
機器予約アプリで競合を防ぎ、返却を追跡する
二重予約を防ぎ、返却と破損を記録し、故障した機器を保守対象にする機器予約アプリの設計方法を紹介します。
pgvectorとマネージドベクトルデータベースの比較:セットアップの手間、スケーリングの懸念、フィルタと権限の扱い、典型的なアプリスタックへの適合性を解説します。
セマンティック検索は、ユーザーが「正しい」キーワードを使わなくても適切な答えを見つけられるようにします。単語の厳密な一致ではなく意味でマッチさせます。たとえば「ログインをリセットしたい」と入力しても、意図が同じなら「パスワードを変更して再度サインインする」という記事が表示されるべきです。
キーワード検索はビジネスアプリでは破綻しがちです。実際のユーザーは短縮語を使い、誤字をし、製品名を混同し、公式用語ではなく症状を説明します。FAQ、サポートチケット、ポリシードキュメント、オンボーディングガイドなどでは同じ問題が多様な言い回しで出てきます。キーワードエンジンは何も有用なものを返さないか、ユーザーをクリック漁りに追い込む長いリストを返すことが多いです。
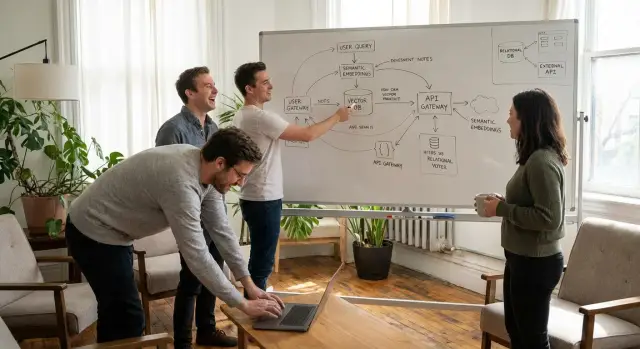
埋め込み(embeddings)は一般的な構成要素です。アプリは各ドキュメント(記事、チケット、製品メモ)を意味を表す数値ベクトルに変換します。ユーザーが質問すると、その質問も埋め込みに変換し、最も近いベクトルを探します。「ベクトルデータベース」はそのベクトルをどこに保存し、どう高速に検索するかを指します。
典型的なビジネススタックでは、セマンティック検索は次の4つに触れます:コンテンツストア(ナレッジベース、ドキュメント、チケットシステム)、埋め込みパイプライン(インポートと更新)、クエリ体験(検索ボックス、候補回答、エージェント支援)、そしてガードレール(権限とチーム、顧客、プラン、リージョンなどのメタデータ)です。
ほとんどのチームにとって「十分良い」ことは完璧を上回ります。実務的な目標は、初回で関連性が出ること、応答が1秒未満であること、コンテンツの増加に伴ってコストが予測可能であることです。その目標はツールの議論より重要です。
多くのチームは最終的に2つのパターンの間で選びます:PostgreSQL内にすべて置く(pgvector)か、メインDBの横に別のマネージドベクトルDBを追加するか。どちらが適切かは「どちらが良いか」よりも、複雑さをどこに置きたいかで決まります。
pgvectorはPostgreSQLの拡張で、ベクトル型とインデックスを追加し、通常のテーブルに埋め込みを保存してSQLで類似検索できるようにします。実務では、ドキュメントテーブルに本文、メタデータ(customer_id、status、visibility)と埋め込みカラムを含めることが多いです。検索は「クエリを埋め込み、埋め込みが最も近い行を返す」になります。
マネージドベクトルDBは埋め込み向けに構築されたホスティッドサービスで、ベクトルの挿入と類似検索のAPI、そして自前で実装するはずの運用機能を提供することが多いです。
両者ともコアの仕事は同じです:埋め込みをIDとメタデータとともに保存し、クエリに対して最も近い近傍を見つけてトップマッチを返す。アプリはそれを受け取って関連アイテムを表示します。
重要な違いは「システム・オブ・レコード」です。マネージドベクトルDBを使っても、アカウント、権限、請求、ワークフロー状態、監査ログなどの業務データはほぼ常にPostgreSQLに残します。ベクトルストアは検索のための取り出し層になり、アプリ全体の実行場所にはなりません。
一般的なアーキテクチャは次の通りです:Postgresに正本を置き、埋め込みはPostgres(pgvector)かベクトルサービスに保存し、類似検索で一致するIDを取得してからPostgresから完全な行を取得します。
AppMasterのようなプラットフォームでアプリを作るなら、PostgreSQLは構造化データと権限の自然なホームです。問いは、埋め込み検索もそこに置くか、Postgresはソース・オブ・トゥルースにして検索を専門サービスに任せるか、です。
チームはしばしば機能で選び、日々の作業量に驚きます。決定の本質は、複雑さを既存のPostgresに置くか別のサービスに置くかです。
