Ứng dụng đặt thiết bị: ngăn xung đột và theo dõi việc trả
Lập kế hoạch cho ứng dụng đặt thiết bị giúp ngăn việc đặt trùng, ghi nhận trả và hư hỏng, đồng thời đưa thiết bị lỗi vào trạng thái tạm giữ để bảo trì.
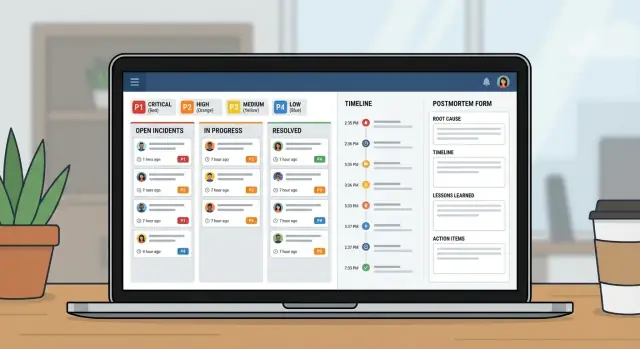
Lập kế hoạch và xây dựng ứng dụng quản lý sự cố nội bộ cho đội IT với quy trình theo mức độ nghiêm trọng, phân công rõ ràng, dòng thời gian và báo cáo hậu sự cố trong một công cụ duy nhất.
Khi một sự cố xảy ra, hầu hết các đội sẽ dùng bất cứ thứ gì đang mở: một luồng chat, chuỗi email, có thể là một bảng tính ai đó cập nhật khi rảnh. Dưới áp lực, cái setup đó vỡ theo cùng những cách: quyền sở hữu mơ hồ, dấu thời gian biến mất, và quyết định trôi mất trong cuộn tin.
Một ứng dụng quản lý sự cố đơn giản sửa được những điều cơ bản. Nó cho bạn một nơi duy nhất để lưu sự cố, với một người chịu trách nhiệm rõ ràng, mức độ nghiêm trọng mà mọi người đồng ý, và một dòng thời gian ghi lại chuyện gì đã xảy ra và khi nào. Bản ghi duy nhất đó quan trọng vì cùng những câu hỏi đó luôn xuất hiện trong mọi sự cố: Ai đang dẫn dắt? Khi nào nó bắt đầu? Trạng thái hiện tại là gì? Đã thử những gì rồi?
Không có bản ghi chung đó, việc bàn giao lãng phí thời gian. Hỗ trợ nói với khách hàng một điều trong khi engineering làm điều khác. Quản lý hỏi cập nhật kéo người phản hồi ra khỏi việc sửa. Sau đó, không ai có thể tái tạo dòng thời gian với độ tin cậy, nên báo cáo hậu sự cố trở thành suy đoán.
Mục tiêu không phải thay thế hệ thống giám sát, chat hay ticket của bạn. Cảnh báo vẫn có thể bắt nguồn từ nơi khác. Ý là ghi lại dấu vết quyết định và giữ con người đồng bộ.
IT operations và kỹ sư trực ca dùng nó để phối hợp phản ứng. Hỗ trợ dùng nó để đưa cập nhật chính xác nhanh. Quản lý dùng nó để thấy tiến độ mà không làm gián đoạn người đang xử lý.
Lúc 9:12 sáng, hệ thống giám sát phát hiện tăng đột biến lỗi 500 trên cổng khách hàng. Một nhân viên hỗ trợ cũng báo: “Đăng nhập thất bại với phần lớn người dùng.” Trưởng ca IT mở một sự cố P1 trong ứng dụng và đính kèm cảnh báo đầu tiên cùng ảnh chụp màn hình từ hỗ trợ.
Với P1, hành vi thay đổi nhanh. Chủ sự cố mời owner backend, owner cơ sở dữ liệu và một liên lạc hỗ trợ vào. Công việc không cần thiết tạm dừng. Các triển khai có kế hoạch dừng lại. Nhóm thống nhất tần suất cập nhật (ví dụ, mỗi 15 phút). Bắt đầu một cuộc gọi chung, nhưng bản ghi sự cố vẫn là nguồn chân lý.
Đến 9:18, ai đó hỏi, “Có gì thay đổi không?” Dòng thời gian cho thấy một deploy lúc 8:57, nhưng không ghi chi tiết đã triển khai gì. Owner backend vẫn rollback. Lỗi giảm, rồi quay lại. Lúc này nhóm nghi ngờ cơ sở dữ liệu.
