
機器予約アプリで競合を防ぎ、返却を追跡する
二重予約を防ぎ、返却と破損を記録し、故障した機器を保守対象にする機器予約アプリの設計方法を紹介します。
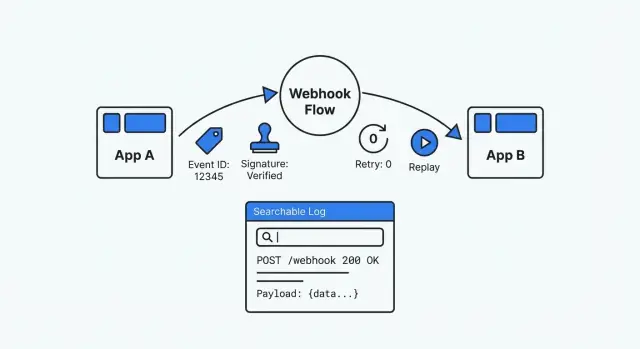
署名の標準化、リトライの安全な処理、リプレイの有効化、検索しやすいイベントログの保持でWebhook統合をデバッグする方法を学ぶ。
Webhookは、何かが起きたときに一つのアプリがあなたのアプリを呼び出す仕組みにすぎません。決済プロバイダが「支払い成功」を送る、フォームツールが「新しい送信」を伝える、CRMが「取引が更新された」と報告する。シンプルに見える反面、何かが壊れたときに開ける画面がなく、明確な履歴がなく、安全に再実行する方法がないことに気づきます。
だからWebhookの問題はイライラします。リクエストは到着する(またはしない)。あなたのシステムは処理する(または失敗する)。最初のシグナルは「顧客がチェックアウトできない」や「ステータスが更新されない」といったあいまいなチケットであることが多いです。プロバイダがリトライすると重複が発生するかもしれません。ペイロードのフィールドが変わると、一部のアカウントだけでパーサが壊れることがあります。
よくある症状:
デバッグできるWebhookの構成は推測の逆です。追跡可能(すべての配信とその扱いを見つけられる)、再現可能(過去のイベントを安全にリプレイできる)、検証可能(真正性と処理結果を証明できる)であること。誰かに「このイベントはどうなった?」と聞かれたら、数分で証拠を示せるべきです。
AppMasterのようなプラットフォームでアプリを作るなら、この考え方はさらに重要です。ビジュアルロジックは素早く変更できますが、外部システムがブラックボックスにならないように明確なイベント履歴と安全なリプレイが必要です。
プレッシャー下でデバッグするときには、毎回同じ基本が必要です: 信頼でき、検索でき、リプレイできる記録。これがなければ、すべてのWebhookが一件物の謎になります。
あなたのシステムで単一のWebhook「イベント」が何を意味するかを決めてください。レシートのように扱いましょう: 1つの着信リクエストは1つの保存されたイベントと見なします。たとえ処理が後で行われてもです。
最低限保存すべきもの:
received_atはペイロード内のタイムスタンプと別に保持する。例: 支払いプロバイダが「payment_succeeded」を送っているのに顧客が未払いのままに見える場合、イベントログに生のリクエストがあれば署名を確認し、正確な金額と通貨を確認できます。invoice_idが含まれていれば、サポートは請求書からイベントを見つけ、ステータスが“failed”で止まっていることを確認し、エンジニアに明確なエラー理由を渡せます。
AppMasterでは、Data Designerの「WebhookEvent」テーブルに、各ステップ完了時にステータスを更新するBusiness Processを組むという実用的なやり方があります。ツール自体が目的ではなく、一貫した記録が目的です。
各プロバイダが異なるペイロード形状を送ると、ログは常に散らかった印象になります。安定したイベントの“エンベロープ”を作れば、データが変わっても毎回同じフィールドを見られるためデバッグが速くなります。
有用なエンベロープには通常、次が含まれます:
id(ユニークなイベントID)type(invoice.paidのような明確なイベント名)created_at(イベントが発生した時刻、受信時刻ではない)data(ビジネスペイロード)version(例: v1)そのままログに保存できるシンプルな例:
{
"id": "evt_01H...",
"type": "payment.failed",
"created_at": "2026-01-25T10:12:30Z",
"version": "v1",
"correlation": {"order_id": "A-10492", "customer_id": "C-883"},
"data": {"amount": 4990, "currency": "USD", "reason": "insufficient_funds"}
}
snake_caseかcamelCaseのどちらかを選び、一貫して使ってください。型にも厳格であること: amountを時々文字列にして時々数値にしないでください。
バージョニングは保険です。フィールドを変更する必要があるときは、v2を公開してしばらくv1も動かし続けてください。これによりサポートのインシデントを防ぎ、アップグレードのデバッグがずっと楽になります。
