
機器予約アプリで競合を防ぎ、返却を追跡する
二重予約を防ぎ、返却と破損を記録し、故障した機器を保守対象にする機器予約アプリの設計方法を紹介します。
加算的マイグレーション、安定したバックフィル、段階的ロールアウトを使って、古いクライアントを稼働させたままゼロダウンタイムでスキーマ変更を行う方法を学びます。
ゼロダウンタイムのスキーマ変更は「何も変えない」ことではありません。データベースとアプリを更新している間でも、ユーザーが失敗やワークフローの停止を経験せずに作業を続けられることを意味します。
ダウンタイムとは、システムが通常通り振る舞わなくなる瞬間すべてを指します。500エラー、APIのタイムアウト、画面が空白や誤った値を表示する、バックグラウンドジョブが落ちる、長いマイグレーションでロックがかかり読み取りはできても書き込みがブロックされる、などが該当します。
スキーマ変更はメインのUIだけを壊すわけではありません。よく起きる問題点としては、古いレスポンス形状を期待するAPIクライアント、特定の列を読み書きするバックグラウンドジョブ、直接テーブルを参照するレポート、サードパーティ連携、そして「昨日までは動いていた」社内の管理スクリプトなどがあります。
古いモバイルアプリやキャッシュされたクライアントは厄介です。すぐにアップデートできないため、あるユーザーは数週間同じアプリバージョンを使い続けます。断続的な接続で古いリクエストを後で再試行することもあります。サービスワーカーやCDN、プロキシキャッシュが古いコードや想定を保持している場合、ウェブクライアントも「古いバージョン」のように振る舞います。
本当の目標は「短時間で終わる一回の大きなマイグレーション」ではありません。各ステップがそれ自体で機能し、異なるクライアントが混在していても安全である一連の小さな手順です。
実用的な定義としては、コードとスキーマをどちらの順番でデプロイしてもシステムが動作することを目指すべきです。
このマインドセットがあれば、よくある落とし穴を避けられます:列が存在する前に新しいアプリをデプロイしたり、新しい列を追加して古いコードがそれを扱えずにクラッシュしたりすることです。まずは加算的に変更を計画し、段階的にロールアウトし、何も使われていないと確信できてから古い経路を削除してください。
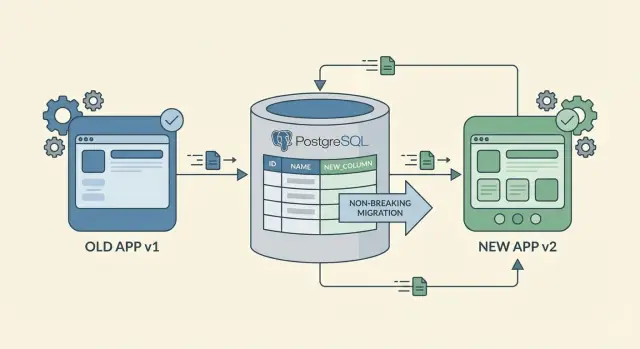
ゼロダウンタイムでスキーマを変更する最も安全な方法は、置き換えではなく追加です。新しい列や新しいテーブルを追加することは、既存のコードは従来の形を読み書きできるため、ほとんどの場合破壊的ではありません。
リネームや削除はリスクが高い操作です。リネームは実質的に「新しいものを追加して古いものを削除する」ことであり、問題は「古いものを削除する」段階で古いクライアントが壊れることにあります。リネームが必要なら、まず新しいフィールドを追加し、しばらく古いフィールドを残し、依存がなくなったことを確認してから削除してください。
列を追加する場合は、まず nullable なフィールドで始めましょう。NULL許容の列があれば、古いコードは新しい列を知らなくても行を挿入できます。最終的に NOT NULL にしたければ、まずはNULL許容で追加し、バックフィルしてから NOT NULL を適用します。デフォルト値も役立ちますが注意が必要です:デフォルト設定が多くの行に対して影響を与えるデータベースもあり、変更が遅くなることがあります。
インデックスも「安全だがコストがかかる」追加です。読み取りを速くしますが、インデックスの構築と維持は書き込みを遅くする可能性があります。どのクエリで使うかが確実に分かってから追加し、データベースが高負荷なら閑散時間に実行することを検討してください。
加算的データベースマイグレーションの簡単なルール:
NOT NULL、一意制約、外部キー)は遅らせる。ゼロダウンタイムのスキーマ変更は「デプロイ」ではなく「ロールアウト」と見なしてください。目標は、古いバージョンと新しいバージョンが並行して動く間にデータベースを徐々に新形状へ移行することです。
実用的な手順例:
例:full_name を導入したが、古いクライアントは first_name と last_name を送るとします。しばらくの間、バックエンドは書き込み時に full_name を構築し、既存ユーザーをバックフィルし、その後デフォルトで full_name を読みつつ古いペイロードを引き続きサポートします。採用状況が明らかになってから古いフィールドを落とします。
バックフィルは既存行に新しい列やテーブルの値を埋める作業です。ゼロダウンタイムの中で最もリスクが高くなることが多く、重いデータベース負荷、長いロック、途中状態の混乱を招きます。
まずバックフィルをどう運用するかを決めます。データ量が小さければワンタイムの手順で十分な場合もありますが、データ量が大きければ何度でも停止・再開できるバックグラウンドワーカーやスケジュールされたジョブを推奨します。
作業はバッチ化してデータベースへの負荷を制御します。何百万行も一度に更新しないでください。予測可能なチャンクサイズ、短い間隔、通常トラフィックを阻害しない休止を入れることを目指します。
実用パターンの例:
ジョブは再起動可能にします。専用テーブルに単純な進捗マーカーを保存し、再実行してもデータが壊れないよう設計します。冪等な更新(例:WHERE new_field IS NULL)が有効です。
進行中に検証を行ってください。まだ値がない行数を追い、いくつかのサニティチェックを入れます。例:残高が負になっていないか、タイムスタンプが期待範囲内か、ステータスが許容される集合にあるか。実データをサンプリングしてスポットチェックするのも有効です。
バックフィルが完了していない間にアプリがどう振る舞うかを決めておきます。安全な選択肢はフォールバック読み取りです:新しいフィールドが null なら古い値を計算または参照して返す、という方法です。例:新しい preferred_language 列を追加した場合、バックフィルが終わるまではプロファイル設定から既存の言語を返すようにできます。完了後に新しいフィールドを必須にします。
スキーマ変更を出すと、すべてのクライアントをコントロールできるわけではありません。ウェブは比較的早く更新されますが、モバイルの古いビルドは何週間も残ることがあります。だからスキーマの移行が安全でも、後方互換なAPIが重要です。
最初は新しいデータをオプションとして扱ってください。リクエストやレスポンスに新しいフィールドを追加しても、初日はそれを必須にしないでください。古いクライアントが新しいフィールドを送らなくてもサーバーはリクエストを受け入れ、従来通り動作するべきです。
既存フィールドの意味を変えないことが大切です。フィールド名を残したまま動作を変えると微妙な壊れ方を招きます。名前を変える場合は旧名も動くようにします。
サーバー側のデフォルトは保険になります。preferred_language のような新しい列を導入するときは、欠落時にサーバーでデフォルトをセットします。APIレスポンスに新フィールドを含めても、古いクライアントはそれを無視できるはずです。
互換性を保つルール:
例:サインアップフローに company_size を追加する場合、バックエンドは欠落時に「unknown」のようなデフォルトを入れておけば、新しいクライアントは実値を送り、古いクライアントはこれまで通り動き、ダッシュボードも読みやすいままです。
プラットフォームがアプリを再生成する場合、コードと設定のクリーンな再構築が得られます。これにより、加算的なステップを頻繁に行ってしばしば再デプロイでき、長期間にわたってパッチを抱え込む必要がなくなります。
重要なのは単一の真実の情報源(one source of truth)です。データベーススキーマが一箇所で変更され、ビジネスロジックが別の場所で変わるとすぐにドリフトが発生します。どこで変更を定義するか決め、それ以外は生成物と扱ってください。
明確な命名は段階的ロールアウト時の事故を減らします。新しいフィールドを導入するなら、どちらが古いクライアント向けでどちらが新しい経路か分かりやすくしてください。例えば status_v2 のような命名は、status_new より数ヶ月後でも意味が通りやすいです。
