউ সময় পেলেই আপডেট করা একটি স্প্রেডশিট। চাপের মধ্যে সেই সেটআপ সব সময় একইভাবে ভেঙে পড়ে: মালিকানা অস্পষ্ট হয়ে যায়, টাইমস্ট্যাম্প মিস হয়, এবং সিদ্ধান্তগুলি স্ক্রোলের ভেতরেই হারিয়ে যায়।
একটি সাধারণ ইনসিডেন্ট ম্যানেজমেন্ট অ্যাপ মৌলিক জিনিসগুলো ঠিক করে। এটি একটি জায়গা দেয় যেখানে ইনসিডেন্টটি থাকে, একটি পরিষ্কার মালিক থাকে, সবাই যে severity তে একমত থাকে তা নির্দিষ্ট থাকে, এবং কী ঘটেছে ও কখন তা দেখানো একটি টাইমলাইন থাকে। ঐ একক রেকর্ড গুরুত্বপূর্ণ, কারণ একই প্রশ্নগুলো প্রতিটি ইনসিডেন্টে উঠে: কে নেতৃত্ব দিচ্ছে? এটা কখন শুরু হয়েছিল? বর্তমান স্ট্যাটাস কী? আগে কী চেষ্টা করা হয়েছে?
ওই শেয়ারড রেকর্ড ছাড়া হ্যান্ডঅফগুলো সময় নষ্ট করে। সাপোর্ট গ্রাহকদের এক বলছে, ইঞ্জিনিয়ারিং অন্য কিছু করছে। ম্যানেজাররা আপডেট চাইলে রেসপন্ডাররা ফিক্স থেকে বিচ্ছিন্ন হয়। পরে কেউ কনফিডেন্সসহ টাইমলাইন পুনর্নির্মাণ করতে পারে না, তাই পোস্টমরটেম অনুমানভিত্তিক হয়ে যায়।
লক্ষ্য আপনার মনিটরিং, চ্যাট বা টিকেটিং প্রতিস্থাপন করা নয়। অ্যালার্টগুলো এখনও অন্যত্র থেকে শুরু হতে পারে। মূল উদ্দেশ্য হল সিদ্ধান্তের ট্রেইল ক্যাপচার করা এবং মানুষগুলোকে সংগত রাখা।
IT অপারেশন এবং অন-কল ইঞ্জিনিয়াররা এটি ব্যবহার করে রেসপন্স সংহত করে। সাপোর্ট দ্রুত সঠিক আপডেট দিতে পারে। ম্যানেজাররা রেসপন্ডারদের বাধা না দিয়ে অগ্রগতি দেখতে পারে।
সকাল 9:12 এ মনিটরিং কাস্টমার পোর্টালে 500 এরর স্পাইক ধরা পড়লে অ্যালার্ট দেয়। একটি সাপোর্ট এজেন্টও রিপোর্ট করে, “প্রায় সকল ব্যবহারকারীর লগইন ব্যর্থ হচ্ছে।” অন-কল IT লিড ইনসিডেন্ট অ্যাপে একটি P1 ইনসিডেন্ট ওপেন করে এবং প্রথম অ্যালার্ট ও সাপোর্টের স্ক্রিনশট সংযুক্ত করে।
P1 হলে আচরণ দ্রুত পরিবর্তিত হয়। ইনসিডেন্ট মালিক ব্যাকএন্ড মালিক, ডাটাবেস মালিক এবং একটি সাপোর্ট লিয়াজনকে টেনে আনে। অনাবশ্যক কাজগুলো স্থগিত করা হয়। পরিকল্পিত ডিপ্লয়মেন্ট বন্ধ করা হয়। টিম আপডেট কেডেন্সে একমত হয় (উদাহরণস্বরূপ প্রতি 15 মিনিটে)। একটি শেয়ার করা কল শুরু হয়, কিন্তু ইনসিডেন্ট রেকর্ডই সত্যের উৎস থাকে।