pgvectorなら、既に運用しているDBにベクトル検索を追加することになります。セットアップは概ね素直ですが、それでもデータベースの作業であり単なるアプリコードではありません。
典型的なpgvectorのセットアップは、拡張の有効化、埋め込みカラムの追加、クエリパターンに合うインデックス作成(後で調整)、コンテンツ変更時の埋め込み更新方針決定、そして通常のフィルタも適用する類似度クエリ作成、などを含みます。
マネージドベクトルDBでは、メインDBの横に新しいシステムを作ります。SQLは減るかもしれませんが、統合のための接着仕事は増えます。
典型的なマネージドのセットアップは、インデックス(次元数と距離指標)の作成、APIキーのシークレット管理、埋め込みとメタデータをプッシュする取り込みジョブの構築、アプリレコードとベクトルレコードの安定したIDマッピングの維持、バックエンドだけが問い合わせできるようネットワークアクセスの制限などを含みます。
CI/CDとマイグレーションも異なります。pgvectorは既存のマイグレーションやレビュー工程に自然に入ります。マネージドサービスは設定変更や再インデックスのための明確な運用プロセスが必要になります。
オーナーシップも選択に従います。pgvectorはアプリ開発者やPostgres担当(時にDBA)の責任領域になりがちです。マネージドサービスはプラットフォームチームが所有し、アプリ開発者は取り込みとクエリロジックを担当することが多いです。よってこの決定は技術よりもチーム構成の問題でもあります。
セマンティック検索が役立つのは、ユーザーが見てよいデータだけを表示する場合です。実アプリでは各レコードに埋め込みの横にメタデータがあります:org_id、user_id、role、status、visibilityなど。検索レイヤーがそのメタデータでクリーンにフィルタできないと、混乱した結果が出るか、最悪の場合データ漏えいになります。
最も実務的な違いは「ベクトル検索の前にフィルタするか後にするか」です。後でフィルタするのは簡単に聞こえますが、二つの一般的な失敗を招きます。第一に、最良の一致が削られて悪い結果だけが残ること。第二に、パイプラインのどこかで未フィルタの結果がログやキャッシュに残り、セキュリティリスクが高まることです。
pgvectorなら、ベクトルとメタデータがPostgreSQL内にあるため、同じSQLクエリで権限を適用し、Postgresにそれを強制させられます。
アプリが既にPostgresを使っているなら、pgvectorは単純さの点で有利です。「ただの別のクエリ」にできます。チケット、顧客、会員情報を跨いだ結合が可能で、Row Level Securityを使えばデータベース自体が権限外の行へのアクセスを遮断します。
一般的なパターンは、orgやstatusなどで候補集合を絞り、その上でベクトル類似度を実行し、必要に応じて正確一致のキーワードマッチも混ぜる、というものです。
多くのマネージドベクトルDBはメタデータフィルタをサポートしますが、フィルタ言語が限られていたり結合ができなかったりします。通常はメタデータを各ベクトルレコードに冗長化し、権限チェックをアプリ側で再実装することになります。
ビジネスアプリのハイブリッド検索では、次の要素を連携させたいことが多いです:ハードフィルタ(org、role、status、visibility)、キーワードマッチ(請求書番号のような正確な識別子)、ベクトル類似度(意味)、ランキングルール(新しさや公開状態でブースト)。
例:AppMasterで作られたサポートポータルはチケットと権限をPostgreSQLに置けるため、「エージェントは自分の組織だけを見る」という制約を簡単に守りながら、チケット要約や返信に対してセマンティックマッチを実現できます。
検索品質は関連性(結果は役立つか)と速度(即時に感じるか)の組み合わせです。pgvectorでもマネージドベクトルDBでも、近似検索で若干の関連性を犠牲にしてレイテンシを下げることが多いです。このトレードオフは、実際のクエリで測定する限りビジネスアプリでは許容されることが多いです。
大きくは3つを調整します:埋め込みモデル(「意味」をどう表すか)、インデックス設定(どれだけ厳密に探索するか)、ランキング層(フィルタや新しさ、人気度を加えた後の並び替え)です。