加算的変更でも、再生成とデプロイ後に隠れた結合が表面化することがあります。再生成とデプロイのたびに、重要なフローを少数チェックしてください:
マイグレーション手順はエディタを触る前に計画します:新しいフィールドを追加→両方をサポートするデプロイ→バックフィル→読み取り切替→古い経路の退役。この順序でスキーマ、ロジック、生成コードが一緒に進むようにすれば、変更は小さく、レビューしやすく、戻しやすくなります。
ゼロダウンタイムのスキーマ変更で起きる多くの障害は「重い」データベース作業が原因ではありません。データベース、API、クライアント間の契約を間違った順序で変えることが原因です。
よくある罠と安全な対処:
NOT NULL を強制する。アプリを再生成する場合、一気に名前や制約をきれいにし直したくなる誘惑に注意してください。クリーンアップは最後のステップであり、最初にやることではありません。
良いルール:前に進める(フォワード)と戻す(ロールバック)が安全にできない変更は、本番に出す準備ができていません。
ゼロダウンタイムのスキーマ変更の成否は「何を監視するか」と「どれだけ速く止められるか」にかかっています。
デプロイが完了したかどうかではなく、実際のユーザー影響を反映するシグナルを追いましょう:
デュアルライトをしている場合は、新旧の値を比較して差分を一時的にログに残すと良いです。量が多くなる場合はサンプリングし、差分が出たときだけ記録するなど絞り込みを入れてください。マイグレーション後にこのログを恒久化しないように削除するリマインダーを作っておきましょう。
ロールバックは現実的である必要があります。多くの場合、スキーマを戻すのではなくコードを戻します。現実的なロールバック手順の例:
バックフィル用に数秒で切れる停止スイッチ(フラグ、設定値、ジョブ一時停止)を用意してください。またフェーズを事前に共有しておきます:デュアルライト開始時、バックフィルの実行時、読み取り切替時、そして「停止」がどういう挙動かを周知しておくと、現場での混乱を避けられます。
スキーマ変更を出荷する直前に一度立ち止まり、この簡単なチェックを実行してください。混在するクライアントバージョンで障害に繋がる小さな前提を捕まえられます。
再生成プラットフォームを使うなら、もう一つの確認を加えてください:マイグレーション対象モデルからビルドを生成してデプロイし、生成されたAPIとビジネスロジックが古いレコードも許容するかを確認します。新しいスキーマ=新しい必須ロジック、という誤った前提に陥らないようにします。
また、デプロイ後に何か問題が見えたときに取る二つの素早いアクションを書き出しておきます:監視する指標(エラー、タイムアウト、バックフィル進捗)と最初にロールバックする対象(フラグオフ、バックフィル一時停止、サーバーリリースのリバート)です。これが「素早く対応する」から「実行可能な計画」に変わります。
あなたは注文アプリを運営しており、新しいビジネスルールで必須となる delivery_window が必要です。問題は古いiOS/Androidビルドがまだ使われており、その間はこのフィールドを送らないことです。もしすぐにこの列を必須にすると古いクライアントが失敗します。
安全な手順:
delivery_window を推測ルール(配送方法から推定する、あるいは顧客が編集するまで "anytime" をデフォルトにする)で埋める。delivery_window を参照し、欠けている場合は推測値にフォールバックする。NOT NULL を追加しフォールバックを削除する。各フェーズ中にユーザーが感じる影響はほとんどなく(それが目的です):
各ステップの簡単な監視ゲート:新規注文における delivery_window が非NULLである割合を追い、一定期間安定して高く、"missing field" のバリデーションエラーがほぼゼロであれば、バックフィルから制約適用へ移る判断材料になります。
一度きりの慎重なロールアウトは戦略になりません。スキーマ変更を定例にしてください:同じ手順、同じ命名、同じ承認フロー。そうすれば次の加算的変更も忙しい状況やクライアントが混在していても平常運転で済みます。
プレイブックは短く保ってください。何を追加するか、どう安全に出すか、いつ古い部分を削除するかに答えられるべきです。
