장비 예약 앱으로 충돌을 방지하고 반납을 추적하는 방법
이중 예약을 방지하고 반납과 손상을 기록하며 고장 난 장비를 유지보수 보류 상태로 전환하는 장비 예약 앱을 계획해 보세요.
정렬, 필터, 총계에 대해 일관된 API 계약을 사용해 웹과 모바일 관리자 화면의 응답성을 유지하는 커서 vs 오프셋 페이지네이션을 학습하세요.
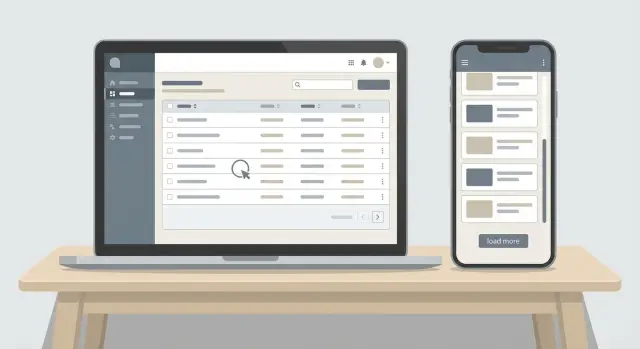
관리자 화면은 흔히 간단한 테이블에서 시작합니다: 처음 25개 행을 불러오고, 검색 상자를 추가하면 끝. 몇백 건일 땐 즉각적으로 느껴집니다. 하지만 데이터셋이 커지면 동일한 화면이 버벅거리기 시작합니다.
문제는 보통 UI가 아닙니다. API가 정렬과 필터를 적용한 채로 12페이지를 반환하기 전에 수행해야 하는 작업이 문제입니다. 테이블이 커질수록 백엔드는 일치하는 항목을 찾고, 개수를 세고, 앞쪽 결과를 건너뛰느라 더 많은 시간을 씁니다. 클릭할 때마다 더 무거운 쿼리가 실행되면 화면은 반응하는 대신 생각하는 것처럼 느껴집니다.
비슷한 증상은 언제나 나타납니다: 페이지 전환이 점점 느려지고, 정렬이 둔해지고, 검색 결과가 페이지마다 일관되지 않으며, 무한 스크롤은 빠르게 로드되다 갑자기 느려집니다. 활발한 시스템에서는 요청 사이에 데이터가 변경되면서 중복이나 누락된 행이 보일 수도 있습니다.
웹과 모바일 UI는 페이지네이션에 서로 다른 요구를 합니다. 웹 관리용 테이블은 특정 페이지로 건너뛰거나 여러 열로 정렬하는 것을 권장합니다. 모바일 화면은 보통 다음 청크를 불러오는 무한 리스트를 사용하며, 각 풀 동작이 동일하게 빠르길 기대합니다. API가 페이지 번호 기반으로만 설계되면 모바일이 고통받고, next/after 기반으로만 설계되면 웹 테이블이 제한적일 수 있습니다.
목표는 단순히 25개 항목을 반환하는 것이 아닙니다. 데이터가 커져도 빠르고 예측 가능한 페이징, 테이블과 무한 리스트 모두에 적용되는 규칙을 만드는 것입니다.
페이지네이션은 긴 목록을 작은 덩어리로 나누어 화면이 빠르게 로드하고 렌더링하도록 합니다. UI는 모든 레코드를 요청하는 대신 다음 결과 조각을 요청합니다.
가장 중요한 제어는 페이지 크기(종종 limit)입니다. 작은 페이지는 서버가 처리할 작업이 적고 앱이 렌더링할 행도 적으므로 보통 더 빠르게 느껴집니다. 하지만 너무 작은 페이지는 사용자가 더 자주 클릭하거나 스크롤해야 하므로 불편할 수 있습니다. 많은 관리자 테이블에서는 25~100개가 실용적 범위이며, 모바일은 보통 낮은 쪽을 선호합니다.