PostgreSQL+pgvectorでは、IVFFlatやHNSWのようなインデックスを選ぶことが一般的です。IVFFlatは高速で作成コストが低いですが「リスト数」のチューニングが必要で、十分なデータ量になってから性能を発揮します。HNSWは低レイテンシでより良いリコールを出すことが多いですが、メモリを多く使い構築に時間がかかります。マネージドシステムも同様の選択肢を名前やデフォルトを変えて提供します。
いくつかの戦術は思ったより重要です:人気クエリをキャッシュする、可能ならバッチ処理で効率化する(例:次ページを事前取得)、高速なベクトル検索で上位20〜100件を取ってからビジネス信号(新しさ、顧客ランク)で再ランクする二段階フローを検討する、ネットワーク往復を注意する、などです。検索を別サービスに置くと、クエリごとにラウンドトリップが増えます。
品質を測るには、小さく具体的に始めてください。20〜50件の実際のユーザー質問を集め、「良い」答えの定義を作り、Top3/Top10のヒット率、中央値とp95レイテンシ、「良い結果がない」クエリの割合、権限・フィルタ適用後の品質低下を記録します。
ここで選択は理論から実務へ移ります。チームが維持できる調整で、ユーザーが受け入れるレイテンシで関連性目標を達成する方が最良です。
多くのチームはpgvectorで始めます。アプリデータと埋め込みを一箇所に置けるためです。多くのビジネスアプリでは、数万〜数十万ベクトルであれば単一のPostgreSQLノードで十分なことが多く、検索がトップのトラフィック要因でない限り問題になりません。
限界に達するのは、セマンティック検索がコアなユーザーアクションになったとき(あらゆるページやチケット、チャットで常に動く)、あるいは数百万ベクトルを保存しピーク時に厳しい応答時間が必要なときです。
単一Postgresが苦しくなったサインはよくあります:通常の書き込み時にp95検索レイテンシが跳ね上がる、速いインデックスと許容できる書き込み速度の両立が難しい、メンテ作業が「夜間にしかできない」イベントになる、検索とその他のDBで異なるスケーリング要求が出る、などです。
pgvectorのスケーリングは、クエリ負荷に対するリードレプリカ追加、テーブルのパーティショニング、インデックス調整、インデックス構築とストレージ増大への計画、という形になることが多いです。可能ですが継続的な作業になります。埋め込みを業務データと同じテーブルに置くか分離するかで、ボリュームやロック競合の扱いも変わります。
マネージドベクトルDBはベンダーが多くを肩代わりします。コンピュートとストレージの独立スケーリング、ビルトインシャーディング、高可用性を提供することが多いです。トレードオフは2つのシステム(Postgresとベクトルストア)を運用し、メタデータと権限を同期し続ける必要がある点です。
コストは性能よりチームを驚かせることが多いです。大きな要因はストレージ(ベクトルとインデックスの増大)、ピーククエリ量(しばしば請求額を決める)、更新頻度(再埋め込みやアップサート)、そしてデータ移動(フィルタ時の追加コール)です。
pgvectorとマネージドの間で迷うなら、どの痛みを選ぶかで決めてください:Postgresの深いチューニングと容量計画の手間を取るか、別依存を増やしてお金で楽を取るか、です。
セキュリティの詳細はしばしばベンチマークより早く決断を促します。データがどこにあり誰が見られるか、障害時にどうなるかを早めに確認してください。
保存場所とアクセスから始めましょう。埋め込みは意味を漏らす可能性があり、多くのチームはハイライトのために生のスニペットも保存します。どのシステムが生テキスト(チケット、ノート、ドキュメント)を持ち、どのシステムが埋め込みのみを持つかを明確にし、社内で誰がストアを直接問い合わせできるか、本番と分析環境を厳格に分ける必要があるかを決めてください。
どちらの選択肢でも次の質問を投げてください:
マルチテナント分離は人を躓かせるポイントです。ある顧客が決して他の顧客に影響を与えてはならない場合、強いテナントスコーピングがすべてのクエリで必要です。PostgreSQLならRow Level Securityと慎重なクエリで強制できます。マネージドベクトルDBではネームスペースやコレクション、アプリ側ロジックに頼ることが多いです。
