Ứng dụng đặt thiết bị: ngăn xung đột và theo dõi việc trả
Lập kế hoạch cho ứng dụng đặt thiết bị giúp ngăn việc đặt trùng, ghi nhận trả và hư hỏng, đồng thời đưa thiết bị lỗi vào trạng thái tạm giữ để bảo trì.
Tìm hiểu cách mô hình bộ đếm SLA và thăng cấp với trạng thái rõ ràng, quy tắc dễ bảo trì và lộ trình thăng cấp đơn giản để luồng công việc dễ thay đổi.
Các quy tắc theo thời gian thường bắt đầu đơn giản: “Nếu ticket không được phản hồi trong 2 giờ thì thông báo ai đó.” Rồi luồng công việc lớn dần, các đội thêm ngoại lệ, và đột nhiên không ai chắc chuyện gì xảy ra. Đó là cách các bộ đếm SLA và thăng cấp biến thành mê cung.
Giúp ích khi đặt tên rõ ràng cho các phần chuyển động.
Một timer là chiếc đồng hồ bạn khởi động (hoặc lập lịch) sau một sự kiện, như “ticket chuyển sang Waiting for Agent.” Một escalation là việc bạn làm khi đồng hồ đó chạm ngưỡng, ví dụ thông báo lead, đổi mức ưu tiên, hoặc phân công lại. Một breach là sự kiện được ghi lại nói rằng “Chúng ta đã trễ SLA”, dùng cho báo cáo, cảnh báo và theo dõi.
Vấn đề xuất hiện khi logic thời gian bị rải khắp ứng dụng: vài kiểm tra trong luồng “cập nhật ticket”, thêm kiểm tra trong một job hàng đêm, và những quy tắc một lần cho khách hàng đặc biệt. Mỗi phần hợp lý riêng, nhưng khi ghép lại thì tạo ra bất ngờ.
Triệu chứng phổ biến:
Mục tiêu là hành vi có thể dự đoán và dễ thay đổi sau này: một nguồn chân lý cho thời gian SLA, các trạng thái breach rõ ràng để báo cáo, và các bước thăng cấp bạn có thể điều chỉnh mà không phải mò khắp logic hình ảnh.
Trước khi xây timer, hãy viết ra cam kết chính xác bạn đang đo. Nhiều logic lộn xộn đến từ cố gắng che phủ mọi quy tắc thời gian ngay từ đầu.
Các loại SLA phổ biến nghe giống nhau nhưng đo khác nhau:
Tiếp theo, quyết định “thời gian” nghĩa là gì. Calendar time tính 24/7. Working time chỉ tính giờ làm việc đã định (ví dụ Thứ 2–6, 9–18). Nếu bạn không thật sự cần working time, tránh dùng sớm. Nó thêm các trường hợp biên như ngày lễ, múi giờ và ngày không trọn.
Rồi cụ thể hóa về tạm dừng. Tạm dừng không chỉ là “trạng thái đổi.” Đó là một quy tắc có người chịu trách nhiệm. Ai có thể tạm dừng (chỉ agent, chỉ hệ thống, hành động khách hàng)? Những trạng thái nào tạm dừng (Waiting on Customer, On Hold, Pending Approval)? Điều gì tiếp tục nó? Khi tiếp tục, bạn chạy tiếp từ thời gian còn lại hay khởi động lại timer?
Cuối cùng, định nghĩa breach theo ngôn ngữ sản phẩm. Một breach nên là vật cụ thể bạn có thể lưu và truy vấn, ví dụ:
Ví dụ: “First response SLA breached” có thể có nghĩa ticket nhận trạng thái Breached, một breached_at timestamp, và mức thăng cấp (escalation_level) đặt thành 1.
Nếu bạn muốn bộ đếm SLA và thăng cấp dễ đọc, hãy coi SLA như một máy trạng thái nhỏ. Khi “sự thật” bị trải ra những kiểm tra nhỏ (if now > due, if priority is high, if last reply is empty), logic hình ảnh nhanh chóng trở nên lộn xộn và thay đổi nhỏ làm vỡ mọi thứ.
Bắt đầu với một tập trạng thái SLA ngắn, đã thỏa thuận, mà mọi bước luồng đều hiểu. Với nhiều đội, các trạng thái này đủ che hầu hết trường hợp:
Một cờ đơn breached = true/false hiếm khi đủ. Bạn vẫn cần biết SLA nào bị vi phạm (first response hay resolution), có đang tạm dừng hay không, và đã thăng cấp chưa. Thiếu bối cảnh đó, mọi người bắt đầu suy luận ý nghĩa từ bình luận, dấu thời gian và tên trạng thái — và đó là lúc logic trở nên mong manh.