Hầu hết trì hoãn xuất hiện ở vài chỗ dễ đoán: bàn giao mơ hồ (“Tôi tưởng bạn đang kiểm tra”), bối cảnh thiếu (thay đổi gần đây, rủi ro đã biết, owner hiện tại), và các cập nhật rải rác trên chat, ticket và email.
Lúc 9:41, owner cơ sở dữ liệu tìm thấy một truy vấn chạy mất kiểm soát do công việc định kỳ gây ra. Họ vô hiệu hóa công việc, khởi động lại dịch vụ bị ảnh hưởng và xác nhận đã phục hồi. Mức độ được hạ xuống P2 để theo dõi.
Đóng tốt không phải là “nó chạy lại được.” Là một bản ghi sạch: dòng thời gian từng phút, nguyên nhân gốc cuối cùng, ai quyết định việc gì, điều gì đã bị tạm dừng, và công việc tiếp theo với chủ sở hữu và hạn hoàn thành. Đó là cách một P1 căng thẳng trở thành bài học thay vì đau lặp lại.
Một công cụ sự cố tốt phần lớn là một mô hình dữ liệu tốt. Nếu bản ghi mơ hồ, mọi người sẽ tranh cãi về sự cố là gì, khi nào nó bắt đầu, và những gì còn mở.
Giữ các thực thể cốt lõi gần với cách các đội IT đã nói:
Để tránh nhầm lẫn về sau, cho Incident vài trường cấu trúc luôn phải được điền. Văn bản tự do có ích, nhưng không nên là nguồn chân lý duy nhất. Tối thiểu thực tế là: tiêu đề rõ ràng, tác động (người dùng trải nghiệm gì), dịch vụ bị ảnh hưởng, thời gian bắt đầu, trạng thái hiện tại, và mức độ nghiêm trọng.
Quan hệ quan trọng hơn các trường phụ. Một incident nên có nhiều updates và nhiều tasks, cùng liên kết nhiều-nhiều với services (vì sự cố thường ảnh hưởng nhiều hệ thống). Một postmortem nên là một-một với incident, để chỉ có một câu chuyện cuối cùng.
Ví dụ: một incident “Lỗi thanh toán” liên kết với Services “Payments API” và “PostgreSQL,” có cập nhật mỗi 15 phút, và các task như “Rollback deploy” và “Thêm cơ chế retry.” Sau đó, postmortem ghi nhận nguyên nhân gốc và tạo các task dài hạn.
Khi mọi người căng thẳng, họ cần nhãn đơn giản có cùng ý nghĩa với tất cả. Định nghĩa P1 đến P4 bằng ngôn ngữ rõ ràng và hiển thị định nghĩa ngay cạnh trường mức độ.
Mục tiêu phản hồi nên đọc như cam kết. Một nền tảng đơn giản (điều chỉnh theo thực tế của bạn):
| Mức độ | Phản hồi đầu tiên (ack) | Cập nhật đầu tiên | Tần suất cập nhật |
|---|---|---|---|
| P1 | 5 phút | 15 phút | mỗi 30 phút |
| P2 | 15 phút | 30 phút | mỗi 60 phút |
| P3 | 4 giờ | 1 ngày làm việc | hàng ngày |
| P4 | 2 ngày làm việc | 1 tuần | hàng tuần |
Giữ quy tắc thang cấp cơ học. Nếu một P2 trễ lịch cập nhật hoặc tác động tăng, hệ thống nên nhắc xem xét lại mức độ. Để tránh xáo trộn, giới hạn ai có thể thay đổi mức độ (thường là owner hoặc incident commander), nhưng vẫn cho phép ai cũng có thể yêu cầu xem xét trong một bình luận.
Một ma trận tác động nhanh cũng giúp chọn mức độ nhanh. Ghi lại nó dưới dạng vài trường bắt buộc: số người dùng bị ảnh hưởng, rủi ro doanh thu, an toàn, tuân thủ/bảo mật, và có hay không giải pháp thay thế.
Trong sự cố, mọi người không cần thêm tùy chọn. Họ cần một tập trạng thái nhỏ khiến bước tiếp theo trở nên rõ ràng.