안정적인 정렬 순서는 대부분의 팀이 예상하는 것보다 중요합니다. 요청 사이에 순서가 바뀌면 사용자는 페이지를 넘기며 중복 또는 누락을 보게 됩니다. 안정적인 정렬은 보통 created_at 같은 기본 필드와 id 같은 타이브레이커를 포함합니다. 이는 오프셋이든 커서든 모두 중요합니다.
클라이언트 관점에서 페이지화된 응답은 항목, 다음 페이지 힌트(페이지 번호나 커서 토큰), 그리고 UI가 실제로 필요한 카운트만 포함해야 합니다. 어떤 화면은 “1-50 of 12,340” 같은 정확한 총계를 필요로 하고, 다른 화면은 has_more만 있으면 됩니다.
오프셋 페이지네이션은 고전적인 페이지 N 방식입니다. 클라이언트는 고정된 행 수를 요청하고 처음에 건너뛸 행 수를 API에 알려줍니다. limit과 offset으로 보이거나 서버가 오프셋으로 변환하는 page와 pageSize로 볼 수 있습니다.
일반적인 요청 예시는 다음과 같습니다:
GET /tickets?limit=50\u0026offset=950페이지 20으로 건너뛰거나 오래된 레코드를 조회하거나 큰 목록을 청크로 내보낼 때 유용합니다. 내부적으로도 설명하기 쉽습니다: “페이지 3을 보세요.”
문제는 깊은 페이지에서 나타납니다. 많은 데이터베이스는 특히 정렬 순서에 적절한 인덱스가 없을 때 건너뛴 행을 지나야 합니다. 페이지 1은 빠르지만 페이지 200은 눈에 띄게 느려질 수 있고, 사용자가 스크롤하거나 건너뛸 때 관리자 화면이 지연되는 이유가 됩니다.
또 다른 문제는 데이터가 변경될 때의 일관성입니다. 지원 매니저가 최신순으로 정렬된 티켓의 5페이지를 열어본다고 가정해보세요. 보는 사이에 새 티켓이 들어오거나 오래된 티켓이 삭제됩니다. 삽입은 항목을 앞으로 밀어 중복을 만들 수 있고, 삭제는 항목이 사라지게 합니다.
오프셋 페이지네이션은 작은 테이블, 안정된 데이터셋, 또는 일회성 내보내기에는 괜찮습니다. 하지만 큰 규모의 활발한 테이블에서는 곧 문제점이 드러납니다.
커서 페이지네이션은 북마크로서 커서를 사용합니다. “7페이지를 달라”가 아니라 “이 항목 뒤부터 계속해 달라”고 클라이언트가 말합니다. 커서는 보통 마지막 항목의 정렬 값(created_at, id 등)을 인코딩하여 서버가 정확한 위치에서 다시 시작할 수 있게 합니다.
요청은 보통 다음과 같습니다:
limit: 반환할 항목 수cursor: 이전 응답에서 받은 불투명 토큰(종종 after라고 불림)응답은 항목과 그 조각의 끝을 가리키는 새 커서를 반환합니다. 실무 차이는 커서가 데이터베이스에 행을 세고 건너뛰라고 요청하지 않는다는 점입니다. 대신 알려진 위치에서 시작하라고 요청합니다.
이 때문에 커서 페이지네이션은 앞으로 스크롤하는 리스트에서 빠르게 유지됩니다. 적절한 인덱스가 있으면 데이터베이스는 “X 이후 항목”으로 바로 건너뛴 다음 limit만큼 읽을 수 있습니다. 반면 오프셋은 오프셋이 커질수록 더 많은 행을 스캔하거나 건너뛰어야 할 때가 많습니다.
UI 관점에서 커서 페이지네이션은 “다음”이 자연스럽습니다: 반환된 커서를 다음 요청에 그대로 보냅니다. “이전”은 선택 사항이고 더 까다롭습니다. 일부 API는 before 커서를 지원하고, 다른 API는 역순으로 가져와 결과를 뒤집습니다.
