Ứng dụng đặt thiết bị: ngăn xung đột và theo dõi việc trả
Lập kế hoạch cho ứng dụng đặt thiết bị giúp ngăn việc đặt trùng, ghi nhận trả và hư hỏng, đồng thời đưa thiết bị lỗi vào trạng thái tạm giữ để bảo trì.
Luồng công việc chạy lâu có thể lỗi theo nhiều cách lộn xộn. Học các mẫu trạng thái rõ ràng, bộ đếm retry, xử lý dead-letter và dashboard mà người vận hành có thể tin tưởng.
Luồng công việc chạy lâu thất bại khác với những yêu cầu nhanh. Một cuộc gọi API ngắn sẽ thành công hoặc lỗi ngay lập tức. Một luồng chạy vài giờ hoặc vài ngày có thể hoàn thành 9 bước trong 10 và vẫn để lại mớ hỗn độn: bản ghi tạo dở, trạng thái rối rắm, và không có hành động tiếp theo rõ ràng.
Đó là lý do vì sao “hôm qua vẫn chạy tốt” thường được nhắc tới. Luồng không thay đổi, nhưng môi trường thì có thể. Luồng chạy lâu phụ thuộc các dịch vụ khác phải duy trì khỏe, thông tin đăng nhập còn hợp lệ, và dữ liệu còn đúng định dạng mà luồng mong đợi.
Các dạng hỏng phổ biến thường là: timeout và phụ thuộc chậm (API đối tác hoạt động nhưng hôm nay mất 40 giây), cập nhật một phần (ghi A xong, ghi B chưa xong và không thể chạy lại an toàn), ngưng trệ phụ thuộc (nhà cung cấp email/SMS, cổng thanh toán, cửa sổ bảo trì), callback bị mất và lịch trình trượt (webhook không bao giờ tới, job timer không chạy), và bước có con người bị tắc (phê duyệt đứng vài ngày rồi tiếp tục với giả định đã lỗi thời).
Điều khó nhất là trạng thái. Một “yêu cầu nhanh” có thể giữ trạng thái trong bộ nhớ cho đến khi hoàn thành. Một luồng thì không. Nó phải lưu trạng thái giữa các bước và sẵn sàng tiếp tục sau khi khởi động lại, deploy hoặc crash. Nó cũng phải xử lý trường hợp cùng bước bị kích hoạt hai lần (retry, webhook trùng, replay của operator).
Trong thực tế, “đáng tin cậy” ít liên quan đến không bao giờ lỗi mà nhiều hơn là dễ dự đoán, dễ giải thích, dễ khôi phục và có chủ sở hữu rõ ràng.
Dự đoán được nghĩa là luồng phản ứng cùng cách mỗi lần khi phụ thuộc thất bại. Giải thích được nghĩa là một người vận hành có thể trả lời trong một phút: “Nó đang kẹt ở đâu và vì sao?” Khôi phục được nghĩa là bạn có thể thử lại hoặc tiếp tục an toàn mà không gây hại. Có chủ sở hữu rõ ràng nghĩa là mọi mục bị kẹt đều có hành động tiếp theo rõ ràng: đợi, thử lại, sửa dữ liệu, hoặc chuyển cho con người.
Ví dụ đơn giản: một automation onboarding tạo bản ghi khách hàng, cấp quyền truy cập và gửi thông báo chào mừng. Nếu cấp quyền thành công nhưng gửi tin nhắn thất bại vì nhà cung cấp email bị xuống, luồng đáng tin sẽ ghi “Provisioned, message pending” và lên lịch thử lại. Nó không chạy lại phần provisioning một cách mù quáng.
Công cụ có thể giúp bằng cách giữ logic luồng và dữ liệu bền gần nhau. Ví dụ, AppMaster cho phép bạn mô hình trạng thái luồng trong dữ liệu (qua Data Designer) và cập nhật từ Business Processes trực quan. Nhưng độ tin cậy đến từ mẫu thiết kế, chứ không phải công cụ: coi tự động hóa chạy lâu như một chuỗi trạng thái bền vững có thể tồn tại qua thời gian, thất bại và can thiệp của con người.