署名検証はWebhookエンドポイントが野放しにならないようにするためのものです。検証がなければ、URLを知った誰でも偽のイベントを送れるし、攻撃者が実際のリクエストを改ざんしようとできます。
最も一般的なパターンは共有シークレットを使ったHMAC署名です。送信者は生のリクエストボディ(これが最良)や正規化した文字列に署名します。受け取り側はHMACを再計算して比較します。多くのプロバイダは、キャプチャされたリクエストのリプレイを防ぐために署名にタイムスタンプを含めます。
検証ルーチンは退屈で一貫しているべきです:
テスト可能にしてください。検証は小さな関数にまとめ、既知の正しいサンプルと間違ったサンプルでテストを書きます。よくある時間の無駄は、パース済みJSONに署名してしまうことです(生バイト列に署名すべき)。
シークレットローテーションを最初から計画してください。移行中に2つのアクティブなシークレットをサポートする: 新しいものをまず試し、次に前のものにフォールバックする。
検証が失敗したときは、秘密を漏らさずにデバッグできる十分な情報をログに残してください: プロバイダ名、タイムスタンプ(古すぎたかどうか)、署名バージョン、リクエスト/相関ID、生ボディの短いハッシュ(本体そのものではない)など。
リトライは普通のことです。プロバイダはタイムアウト、ネットワーク障害、5xxレスポンスのときにリトライします。たとえあなたのシステムが処理を完了していても、プロバイダがあなたの応答を受け取れなかったために同じイベントが再送されることがあります。
あらかじめどのレスポンスが「リトライ」か「停止」かを決めておきましょう。多くのチームは次のようなルールを使います:
冪等性とは、同じイベントを何度処理しても副作用が繰り返されないこと(二重請求、重複注文、二重メールを防ぐ)です。Webhookは少なくとも一度配信(at-least-once)されるものとして扱ってください。
実用的なパターンは、各着信イベントのユニークIDと処理結果を保存することです。再配信が来たら:
内部リトライには指数バックオフを使い、試行回数に上限を設けます。上限に達したら、イベントを「要確認」ステートに移し、最後のエラーを残してください。AppMasterでは、これはイベントIDとステータス用の小さなテーブルと、リトライをスケジュールして繰り返し失敗をルーティングするBusiness Processにきれいに対応します。
リトライは自動的に行われます。リプレイは意図的に行うものです。
リプレイツールは「送ったはずだ」を再現可能なテストに変え、まったく同じペイロードを再配信します。これが安全なのは、冪等性と監査証跡がある場合だけです。冪等性は二重請求・二重出荷・二重メールを防ぎ、監査証跡は誰が何をリプレイしたかと結果を示します。
単一イベントのリプレイは一般的なサポートケースです: 1人の顧客、1件の失敗イベント、修正後に再配信する。時間範囲リプレイはインシデント向けです: プロバイダが特定のウィンドウで障害を起こし、その期間に失敗したすべてを再送する必要があるときです。
選択をシンプルに保ってください: イベントタイプ、時間範囲、ステータス(failed, timed out, delivered but unacknowledged)でフィルタして、1件またはバッチでリプレイします。
リプレイは強力ですが危険であってはなりません。いくつかのガードレールを設けましょう:
リプレイ後は、元のイベントの横に結果を表示します: 成功、依然失敗(最新エラー付き)、または無視(冪等性により重複として検出)など。
Webhookがインシデントで壊れたとき、数分で答えが必要です。良いログは明確なストーリーを語ります: 何が届き、何をしたか、どこで止まったか。
受信時の生のリクエストはそのまま保存してください: タイムスタンプ、パス、メソッド、ヘッダ、生のボディ。プロバイダがフィールドを変えたりパーサがデータを誤読したとき、これが真実の基準になります。保存前に機密値(認証ヘッダ、トークン、不要な個人情報や支払い情報)はマスクしてください。
生データだけでは不十分です。検索可能なパース済みビューも保存しましょう: イベントタイプ、外部イベントID、顧客/アカウント識別子、関連オブジェクトID(invoice_id, order_id)、内部相関ID。これによりサポートは「顧客8142のすべてのイベント」を開かずに見つけられます。
処理中は一貫した文言で短いステップタイムラインを保ちます。例: “validated signature”, “mapped fields”, “checked idempotency”, “updated records”, “queued follow-ups”。