선택은 사람들이 목록을 실제로 어떻게 사용하는지에서 시작합니다.
커서 페이지네이션은 주로 앞으로 이동하고 속도가 중요한 경우에 적합합니다: 활동 로그, 채팅, 주문, 티켓, 감사 기록, 대부분의 모바일 무한 스크롤. 새 행이 삽입되거나 삭제될 때에도 더 잘 동작합니다.
오프셋 페이지네이션은 사용자가 자주 이리저리 건너뛰는 클래식한 관리자 테이블(페이지 번호, 특정 페이지로 가기)이 있을 때 의미가 있습니다. 설명하기 쉽지만 큰 데이터셋에서는 느려지고 데이터가 변하면 덜 안정적입니다.
실용적인 판단 기준:
하이브리드는 흔합니다. 한 접근법은 속도를 위해 커서 기반 next/prev를 사용하고, 오프셋이 여전히 빠른 작은 필터된 부분집합에 대해 선택적 페이지 점프 모드를 제공하는 것입니다. 또 다른 방법은 캐시된 스냅샷을 기반으로 페이지 번호를 제공하는 커서 검색으로, 테이블이 친숙하게 느껴지게 하면서 모든 요청을 무겁게 만들지 않습니다.
관리자 UI는 모든 목록 엔드포인트가 동일하게 동작할 때 더 빠르게 느껴집니다. UI가 바뀌어도(API가 테이블인지 무한 스크롤인지), API 계약은 동일해야 각 화면마다 별도의 페이지네이션 규칙을 배울 필요가 없습니다.
실용적인 계약은 세 부분으로 구성됩니다: 행(items), 페이징 상태(paging state), 선택적 총계(totals). 엔드포인트 간 이름을 동일하게 유지하세요(tickets, users, orders 등). 내부 페이징 모드가 달라도 이름은 같게 유지합니다.
웹과 모바일 모두에 잘 맞는 응답 형태 예시는 다음과 같습니다:
{
"data": [ { "id": "...", "createdAt": "..." } ],
"page": {
"mode": "cursor",
"limit": 50,
"nextCursor": "...",
"prevCursor": null,
"hasNext": true,
"hasPrev": false
},
"totals": {
"count": 12345,
"filteredCount": 120
}
}
다음 세부 사항이 재사용을 쉽게 만듭니다:
page.mode는 서버가 어떤 방식을 사용하는지 알려주어 필드 이름을 바꾸지 않아도 됩니다.limit은 항상 요청한 페이지 크기입니다.nextCursor와 prevCursor는 하나가 null이라도 항상 존재합니다.totals는 선택적입니다. 비용이 크면 클라이언트가 요청할 때만 반환하세요.웹 테이블은 자체적으로 “페이지 3”을 계산해 API를 반복 호출하여 표시할 수 있고, 모바일 리스트는 페이지 번호를 무시하고 단순히 다음 청크를 요청하면 됩니다.
AppMaster로 웹과 모바일 관리자 UI를 모두 빌드하고 있다면, 이런 안정된 계약은 빠르게 효과를 발휘합니다. 같은 목록 동작을 여러 화면에서 재사용할 수 있어 엔드포인트마다 별도의 페이지네이션 로직을 만들 필요가 줄어듭니다.
정렬은 보통 페이지네이션을 깨뜨리는 지점입니다. 요청 사이에 순서가 바뀌면 사용자는 중복, 간격, 또는 “없는” 행을 보게 됩니다.
정렬을 제안이 아니라 계약으로 만드세요. 허용된 정렬 필드와 방향을 공개하고, 그렇지 않은 요청은 거부하세요. 이렇게 하면 예측 가능하고 개발 환경에서는 문제가 없어 보였던 느린 정렬 요청을 클라이언트가 요청하지 못하게 합니다.