Luồng công việc chạy lâu có xu hướng thất bại theo cách lặp lại: API bên thứ ba chậm lại, con người chưa phê duyệt, hoặc job chờ sau hàng đợi. Trạng thái rõ ràng làm cho những tình huống đó hiển nhiên, để người ta không nhầm “đang mất thời gian” với “bị hỏng.”
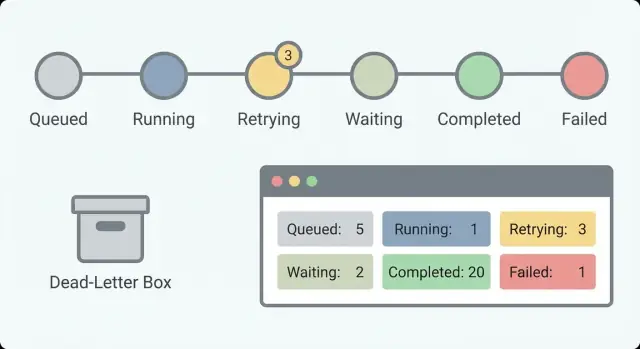
Bắt đầu với một tập trạng thái nhỏ trả lời một câu hỏi: bây giờ đang xảy ra gì? Nếu bạn có 30 trạng thái, chẳng ai nhớ được. Với khoảng 5 đến 8, người trực có thể quét qua danh sách và hiểu nhanh.
Một bộ trạng thái thực tế phù hợp cho nhiều luồng:
Tách Waiting khỏi Running rất quan trọng. “Đang chờ phản hồi khách hàng” là bình thường. “Đang chạy 6 giờ” có thể là treo. Nếu không tách, bạn sẽ đuổi theo báo động giả và bỏ lỡ cảnh báo thực.
Một tên trạng thái không đủ. Thêm vài trường biến một trạng thái thành thứ có thể hành động:
Ví dụ: luồng onboarding có thể hiển thị “Đang chờ” với lý do “Chờ phê duyệt quản lý” và thay đổi lần cuối “2 ngày trước.” Điều đó nói lên nó không bị treo, nhưng có thể cần một lời nhắc.
Đối xử tên trạng thái như API. Nếu bạn đổi tên mỗi tháng, dashboard, cảnh báo và playbook hỗ trợ sẽ nhanh chóng sai lệch. Nếu cần ý nghĩa mới, hãy cân nhắc thêm trạng thái mới và giữ trạng thái cũ cho các bản ghi hiện có.
Trong AppMaster, bạn có thể mô hình các trạng thái này trong Data Designer và cập nhật chúng từ Business Process. Điều đó giữ trạng thái hiển thị và nhất quán trong toàn app thay vì chôn trong log.
Retry hữu ích cho đến khi chúng che dấu vấn đề thực sự. Mục tiêu không phải “không bao giờ lỗi” mà là “lỗi theo cách người ta hiểu và sửa được.” Điều đó bắt đầu bằng quy tắc rõ ràng về lỗi nào nên thử lại và lỗi nào không.
Quy tắc nhiều đội có thể sống với: thử lại những lỗi khả năng tạm thời (timeout mạng, bị giới hạn tần suất, sự cố bên thứ ba ngắn). Đừng thử lại những lỗi rõ ràng vĩnh viễn (dữ liệu không hợp lệ, thiếu quyền, “tài khoản đóng”, “thẻ bị từ chối”). Nếu bạn không biết lỗi thuộc nhóm nào, coi nó là không retry cho đến khi hiểu thêm.