検索がダウンした場合を想定してください。検索ストアが落ちたらユーザーは何を見るでしょうか。安全なデフォルトはキーワード検索にフォールバックするか、最近のアイテムだけを表示してページを壊さないことです。
例:AppMasterで作ったサポートポータルでは、チケットはPostgreSQLに残しセマンティック検索はオプション機能と扱えます。埋め込みが利用できない間は、ポータルはチケット一覧を表示し厳密検索で動作し続けることが可能です。
安全な決め方は、本番に近い小さなパイロットを回すことです。デモノートブックではなく、実際のアプリに近いものを作ってください。
まず、何を検索し何を必ずフィルタする必要があるかを書き出します。「ドキュメントを検索する」は曖昧です。「ヘルプ記事、チケット返信、PDFマニュアルを検索し、ユーザーが見られるものだけを表示する」は現実的な要件です。権限、テナントID、言語、プロダクト領域、公開済みのみなどのフィルタが勝敗を決めることが多いです。
次に埋め込みモデルと更新方針を決めます。何を埋め込むか(全文、チャンク、それとも両方)、どの頻度で更新するか(編集ごと、夜間、公開時)を決めます。コンテンツが頻繁に変わるなら、再埋め込みの負担を測ることが重要です。
それからバックエンドに薄い検索APIを作ります。単純に保ちましょう:クエリとフィルタを受け取りトップ結果を返し、動作をログする1つのエンドポイントで十分です。AppMasterで作るなら、取り込みと更新フローをバックエンドサービスとビジネスプロセスとして実装し、埋め込みプロバイダを呼び、ベクトルとメタデータを書き込みアクセスルールを適用できます。
実際のユーザーと実タスクで2週間ほどのパイロットを回します。よくある問いを数件使い、「見つかった」率と最初の有用な結果までの時間を測り、週ごとに悪い結果をレビューし、再埋め込み量とクエリ負荷を観察し、メタデータ欠落や古いベクトルなどの故障モードをテストします。
最後に証拠に基づいて決めます。pgvectorが品質とフィルタ要件を満たし運用負荷が許容できるなら残します。スケールと信頼性が優先ならマネージドに切り替えます。あるいはハイブリッド(PostgreSQLでメタデータと権限、ベクトルストアで検索)を取るのも実用的です。
多くのミスは最初のデモがうまくいった後に表れます。簡単な概念実証は良く見えますが、実ユーザー、実データ、実ルールを追加すると破綻します。
よく再作業に繋がる問題は次の通りです:
シンプルな「Day-2」テストで早期に検出できます:新しい権限ルールを追加し、20件を更新、5件を削除して同じ10個の評価クエリを再実行してください。AppMasterのようなプラットフォームで構築するなら、これらのチェックをビジネスロジックとDBモデルと一緒に計画しておくべきです。
中規模SaaS企業がサポートポータルを運営しており、主に2種類のコンテンツがあります:顧客チケットとヘルプセンター記事。検索ボックスに意味を持たせ、「電話を変えた後にログインできない」と入力すれば、適切な記事や類似の過去チケットが出てきてほしいというニーズです。
譲れない要件は実務的です:各顧客は自分のチケットしか見られない、エージェントはステータス(open、pending、solved)で絞れること、入力時に候補が出るためレスポンスは瞬時に感じられること、です。
ポータルが既にチケットと記事をPostgreSQLに保存しているなら(AppMasterのようなスタックでは一般的)、pgvectorを追加するのはクリーンな第一手です。埋め込み、メタデータ、権限を一箇所に置けるので「customer_123のチケットだけ」を返すのは通常のWHERE句で済みます。
このアプローチは、データセットが控えめ(数万〜数十万項目)で、チームがPostgresのインデックスやクエリプランの調整に慣れており、可搬性の少ない運用でシンプルに保ちたい場合に有効です。
トレードオフは、ベクトル検索がトランザクションワークロードと競合することです。利用が増えれば追加キャパシティや細かなインデックス調整、場合によってはチケット書き込みを保護するための別Postgresインスタンスが必要になります。
