장비 예약 앱으로 충돌을 방지하고 반납을 추적하는 방법
이중 예약을 방지하고 반납과 손상을 기록하며 고장 난 장비를 유지보수 보류 상태로 전환하는 장비 예약 앱을 계획해 보세요.
내부 도구용 감사 로그 실무 가이드: CRUD 변경마다 누가 언제 무엇을 했는지 추적하고, 안전하게 diff를 저장하고, 관리자 활동 피드를 제공하는 방법.
Order_history나 User_versions처럼 엔티티별 이력 테이블을 만들어, 각 업데이트마다 전체 스냅샷(또는 구조화된 변경 필드 집합)을 버전 번호와 함께 저장합니다.\n\n이 방식은 특정 시점의 보고(예: "이 레코드는 지난 화요일에 어떻게 보였나?")를 쉽게 하고, 각 레코드의 타임라인이 자체적으로 포함되어 있어 감사자에게 더 명확하게 느껴질 수 있습니다.\n\n실용적 선택 가이드:\n\n- 한 곳에서 검색하고 싶고 활동 피드를 쉽게 만들고 싶다면 이벤트 로그를 선택하세요.\n- 레코드별 시점 뷰가 자주 필요하다면 버전 이력을 선택하세요.\n- 저장 용량이 문제라면 필드 수준의 diff가 있는 이벤트 로그가 전체 스냅샷보다 보통 가볍습니다.\n- 보고가 주목적이라면 버전 테이블이 이벤트 페이로드를 파싱하는 것보다 쿼리하기 쉬울 수 있습니다.\n\n어떤 모델을 택하든 감사 항목은 불변(immutable)으로 유지하세요: 업데이트나 삭제 없음. 뭔가 잘못되었다면 정정 사실을 설명하는 새 항목을 추가하세요.\n\n또한 correlation_id(또는 operation id) 추가를 고려하세요. 한 사용자 액션이 여러 변경을 촉발하는 경우(예: "사용자 비활성화"가 사용자 업데이트, 세션 해제, 대기 중 작업 취소를 동시에 발생시킬 수 있음) 공유된 correlation id로 해당 행들을 하나의 읽기 쉬운 작업으로 그룹화할 수 있습니다.\n\n## 삭제와 대량 편집을 포함해 CRUD 동작을 신뢰성 있게 캡처하기\n\n신뢰성 있는 감사 로깅의 규칙 하나는: 모든 쓰기는 감사 이벤트도 작성하는 단일 경로를 통해 이루어져야 한다는 것입니다. 일부 업데이트가 백그라운드 작업, 임포트, 빠른 편집 화면을 통해 정상 저장 흐름을 우회하면 로그에 구멍이 생깁니다.\n\n생성의 경우 행위자와 출처(UI, API, 임포트)를 기록하세요. 임포트는 누가 했는지를 자주 잃는 곳이므로, 파일이나 통합에서 왔더라도 명시적 "performed by" 값을 저장하세요. 또한 초기 값(전체 스냅샷 또는 핵심 필드 집합)을 저장해 그 레코드가 왜 존재하는지 설명할 수 있게 하세요.\n\n업데이트는 더 까다롭습니다. 변경된 필드만 기록할 수 있고(작고 읽기 쉬움, 빠름), 또는 각 저장 후 전체 스냅샷을 보관할 수 있습니다(나중에 쿼리하기 간단하지만 무겁다). 실용적 중간 방법은 일반 편집에는 diff를 저장하고, 권한, 은행 정보, 가격 규칙 같은 민감 객체에 대해서만 스냅샷을 보관하는 것입니다.\n\n삭제는 증거를 지우면 안 됩니다. 소프트 삭제(is_deleted 플래그 + 감사 항목)를 선호하세요. 하드 삭제가 필요하면 감사 이벤트를 먼저 기록하고 레코드의 스냅샷을 포함해 무엇이 제거되었는지 증명할 수 있게 하세요.\n\n복원은 자체 행동으로 취급하세요. "Restore"는 "Update"와 같지 않으며, 분리하면 검토와 컴플라이언스 검증이 훨씬 쉬워집니다.\n\n대량 편집의 경우 "500개 레코드 업데이트" 같은 모호한 단일 항목을 피하세요. 나중에 "어떤 레코드가 변경됐나?"에 답할 수 있을 만큼의 세부 정보가 필요합니다. 