안정적인 정렬은 고유한 타이브레이커를 필요로 합니다. 예를 들어 created_at으로 정렬할 때 두 레코드가 동일한 타임스탬프를 가질 수 있으므로 마지막 정렬 키로 id(또는 다른 고유 컬럼)를 추가하세요. 그렇지 않으면 데이터베이스는 동일한 값에 대해 임의의 순서를 반환할 수 있습니다.
실용적인 규칙:
created_at, updated_at, status, priority).id ASC).created_at DESC, id DESC) 클라이언트 전반에서 일관되게 유지하세요.정렬은 또한 커서 생성에 영향을 줍니다. 커서는 마지막 항목의 정렬 값을 순서대로 인코딩해야 하며, 타이브레이커도 포함되어야 다음 페이지에서 그 튜플 이후를 쿼리할 수 있습니다. 정렬이 변경되면 이전 커서는 무효가 됩니다. 정렬 매개변수를 커서 계약의 일부로 취급하세요.
필터는 페이지네이션과 분리되어야 합니다. UI는 “다른 집합의 행을 보여줘”라고 말한 다음에 “그 집합을 페이지네이션해 줘”라고 요청합니다. 필터 필드를 페이지네이션 토큰에 섞거나 필터를 선택적으로 검증하면 빈 페이지, 중복, 또는 커서가 갑자기 다른 데이터셋을 가리키는 등 디버그하기 어려운 동작이 생깁니다.
간단한 규칙: 필터는 평문 쿼리 파라미터에(또는 POST의 경우 요청 본문에) 두고, 커서는 해당 정확한 필터+정렬 조합에만 유효한 불투명한 토큰으로 하세요. 사용자가 어떤 필터(예: status, 날짜 범위, 담당자)를 변경하면 클라이언트는 이전 커서를 버리고 처음부터 시작해야 합니다.
허용되는 필터를 엄격하게 하세요. 성능을 보호하고 동작을 예측 가능하게 합니다:
총계는 많은 API를 느리게 만드는 지점입니다. 정확한 카운트는 특히 여러 필터가 있는 큰 테이블에서 비용이 큽니다. 보통 세 가지 옵션이 있습니다: 정확한 값, 추정값, 또는 없음. 정확한 값은 작은 데이터셋이나 사용자가 실제로 총계를 필요로 할 때 유용합니다. 추정은 관리자 화면에 충분한 경우가 많습니다. 필요 없다면 생략해도 됩니다.
모든 요청을 느리게 하지 않으려면 총계를 선택사항으로 만드세요: 클라이언트가 요청할 때만 계산(includeTotal=true 같은 플래그로), 필터 집합별로 잠시 캐시하거나 첫 페이지에서만 반환하세요.
기본값부터 시작하세요. 목록 엔드포인트는 안정적인 정렬 순서와 같은 값을 가진 행을 위한 타이브레이커가 필요합니다. 예: createdAt DESC, id DESC. 타이브레이커(id)는 새 레코드가 추가될 때 중복과 간격을 방지합니다.
요청 형식을 하나로 정의하고 지루하게 유지하세요. 일반 매개변수는 limit, cursor(또는 offset), sort, filters입니다. 두 모드를 모두 지원하면 상호 배타적으로 만드세요: 클라이언트는 cursor를 보내거나 offset을 보내지만 둘 다 보내면 안 됩니다.
응답 계약을 일관되게 유지해 웹과 모바일 UI가 같은 목록 로직을 공유하도록 하세요:
items: 레코드 페이지nextCursor: 다음 페이지를 가져올 커서(또는 null)hasMore: UI가 “더 불러오기”를 표시할지 결정하는 불리언total: 전체 일치 레코드 수(null, 카운팅이 비싸면 요청 시에만)구현은 두 접근법이 갈리는 지점입니다.
오프셋 쿼리는 보통 ORDER BY ... LIMIT ... OFFSET ...이고 큰 테이블에서 느려질 수 있습니다.
커서 쿼리는 마지막 항목을 기준으로 탐색 조건을 사용합니다: “(createdAt, id) 이 마지막 (createdAt, id)보다 작은 항목을 줘”. 이렇게 하면 데이터베이스가 인덱스를 사용해 성능을 안정적으로 유지할 수 있습니다.