Theo dõi bộ đếm retry theo từng bước (hoặc theo cuộc gọi ra ngoài), chứ không chỉ một bộ đếm cho cả luồng. Một luồng có thể có mười bước, và chỉ một bước có thể dễ lỗi. Bộ đếm theo bước ngăn bước sau “ăn” lượt thử từ bước trước.
Ví dụ, thao tác “Upload document” có thể được thử lại vài lần, trong khi “Gửi email chào mừng” không nên thử mãi vì upload đã dùng hết lượt thử trước đó.
Chọn mẫu backoff phù hợp với rủi ro. Delay cố định có thể ổn cho retry đơn giản, chi phí thấp. Exponential backoff hữu ích khi bạn có thể bị giới hạn tần suất. Thêm giới hạn để chờ không tăng vô hạn, và thêm chút jitter để tránh bão retry.
Rồi quyết định khi nào dừng. Điều kiện dừng tốt là rõ ràng: tối đa số lần thử, tổng thời gian tối đa, hoặc “bỏ cuộc cho mã lỗi nhất định.” Cổng thanh toán trả “thẻ không hợp lệ” nên dừng ngay cả khi bạn thường cho phép năm lần thử.
Người vận hành cũng cần biết chuyện gì sẽ xảy ra tiếp theo. Ghi lại thời gian thử tiếp theo và lý do (ví dụ: “Retry 3/5 lúc 14:32 do timeout”). Trong AppMaster, bạn có thể lưu điều này trên bản ghi luồng để dashboard hiển thị “chờ tới” mà không phải đoán.
Chính sách retry tốt để lại dấu vết: gì đã thất bại, đã thử bao nhiêu lần, khi nào thử lại, và khi nào dừng và chuyển sang xử lý dead-letter.
Trong luồng chạy giờ hoặc ngày, retry là bình thường. Rủi ro là lặp lại một bước đã thực sự thành công. Idempotency là quy tắc làm cho việc này an toàn: một bước là idempotent nếu chạy hai lần có cùng hiệu quả như chạy một lần.
Một lỗi kinh điển: bạn đã charge thẻ, rồi luồng crash trước khi lưu “payment succeeded.” Khi retry, nó charge lần nữa. Đó là vấn đề ghi đôi: thế giới bên ngoài đã thay đổi nhưng trạng thái luồng của bạn thì chưa.
Mẫu an toàn nhất là tạo idempotency key ổn định cho mỗi bước gây tác động, gửi nó cùng cuộc gọi ra ngoài và lưu kết quả bước ngay khi nhận. Nhiều nhà cung cấp thanh toán và webhook hỗ trợ idempotency key (ví dụ charge theo OrderID). Nếu bước lặp lại, nhà cung cấp trả kết quả ban đầu thay vì thực hiện hành động thêm.
Trong engine luồng, giả định mọi bước có thể được replay. Trong AppMaster, điều đó thường nghĩa là lưu output bước vào mô hình database và kiểm tra chúng trong Business Process trước khi gọi tích hợp lần nữa. Nếu “Gửi email chào mừng” đã có MessageID, lần retry nên tái dùng bản ghi đó và tiếp tục.
Một cách tiếp cận an toàn với trùng lặp:
Trùng lặp vẫn xảy ra, đặc biệt với webhook đến hoặc khi người dùng bấm nút cùng lúc. Quyết định chính sách theo loại sự kiện: bỏ qua hoàn toàn trùng lặp (same idempotency key), gộp cập nhật tương thích (last-write-wins cho trường profile), hoặc đánh dấu để xem xét khi liên quan tiền bạc hoặc rủi ro tuân thủ.
Dead-letter là mục luồng đã thất bại và được chuyển ra khỏi đường chính để không chặn phần còn lại. Bạn lưu nó có chủ ý. Mục tiêu là làm cho việc hiểu chuyện gì đã xảy ra, quyết định xem có sửa được không và tái xử lý an toàn trở nên dễ dàng.