실용적 패턴은 상위 이벤트(parent event)와 레코드별 자식 이벤트(child events)를 함께 기록하는 것입니다:\n\n- 상위 이벤트: 행위자, 사용한 도구/화면, 사용한 필터, 배치 크기\n- 레코드별 자식 이벤트: 레코드 ID, before/after(또는 변경된 필드), 결과(success/fail)\n- 선택적: 공통된 이유(reason) 필드(정책 업데이트, 정리, 마이그레이션)\n\n예: 지원 리더가 120개의 티켓을 일괄 종료합니다. 상위 항목은 필터(예: status=open, older than 30 days)를 캡처하고 각 티켓은 상태 open -> closed를 보여주는 자식 항목을 가집니다.\n\n## 저장 공간과 개인정보 문제 없이 변경 내용을 저장하기\n\n감사 로그는 너무 많은 것(전체 레코드 영구 저장) 또는 너무 적은 것(단지 "사용자 편집") 둘 중 하나가 되면 금방 쓸모없어집니다. 목표는 컴플라이언스에 방어적이고 관리자가 읽기 쉬운 기록을 만드는 것입니다.\n\n실용적 기본값은 대부분의 업데이트에 대해 필드 수준의 diff를 저장하는 것입니다. 변경된 필드만, before와 after 값을 저장하세요. 이렇게 하면 저장 공간을 줄이고 활동 피드를 스캔하기 쉽게 만듭니다: "Status: Pending -> Approved"는 거대한 블롭보다 훨씬 명확합니다.\n\n중요 순간(생성, 삭제, 주요 워크플로 전환)에 대해 전체 스냅샷을 보관하세요. 스냅샷은 무겁지만 "삭제되기 전 고객 프로필이 정확히 어땠나?"라는 질문에 대비할 수 있게 합니다.\n\n민감한 데이터는 마스킹 규칙이 필요합니다. 그렇지 않으면 감사 테이블이 비밀로 가득한 두 번째 데이터베이스가 됩니다. 일반 규칙:\n\n- 비밀번호, API 토큰, 개인 키는 절대 저장하지 마세요(단순히 "변경됨"으로 기록)\n- 이메일/전화 번호 같은 개인 데이터는 부분 마스킹하거나 해시로 저장하세요\n- 메모나 자유 텍스트 필드는 짧은 미리보기와 "변경됨" 플래그를 저장하세요\n- 관련 객체 전체를 복사하지 말고 참조(user_id, order_id)를 기록하세요\n\n스키마 변경도 감사 이력을 망칠 수 있습니다. 필드가 나중에 이름이 바뀌거나 제거되면 "unknown field" 같은 안전한 폴백과 원래 필드 키를 저장하세요. 삭제된 필드는 마지막 알려진 값을 보관하되 "schema에서 제거된 필드"로 표시해 피드의 정직성을 유지하세요.\n\n마지막으로 항목을 사람이 읽기 쉽게 만드세요. 원시 키(assignee_id) 옆에 표시용 레이블("할당자")을 저장하고 값(date, 통화, 상태 이름)을 형식화하세요.\n\n## 단계별 패턴: 앱 흐름에 감사 로깅 구현하기\n\n신뢰할 수 있는 감사 추적은 더 많이 로그하는 것이 아니라 어디서나 반복 가능한 패턴을 사용하는 것입니다. 그래야 대량 임포트가 기록되지 않았다거나 모바일 편집이 익명처럼 보이는 구멍을 피할 수 있습니다.\n\n### 1) 감사 데이터 모델을 한 번 정의하세요\n\n데이터 모델에서 시작해 어떤 변경도 설명할 수 있는 작은 테이블 집합을 만드세요.\n\n단순하게 유지하세요: 이벤트용 한 테이블, 변경된 필드용 하나, 그리고 작은 행위자 컨텍스트.\n\n- audit_event: id, entity_type, entity_id, action(create/update/delete/restore), created_at, request_id\n- audit_event_item: id, audit_event_id, field_name, old_value, new_value\n- actor_context(또는 audit_event의 필드들): actor_type(user/system), actor_id, actor_email, ip, user_agent\n\n### 2) 하나의 공유된 "쓰기 + 감사(Write + Audit)" 하위 프로세스를 추가하세요\n\n재사용 가능한 하위 프로세스를 만들어서:\n\n1) 엔티티 이름, 엔티티 ID, 액션, before/after 값을 받습니다.