Hãy làm trạng thái rõ ràng và lưu các dấu thời gian giải thích trạng thái đó. Khi đó quyết định đơn giản: bộ đánh giá đọc bản ghi, quyết định trạng thái tiếp theo, và mọi thứ khác phản ứng theo trạng thái.
Các trường hữu ích nên lưu cùng trạng thái:
started_at và due_at (đang chạy đồng hồ nào và khi nào đến hạn?)breached_at (khi nào thực sự vượt quá)paused_at và paused_reason (tại sao đồng hồ dừng?)breach_reason (quy tắc nào kích hoạt breach, bằng lời dễ hiểu)last_escalation_level (để không thông báo cùng mức nhiều lần)Ví dụ: một ticket chuyển sang “Waiting on customer.” Đặt trạng thái SLA là Paused, ghi paused_reason = "waiting_on_customer", và dừng đồng hồ. Khi khách hàng trả lời, resume bằng cách đặt started_at mới (hoặc bỏ pause và tính lại due_at). Không phải mò qua nhiều điều kiện.
Thang thăng cấp là kế hoạch rõ ràng cho những gì xảy ra khi bộ đếm SLA sắp vi phạm hoặc đã vi phạm. Sai lầm là sao chép sơ đồ tổ chức vào luồng. Bạn muốn tập những bước nhỏ nhất có thể khiến mục trì trệ di chuyển tiếp.
Một thang đơn giản nhiều đội dùng: agent được phân công (Level 0) nhận nhắc nhở đầu tiên, sau đó team lead (Level 1) được kéo vào, và chỉ sau đó tới manager (Level 2). Nó hiệu quả vì bắt đầu ở nơi có thể làm việc, và chỉ tăng quyền hạn khi cần.
Để giữ quy tắc thăng cấp dễ bảo trì, lưu ngưỡng thăng cấp như dữ liệu, không phải điều kiện cứng. Đặt chúng trong bảng hoặc object cài đặt: “nhắc lần một sau 30 phút” hoặc “thăng cấp lead sau 2 giờ.” Khi chính sách thay đổi, cập nhật một chỗ thay vì chỉnh nhiều luồng.
Thăng cấp biến thành spam khi chúng chạy quá thường xuyên. Thêm rào chắn để mỗi bước có mục đích:
Chỉ thông báo thôi không giải quyết được việc trì trệ nếu trách nhiệm mơ hồ. Định nghĩa quy tắc sở hữu trước: ticket vẫn gán cho agent, được chuyển cho lead, hay chuyển sang hàng đợi chung?
Ví dụ: sau thăng cấp Level 1, phân công lại cho team lead và đặt agent gốc làm watcher. Điều đó làm rõ ai cần hành động tiếp và tránh việc thang nhảy qua lại giữa các người.
Cách dễ nhất để giữ bộ đếm SLA và thăng cấp dễ bảo trì là coi chúng như một hệ nhỏ gồm ba phần: events, một evaluator, và actions. Điều này ngăn toán học thời gian bị trải khắp hàng chục kiểm tra “if time > X”.
Events là các sự kiện đơn giản không chứa toán học timer. Chúng trả lời “cái gì thay đổi?” chứ không phải “nên làm gì về nó?” Các events điển hình gồm ticket created, agent replied, customer replied, status changed, hoặc pause/resume thủ công.
Lưu chúng như dấu thời gian và các trường trạng thái (ví dụ: created_at, last_agent_reply_at, last_customer_reply_at, status, paused_at).
Tạo một bước “SLA evaluator” chạy sau mọi event và theo lịch định kỳ. Evaluator này là nơi duy nhất tính due_at và thời gian còn lại. Nó đọc các dữ kiện hiện tại, tính lại deadline, và ghi các trường trạng thái SLA rõ ràng như sla_response_state và sla_resolution_state.
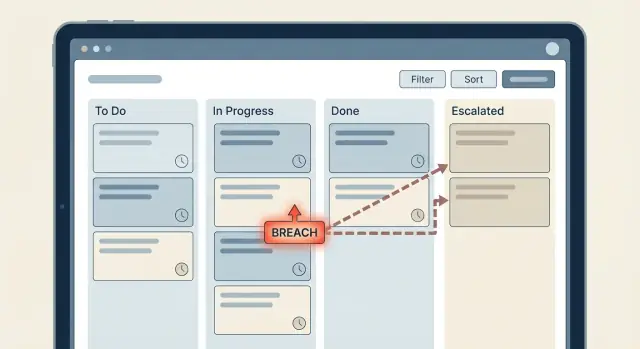
Đây là nơi mô hình trạng thái breach được giữ sạch: evaluator đặt các trạng thái như OK, AtRisk, Breached, thay vì giấu logic trong thông báo.
