BubbleCon 2024 の AppMaster: ノーコードトレンドを探る
AppMaster はニューヨークで開催された BubbleCon 2024 に参加し、洞察を獲得し、ネットワークを拡大し、ノーコード開発分野でイノベーションを推進する機会を模索しました。
Microsoft の Semantic Kernel SDK は、GPT のような大規模言語モデル (LLM) をコードに統合するプロセスを簡素化します。 LLM API にオペレーティング システムのような動作を提供し、複雑なプロンプトを管理し、操作を調整し、焦点を絞った出力を保証します。
Microsoft は Semantic Kernel SDK を導入し、GPT-4 などの大規模言語モデル (LLM) をコードに簡単に統合できるようにします。この SDK を使用すると、プロンプト、入力、および焦点を絞った出力を管理する複雑さが簡素化され、言語モデルと開発者の間のギャップが解消されます。
AI モデルをコードに統合するプロセスは、2 つの異なるコンピューティング方法の境界を越える必要があるため、非常に困難な場合があります。 LLM と対話するには、従来のプログラミング方法では不十分です。必要なのは、異なるドメイン間で変換する高レベルの抽象化であり、コンテキストを管理し、ソース データに基づいた出力を維持する方法を提供します。
数週間前、Microsoft は Prompt Engine と呼ばれる最初の LLM ラッパーをリリースしました。そこから構築されたソフトウェアの巨人は、Azure OpenAI と OpenAI の API を操作するための、より強力な C# ツールである Semantic Kernel を発表しました。このオープンソース ツールは、いくつかのサンプル アプリケーションと共に GitHub で入手できます。
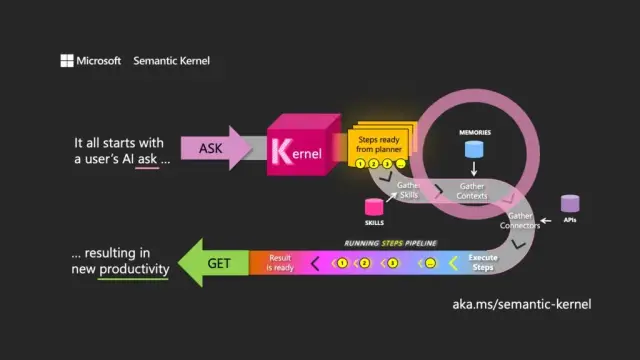
名前の選択は、LLM の主な目的を理解していることを意味します。セマンティック カーネルは、最初のユーザー リクエスト (ask) を使用してモデルを指示し、関連付けられたリソースを介してパスを調整し、リクエストを実行してレスポンスを返す (get) ことにより、自然言語の入力と出力に焦点を当てています。
セマンティック カーネルは、LLM API のオペレーティング システムのように機能し、入力を受け取り、言語モデルを操作してそれらを処理し、出力を返します。カーネルのオーケストレーションの役割は、プロンプトとそれに関連付けられたトークンだけでなく、メモリ、他の情報サービスへのコネクタ、およびプロンプトと従来のコードを組み合わせた事前定義されたスキルの管理にも不可欠です。
セマンティック カーネルは、メモリの概念を通じてコンテキストを管理し、ファイルとキーと値のストレージを操作します。 3 番目のオプションである セマンティック メモリは、コンテンツをベクトルまたは埋め込みとして扱います。これは、LLM がテキストの意味を表すために使用する数値の配列です。これらの埋め込まれたベクトルは、基になるモデルが関連性、一貫性を維持し、ランダムな出力を生成する可能性を減らすのに役立ちます。
埋め込みを使用することで、開発者は大きなプロンプトをテキストのブロックに分割して、リクエストに使用できるトークンを使い果たすことなく、より焦点を絞ったプロンプトを作成できます (たとえば、GPT-4 では、入力ごとに 8,192 トークンの制限があります)。
コネクタは セマンティック カーネルで重要な役割を果たし、既存の API と LLM を統合できます。たとえば、Microsoft Graph コネクタは、要求の出力を電子メールで送信したり、組織図で関係の説明を作成したりできます。コネクタは、ロールベースのアクセス制御の形式も提供し、データに基づいて出力がユーザーに合わせて調整されるようにします。
セマンティック カーネルの 3 番目の主要コンポーネントは スキル です。これは、Azure 関数と同様に、LLM プロンプトと従来のコードを組み合わせた関数のコンテナーです。それらを使用して、特殊なプロンプトを連鎖させ、LLM を利用したアプリケーションを作成できます。
ある関数の出力を別の関数に連鎖させることができるため、ネイティブ処理と LLM 操作を組み合わせた関数のパイプラインを構築できます。このようにして、開発者は必要に応じて選択して利用できる柔軟なスキルを構築できます。
セマンティック カーネルは強力なツールですが、効果的なアプリケーションを作成するには慎重な検討と計画が必要です。 SDK をネイティブ コードと一緒に戦略的に使用することで、開発者は LLM の可能性を活用し、開発プロセスをより効率的かつ生産的にすることができます。開始を支援するために、Microsoft は、自社内で LLM アプリケーションを構築することから学んだベスト プラクティス ガイドラインのリストを提供しています。
最新のソフトウェア開発のコンテキストでは、Microsoft の Semantic Kernel SDK は、さまざまなアプリケーションで大規模な言語モデルを統合するための重要なイネーブラーとしての地位を確立しています。その実装は、 AppMasterのno-codeプラットフォームや Web サイト ビルダーなど のツールに大きなメリットをもたらし、幅広いユーザーにより柔軟で効率的なソリューションを提供します。



Experiment with AppMaster with free plan.
When you will be ready you can choose the proper subscription.