9:18 AM নাগাদ কেউ জিজ্ঞাসা করে, “কী পরিবর্তন হয়েছে?” টাইমলাইনে 8:57 AM এ একটি ডিপ্লয় দেখা যায়, কিন্তু কি ডিপ্লয় করা হয়েছিল তা লেখা নেই। ব্যাকএন্ড মালিক তবুও রোলব্যাক করে। এরর কমে, পরে আবার ফিরে আসে। এখন টিম সন্দেহ করে ডাটাবেসের দিকে।
বেশিরভাগ বিলম্ব কয়েকটি পূর্বানুমেয় স্থানে দেখা যায়: অস্পষ্ট হ্যান্ডঅফ (“আমি ভেবেছিলাম তুমি সেটা দেখছো”), প্রাসঙ্গিকতা হারানো (সাম্প্রতিক পরিবর্তন, জানা ঝুঁকি, বর্তমান মালিক), এবং চ্যাট, টিকেট ও ইমেইলে ছড়িয়ে থাকা আপডেট।
9:41 AM এ ডাটাবেস মালিক একটি রানের কুয়েরি খুঁজে পায় যা একটি শিডিউল করা জব শুরু করেছিল। তারা জবটি নিষ্ক্রিয় করে, প্রভাবিত সার্ভিস রিস্টার্ট করে এবং পুনরুদ্ধার নিশ্চিত করে। মনিটরিংয়ের জন্য সেভারিটি P2 তে ডাউনগ্রেড করা হয়।
ভাল ক্লোজার মানে শুধু “এটি আবার চলছে” নয়। এটা একটি পরিষ্কার রেকর্ড: মিনিট-প্রতি-মিনিট টাইমলাইন, চূড়ান্ত রুট কারণ, কে কোন সিদ্ধান্ত নিয়েছিল, কী বন্ধ করা হয়েছিল, এবং মালিক ও ডিউ-তারিখসহ ফলো-আপ কাজ। এভাবে একটি চাপপূর্ণ P1 শেখায় এবং পুনরাবৃত্তি কমায়।
একটি ভাল ইনসিডেন্ট টুল বড় মাপেই একটি ভাল ডেটা মডেল। যদি রেকর্ডগুলো অস্পষ্ট হয়, মানুষ ইনসিডেন্ট কী, কখন শুরু হয়েছে, এবং কী এখনও খোলা তা নিয়ে বিতর্ক করবে।
কোর এনটিটি গুলোকে এমনভাবে রাখুন যেভাবে IT টিমগুলো ইতিমধ্যেই কথা বলে:
ভবিষ্যতে বিভ্রান্তি এড়াতে Incident-কে কিছু স্ট্রাকচার্ড ফিল্ড দিন যা সবসময় পূরণ করা হয়। ফ্রি টেক্সট সাহায্য করে, কিন্তু এটিই একমাত্র সত্যের উৎস হওয়া উচিত নয়। একটি ব্যবহারিক মিনিমাম: একটি স্পষ্ট টাইটেল, প্রভাব (ব্যবহারকারীরা কী অভিজ্ঞতা পাচ্ছেন), প্রভাবিত সার্ভিসসমূহ, শুরু সময়, বর্তমান স্ট্যাটাস, এবং সেভারিটি।
রিলেশনশিপগুলো অতিরিক্ত ফিল্ডের চেয়েও বেশি গুরুত্বপূর্ণ। একটি ইনসিডেন্টের অনেকগুলো আপডেট ও টাস্ক থাকতে হবে, এবং সার্ভিসগুলোর সাথে many-to-many লিঙ্ক থাকবে (কারণ আউটেজ প্রায়ই একাধিক সিস্টেমকে প্রভাবিত করে)। একটি পোস্টমরটেম ইনসিডেন্টের সাথে one-to-one হওয়া উচিত, যাতে একটি চূড়ান্ত গল্প থাকে।