Thông báo, phân công và thăng cấp chỉ nên kích hoạt khi trạng thái thay đổi (ví dụ: OK -> AtRisk). Giữ việc gửi tin tách biệt khỏi cập nhật trạng thái SLA. Khi đó bạn có thể thay đổi người nhận mà không động đến tính toán.
Một thiết lập dễ bảo trì thường trông như sau: vài trường trên bản ghi, một bảng chính sách nhỏ, và một evaluator quyết định bước tiếp theo.
Bắt đầu với thực thể sở hữu SLA (ticket, order, request). Thêm các dấu thời gian rõ ràng và một trường “trạng thái SLA hiện tại”. Giữ nó đơn điệu và dễ đoán.
Rồi thêm một bảng chính sách nhỏ mô tả quy tắc thay vì cứng mã trong nhiều luồng. Phiên bản đơn giản: một hàng cho mỗi độ ưu tiên (P1, P2, P3) với cột target minutes và các ngưỡng thăng cấp (ví dụ: warn ở 80%, breach ở 100%). Đó là khác biệt giữa sửa một bản ghi so với chỉnh năm luồng.
Thay vì tạo nhiều timer riêng, dùng một tiến trình theo lịch kiểm tra các mục định kỳ (mỗi phút cho SLA nghiêm ngặt, mỗi 5 phút cho nhiều đội). Lịch gọi một evaluator duy nhất mà:
sla_state và next_check_atĐiều này làm cho bộ đếm SLA và thăng cấp dễ lý giải hơn vì bạn gỡ lỗi một evaluator chứ không nhiều timer.
Evaluator nên xuất cả trạng thái mới và có thay đổi hay không. Chỉ gửi tin nhắn hoặc tạo tác vụ khi trạng thái thay đổi (ví dụ ok -> warning, warning -> breached). Nếu bản ghi giữ breached trong một giờ, bạn không muốn nhận 12 thông báo lặp lại.
Mẫu thực tế: lưu sla_state và last_escalation_level, so sánh với giá trị mới tính, và chỉ rồi gọi messaging (email/SMS/Telegram) hoặc tạo task nội bộ.
Tạm dừng là nơi logic thời gian thường rối. Nếu bạn không mô hình rõ, SLA hoặc sẽ chạy khi không nên, hoặc bị đặt lại khi ai đó bấm nhầm trạng thái.
Quy tắc đơn giản: chỉ một trạng thái (hoặc vài trạng thái) tạm dừng đồng hồ. Lựa chọn phổ biến là Waiting for customer. Khi ticket vào trạng thái đó, lưu pause_started_at. Khi khách hàng trả lời và ticket rời trạng thái đó, đóng pause bằng cách ghi pause_ended_at và cộng thời lượng vào paused_total_seconds.
Đừng chỉ giữ một bộ đếm tổng. Ghi lại mỗi cửa sổ pause (start, end, ai hoặc gì kích hoạt) để có trace audit. Sau này, khi ai đó hỏi vì sao case vi phạm, bạn có thể chứng minh nó đợi khách hàng 19 giờ.
Phân công lại và thay đổi trạng thái bình thường không nên đặt lại đồng hồ. Giữ các dấu thời gian SLA tách khỏi trường sở hữu. Ví dụ sla_started_at và sla_due_at nên được đặt một lần (khi tạo, hoặc khi chính sách SLA thay đổi), trong khi reassignment chỉ cập nhật assignee_id. Evaluator sau đó tính thời gian đã trôi là: now minus sla_started_at minus paused_total_seconds.
Quy tắc để giữ bộ đếm SLA và thăng cấp dự đoán được:
Một cách đơn giản để thử thiết kế là ticket hỗ trợ với hai SLA: phản hồi đầu trong 30 phút, và giải quyết trong 8 giờ. Đây là nơi logic hay vỡ nếu nó rải rác qua màn hình và các nút bấm.
Giả sử mỗi ticket lưu: state (New, InProgress, WaitingOnCustomer, Resolved), response_status (Pending, Warning, Breached, Met), resolution_status (Pending, Warning, Breached, Met), cùng dấu thời gian như created_at, first_agent_reply_at, và resolved_at.