Sai lầm lớn là chỉ lưu thông điệp lỗi. Khi ai đó nhìn vào dead-letter sau này, họ cần đủ ngữ cảnh để tái tạo vấn đề mà không đoán mò.
Một mục dead-letter hữu dụng nên chứa:
Phân loại giúp dead-letter có thể hành động. Một danh mục ngắn giúp người vận hành chọn bước tiếp theo đúng: permanent error (luật nghiệp vụ, trạng thái không hợp lệ), data issue (thiếu trường, định dạng sai), dependency down (timeout, rate limit, outage), và auth/permission (token hết hạn, credentials bị từ chối).
Tái xử lý phải được kiểm soát. Mục đích là tránh gây hại lặp lại, như charge hai lần hoặc spam email. Định nghĩa ai có thể retry, khi nào retry, gì có thể thay đổi (sửa trường cụ thể, đính kèm tài liệu còn thiếu, refresh token), và gì phải giữ nguyên (request ID và idempotency key xuống dòng).
Làm cho mục dead-letter có thể tìm kiếm theo định danh ổn định. Khi một người vận hành gõ “order 18422” và thấy chính xác bước, input và lịch sử lần thử, việc sửa sẽ nhanh và nhất quán.
Nếu bạn xây trong AppMaster, đối xử dead-letter như một mô hình database hạng nhất và lưu trạng thái, lần thử và định danh như các trường. Bằng cách đó dashboard nội bộ có thể query, lọc và kích hoạt hành động tái xử lý có kiểm soát.
Luồng chạy lâu có thể lỗi theo cách chậm và khó hiểu: một bước chờ trả lời email, nhà cung cấp thanh toán timeout, hoặc webhook đến hai lần. Nếu bạn không thấy luồng đang làm gì ngay lúc này, bạn sẽ phải đoán. Khả năng hiển thị tốt biến “nó hỏng” thành câu trả lời rõ ràng: luồng nào, bước nào, trạng thái nào, và phải làm gì tiếp theo.
Bắt đầu bằng việc khiến mỗi bước phát ra cùng một tập trường nhỏ để người vận hành quét nhanh:
Những trường này hỗ trợ các bộ đếm cơ bản cho thấy tình trạng sức khỏe. Với luồng chạy lâu, số lượng quan trọng hơn lỗi đơn lẻ vì bạn tìm kiếm xu hướng: công việc chất đống, retry tăng vọt, hoặc chờ mãi không xong.
Theo dõi started, completed, failed, retrying và waiting theo thời gian. Một số waiting nhỏ có thể bình thường (phê duyệt con người). Một đếm waiting tăng thường báo hiệu cái gì đó bị chặn. Tỷ lệ retry tăng nhiều chỉ ra vấn đề nhà cung cấp hoặc bug cứ lặp lại cùng lỗi.
Cảnh báo nên khớp trải nghiệm người vận hành. Thay vì “đã xảy ra lỗi”, cảnh báo theo triệu chứng: backlog tăng (started minus completed liên tục dương), quá nhiều luồng kẹt ở waiting quá thời gian mong đợi, tỷ lệ retry cao cho bước cụ thể, hoặc spike lỗi ngay sau release hoặc thay đổi cấu hình.
Giữ một trail sự kiện cho mỗi luồng để trả lời “đã xảy ra gì?” trong một view. Trail hữu dụng gồm timestamp, chuyển trạng thái, tóm tắt inputs và outputs (không phải payload nhạy cảm đầy đủ), và lý do retry hoặc lỗi. Ví dụ: “Charge card: retry 3/5, timeout từ provider, thử lại sau 10m.”
Correlation IDs là chất kết dính. Nếu khách hàng nói “thanh toán tôi bị charge hai lần,” bạn cần nối sự kiện luồng tới charge ID của nhà cung cấp và order ID nội bộ. Trong AppMaster, bạn có thể tiêu chuẩn hóa điều này trong Business Process bằng cách tạo và truyền correlation ID qua các cuộc gọi API và bước messaging để dashboard và log khớp nhau.