উদাহরণ: “Checkout errors” ইনসিডেন্টটি Services “Payments API” এবং “PostgreSQL”-এর সাথে লিঙ্ক করবে, প্রতি 15 মিনিটে আপডেট থাকবে, এবং “রোলব্যাক করা” ও “রিট্রাই গার্ড যুক্ত করা” মতো টাস্ক থাকবে। পরে পোস্টমরটেম রুট কারণ ধরে এবং দীর্ঘমেয়াদী টাস্ক তৈরি করে।
চাপের মধ্যে মানুষ সহজ লেবেল চায় যেগুলো প্রত্যেকের কাছে একই অর্থ বহন করে। P1 থেকে P4 স্পষ্ট ভাষায় সংজ্ঞায়িত করুন এবং সেভারিটি ফিল্ডের পাশে সংজ্ঞা দেখান।
রেসপন্স লক্ষ্যগুলোকে প্রতিশ্রুতির মতো পড়ান। একটি সহজ বেসলাইন (আপনার বাস্তবতার সাথে সামঞ্জস্য করুন):
| Severity | First response (ack) | First update | Update frequency |
|---|---|---|---|
| P1 | 5 min | 15 min | every 30 min |
| P2 | 15 min | 30 min | every 60 min |
| P3 | 4 hours | 1 business day | daily |
| P4 | 2 business days | 1 week | weekly |
এস্ক্যালেশন নিয়মগুলো মেকানিক্যাল রাখুন। যদি একটি P2 তার আপডেট কেডেন্স মিস করে বা প্রভাব বাড়ে, সিস্টেম সেভারিটি রিভিউ পরামর্শ দেওয়া উচিত। থ্র্যাশ এড়াতে সেভারিটি পরিবর্তন করার অনুমতি সীমিত রাখুন (প্রায়ই ইনসিডেন্ট মালিক বা ইনসিডেন্ট কমান্ডার), তবু যে কেউ মন্তব্য করে রিভিউ অনুরোধ করতে পারবে।
একটি দ্রুত ইমপ্যাক্ট ম্যাট্রিক্স টিমগুলোকে দ্রুত সেভারিটি নির্ধারণে সাহায্য করে। এটিকে কিছু বাধ্যতামূলক ফিল্ড হিসেবে ধরে রাখুন: প্রভাবিত ব্যবহারকারী, আয় ঝুঁকি, সেফটি, সম্মতি/সিকিউরিটি, এবং ওয়ার্কঅ্যারাউন্ড আছে কি না।
ইনসিডেন্ট চলাকালীন মানুষদের আরো অপশন নয় দরকার—তারা এমন একটি ছোট সেট স্টেট চায় যা পরবর্তী পদক্ষেপ স্পষ্ট করে।
ভাল দিনের মতো আপনি যে ধাপগুলো ইতিমধ্যেই অনুসরণ করেন সেগুলো দিয়ে শুরু করুন, তারপর তালিকাটি ছোট রাখুন। যদি 6 বা 7-এর বেশি স্টেট থাকে, টিমগুলো বাক্যবিন্যাস নিয়ে বিতর্ক করবে ফিক্স করার বদলে।
একটি ব্যবহারিক সেট:
প্রতিটি স্ট্যাটাসের স্পষ্ট এন্ট্রি এবং এক্সিট নিয়ম থাকা উচিত। উদাহরণস্বরূপ:
ট্রানজিশন ব্যবহার করে মানুষ যে ফিল্ডগুলো ভুলে যায় সেগুলো জোর দিয়ে নিন। একটি সাধারণ নিয়ম: ইনসিডেন্ট ক্লোজ করা যাবে না যদি না একটি সংক্ষিপ্ত রুট কারণ সারাংশ এবং অন্তত একটি ফলো-আপ আইটেম থাকে। যদি “RCA: TBD” অনুমোদিত থাকে, তা বেশিরভাগ সময়ই তেমনই থেকে যায়।