Một timeline thực tế:
Với thăng cấp, giữ một chuỗi rõ ràng kích hoạt trên các chuyển đổi trạng thái. Ví dụ, khi response trở thành Warning, thông báo cho agent được phân công. Khi nó trở thành Breached, thông báo team lead và cập nhật ưu tiên.
Ở mỗi bước, cập nhật cùng tập trường nhỏ để dễ lý giải:
response_status hoặc resolution_status thành Pending, Warning, Breached hoặc Met.*_warning_at và *_breach_at một lần, sau đó không ghi đè.escalation_level (0, 1, 2) và đặt escalated_to (Agent, Lead, Manager).sla_events với loại sự kiện và ai được thông báo.priority và due_at để UI và báo cáo phản ánh thăng cấp.Chìa khóa là Warning và Breached là trạng thái rõ ràng. Bạn nhìn thấy chúng trong dữ liệu, kiểm toán được, và thay đổi thang sau này mà không phải mò các kiểm tra timer ẩn.
Logic SLA lộn xộn khi nó lan tràn. Một kiểm tra thời gian vội vàng thêm vào nút ở đây, một cảnh báo có điều kiện ở kia, và sớm thôi không ai giải thích được vì sao ticket bị thăng cấp. Giữ bộ đếm SLA và thăng cấp như một mảnh logic nhỏ trung tâm mà mọi màn hình và hành động phụ thuộc vào.
Bẫy hay gặp là nhúng kiểm tra thời gian ở nhiều chỗ (UI, API handlers, hành động thủ công). Sửa là tính trạng thái SLA trong một evaluator duy nhất và lưu kết quả vào bản ghi. Màn hình chỉ đọc trạng thái, không suy ra.
Một bẫy khác là để timer dùng các đồng hồ khác nhau. Nếu trình duyệt tính “phút kể từ khi tạo” còn backend dùng giờ máy chủ, bạn sẽ gặp các trường hợp biên quanh ngủ máy, múi giờ và chuyển mùa. Ưu tiên giờ máy chủ cho bất cứ thứ gì kích hoạt thăng cấp.
Thông báo cũng có thể nhanh chóng ồn ào. Nếu bạn “kiểm tra mỗi phút và gửi nếu overdue”, mọi người có thể bị spam mỗi phút. Gắn tin vào chuyển đổi trạng thái thay vì “vẫn quá hạn”: “warning sent”, “escalated”, “breached”. Khi đó bạn gửi một lần cho mỗi bước và có thể kiểm toán được.
Logic giờ làm việc là nguồn phức tạp khác. Nếu mỗi quy tắc có nhánh “nếu cuối tuần thì…” riêng, cập nhật sẽ đau. Đặt toán học giờ làm việc vào một hàm (hoặc khối chung) trả về “SLA minutes đã tiêu thụ”, và tái sử dụng nó.
Cuối cùng, đừng phụ thuộc vào việc tính lại breach từ đầu. Lưu khoảnh khắc nó xảy ra:
breached_at lần đầu bạn phát hiện breach và không ghi đè.escalation_level và last_escalated_at để hành động idempotent.notified_warning_at (hoặc tương tự) để tránh alert lặp.Ví dụ: ticket vi phạm Response SLA lúc 10:07. Nếu chỉ tính lại, một thay đổi trạng thái hay lỗi pause/resume sau đó có thể làm nó trông như breach xảy ra lúc 10:42. Với breached_at = 10:07, báo cáo và postmortem giữ nguyên thực tế.
Trước khi thêm timer và cảnh báo, rà một lượt với mục tiêu để các quy tắc dễ đọc sau một tháng.
Một bài test thực tế: chọn một ticket sắp vi phạm và phát lại timeline của nó. Nếu bạn không thể giải thích điều gì xảy ra ở mỗi thay đổi trạng thái mà không đọc toàn bộ workflow, mô hình bạn quá rải rác.
Xây lát cắt nhỏ hữu ích nhất trước. Chọn một SLA (ví dụ first response) và một mức thăng cấp (ví dụ thông báo team lead). Bạn sẽ học nhiều hơn sau một tuần dùng thực tế so với thiết kế hoàn hảo trên giấy.
Giữ ngưỡng và người nhận dưới dạng dữ liệu, không phải logic. Đặt phút và giờ, quy tắc giờ làm việc, ai được thông báo và hàng đợi sở hữu vào bảng hoặc bản ghi cấu hình. Khi đó workflow ổn định trong khi business điều chỉnh số và routing.