Bắt đầu với các bước bạn đã làm vào ngày thường tốt, rồi giữ danh sách ngắn. Nếu có hơn 6–7 trạng thái, đội sẽ tranh cải về cách đặt tên thay vì sửa vấn đề.
Một bộ trạng thái thực tế:
Mỗi trạng thái cần luật vào/ra rõ ràng. Ví dụ:
Dùng các chuyển trạng thái để bắt buộc các trường mà mọi người hay quên. Quy tắc phổ biến: không thể đóng sự cố nếu không có tóm tắt nguyên nhân gốc ngắn và ít nhất một mục follow-up. Nếu cho phép “RCA: TBD”, nó thường sẽ giữ nguyên như vậy.
Trang sự cố nên trả lời ba câu hỏi thoáng nhìn: ai là chủ sự cố, hành động tiếp theo là gì, và khi nào cập nhật cuối được đăng.
Khi sự cố ồn ào, cách nhanh nhất để mất thời gian là quyền sở hữu mơ hồ. Ứng dụng của bạn nên làm cho một người rõ ràng chịu trách nhiệm, trong khi vẫn dễ cho người khác hỗ trợ.
Một mẫu đơn giản bền vững:
Việc phân công nên rõ ràng và có thể kiểm toán. Ghi ai đặt owner, ai chấp nhận, và mọi thay đổi sau đó. “Chấp nhận” quan trọng, vì giao ai đó đang ngủ hoặc offline không phải là ownership thực sự.
Phân công theo on-call hay theo đội thường phụ thuộc vào mức độ. Với P1/P2, mặc định dùng luân phiên on-call để luôn có chủ sở hữu có tên. Với mức thấp hơn, phân công theo đội vẫn ổn, nhưng vẫn yêu cầu một primary owner trong một khoảng thời gian ngắn.
Lên kế hoạch cho kỳ nghỉ và mất tích nhân sự trong quy trình con người, không chỉ trong hệ thống. Nếu người được giao đánh dấu là unavailable, định tuyến tới on-call phụ hoặc trưởng nhóm. Giữ tự động nhưng hiển thị để dễ sửa nhanh.
Thang cấp nên kích hoạt theo cả mức độ và im lặng. Một khởi điểm hữu ích:
Một dòng thời gian tốt là ký ức chung. Trong sự cố, bối cảnh biến mất nhanh. Nếu bạn ghi đúng khoảnh khắc ở một nơi, việc chuyển giao dễ hơn và postmortem hầu như đã được viết trước khi ai đó mở tài liệu.
Giữ dòng thời gian có quan điểm. Đừng biến nó thành bản ghi chat. Phần lớn đội dựa vào một tập mục nhỏ: phát hiện, xác nhận, bước giảm thiểu chính, khôi phục và đóng.
Mỗi mục cần dấu thời gian, tác giả và mô tả ngắn bằng ngôn ngữ đơn giản. Người vào muộn nên đọc năm mục và hiểu đang xảy ra gì.
Các cập nhật khác nhau phục vụ khán giả khác nhau. Có ích khi các mục có loại, ví dụ internal note (chi tiết thô), customer-facing update (diễn đạt an toàn), decision (tại sao chọn phương án A), và handoff (cái tiếp theo người khác phải biết).
Nhắc nhở nên theo mức độ, không theo sở thích cá nhân. Nếu hẹn giờ chạm mốc, nhắc chủ sở hữu hiện tại trước, rồi thang cấp nếu lặp lại bỏ lỡ.
Thông báo nên có mục tiêu và dự đoán được. Một tập luật nhỏ thường đủ: thông báo khi tạo, khi thay đổi mức độ, khi khôi phục và khi cập nhật quá hạn. Tránh thông báo cả công ty cho mọi thay đổi.
Báo cáo hậu sự cố nên làm hai việc: giải thích chuyện gì đã xảy ra bằng ngôn ngữ đơn giản, và làm cho sự thất bại tương tự ít có khả năng lặp lại.
Giữ bài viết ngắn, và buộc kết quả thành hành động. Cấu trúc thực tế gồm: tóm tắt, tác động với khách hàng, nguyên nhân gốc, các sửa trong lúc xử lý, và các follow-up.