ইনসিডেন্ট পেজটি এক নজরে তিনটি প্রশ্নের উত্তর দিতে পারা উচিত: এটি কাদের মালিকানাধীন, পরবর্তী অ্যাকশন কী, এবং সর্বশেষ আপডেট কখন পোস্ট করা হয়েছে।
ইনসিডেন্ট যদি উচ্চশব্দপূর্ণ হয়, সবচেয়ে দ্রুত সময় নষ্ট হওয়ার উপায় হল অস্পষ্ট মালিকানা। আপনার অ্যাপটি একজন ব্যক্তিকে স্পষ্টভাবে দায়িত্ব দেবার ব্যবস্থা করবে, তবু অন্যরা সহজে সাহায্য করতে পারবে।
একটি সহজ প্যাটার্ন যা কার্যকর:
অ্যাসাইনমেন্ট স্পষ্ট এবং অডিটেবল হওয়া উচিত। কে মালিক সেট করেছে, কে গ্রহণ করেছে, এবং পরবর্তী সব পরিবর্তন ট্র্যাক করুন। “Accepted” গুরুত্বপূর্ণ, কারণ যে কাউকে নিযুক্ত করা হয়েছে কিন্তু সে ঘুমোচ্ছে বা অফলাইনে থাকে সে প্রকৃত মালিক নয়।
অন-কল বনাম টিম-ভিত্তিক অ্যাসাইনমেন্ট সাধারণত সেভারিটির ওপর নির্ভর করে। P1/P2-এর জন্য ডিফল্ট অন-কল রোটেশন রাখা ভাল যাতে সবসময় একটি নামকরা মালিক থাকে। নিম্ন সেভারিটির জন্য টিম-ভিত্তিক অ্যাসাইনমেন্ট কাজ করতে পারে, কিন্তু তখনও সংক্ষিপ্ত সময়ে একটি একক প্রাইমারি মালিক নির্দিষ্ট করতে হবে।
ছুট এবং আউটেজের জন্য আপনার প্রক্রিয়ায় পরিকল্পনা রাখুন, কেবল আপনার সিস্টেমেই নয়। যদি নিযুক্ত ব্যক্তি ‘অব্যর্থ’ হিসেবে চিহ্নিত থাকে, তাহলে এটি স্বয়ংক্রিয়ভাবে সেকেন্ডারি অন-কল বা টিম লিডের কাছে রুট করুন। এটিকে স্বয়ংক্রিয় রাখুন, কিন্তু দৃশ্যমান রাখুন যাতে দ্রুত সংশোধন করা যায়।
এস্ক্যালেশন সেভারিটি এবং নীরবতা—দুটোর ওপর ট্রিগার করা উচিত। একটি ব্যবহারিক শুরু:
একটি ভাল টাইমলাইনটাই শেয়ারড মেমোরি। ইনসিডেন্ট চলাকালীন প্রসঙ্গ দ্রুত হারিয়ে যায়। যদি আপনি সঠিক মুহূর্তগুলো এক জায়গায় ক্যাপচার করেন, হ্যান্ডঅফ সহজ হয় এবং পোস্টমরটেম বেশিরভাগই খুলে দেয়ার আগে লেখা হয়ে যায়।
টাইমলাইনটি মতামতপূর্ণ রাখুন। এটাকে চ্যাট লগ বানাতে দেবেন না। বেশিরভাগ টিম কয়েকটি এন্ট্রিতে নির্ভর করে: ডিটেকশন, অ্যাকনলেজমেন্ট, মূল মিটিগেশন ধাপ, পুনরুদ্ধার, এবং ক্লোজার।