Lên kế hoạch một bảng điều khiển đơn giản sớm. Bạn không cần hệ analytics lớn, chỉ một góc nhìn chia sẻ về tình trạng hiện tại: on track, warning, breached, escalated.
Nếu bạn xây trong công cụ no-code, chọn nền tảng cho phép mô hình dữ liệu, logic và evaluator theo lịch trong cùng một chỗ. Ví dụ, AppMaster (appmaster.io) hỗ trợ mô hình cơ sở dữ liệu, quy trình nghiệp vụ trực quan, và sinh ứng dụng sẵn sàng cho production, phù hợp với mẫu “events, evaluator, actions”.
Tinh chỉnh an toàn theo thứ tự sau:
Khi sẵn sàng, xây một phiên bản nhỏ trước rồi mở rộng theo phản hồi thực tế và ticket thật.
Bắt đầu bằng định nghĩa rõ ràng về cam kết bạn đang đo, ví dụ first response hay resolution, và ghi rõ sự kiện bắt đầu, kết thúc và quy tắc tạm dừng. Sau đó tập trung toán học thời gian vào một bộ đánh giá (evaluator) duy nhất, để thiết lập trạng thái SLA thay vì rải các kiểm tra “if now > X” khắp nhiều luồng.
Một bộ đếm (timer) là chiếc đồng hồ bạn khởi động hoặc lập lịch sau một sự kiện, như một ticket chuyển trạng thái. Một thăng cấp (escalation) là hành động bạn thực hiện khi đạt ngưỡng, chẳng hạn thông báo lead hoặc thay đổi mức ưu tiên. Một breach là sự kiện được lưu lại cho biết SLA đã bị bỏ lỡ, dùng cho báo cáo sau này.
First response đo thời gian đến lần trả lời có ý nghĩa đầu tiên của con người, còn resolution đo đến khi vấn đề thực sự đóng. Chúng xử lý khác nhau các trường hợp tạm dừng và mở lại, nên tách riêng hai SLA giúp logic đơn giản và báo cáo chính xác hơn.
Mặc định hãy dùng calendar time vì đơn giản và dễ gỡ lỗi. Chỉ thêm working-time (giờ làm việc) nếu thực sự cần, vì giờ làm việc kéo theo phức tạp thêm như ngày nghỉ lễ, múi giờ và tính toán nửa ngày.
Mô hình tạm dừng như các trạng thái rõ ràng, ví dụ Waiting on Customer; lưu thời điểm bắt đầu pause và kết thúc. Khi resume, tiếp tục với thời gian còn lại hoặc tính lại due time ở một chỗ duy nhất — đừng để các toggle trạng thái ngẫu nhiên đặt lại đồng hồ.
Một cờ đơn breached = true/false thường không đủ vì nó che mất ngữ cảnh quan trọng: SLA nào bị vi phạm, có đang tạm dừng không, đã thăng cấp chưa. Các trạng thái rõ ràng như On track, Warning, Breached, Paused, Completed giúp hệ thống dễ đoán và dễ kiểm toán.
Lưu các dấu thời gian giải thích trạng thái, như started_at, due_at, breached_at, và các trường pause như paused_at, paused_reason. Cũng lưu theo dõi thăng cấp như last_escalation_level để tránh thông báo trùng lặp.
Tạo một thang nhỏ bắt đầu với người có thể hành động (assigned agent), rồi lead, và chỉ tới manager nếu cần. Lưu ngưỡng và người nhận dưới dạng dữ liệu (bảng chính sách) để thay đổi thời gian không phải chỉnh nhiều luồng.
Gắn thông báo vào chuyển đổi trạng thái như OK -> Warning hoặc Warning -> Breached, không phải vào việc “vẫn quá hạn”. Thêm cơ chế guard như cửa sổ cooldown và điều kiện dừng để chỉ gửi một thông báo cho mỗi bước.
Áp dụng mẫu events — evaluator — actions: events ghi lại sự kiện, evaluator tính deadline và đặt trạng thái SLA, actions chỉ phản ứng khi trạng thái thay đổi. Trong AppMaster (appmaster.io), bạn có thể mô hình hóa dữ liệu, dựng quy trình đánh giá trực quan và kích hoạt thông báo hoặc phân công từ việc cập nhật trạng thái, giữ toán học thời gian tập trung.



Thử nghiệm với AppMaster với gói miễn phí.
Khi bạn sẵn sàng, bạn có thể chọn đăng ký phù hợp.