\n2) 비즈니스 변경을 메인 테이블에 씁니다.\n3) audit_event 레코드를 생성합니다.\n4) 변경된 필드를 계산해 audit_event_item 행을 삽입합니다.\n\n규칙은 엄격합니다: 모든 쓰기 경로는 이 동일한 하위 프로세스를 호출해야 합니다. 여기에는 UI 버튼, API 엔드포인트, 예약 자동화, 통합이 모두 포함됩니다.\n\n### 3) 서버에서 행위자와 시간을 생성하세요\n\n브라우저를 "누가"와 "언제"로 신뢰하지 마세요. 인증 세션에서 행위자를 읽고, 타임스탬프는 서버 측에서 생성하세요. 만약 자동화가 실행되면 actor_type을 system으로 설정하고 작업 이름을 행위자 레이블로 저장하세요.\n\n### 4) 하나의 구체적 시나리오로 테스트하세요\n\n단일 레코드(예: 고객 티켓)를 골라 생성, 두 필드(status와 assignee) 편집, 삭제, 복원을 해보세요. 감사 피드에는 다섯 개의 이벤트가 보여야 하고, 편집 이벤트 아래에는 두 개의 업데이트 항목이 있으며, 행위자와 타임스탬프가 매번 동일한 방식으로 채워져야 합니다.\n\n## 사람이 실제로 사용할 수 있는 관리자 활동 피드 구축\n\n감사 로그는 누군가 빠르게 읽을 수 있어야만 유용합니다. 관리자 피드의 목표는 간단합니다: 한눈에 "무슨 일이 있었나?"를 답하고, 원할 때 원시 JSON에 빠져들지 않고 더 깊이 볼 수 있게 하는 것입니다.\n\n타임라인 레이아웃으로 시작하세요: 최신 순, 이벤트당 한 줄, 그리고 Created, Updated, Deleted, Restored 같은 명확한 동사 사용. 각 행은 행위자(사람 또는 시스템), 대상(레코드 유형 + 사람이 이해하기 쉬운 이름), 시간 표시를 포함해야 합니다.\n\n실용적 행 포맷:\n\n- 동사 + 객체: "Updated Customer: Acme Co."\n- 행위자: "Maya (Support)" 또는 "System: Nightly Sync"\n- 시간: 절대 타임스탬프(타임존 포함)\n- 변경 요약: "status: Pending -> Approved, limit: 5,000 -> 7,500"\n- 태그: Updated, Deleted, Integration, Job\n\n"무엇이 바뀌었나"는 간결하게 유지하세요. 인라인으로 1security_audit 스트림으로 보내고, 비즈니스 편집(status 업데이트, 승인, 워크플로 변경)은 일반 감사 스트림에 두는 게 좋습니다.\n\n누군가 개인 데이터 삭제를 요청하면 전체 감사 추적을 지우지 마세요. 대신:\n\n- 사용자 프로필 데이터를 삭제하거나 익명화\n- 로그의 행위자 식별자는 안정적 가명(예: "deleted-user-123")으로 대체\n- 개인 데이터로 저장된 필드 값은 편집(레드액션)\n- 컴플라이언스를 위해 타임스탬프, 액션 유형, 레코드 참조는 보관\n\n## 보존, 무결성, 성능(컴플라이언스 관점)\n\n유용한 감사 로그는 단순히 "이벤트를 기록한다"에 그치지 않습니다. 컴플라이언스에서는 세 가지를 증명해야 합니다: 데이터를 충분히 오래 보관했는지, 사후에 변경되지 않았는지, 요청 시 빠르게 검색할 수 있는지입니다.\n\n### 보존: 설명할 수 있는 정책을 정하세요\n\n위험 수준에 맞는 단순한 규칙으로 시작하세요. 많은 팀은 일상 문제 해결을 위해 90일, 내부 컴플라이언스를 위해 1내부 도구가 실제 데이터를 변경할 수 있다면 가능한 빨리 감사 로그를 추가하세요. 첫 분쟁이나 감사 요구는 보통 예상보다 빨리 옵니다. 나중에 과거 이력을 채우려 하면 대부분 추측에 의존하게 됩니다.