প্রতিটি এন্ট্রিতে টাইমস্ট্যাম্প, লেখক, এবং সংক্ষিপ্ত সাদাসিধে বর্ণনা থাকা দরকার। পরে যোগ হওয়া কেউ পাঁচটি এন্ট্রি পড়ে দ্রুত কি হচ্ছে তা বুঝতে পারা উচিত।
বিভিন্ন আপডেট বিভিন্ন শ্রোতাদের বহন করে। এন্ট্রিগুলোতে টাইপ থাকলে সুবিধা হয়—যেমন internal note (কাঁচা বিবরণ), customer-facing update (নিরাপদ ভাষা), decision (কেন আপনি অপশন A বেছে নিলেন), এবং handoff (পরবর্তী ব্যক্তিকে কী জানতে হবে)।
রিমাইন্ডারগুলো ব্যক্তিগত পছন্দ নয় বরং সেভারিটির উপর নির্ভর করা উচিত। টাইমার গেলে প্রথমে কারেন্ট মালিককে পিং করুন, তারপর যদি বারবার মিস হয় তবে এসক্যালেট করুন।
নোটিফিকেশনগুলো লক্ষ্যভিত্তিক এবং পূর্বানুমেয় হওয়া উচিত। সাধারণ নিয়ম: তৈরি হলে, সেভারিটি পরিবর্তন হলে, পুনরুদ্ধার হলে, এবং ওভারডিউ আপডেট হলে নোটিফাই করুন। কোম্পানি-স্তরে সবাইকে প্রতিটি পরিবর্তনের জন্য নোটিফাই করা থেকে বিরত থাকুন।
একটি পোস্টমরটেমের দুইটি কাজ থাকা উচিত: সাধারন ভাষায় কী ঘটেছে ব্যাখ্যা করা, এবং পরবর্তীবার একই ব্যর্থতা কম ঘটার উপায় তৈরি করা।
রিপোর্টটি সংক্ষিপ্ত রাখুন, এবং আউটপুটকে অ্যাকশনে বাধ্য করুন। একটি ব্যবহারিক কাঠামো: সারসংক্ষেপ, গ্রাহক প্রভাব, রুট কারণ, প্রয়োগকৃত ফিক্স, এবং ফলো-আপ।
ফলো-আপই মূল বিষয়। এগুলোকে শেষে একটি অনুচ্ছেদে রেখে দেবেন না। প্রতিটি ফলো-আপকে একটি ট্র্যাক করা টাস্কে রূপান্তর করুন যার মালিক এবং একটি ডিউ-তারিখ আছে—even যদি ডিউ-তারিখ “পরবর্তী স্প্রিন্ট” হয়। এটাই পার্থক্য “আমরা মনিটরিং উন্নত করা উচিত” এবং “Alex শুক্রবারের মধ্যে DB কানেকশন স্যাচুরেশন অ্যালার্ট যোগ করবে” এর মধ্যে।
ট্যাগগুলি পোস্টমরটেমগুলো পরে কাজে লাগবে। প্রতিটি ইনসিডেন্টে 1 থেকে 3 টি থিম যোগ করুন (monitoring gap, deployment, capacity, process)। এক মাস পরে আপনি সহজ প্রশ্নের উত্তর দিতে পারবেন, যেমন বেশিরভাগ P1 রিলিজ থেকেই আসে নাকি অ্যালার্ট হারানোর কারণে।
এভিডেন্স অটাচ করা সহজ হওয়া উচিত, বাধ্যতামূলক নয়। স্ক্রিনশট, লগ স্নিপেট, এবং বাহ্যিক সিস্টেমের রেফারেন্স (টিকেট আইডি, চ্যাট থ্রেড, ভেন্ডর কেস নাম্বার) সংযুক্ত করার জন্য অপশনাল ফিল্ড রাখুন। এটি লাইটওয়েট রাখুন যাতে মানুষ আসলে এটিতে ভর্তি করে।
