
機器予約アプリで競合を防ぎ、返却を追跡する
二重予約を防ぎ、返却と破損を記録し、故障した機器を保守対象にする機器予約アプリの設計方法を紹介します。
明確な状態、保守しやすいルール、単純なエスカレーション経路でSLAタイマーとエスカレーションをモデル化し、ワークフローアプリを変更しやすく保つ方法を学びます。
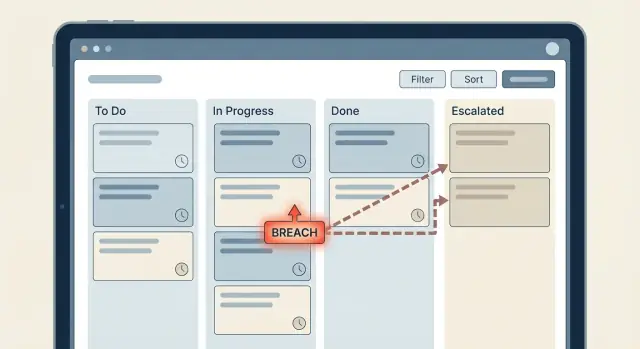
時間ベースのルールはたいてい単純に始まります。「チケットに2時間以内の返信がなければ誰かに通知する」。しかしワークフローが成長し、チームが例外を足し、気づけば誰も何が起きるかを正確に説明できなくなります。こうしてSLAタイマーとエスカレーションは迷路になります。
可動部分を明確に名前付けすると助かります。
タイマーはイベント(例:「チケットがWaiting for Agentに移動した」)の後に開始する時計です。エスカレーションはその時計が閾値に到達したときに行う処置(リードに通知する、優先度を変える、担当を変更するなど)です。**違反(ブリーチ)**は「SLAを守れなかった」という事実を記録したもので、レポート、アラート、フォローアップに使います。
時間ロジックがアプリ全体に散らばると問題が出ます:いくつかは「チケット更新」フローのチェック、さらに夜間バッチに別のチェック、特定顧客用のワンオフルールが後から追加される。各部分は個別には意味がありますが、合わせると驚きが生まれます。
典型的な症状:
目標は、後で変更しやすい予測可能な動作です。SLAタイミングの一つの明確な真実、レポートできる明示的な違反状態、そして視覚論理を探し回らずに調整できるエスカレーション手順を持つことです。
タイマーを作る前に、測る約束を正確に書き出してください。多くの混乱は最初からあらゆる時間ルールを網羅しようとするところから始まります。
よくあるSLAの種類は似ているようで測る対象が違います:
次に「時間」が何を意味するかを決めます。カレンダー時間は24時間365日を通してカウントします。**稼働時間(Working time)**は定義された営業時間のみをカウントします(例:月〜金、9〜18時)。本当に稼働時間が必要でなければ、初期段階では避けてください。祝日、タイムゾーン、部分日の扱いなどのエッジケースが増えます。
次にポーズ(pause)について具体化します。ポーズは単に「ステータスが変わった」ことではありません。所有者やルールを持つ定義です。誰がポーズできるのか(エージェントのみ、システムのみ、顧客のアクション)、どのステータスがポーズと見なされるか(Waiting on Customer、On Hold、Pending Approval)、何が再開になるのか、再開時に残り時間から続行するのか再スタートするのかを決めます。
最後に、製品上で違反が何を意味するかを定義します。違反は保存してクエリ可能な具体的なものにするべきです。たとえば:
例:「ファーストレスポンスSLA違反」はチケットにBreached状態を付け、breached_atタイムスタンプを保存し、エスカレーションレベルを1に設定する、という具合です。
SLAタイマーとエスカレーションを読みやすく保ちたいなら、SLAを小さなステートマシンとして扱ってください。「真実」が小さなチェック(if now > due、優先度が高いか、最後の返信が空か)に分散していると、ビジュアルロジックはすぐに混乱し、小さな変更で壊れます。
まず、すべてのワークフローステップが理解できる短い合意されたSLA状態のセットを決めます。多くのチームでは次があれば十分です:
単一のbreached = true/falseフラグだけではほとんどの場合不十分です。どのSLAが違反したのか(ファーストレスポンスか解決か)、現在ポーズ中かどうか、既にエスカレーションしたかどうかの文脈が必要です。その文脈がないと、人々はコメントやタイムスタンプ、ステータス名から意味を再導出し始め、ロジックが壊れやすくなります。
状態を明示的にし、説明するタイムスタンプを保存してください。すると判断が単純になります:評価ロジックがレコードを読み、次の状態を決め、他はその状態に反応します。
一緒に保存しておくと便利なフィールド:
started_at と due_at(どの時計を走らせていて、いつが期限か)breached_at(実際にラインを越えた時刻)paused_at と paused_reason(なぜ時計が止まったか)breach_reason(どのルールが違反を引き起こしたかを平易な文で)last_escalation_level(同じレベルに二度通知しないため)例:チケットが "Waiting on customer" に移動したら、SLA状態をPausedにして paused_reason = "waiting_on_customer" を記録し、タイマーを止めます。顧客が返信したら再開し、新しい started_at をセットする(またはアンポーズして due_at を再計算する)。こうすれば多くの条件を探して回る必要がありません。