유용한 감사 로그는 누가 했는지, 어떤 레코드에 영향을 줬는지, 무엇이 변경됐는지, 언제 일어났는지, 어디서 왔는지(UI, API, 임포트, 작업 등)를 빠르게 답할 수 있어야 합니다. 이 중 하나라도 빠르게 답할 수 없다면 로그는 신뢰받기 어렵습니다.
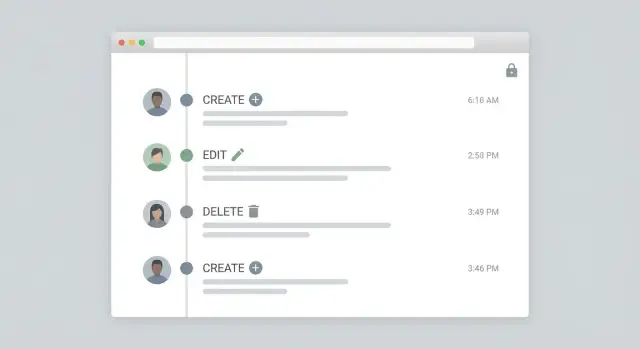
디버그 로그는 개발자를 위한 것이며 종종 시끄럽고 일관성이 없습니다. 감사 로그는 책임성을 위한 것으로, 일관된 필드, 명확한 문구, 비기술자도 읽을 수 있는 안정된 형식이 필요합니다.
일반적으로 보이는 편집은 로그에 남지만, 표준 편집 화면 밖에서 발생하는 변경(대량 편집, 임포트, 예약 작업, 관리자 단축 작업, 삭제 등)이 누락될 때 커버리지가 실패합니다. 이러한 비표준 경로를 놓치지 않는 것이 핵심입니다.
행위자 유형과 식별자를 저장하세요. 단순히 사용자 ID만 기록하면 직원과 시스템 작업, 서비스 계정, 외부 통합을 구분할 수 없습니다. 그래서 actor_type과 actor_id를 함께 기록하면 누가 했는지 명확해집니다.
데이터베이스에는 타임스탬프를 UTC로 저장하고, 관리자 UI에서는 뷰어 로컬 시간으로 표시하세요. 이렇게 하면 검토 중에 발생하는 시간대 혼란을 피할 수 있습니다.
검색을 한 곳에서 하고 활동 피드를 쉽게 만들고 싶다면 append-only 이벤트 로그를 사용하세요. 특정 레코드의 시점별 뷰가 자주 필요하다면 버전 이력(per-entity version)을 선택하세요. 많은 앱에서는 필드 수준의 diff를 갖춘 이벤트 로그가 저장 공간 측면에서 충분한 경우가 많습니다.
증거를 지우지 않으려면 소프트 삭제를 선호하세요(is_deleted 플래그와 감사 항목). 하드 삭제가 반드시 필요하다면 먼저 감사 이벤트를 기록하고 삭제된 레코드의 스냅샷을 포함하세요.
업데이트는 대부분 필드 수준의 diff를 저장하고, 생성 또는 삭제 같은 중요한 순간에는 전체 스냅샷을 보관하는 것이 실용적입니다. 민감한 필드는 변경만 기록하고 실제 값은 저장하지 않거나 마스킹하세요.
모든 쓰기 경로가 실제로 감사 이벤트를 생성하도록 하나의 공유된 "쓰기 + 감사(Write + Audit)" 경로를 만드세요. UI, API, 임포트, 백그라운드 작업 등 모든 쓰기 작업이 이 경로를 사용하게 강제하면 누락이 줄어듭니다.