এটিকে একটি ছোট প্রোডাক্ট হিসেবে বিবেচনা করুন, একটি অতিরিক্ত কলাম সহ স্প্রেডশিট হিসেবে নয়। একটি ভাল ইনসিডেন্ট অ্যাপটি মূলত তিনটি ভিউ: এখন কী ঘটছে, পরবর্তী কী করা উচিত, এবং পরে কী শেখা হয়েছে।
চাপের নিচে মানুষ যে স্ক্রিনগুলো খুলবে সেগুলো প্রথমে স্কেচ করুন:
ডেটা মডেল এবং পারমিশন একসাথে তৈরি করুন। যদি সবাই সব কিছু এডিট করতে পারে, হিস্টরি বিশৃঙ্খল হবে। সাধারণ পদ্ধতি: IT-এর জন্য বিস্তৃত ভিউ অ্যাক্সেস, স্টেট/সেভারিটি পরিবর্তন নিয়ন্ত্রিত, রেসপন্ডাররা আপডেট যোগ করতে পারবেন, এবং পোস্টমরটেম অনুমোদনের জন্য একটি স্পষ্ট মালিক থাকবে।
তারপর ওয়ার্কফ্লো নিয়ম যোগ করুন যা আধা-ভরা ইনসিডেন্ট বাধা দেয়। প্রয়োজনীয় ফিল্ডগুলো স্টেটের ওপর নির্ভর করবে। আপনি হতে পারেন “New” এ শুধু টাইটেল ও রিপোর্টার অনুমোদন করেন, কিন্তু “Mitigating” এ ইমপ্যাক্ট সারাংশ বাধ্যতামূলক করতে পারেন, এবং “Resolved” এ রুট কারণ সারাংশ এবং অন্তত একটি ফলো-আপ টাস্ক বাধ্যতামূলক করতে পারেন।
শেষে, 2 থেকে 3টি পুরনো ইনসিডেন্ট রেপ্লে করে টেস্ট করুন। একজনকে ইনসিডেন্ট কমান্ডার ও একজনকে রেসপন্ডার হিসেবে রাখুন। আপনি দ্রুত দেখবেন কোন স্ট্যাটাসগুলো অস্পষ্ট, কোন ফিল্ডগুলো মানুষ স্কিপ করে, এবং কোথায় আরও ভাল ডিফল্ট দরকার।
অধিকাংশ ইনসিডেন্ট সিস্টেম সহজ কারণে ব্যর্থ হয়: মানুষ স্ট্রেসে নিয়মগুলো মনে রাখে না, এবং অ্যাপ পরে যা দরকার তা ক্যাপচার করে না।
যদি আপনার ছয়টির বেশি সেভারিটি এবং দশটির বেশি স্ট্যাটাস থাকে, মানুষ আন্দাজ করবে। সেভারিটি 3 থেকে 4 রাখুন এবং স্ট্যাটাসগুলোকে পরের কী করা উচিত তা বোঝার উপর ফোকাস করুন।
যখন সবাই “দেখছে”, তখন কেউ চালায় না। ইনসিডেন্ট এগোতে পারার আগে একটি নামকরা মালিক বাধ্যতামূলক করুন, এবং হ্যান্ডঅফগুলো স্পষ্টভাবে রেকর্ড করুন।
“কবে কী হল” যদি চ্যাট হিস্ট্রির ওপর নির্ভর করে, পোস্টমরটেম বিতর্কে পরিণত হয়। ওপেন, অ্যাকনলেজড, মিটিগেটেড, এবং রিজলভড টাইমস্ট্যাম্পগুলো অটো-ক্যাপচার করুন এবং টাইমলাইন এন্ট্রিগুলো সংক্ষিপ্ত রাখুন।