エスカレーションラダーは、SLAタイマーが締切に近づいたときや既に締切を過ぎたときに何が起きるかの明確な計画です。間違いは組織図をそのままワークフローにコピーすることです。停滞した案件を動かすための最小限のステップが欲しいのです。
多くのチームが使うシンプルなラダー:担当エージェント(Level 0)に最初のリマインドを送り、次にチームリード(Level 1)、それでも動かなければマネージャー(Level 2)へ。現場で動ける人から始め、必要なときだけ権限を上げるので効果的です。
ワークフローのエスカレーションルールを保守しやすくするには、閾値をコードに埋め込むのではなくデータとして保存してください。テーブルや設定オブジェクトに「最初のリマインドは30分後」「リードへは2時間後にエスカレート」のように入れておけば、方針変更は一箇所を更新するだけで済みます。
エスカレーションは頻発するとスパムになります。各ステップに目的を持たせるためのガードレールを追加してください:
通知だけでは責任が曖昧なままでは作業は進みません。エスカレーション後の所有権ルールを事前に定義してください:チケットは担当者のままか、リードに再割り当てするか、共有キューに移すか。
例:Level 1エスカレーション後はチームリードに再割り当てし、元のエージェントをウォッチャーにする。次に誰が対応すべきかが明確になりますし、同じ案件が人の間で跳ね返るのを防げます。
SLAタイマーとエスカレーションを保守しやすくする最も簡単な方法は、それらをイベント、評価者(Evaluator)、アクションの三つの部分からなる小さなシステムとして扱うことです。これにより「if time > X」チェックが何十箇所にも散らばるのを防げます。
イベントは事実を表し、タイマー計算を含めるべきではありません。イベントは「何が変わったか?」に答え、「それについて何をするべきか?」は含まないようにします。典型的なイベントはチケット作成、エージェントの返信、顧客の返信、ステータス変更、手動のポーズ/再開などです。
これらをタイムスタンプやステータスフィールドとして保存します(例:created_at、last_agent_reply_at、last_customer_reply_at、status、paused_at)。
すべてのイベント後および定期スケジュールで動く「SLA評価者」ステップを一つ作ってください。この評価者が due_at や残り時間を計算する唯一の場所です。評価者は現在の事実を読み、締切を再計算し、sla_response_state や sla_resolution_state のような明示的なSLA状態フィールドを書き込みます。
ここで違反状態のモデリングがきれいに保たれます:評価者が OK、AtRisk、Breached といった状態を設定し、通知ロジックに計算を隠さないようにします。
通知、割り当て、エスカレーションは状態が変わったときだけトリガーするようにします(例:OK -> AtRisk)。メッセージ送信はSLA状態の更新から切り離しておき、通知先を変えるときに計算ロジックに触る必要がないようにします。
保守しやすいセットアップは通常、レコード上のいくつかのフィールド、シンプルなポリシーテーブル、そして何が次に起きるかを決める1つの評価者から成ります。
SLAを所有するエンティティ(チケット、注文、リクエスト)に明示的なタイムスタンプと「現在のSLA状態」フィールドを追加します。地味で予測可能に保つこと。
次にポリシーテーブルを追加してルールをフローにハードコーディングしないようにします。単純な構成例は、優先度ごとに1行(P1、P2、P3)を置き、目標分数とエスカレーション閾値(例:80%でWarning、100%でBreach)を列として持つことです。これにより1レコードを変更するだけで済みます。
あちこちにタイマーを作る代わりに、定期的にアイテムをチェックする1つのスケジュールプロセスを使います(厳密なSLAなら毎分、一般的なチームなら5分毎など)。このスケジュールは以下を行う評価者を呼びます:
sla_state と next_check_at を書き戻すこれによりデバッグは1つの評価者を見れば良くなり、複数のタイマーを追いかける必要がなくなります。
評価者は新しい状態とその変化の有無を出力するべきです。メッセージやタスクは状態が移ったときだけ発火するようにします(例:ok -> warning、warning -> breached)。レコードが1時間breachedのままでも、1時間に12回通知が飛ぶのは避けたいはずです。
実践的なパターンは、sla_state と last_escalation_level を保存し、新しく計算した値と比較してからメッセージ送信や内部タスク作成を行う、というものです。