Follow-up là điểm mấu chốt. Đừng để chúng như một đoạn văn ở cuối. Biến mỗi follow-up thành một task được theo dõi với chủ sở hữu và hạn hoàn thành, ngay cả khi hạn là “sprint sau.” Đó là sự khác biệt giữa “chúng ta nên cải thiện giám sát” và “Alex thêm alert saturation DB trước thứ Sáu.”
Thẻ (tags) làm cho postmortem có ích về sau. Thêm 1–3 chủ đề cho mỗi sự cố (thiếu giám sát, triển khai, thiếu capacity, quy trình). Sau một tháng, bạn có thể trả lời câu hỏi cơ bản như phần lớn P1 đến từ release hay thiếu cảnh báo.
Chứng cứ nên dễ đính kèm, không bắt buộc. Hỗ trợ các trường tuỳ chọn cho ảnh chụp màn hình, đoạn log, và tham chiếu tới hệ thống ngoài (ID ticket, luồng chat, số case nhà cung cấp). Giữ nhẹ để người ta thực sự điền vào.
Xem việc này như một sản phẩm nhỏ, không phải một bảng tính thêm vài cột. Một app sự cố tốt thực tế có ba view: gì đang diễn ra, nên làm gì tiếp theo, và học được gì sau cùng.
Bắt đầu bằng phác thảo các màn hình người ta sẽ mở khi có áp lực:
Xây mô hình dữ liệu và quyền truy cập cùng lúc. Nếu ai cũng sửa mọi thứ, lịch sử sẽ lộn xộn. Cách phổ biến: quyền xem rộng cho IT, kiểm soát thay đổi trạng thái/mức độ, người phản hồi có thể thêm cập nhật, và một owner rõ ràng để phê duyệt postmortem.
Rồi thêm quy tắc luồng công việc để ngăn các sự cố bị điền nửa vời. Trường bắt buộc nên phụ thuộc vào trạng thái. Có thể cho phép “New” chỉ cần tiêu đề và người báo, nhưng yêu cầu “Mitigating” phải có tóm tắt tác động, và yêu cầu “Resolved” phải có tóm tắt nguyên nhân gốc cộng ít nhất một follow-up.
Cuối cùng, thử bằng cách phát lại 2–3 sự cố trong quá khứ. Giao cho một người làm incident commander và một người làm responder. Bạn sẽ nhanh thấy trạng thái nào mơ hồ, trường nào bị bỏ qua, và nơi cần mặc định tốt hơn.
Hầu hết hệ thống sự cố thất bại vì lý do đơn giản: mọi người quên quy tắc khi căng thẳng, và app không ghi lại các dữ kiện bạn cần sau này.
Nếu bạn có sáu mức độ và mười trạng thái, mọi người sẽ đoán. Giữ mức độ 3–4 và trạng thái tập trung vào việc nên làm tiếp theo.
Khi ai cũng “theo dõi”, không ai dẫn dắt. Yêu cầu một chủ sở hữu tên trước khi sự cố tiến, và làm cho việc bàn giao rõ ràng.
Nếu “chuyện gì xảy ra khi” dựa vào lịch sử chat, postmortem thành tranh cãi. Tự động ghi lại thời điểm mở, xác nhận, giảm thiểu và đóng, và giữ các mục dòng thời gian ngắn.
Cũng tránh đóng bằng các ghi chú nguyên nhân mơ hồ như “vấn đề mạng.” Yêu cầu một câu nguyên nhân gốc rõ ràng và ít nhất một bước tiếp theo cụ thể.
Trước khi triển khai cho cả tổ chức IT, stress test các điều cơ bản. Nếu người dùng không tìm thấy nút đúng trong hai phút đầu, họ sẽ quay lại chat và bảng tính.
Tập trung vào một bộ kiểm tra ra mắt ngắn: vai trò và quyền, định nghĩa mức độ rõ ràng, bắt buộc ownership, quy tắc nhắc nhở, và đường thang cấp khi lỡ các mục tiêu phản hồi.
Thí điểm với một đội và vài dịch vụ hay tạo cảnh báo. Chạy hai tuần, rồi điều chỉnh dựa trên các sự cố thực tế.
Nếu bạn muốn xây cái này như một công cụ nội bộ duy nhất mà không phải ghép bảng tính và nhiều app, AppMaster (appmaster.io) là một lựa chọn. Nó cho phép bạn tạo mô hình dữ liệu, quy tắc luồng công việc và giao diện web/mobile trong một chỗ, phù hợp với hàng đợi sự cố, trang sự cố và theo dõi postmortem.