এছাড়াও অস্পষ্ট রুট কারণ নোট যেমন “নেটওয়ার্ক সমস্যা” দিয়ে ক্লোজ করা এড়ান। একটি স্পষ্ট রুট কারণ বিবৃতি এবং অন্তত একটি কংক্রিট পরবর্তী ধাপ অনিবার্য করুন।
পুরো IT অর্গে রোল আউট করার আগে মৌলিকগুলো স্ট্রেস টেস্ট করুন। যদি মানুষ প্রথম দুই মিনিটে সঠিক বোতাম না পায়, তারা আবার চ্যাট থ্রেড ও স্প্রেডশিটে ফিরে যাবে।
ছোট একটি লঞ্চ চেকগুলোর ওপর ফোকাস করুন: ভূমিকা ও পারমিশন, স্পষ্ট সেভারিটি সংজ্ঞা, বাধ্যতামূলক মালিকানা, রিমাইন্ডার নিয়ম, এবং রেসপন্স টার্গেট মিস হলে একটি এসক্যালেশন পথ।
একটি টিম এবং কয়েকটি সার্ভিস নিয়ে পাইলট চালান যেগুলো প্রায়ই অ্যালার্ট জেনারেট করে। দুসপ্তাহ চালান, তারপর বাস্তব ইনসিডেন্টের ভিত্তিতে সমন্বয় করুন।
যদি আপনি এটি একটিই অভ্যন্তরীণ টুল হিসেবে তৈরি করতে চান এবং স্প্রেডশিট ও আলাদা অ্যাপগুলো জোড়া না করতে চান, AppMaster (appmaster.io) একটি অপশন হতে পারে। এটি আপনাকে একটি ডেটা মডেল, ওয়ার্কফ্লো নিয়ম, এবং ওয়েব/মোবাইল ইন্টারফেস এক জায়গায় তৈরির সুযোগ দেয়, যা ইনসিডেন্ট কিউ, ইনসিডেন্ট পেজ, এবং পোস্টমরটেম ট্র্যাকিংয়ের সাথে ভাল মিলবে।
এটি ছড়িয়ে থাকা আপডেটগুলোকে একটিই শেয়ারড রেকর্ডে বদলে দেয় যা দ্রুত মৌলিক প্রশ্নগুলোর উত্তর দেয়: কে ইনসিডেন্টের মালিক, ব্যবহারকারীরা কী দেখছে, কী কী চেষ্টা করা হয়েছে, এবং পরবর্তী কী। এর ফলে হ্যান্ডঅফ, বিরোধী বার্তা এবং “সংক্ষেপ বলুন” ধরনের বিরক্তি কমে যায়।
যখনই আপনি মনে করেন যে গ্রাহক বা ব্যবসায়িক প্রভাব সত্যিই ঘটছে, তখনই ইনসিডেন্ট খুলুন—রুট কারণ অস্পষ্ট হলেও। শুরুতে ড্রাফট টাইটেল এবং “প্রভাব অজানা” দিয়ে খুলে পরে সেভাবেই তথ্য কড়া করুন যখন আপনি সেভারিটি এবং স্কোপ নিশ্চিত করবেন।
কনিষ্ঠ ও স্ট্রাকচার্ড রাখুন: একটি পরিষ্কার টাইটেল, প্রভাব সারসংক্ষেপ, প্রভাবিত সার্ভিস(গুলো), শুরু সময়, বর্তমান স্ট্যাটাস, সেভারিটি, এবং এক জন মালিক। পরিস্থিতি বাড়লে আপডেট ও টাস্ক যোগ করুন, কিন্তু মূল তথ্যের জন্য ফ্রি টেক্সটের উপর নির্ভর করবেন না।
৩ থেকে ৪ স্তর ব্যবহার করুন যেগুলো সহজে বোঝা যায়। একটি ভালো ডিফল্ট: P1—কোর সার্ভিস ডাউন বা ডেটা-লস ঝুঁকি, P2—বড় ফিচার প্রভাবিত কিন্তু কিছু ওয়ার্কঅ্যারাউন্ড আছে বা সীমিত বিস্তার, P3—কম-প্রভাব, P4—নির্মাণাত্মক বা সামান্য ত্রুটি।