Khi một luồng chạy vài giờ hoặc vài ngày, lỗi là bình thường. Điều biến lỗi bình thường thành sự cố là dashboard chỉ nói “Failed” mà không có gì khác. Mục tiêu là giúp người vận hành trả lời ba câu hỏi nhanh: chuyện gì đang xảy ra, vì sao xảy ra và họ có thể làm gì an toàn tiếp theo.
Bắt đầu với danh sách luồng giúp tìm vài mục quan trọng dễ dàng. Bộ lọc giảm hoảng loạn và chat thừa vì ai cũng có thể thu hẹp view nhanh.
Bộ lọc hữu ích gồm trạng thái, tuổi (thời gian bắt đầu và thời gian ở trạng thái hiện tại), owner (team/khách hàng/người chịu trách nhiệm), loại (tên/phiên bản luồng) và độ ưu tiên nếu có bước hướng đến khách hàng.
Tiếp theo, hiển thị “tại sao” cạnh trạng thái thay vì giấu trong log. Một pill trạng thái chỉ hữu ích nếu đi kèm lỗi cuối cùng, một danh mục lỗi ngắn và hệ thống dự định làm gì tiếp theo. Hai trường làm chủ yếu công việc: last error và next retry time. Nếu next retry trống, hiển thị rõ liệu luồng đang chờ con người, tạm dừng, hay đã thất bại vĩnh viễn.
Hành động của người vận hành nên an toàn theo mặc định. Hướng họ đến hành động rủi ro thấp trước và làm rõ các hành động rủi ro:
“Force continue” là nơi thường gây hại nhất. Nếu cho phép, hãy nêu rủi ro bằng ngôn ngữ rõ ràng: “Điều này bỏ qua xác minh thanh toán và có thể tạo đơn chưa thanh toán.” Cũng hiển thị dữ liệu sẽ được ghi nếu tiếp tục.
Audit mọi hành động người vận hành làm. Ghi ai làm, khi nào, trạng thái trước/sau, và ghi chú lý do. Nếu xây công cụ nội bộ trong AppMaster, lưu audit trail như bảng hạng nhất và hiển thị trên trang chi tiết luồng để chuyển giao giữ được sạch sẽ.
Mẫu này giữ luồng dự đoán được: mỗi mục luôn ở trạng thái rõ ràng, mỗi lỗi có nơi để tới, và người vận hành có thể hành động mà không phải đoán.
Bước 1: Định nghĩa trạng thái và các chuyển đổi cho phép. Ghi lại một tập nhỏ trạng thái người ta hiểu (ví dụ: Queued, Running, Waiting on external, Succeeded, Failed, Dead-letter). Rồi quyết định chuyển nào hợp lệ để công việc không trôi vào limbo.
Bước 2: Chia công việc thành các bước nhỏ với input và output rõ ràng. Mỗi bước nên nhận một input định nghĩa rõ và xuất một output hoặc một lỗi rõ ràng. Nếu cần quyết định con người hoặc gọi API ngoài, tách thành bước riêng để có thể tạm dừng và tiếp tục sạch.
Bước 3: Thêm chính sách retry theo bước. Chọn giới hạn số lần, thời gian chờ giữa các lần và các lý do dừng không bao giờ retry (dữ liệu không hợp lệ, bị từ chối quyền, thiếu trường bắt buộc). Lưu bộ đếm retry theo bước để người vận hành thấy chính xác chỗ nào bị kẹt.
Bước 4: Lưu tiến trình sau mỗi bước. Sau khi bước xong, lưu trạng thái mới cùng các output chính. Nếu process khởi động lại, nó nên tiếp tục từ bước đã hoàn thành cuối cùng, không bắt đầu lại.