簡単なテンプレート:
まず危険度の低いテーブル(新しい任意のステータス、メモ欄など)でフルプレイブックを試し、加算的変更→バックフィル→混在バージョンでの動作→クリーンアップの流れを通してみてください。この練習で監視、バッチ処理、コミュニケーションの穴が露呈します。
長期的な混乱を防ぐ習慣:"後で削除する" 項目を実際の作業として追跡すること。臨時の列や互換コード、デュアルライトのチケットを直ちに作り、担当者と期限を設定しておく。リリースドキュメントに小さな「互換性負債」メモを残して可視化しておくと忘れにくくなります。
AppMasterで構築する場合、再生成を安全プロセスの一部として扱えます:加算的なスキーマをモデル化し、移行中は旧フィールドと新フィールドの両方を扱うようビジネスロジックを更新し、再生成してソースコードを整えることで要件の変化に合わせてクリーンに保てます。AppMaster (appmaster.io) はこの種の反復的で段階的なデリバリースタイルを想定して設計されています。
目標は完璧さではなく再現性です。すべてのマイグレーションに計画、計測、撤退手順があり、そうすればどの変更も平穏に進められます。
ゼロダウンタイムとは、スキーマを変更してコードをデプロイしている間でもユーザーが通常通り作業を続けられることを指します。目に見える障害(アウトエイジ)を避けるだけでなく、空白の画面、誤った値、ジョブのクラッシュ、長いロックによって書き込みが止まるような“静かな破損”も防ぎます。
マイグレーションが成功しても、それだけで全てが安全になるわけではありません。システムの多くの部分がデータベースの形に依存しているため、バックグラウンドジョブ、レポート、管理スクリプト、外部連携、そして古いモバイルアプリなどが新しい形に対応していないことが原因で問題が発生します。
古いモバイルビルドは数週間稼働し続けることがあり、クライアントが古いリクエストを再試行する場合もあります。そのためAPIはしばらくの間、古いペイロードと新しいペイロードの両方を受け入れられる必要があります。これができないと混在したバージョン環境でエラーが発生します。
既存のスキーマを残す「加算的」な変更が最も安全です。既存のスキーマがそのまま残る限り、古いコードは従来通り動作できます。対してリネームや削除は古いクライアントが参照しているものを取り除いてしまうため危険です。
まず列を nullable(NULL許容)で追加します。古いコードはそのまま行を挿入でき、後からバッチで既存行をバックフィルします。十分なカバレッジと一貫した新規書き込みが確認できてから NOT NULL を適用してください。
実務的なロールアウトは次のように扱います:互換的にスキーマを追加→両方に対応するコードをデプロイ(デュアルライト)→小さなバッチでバックフィル→カバレッジが高くなってから読み取りを切り替え→最後に古いフィールドを削除。各ステップは単独で安全に動作するべきです。
テーブル全体を一度に巨大なトランザクションで更新するとロックや負荷が発生します。小さなバッチで、短時間のトランザクション、途中の休止を入れ、進捗を記録して再開可能にするのが安全です。更新は WHERE new_field IS NULL のように冪等にするのが望ましいです。
最初は新しいフィールドを任意(optional)にし、サーバー側で欠落時のデフォルトを適用します。既存フィールドの意味を変えないこと、両方のパス(新しいクライアントが送る場合と古いクライアントが省略する場合)のテストを行うことが重要です。
ほとんどの場合、スキーマ自体はロールバックしません。アプリケーションコードを以前の安定版に戻し、新しい読み取りを無効化し、その後新しい書き込みを止め、バックフィルを一時停止します。加算された列やテーブルは残しておき、使用を停止する方針が現実的です。
各段階で見たい指標は、エラー率(特に更新したエンドポイントの4xx/5xx)、遅いクエリのp95/p99、書き込み遅延、ジョブキューの深さ、データベースのCPU/IO負荷などユーザー影響を反映するものです。新しいフィールドのカバレッジが高く安定したら次へ進んでください。