টার্গেটগুলোকে প্রতিশ্রুতির মতো রাখুন: স্বীকারের সময়, প্রথম আপডেটের সময়, এবং আপডেট ঘনত্ব। এরপর কেডেন্স মিস হলে রিমাইন্ডার ও এসক্যালেশন ট্রিগার করুন—কারণ ইনসিডেন্টে ‘নীরবতা’ প্রায়ই আসল ব্যর্থতা।
প্রায় ছয়টি স্ট্যাটাসের লক্ষ্য রাখুন: New, Acknowledged, Investigating, Mitigating, Monitoring, Resolved। প্রতিটি স্টেটে পরবর্তী পদক্ষেপ স্পষ্ট হওয়া উচিত, এবং স্টেট ট্রানজিশনগুলো এমন ফিল্ডগুলো বাধ্যতামূলক করতে পারে যা স্ট্রেসে মানুষ ভুলে যায়—যেমন Acknowledged হওয়ার আগে মালিক থাকা বাধ্যতামূলক।
একজন প্রাথমিক মালিককে বাধ্যতামূলক করুন যিনি রেসপন্স চালাবেন এবং আপডেট দেবেন। “অ্যাকসেপ্টেড” ট্র্যাক করুন যাতে কেউ যে নিযুক্ত করা হয়েছে সে অনলাইনে আছে কিনা জানা যায়, এবং হ্যান্ডঅফগুলো রেকর্ড করা নিশ্চিত করুন যাতে পরবর্তী ব্যক্তি পুনরায় তদন্ত না শুরু করে।
টাইমলাইনটি কেবলমাত্র গুরুত্বপূর্ণ মুহূর্তগুলোই ধরুক: ডিটেকশন, অ্যাকনলেজমেন্ট, মূল সিদ্ধান্ত, মিটিগেশন ধাপ, পুনরুদ্ধার এবং ক্লোজার—প্রতিটিতে টাইমস্ট্যাম্প এবং লেখক থাকা উচিত। এটাকে চ্যাট ট্রান্সক্রিপ্ট বানাবেন না, যাতে পরে আসা কেউ দ্রুত পরিস্থিতি বুঝে নিতে পারে।
সংক্ষিপ্ত ও অ্যাকশন-ফোকাসড রাখুন: কী ঘটল, গ্রাহক প্রভাব, রুট কারণ, মিটিগেশনের সময় কি বদল করা হয়েছে, এবং ফলো-আপ আইটেমগুলো সঙ্গে দায়ী ব্যক্তি ও ডিউ-তারিখসহ। লেখাটি দরকারী, কিন্তু একই ইনসিডেন্ট পুনরাবৃত্তি বন্ধ করার কাজটা করে এমন ট্র্যাক করা টাস্কই সবচেয়ে গুরুত্বপূর্ণ।
হ্যাঁ—যদি আপনি ইনসিডেন্ট, আপডেট, টাস্ক, সার্ভিস এবং পোস্টমরটেমকে প্রকৃত ডেটা হিসেবে মডেল করে অ্যাপের মধ্যে ওয়ার্কফ্লো নিয়ম জোরদার করেন। AppMaster (appmaster.io) দিয়ে টিমগুলো সেই ডেটা মডেল, ওয়েব/মোবাইল স্ক্রিন এবং স্টেট-ভিত্তিক ভ্যালিডেশন এক জায়গায় তৈরি করতে পারে, ফলে চাপের সময় প্রসেস স্প্রেডশিটে ফিরে যায় না।



বিনামূল্যের পরিকল্পনা সহ অ্যাপমাস্টারের সাথে পরীক্ষা করুন।
আপনি যখন প্রস্তুত হবেন তখন আপনি সঠিক সদস্যতা বেছে নিতে পারেন৷