保持期間も重要です。実際の遅延や紛争をカバーするのに十分な履歴を残しつつ、永久に保持しないように。まず生のペイロードを削除または匿名化し、軽量なメタデータを長く残すことを検討してください。
受信側を小さなパイプラインとして明確なチェックポイントを持たせて構築します。すべてのリクエストが保存されたイベントになり、すべての処理実行が試行として記録され、すべての失敗が検索可能になります。
HTTPエンドポイントは取り込みのみと考えてください。最初に最小限の作業を行い、その後ワーカーに処理を移してタイムアウトが謎の動作を生まないようにします。
実際には、2つのコアレコードが欲しくなるでしょう: Webhookイベントごとに1行、処理試行ごとに1行。
堅牢なイベントモデルには: event_id, provider, received_at, signature_status, payload_hash, payload_json(またはraw payload), current_status, last_error, next_retry_at。試行レコードには: attempt_number, started_at, finished_at, http_status(該当する場合), error_code, error_text を保存できます。
データが揃ったら、サポートがevent ID、customer ID、時間範囲で検索し、ステータスでフィルタできる小さな管理ページを追加してください。シンプルで高速に保ちます。
パターンに基づいてアラートを設定しましょう。単発の失敗ではなく、例えば「5分でプロバイダが10回失敗」や「イベントがfailedに詰まっている」といったパターンです。
送信側を制御できるなら、次の3つを標準化してください: 常にイベントIDを含める、常に同じ方法でペイロードに署名する、リトライポリシーを平易な言葉で公開する。これにより、パートナーが「送った」と言い張ってあなたのシステムに何も残っていないときの無駄なやり取りを防げます。
よくあるパターンは、StripeのWebhookが注文レコードを作り、受領メール/SMSを送るという処理です。1つのイベントが失敗すると、顧客が課金されたか、注文が存在するか、受領メールが送られたか誰もわからなくなります。
現実的な失敗例: Stripeの署名シークレットをローテーションしたとします。数分間、あなたのエンドポイントはまだ古いシークレットで検証しているため、Stripeはイベントを送るがサーバは401/400で拒否する。ダッシュボードは「webhook failed」と表示され、アプリのログは「invalid signature」としか書いていない。
良いログは原因を明白にします。失敗したイベントのレコードには安定したイベントIDと、ミスマッチを特定するのに十分な検証詳細: 署名バージョン、署名タイムスタンプ、検証結果、明確な拒否理由(間違ったシークレット vs タイムスタンプのずれ)が表示されるべきです。ローテーション中はどのシークレットを試したか(例: “current” vs “previous”)をログに残すのも役立ちます(生の秘密はログに残さない)。
シークレットを修正して短いウィンドウで“current”と“previous”の両方を受け入れるようにしても、バックログを処理する必要があります。リプレイツールがそれを短時間のタスクに変えます:
ほとんどのWebhook問題は、システムが最終的なエラーだけを記録しているために謎のままになります。各配信を小さなインシデントレポートとして扱ってください: 何が届いたか、何を判断したか、次に何が起きたか。
よくあるミス:
実践的な修正:
AppMasterを使っているなら、これらは自然にプラットフォームにフィットします: Data Designerのイベントテーブル、検証と処理のためのステータス駆動のBusiness Process、検索とリプレイ用の管理UI。
毎回同じ基本を目指しましょう:
これらのうち1つでも欠けると、統合はブラックボックスになり得ます。生のペイロードを保存していなければ、プロバイダが何を送ったか証明できません。署名失敗が具体的でなければ、誰の責任かで何時間も議論する羽目になります。
素早くこれを組み立てたいがすべてを手で書く時間がないなら、AppMaster (appmaster.io)はデータモデル、処理フロー、管理UIを一つの場所で組み立てる手助けができます。最終的なアプリのために実際のソースコードも生成します。