ポーズは時間ルールが最も混乱しやすい箇所です。明確にモデル化しないとSLAは意図せず動き続けるか、誰かが誤ってクリックしただけでリセットされてしまいます。
単純なルール:時計を止めるのは一つのステータス(または小さなセット)のみとする。一般的にはWaiting for customerが選ばれます。チケットがそのステータスに入ると pause_started_at を記録し、顧客が返信してそのステータスを離れたら pause_ended_at を書き、総ポーズ秒数 paused_total_seconds に加算します。
単一のカウンタだけにせず、各ポーズウィンドウ(開始、終了、トリガーした主体)を記録して監査トレイルを残してください。後で「なぜこのケースが違反したのか?」と問われたときに、19時間顧客待ちだったことを示せます。
再割り当てや通常のステータス変更で時計を再スタートしてはいけません。SLAタイムスタンプは所有権フィールドとは分離しておきます。例:sla_started_at と sla_due_at は作成時(あるいはSLAポリシー変更時)にセットし、再割り当ては assignee_id のみ更新する。評価者は経過時間を次のように計算できます: now - sla_started_at - paused_total_seconds。
SLAタイマーとエスカレーションを予測可能に保つルール:
設計をテストする簡単な方法は、ファーストレスポンス30分とフル解決8時間の2つのSLAを持つサポートチケットです。ロジックが画面やボタンに散らばっているとここでよく壊れます。
各チケットは次を保存しているとします:state(New、InProgress、WaitingOnCustomer、Resolved)、response_status(Pending、Warning、Breached、Met)、resolution_status(Pending、Warning、Breached、Met)、そして created_at、first_agent_reply_at、resolved_at のようなタイムスタンプ。
現実的なタイムラインの例:
エスカレーションは状態遷移に基づく単一のチェーンにしておきます。例:レスポンスがWarningになったら担当エージェントに通知、Breachedになったらチームリードに通知して優先度を上げる、という具合です。
各ステップで同じ小さなフィールドセットを更新すれば理由を追うのが簡単になります:
response_status や resolution_status を Pending、Warning、Breached、Met に設定する。*_warning_at と *_breach_at タイムスタンプを一度だけ書き、上書きしない。escalation_level(0,1,2)をインクリメントし、escalated_to(Agent、Lead、Manager)を設定する。sla_events ログ行を追加してイベント種別と通知先を記録する。priority と due_at を設定してUIやレポートで反映させる。重要なのはWarningとBreachedが明示的な状態であることです。データ上でそれらを見られ、監査でき、ラダーを後で変えても隠れたタイマー条件を探す必要がありません。
SLAロジックは散らばると厄介です。ボタンに入れたちょっとした時間チェック、APIハンドラの条件、手動のアクションに埋め込まれたロジックが蓄積し、誰もチケットがなぜエスカレートしたか説明できなくなります。SLAタイマーとエスカレーションは小さく中央にまとめたロジックにして、すべての画面やアクションがそこに依存するようにしてください。
よくある落とし穴は時間チェックを多くの場所に埋め込むこと(UI、API、手動操作)。修正法は評価者でSLA状態を一箇所で計算し、その結果をレコードに保存することです。画面は状態を読み、独自に再計算しないでください。
別の落とし穴は異なる時計を使ってタイマーが食い違うことです。ブラウザが「作成からの分数」を計算し、バックエンドがサーバー時間を使うとスリープやタイムゾーン、夏冬時間で端境が出ます。エスカレーションをトリガーするものはサーバー時間を優先してください。
通知もすぐにうるさくなります。「毎分チェックして期限超過なら送る」型だと毎分スパムを出しかねません。遷移に結び付けて「warning sent」「escalated」「breached」のように各ステップで1回だけ送る設計にしてください。これで何が起きたかの監査も容易になります。
ビジネスアワーのロジックも別の複雑さの源です。すべてのルールに「週末なら…」の分岐があると、更新が面倒になります。ビジネスアワー計算は一つの関数(または共有ブロック)に置き、「これまでに消費されたSLA分を返す」ようにして再利用してください。
最後に、違反を再計算だけに頼らないでください:
breached_at に保存し、上書きしない。escalation_level と last_escalated_at を保存してアクションが冪等になるようにする。notified_warning_at のようなフィールドを保存して重複アラートを防ぐ。例:チケットが10:07に「レスポンスSLA違反」になったとき、再計算だけだと後でステータス変更やポーズ/再開バグで違反時刻が10:42に見えることがあります。breached_at = 10:07 を保存すればレポートや振り返りが一貫します。
タイマーやアラートを追加する前に、1ヶ月後でもルールが読みやすいことを目標に一度見直してください。
実践的なテスト:締切に近い1件のチケットを選び、そのタイムラインを再生してください。各ステータス変更で何が起きるか、ワークフロー全体を読まずに説明できなければモデルが散らばりすぎです。
まず最小の有用なスライスを作ってください。例えばファーストレスポンスSLA1つとエスカレーションレベル1つ(チームリードに通知)を実装する。完璧な設計を紙の上で考えるより、1週間の実動作から学べることが多いです。
閾値と受信者はロジックではなくデータにしておいてください。分数や時間、ビジネスアワーのルール、通知先、どのキューがケースを所有するかはテーブルや設定レコードに入れておくと、ビジネス側が数値やルーティングを調整してもワークフローの配線をいじる必要がありません。
シンプルなダッシュボードビューを早めに用意しましょう。大きな分析システムは不要で、現状を共有するための「On track、Warning、Breached、Escalated」が見える小さな画面で十分です。
ノーコードのワークフローアプリでこれを構築する場合、データ設計、ロジック、スケジュール評価を一箇所でモデル化できるプラットフォームを選ぶと楽です。たとえばAppMaster(appmaster.io)はデータベースモデル、ビジュアルな業務プロセス、実運用向けアプリを生成する機能を提供しており、「イベント/評価者/アクション」パターンに適しています。
安全に改善する順序の例:
小さなバージョンをまず作り、実際のフィードバックと本物のチケットで育てていってください。
最初に何を測るのか(ファーストレスポンスか解決かなど)を明確に定義し、正確な開始・停止・一時停止ルールを書き出してください。時間計算は一つの評価ロジックに集中させ、ワークフロー全体に「if now > X」のチェックをばらまかないようにするのが鍵です。
タイマーはイベント後に開始する時計、エスカレーションは閾値到達時のアクション(リードへの通知や優先度変更など)、違反(ブリーチ)はSLAが守られなかった事実として保存して報告に使うものです。
ファーストレスポンスは最初の意味のある人間の返信までの時間を測り、解決は問題が本当にクローズされるまでの時間を測ります。ポーズや再オープン時の振る舞いが異なるため、別々にモデル化した方がルールもレポートも正確になります。
デフォルトではカレンダー時間(24/7)を使うことを推奨します。ビジネスアワー(稼働時間)ルールは祝日、タイムゾーン、部分日の計算などの複雑さを招くので、本当に必要な場合にのみ追加してください。
「Waiting on Customer」のような特定のステータスに結びついた明示的なポーズとしてモデル化し、ポーズ開始・終了を記録してください。再開時に残り時間から続行するのか再計算するのかは評価ロジックの一箇所で扱い、ランダムなステータス切替で時計がリセットされないようにします。
単一のbreached = true/falseフラグではどのSLAが違反したのか、現在ポーズ中か、既にエスカレーション済みかといった文脈が分かりづらくなります。On track、Warning、Breached、Paused、Completedのような明示的な状態の方が予測可能で監査しやすくなります。
状態を説明するタイムスタンプを保存してください。たとえばstarted_at、due_at、breached_at、paused_at、paused_reasonのようなフィールドと、last_escalation_levelなどのエスカレーション追跡です。これらがあれば動作の説明や後追いが簡単になります。
実際に動ける人から始め、必要に応じてリード、マネージャーへと上げる小さなラダーが現実的です。閾値や受信者は設定データ(ポリシーテーブル)に置き、ルール変更時にワークフローを何箇所も編集せずに済むようにします。
通知は状態遷移(例えばOK -> WarningやWarning -> Breached)に結び付け、クールダウンや最大レベル、停止条件を設けて一歩ごとに一回だけ送るようにします。これで過剰な通知や重複を防げます。
イベントを記録し、単一の評価者が締切を計算して状態を設定し、アクションは状態変化にのみ反応する、という「イベント/評価者/アクション」のパターンを使ってください。AppMasterではデータモデル、ビジュアルな業務プロセス、プロダクション対応アプリ生成を同じプラットフォームで行えるので、このパターンと相性が良いです。