출시 전에 다음 가드레일을 추가하세요:
limit을 제한하세요(예: 최대 100) 및 기본값 설정.sort를 허용 목록으로 검증하세요.cursor는 불투명하게 만들고 잘못된 커서는 거부하세요.total이 어떻게 요청되는지 결정하세요.데이터가 요청 사이에 변경되는 상황으로 테스트하세요. 요청 사이에 레코드를 생성하고 삭제하고 정렬에 영향을 주는 필드를 업데이트해 중복이나 누락이 발생하지 않는지 확인하세요.
지원 팀이 최신 티켓을 검토하려고 관리자 화면을 엽니다. 새 티켓이 들어오고 에이전트가 오래된 티켓을 업데이트해도 목록이 즉각적으로 느껴져야 합니다.
웹에서는 UI가 테이블입니다. 기본 정렬은 updated_at(최신 순)이고 팀은 보통 Open 또는 Pending으로 필터합니다. 같은 엔드포인트가 안정적인 정렬과 커서 토큰으로 두 시나리오를 모두 지원할 수 있습니다.
GET /tickets?status=open\u0026sort=-updated_at\u0026limit=50\u0026cursor=eyJ1cGRhdGVkX2F0IjoiMjAyNi0wMS0yNVQxMTo0NTo0MloiLCJpZCI6IjE2OTMifQ==
응답은 UI에 예측 가능한 형태로 남습니다:
{
"items": [{"id": 1693, "subject": "Login issue", "status": "open", "updated_at": "2026-01-25T11:45:42Z"}],
"page": {"next_cursor": "...", "has_more": true},
"meta": {"total": 128}
}
모바일에서는 같은 엔드포인트가 무한 스크롤을 지원합니다. 앱은 한 번에 20개의 티켓을 로드하고, 다음 배치를 가져오기 위해 next_cursor를 보냅니다. 페이지 번호 로직이 없고, 레코드가 변해도 이미 스크롤한 부분에서 놀라운 일이 적습니다.
핵심은 커서가 마지막으로 본 위치(예: updated_at과 타이브레이커로서 id)를 인코딩한다는 점입니다. 티켓이 사용자가 스크롤하는 동안 업데이트되면 다음 새로고침에서 위로 이동할 수 있지만, 이미 스크롤한 피드에서 중복이나 간격을 만들지는 않습니다.
총계는 유용하지만 큰 데이터셋에서는 비용이 큽니다. 간단한 규칙은 사용자가 필터를 적용했거나 명시적으로 요청했을 때만 meta.total을 반환하는 것입니다(status=open 같은 경우).
대부분의 페이지네이션 버그는 데이터베이스가 아니라 사소한 API 결정에서 옵니다. 테스트에서는 괜찮아 보이던 것이 요청 사이에 데이터가 변경되면 무너집니다.
가장 흔한 중복(또는 누락) 원인은 고유하지 않은 필드로 정렬하는 것입니다. created_at으로 정렬할 때 두 항목이 같은 타임스탬프를 가지면 요청 사이에 순서가 뒤바뀔 수 있습니다. 해결책은 간단합니다: 항상 기본 키 같은 안정적인 타이브레이커를 추가하고 정렬을 (created_at desc, id desc) 같은 쌍으로 취급하세요.
또 다른 흔한 문제는 클라이언트가 어떤 페이지 크기든 요청할 수 있게 하는 것입니다. 큰 요청 하나가 CPU, 메모리, 응답 시간을 급증시켜 모든 관리자 화면을 느려지게 합니다. 합리적인 기본값과 강제 최대값을 정하고 클라이언트가 더 많이 요청하면 오류를 반환하세요.
총계도 문제를 일으킬 수 있습니다. 모든 요청에서 일치하는 모든 행을 세는 것은 느려질 수 있으며 필터가 있을수록 최악입니다. UI가 총계를 필요로 한다면 요청할 때만 가져오거나(또는 추정값 반환) 전체 카운트에 UI를 블로킹하지 마세요.