Bước 5: Điều hướng tới dead-letter và hỗ trợ tái xử lý. Khi hết retry, chuyển mục vào trạng thái dead-letter và giữ đầy đủ ngữ cảnh: inputs, lỗi cuối cùng, tên bước, số lần thử, và timestamp. Tái xử lý phải có chủ đích: sửa dữ liệu hoặc cấu hình trước, rồi re-queue từ bước cụ thể.
Bước 6: Định nghĩa trường dashboard và hành động người vận hành. Dashboard tốt trả lời “cái gì lỗi, ở đâu và tôi có thể làm gì tiếp theo?” Trong AppMaster, bạn có thể xây này như một admin web app đơn giản hậu thuẫn bởi bảng luồng.
Các trường và hành động chính nên có:
Onboarding nhân viên là bài kiểm tra tốt. Nó trộn phê duyệt, hệ thống ngoài và con người có thể offline. Luồng đơn giản: HR gửi form tuyển dụng, quản lý phê duyệt, IT tạo tài khoản, và nhân viên mới nhận thông báo chào mừng.
Làm cho trạng thái dễ đọc. Khi ai đó mở bản ghi, họ nên thấy ngay sự khác biệt giữa “Đang chờ phê duyệt” và “Đang thử lại tạo tài khoản.” Một dòng rõ ràng có thể cứu cả tiếng đồng hồ dò lỗi.
Một tập trạng thái rõ ràng để hiển thị trong UI:
Retry áp dụng cho các bước phụ thuộc mạng hoặc API bên ngoài. Provisioning tài khoản (email, SSO, Slack), gửi email/SMS, và gọi API nội bộ đều là ứng viên tốt cho retry. Hiển thị bộ đếm retry và giới hạn nó (ví dụ, thử tối đa năm lần với độ trễ tăng dần, rồi dừng).
Xử lý dead-letter dành cho vấn đề không tự sửa: không có quản lý trên form, địa chỉ email không hợp lệ, hoặc yêu cầu truy cập xung đột chính sách. Khi dead-letter một chạy, lưu ngữ cảnh: trường nào validate fail, phản hồi API cuối cùng, và ai có quyền override.
Người vận hành nên có vài hành động đơn giản: sửa dữ liệu (thêm quản lý, chỉnh email), chạy lại một bước thất bại (không phải cả luồng), hoặc hủy sạch (và undo phần đã tạo nếu cần).
Với AppMaster, bạn có thể mô hình hóa điều này trong Business Process Editor, giữ bộ đếm retry trong dữ liệu, và xây màn hình vận hành trong web UI builder hiển thị trạng thái, lỗi cuối và nút retry bước thất bại.
Hầu hết vấn đề độ tin cậy có thể dự đoán: một bước chạy hai lần, retry quay vòng lúc 2 giờ sáng, hoặc một mục “bị kẹt” không biết đã xảy ra gì. Một checklist giúp tránh suy đoán.
Kiểm tra nhanh bắt hầu hết vấn đề sớm:
Nếu chỉ cải thiện được một thứ, hãy cải thiện khả năng hiển thị. Nhiều “bug luồng” thực ra là “chúng ta không thấy nó đang làm gì.” Dashboard nên cho biết đã xảy ra gì, chuyện gì sẽ xảy ra tiếp và khi nào. Một view vận hành thực tế gồm trạng thái hiện tại, lỗi cuối, số lần thử, thời gian thử tiếp theo và một hành động rõ ràng (retry now, mark resolved hoặc gửi review thủ công). Giữ hành động theo mặc định an toàn: chạy lại một bước, không chạy lại toàn bộ luồng.
Bước tiếp theo:
Đối xử đây như một checklist sống. Mỗi khi thêm bước mới, chạy các kiểm tra này trước khi đưa lên production.