Nó thay thế các cập nhật rải rác bằng một hồ sơ chung trả lời nhanh các câu hỏi cơ bản: ai chịu trách nhiệm, người dùng đang gặp trải nghiệm gì, những gì đã thử, và bước tiếp theo là gì. Điều này giảm thời gian lãng phí vì chuyển giao, thông điệp mâu thuẫn, và các yêu cầu “bạn tóm tắt lại được không?” làm gián đoạn.
Mở sự cố ngay khi bạn tin rằng có tác động thực sự đến khách hàng hoặc doanh nghiệp, ngay cả khi nguyên nhân gốc chưa rõ. Bạn có thể mở với tiêu đề nháp và ghi “tác động chưa rõ”, rồi bổ sung chi tiết khi xác nhận mức độ và phạm vi.
Giữ gọn và có cấu trúc: tiêu đề rõ ràng, tóm tắt tác động, dịch vụ bị ảnh hưởng, thời gian bắt đầu, trạng thái hiện tại, mức độ nghiêm trọng và một người chịu trách nhiệm duy nhất. Thêm cập nhật và nhiệm vụ khi sự việc tiến triển, nhưng đừng chỉ dựa vào văn bản tự do cho các thông tin cốt lõi.
Dùng 3 đến 4 mức với nghĩa rõ ràng, không cần tranh luận. Mặc định tốt: P1 cho sập dịch vụ chính hoặc rủi ro mất dữ liệu, P2 cho chức năng lớn bị ảnh hưởng nhưng có biện pháp tạm thời hoặc phạm vi giới hạn, P3 cho vấn đề tác động nhỏ hơn, P4 cho lỗi nhỏ hoặc thẩm mỹ.
Theo dõi những cam kết rõ ràng: thời gian để xác nhận, thời gian cập nhật đầu tiên, và tần suất cập nhật. Sau đó kích hoạt nhắc nhở và thang cấp khi lịch cập nhật bị bỏ lỡ, vì “im lặng” thường là lỗi thực sự trong sự cố.
Nhắm đến khoảng sáu trạng thái: New, Acknowledged, Investigating, Mitigating, Monitoring và Resolved. Mỗi trạng thái nên làm rõ bước tiếp theo, và các chuyển trạng thái nên bắt buộc các trường mà mọi người thường quên khi căng thẳng, ví dụ yêu cầu có chủ sở hữu trước khi chuyển sang Acknowledged hoặc yêu cầu tóm tắt nguyên nhân gốc trước khi đóng.
Yêu cầu một chủ sở hữu chính chịu trách nhiệm dẫn dắt phản ứng và đăng cập nhật. Ghi nhận việc chấp nhận rõ ràng để bạn không “giao” cho người đang ngoại tuyến, và làm cho việc chuyển giao thành một sự kiện được ghi lại để người tiếp theo không phải bắt đầu điều tra lại từ đầu.
Ghi lại chỉ những thời điểm quan trọng: phát hiện, xác nhận, quyết định chính, các bước giảm thiểu, khôi phục và đóng, mỗi mục có dấu thời gian và tác giả. Xử lý nó như ký ức chung chứ không phải nhật ký chat, để người mới vào có thể nắm bắt trong vài phút.
Giữ ngắn gọn và tập trung vào hành động: chuyện gì đã xảy ra, tác động với khách hàng, nguyên nhân gốc, những gì đã thay đổi trong quá trình giảm thiểu, và các công việc tiếp theo với chủ sở hữu và hạn hoàn thành. Bản viết hữu ích, nhưng các tác vụ được theo dõi mới là thứ ngăn chặn sự cố lặp lại.
Có. Nếu bạn mô hình hóa incidents, updates, tasks, services và postmortems là dữ liệu thực và thi hành quy tắc luồng công việc trong app, bạn có thể tránh việc ghép nhiều hệ thống. Với AppMaster, các nhóm có thể xây dựng mô hình dữ liệu, giao diện web/mobile và các xác thực theo trạng thái trong cùng một nơi, giúp quy trình không quay lại bảng tính khi căng thẳng.



Thử nghiệm với AppMaster với gói miễn phí.
Khi bạn sẵn sàng, bạn có thể chọn đăng ký phù hợp.