가장 자주 문제를 만드는 실수:
필터나 정렬이 변경되면 페이지네이션을 리셋하세요. 새로운 필터는 새로운 검색으로 취급해 커서/오프셋을 지우고 처음부터 시작하세요.
API와 UI를 나란히 놓고 한 번만 실행해 보세요. 대부분의 문제는 목록 화면과 서버 간 계약에서 발생합니다.
created_at DESC, id DESC).limit)가 강제되는지.사람들이 매일 사용하는 관리자 목록 하나를 골라 그것을 골드 스탠더드로 만드세요. Tickets, Orders, Users 같은 바쁜 테이블이 좋은 출발점입니다. 그 엔드포인트가 빠르고 예측 가능해지면 동일한 계약을 다른 관리자 화면들로 복사하세요.
계약을 문서로 남기세요, 간단하더라도 좋습니다. API가 수락하는 것과 반환하는 것을 명시하면 UI 팀이 추측하지 않아 엔드포인트마다 다른 규칙을 실수로 만들지 않습니다.
모든 목록 엔드포인트에 적용할 간단한 표준:
id 같은 타이브레이커)items, 페이징 정보, 적용된 정렬/필터, totals)AppMaster로 이러한 관리자 화면을 빌드한다면(예: appmaster.io), 일찍 페이지네이션 계약을 표준화하는 것이 도움이 됩니다. 동일한 목록 동작을 웹 앱과 네이티브 모바일 앱 전반에서 재사용할 수 있어 나중에 페이지네이션 엣지 케이스를 쫓아다니는 데 드는 시간을 줄일 수 있습니다.
Offset pagination uses limit plus offset (or page/pageSize) to skip rows, so deeper pages often get slower as the database has to walk past more records. Cursor pagination uses an after token based on the last item’s sort values, so it can jump to a known position and stay fast as you keep moving forward.
Because page 1 is usually cheap, but page 200 forces the database to skip a large number of rows before it can return anything. If you also sort and filter, the work grows, so each click feels more like a new heavy query than a quick fetch.
Always use a stable sort with a unique tie-breaker, such as created_at DESC, id DESC or updated_at DESC, id DESC. Without the tie-breaker, records with the same timestamp can swap order between requests, which is a common cause of duplicates and “missing” rows.
Use cursor pagination for lists where people mostly move forward and speed matters, like activity logs, tickets, orders, and mobile infinite scroll. It stays consistent when new rows are inserted or deleted, because the cursor anchors the next page to an exact last-seen position.
Offset pagination fits best when “jump to page N” is a real UI feature and users regularly bounce around. It’s also convenient for small tables or stable datasets, where deep-page slowdown and shifting results are unlikely to matter.
Keep one response shape across endpoints and include the items, paging state, and optional totals. A practical default is returning items, a page object (with limit, nextCursor/prevCursor or offset), and a lightweight flag like hasNext so both web tables and mobile lists can reuse the same client logic.
Because exact COUNT(*) on large, filtered datasets can become the slowest part of the request and make every page change feel laggy. A good default is to make totals optional, return them only when requested, or return has_more when the UI only needs “Load more.”
Treat filters as part of the dataset, and treat the cursor as valid only for that exact filter and sort combination. If a user changes any filter or sort, reset pagination and start from the first page; reusing an old cursor after changes is a common way to get empty pages or confusing results.
Whitelist allowed sort fields and directions, and reject anything else so clients can’t accidentally request slow or unstable ordering. Prefer sorting on indexed fields and always append a unique tie-breaker like id to keep the order deterministic across requests.
Enforce a maximum limit, validate filters and sort parameters, and make cursor tokens opaque and strictly validated. If you’re building admin screens in AppMaster, keeping these rules consistent across all list endpoints makes it easier to reuse the same table and infinite-scroll behavior without custom pagination fixes per screen.