マネージドベクトルDBを使う場合、通常は埋め込みとIDをそちらに保存し、チケットの真実(status、customer_id、権限)はPostgreSQLに残します。実務では、まずPostgresで候補IDを絞ってから検索するか、検索してから権限を再チェックして表示するかのどちらかの流れになります。
この選択は成長が不確実であったり、パフォーマンスの世話をしたくないチームに有利ですが、権限の流れを慎重に設計しないと顧客間で結果が漏れるリスクがあります。
実用的な判断としては、今すぐ厳密なフィルタと単純な運用が必要ならpgvectorで始め、急速な成長や高負荷を予想するならマネージドに移行する計画を立てる、というのがよくある決め方です。
迷っているなら、機能の議論をやめて初日の要件を書き出してください。本当の要求は小さなパイロットで出てきます。
次の質問が勝敗を早く決めます:
また変化に備えてください。埋め込みは「設定して忘れる」ものではありません。テキストは変わり、モデルは変わり、関連性は人が不満を言うまでドリフトします。更新方針、ドリフト検出、監視指標(クエリレイテンシ、エラー率、小さなテストセットでのリコール、「結果なし」検索数)を事前に決めておきましょう。
検索を中心とした本格的な業務アプリを素早く進めたいなら、AppMaster (appmaster.io)は実用的な選択肢になり得ます:PostgreSQLのデータモデリング、バックエンドロジック、Web/モバイルUIをノーコードワークフローで提供し、コアのアプリと権限が整ってからセマンティック検索を反復的に追加できます。
セマンティック検索は、ユーザーの言葉がドキュメントの正確な語句と一致しなくても有用な結果を返します。サポートポータルや社内ツール、ナレッジベースで、綴り間違いや略語、症状の記述が多い場合に特に役立ちます。
移動する部品をなるべく少なくし、SQLベースの厳密なフィルタが欲しい場合はpgvectorが向いています。データ規模とトラフィックがまだ控えめな段階では、PostgreSQL内に埋め込みとメタデータを置くのが安全で速い道になることが多いです。
ベクトル数やクエリ量の急成長を見込んでいたり、検索のスケーリングや可用性をメインDBの外で解決したい場合は、マネージドベクトルDBが適しています。ただし別システムの運用と権限管理の統合に注意が必要です。
埋め込みはテキストを意味を表す数値ベクトルに変換するプロセスです。ベクトルデータベース(またはPostgreSQLのpgvector)はそれらを保存し、ユーザーの埋め込みクエリに最も近いベクトルを素早く探せるようにするために使います。これが「意図で類似」を実現する仕組みです。
ベクトル検索の後でフィルタをかけると、最良の一致が削られて残り物になったり、空の結果を返したりします。またパイプラインのどこかで未フィルタの結果がログやキャッシュに残ると情報漏えいのリスクが高まります。できるだけ早い段階でテナントやロールのフィルタを適用する方が安全です。
pgvectorなら埋め込みとメタデータが同じPostgreSQLにあるため、類似検索と同じSQLで権限や結合を適用できます。Row Level Securityを使えば、データがある場所で不正アクセスを防げるため「許可されない行を表示しない」ことを保証しやすくなります。
多くのマネージドベクトルDBはメタデータフィルタをサポートしますが、結合はできずフィルタ言語が限定的なことが多いです。権限関連のメタデータを各ベクトルに冗長化し、アプリケーション側で最終的な認可チェックを行う設計になることが一般的です。
大きなドキュメントはチャンク化(分割)して埋め込む方が精度が上がります。短い項目なら全文を1つのベクトルにするだけで十分なこともありますが、長いチケットやポリシー、PDFは分割しないと曖昧な結果になりやすく、バージョン管理も必要になります。
初めから更新設計をしておいてください。頻繁に変わるコンテンツは公開・編集時に再埋め込みし、ソースレコードが削除されたらベクトルも必ず削除する必要があります。これを怠ると、古い内容や存在しないテキストを指す結果を返してしまいます。
実際のクエリと厳格なフィルタを使った小さなパイロットを行い、関連性とレイテンシ、障害時の挙動を測定するのが安全な判断方法です。権限ルール下でもトップの結果が安定して良いと判断でき、コストや運用負荷がチームで維持できる方を選んでください。