Luồng công việc chạy lâu có thể thành công trong nhiều giờ nhưng vẫn thất bại vào cuối, để lại thay đổi chưa hoàn tất. Chúng còn phụ thuộc vào yếu tố có thể thay đổi trong khi đang chạy, như thời gian hoạt động của bên thứ ba, thông tin đăng nhập, cấu trúc dữ liệu và thời gian phản hồi của con người.
Giữ tập trạng thái nhỏ và dễ đọc để người vận hành hiểu ngay lập tức. Một cấu hình mặc định tốt là: queued, running, waiting, succeeded và failed — trong đó “waiting” phải tách biệt rõ với “running” để phân biệt tạm dừng hợp lệ và treo.
Lưu đủ thông tin để trạng thái trở nên có thể hành động: trạng thái hiện tại, thời điểm thay đổi trạng thái lần cuối, trạng thái trước đó và một lý do ngắn khi đang chờ hoặc lỗi. Nếu có retry, cũng lưu số lần thử và thời gian thử tiếp theo để mọi người không phải đoán điều sẽ xảy ra tiếp theo.
Nó ngăn báo động giả và bỏ lỡ sự cố thật. “Đang chờ phê duyệt” hoặc “đang chờ webhook” có thể là trạng thái bình thường, trong khi “đang chạy suốt 6 giờ” nhiều khả năng là treo — nên tách hai thứ này để cải thiện cảnh báo và quyết định của người vận hành.
Thử lại những lỗi có khả năng tạm thời như timeout, giới hạn tần suất, hoặc sự cố thoáng qua của bên thứ ba. Không thử lại những lỗi rõ ràng vĩnh viễn như dữ liệu đầu vào không hợp lệ, thiếu quyền truy cập hoặc thanh toán bị từ chối — vì những lần thử lặp lại chỉ lãng phí thời gian và có thể gây hậu quả.
Đếm retry theo từng bước để một tích hợp hay bước dễ hỏng không cướp hết lượt thử cho cả luồng. Điều này cũng giúp chẩn đoán vì bạn thấy bước nào thất bại, đã thử bao nhiêu lần và các bước khác có bị ảnh hưởng hay không.
Chọn backoff phù hợp với rủi ro và luôn đặt giới hạn để thời gian chờ không tăng vô hạn. Đưa ra quy tắc dừng rõ ràng như số lần tối đa hoặc tổng thời gian tối đa, và ghi nhận cả lý do thất bại lẫn thời gian thử tiếp theo để quyền sở hữu vấn đề rõ ràng.
Giả định mỗi bước có thể chạy lại và thiết kế để lặp lại không gây hại. Cách phổ biến là dùng idempotency key ổn định cho mỗi bước gây tác động bên ngoài, lưu bản ghi “step started” trước khi gọi bên ngoài và ghi kết quả ngay khi nhận được, để lần chạy lại có thể tái sử dụng kết quả thay vì lặp lại hành động.
Một mục dead-letter là một bản ghi bạn chuyển ra khỏi đường chính sau khi hết retry để không chặn các mục khác. Lưu đủ ngữ cảnh để sửa và tái xử lý an toàn sau này: các định danh ổn định, input (hoặc snapshot an toàn), nơi thất bại, lịch sử lần thử và phản hồi lỗi từ phụ thuộc — chứ không chỉ một thông điệp lỗi mơ hồ.
Dashboard nhanh nhất cho người vận hành cho thấy nó đang ở đâu, tại sao ở đó và chuyện gì sẽ xảy ra tiếp theo, bằng các trường như workflow ID, bước hiện tại, trạng thái, thời gian ở trạng thái, lỗi cuối cùng và correlation IDs. Các hành động mặc định phải an toàn — ví dụ retry một bước — và các hành động rủi ro phải được gắn nhãn rõ ràng để tránh gây thêm lỗi khi “sửa” sự cố.



Thử nghiệm với AppMaster với gói miễn phí.
Khi bạn sẵn sàng, bạn có thể chọn đăng ký phù hợp.


