
機器予約アプリで競合を防ぎ、返却を追跡する
二重予約を防ぎ、返却と破損を記録し、故障した機器を保守対象にする機器予約アプリの設計方法を紹介します。
ノーコードアプリのリリース管理:実用的なブランチと環境の構成、ロールバック計画、要件変更後の素早い回帰チェック。
プラットフォームがモデルや視覚的ロジックからアプリを再生成する場合、リリースは「ちょっとした変更の出荷」ではなく「家を建て直す」ように感じられます。コードをきれいに保てる利点はありますが、手書きコードで身につけた多くの習慣が通用しなくなります。
再生成されるコードでは、数ファイルをパッチするような作業はありません。データモデルやワークフロー、画面を変えるとプラットフォームが新しいアプリの版を生成します。AppMaster ではバックエンド、Web、モバイルが同じ変更セットから同時に更新されることもあります。利点は累積したゴミがたまらないこと、代償は小さな編集が想定より広い影響を及ぼす可能性があることです。
問題はたいてい次のように現れます:
「安全」とは「何も問題が起きない」という意味ではありません。リリースが予測可能で、問題はユーザーの報告前に出てきて、ロールバックが迅速で単調な作業であることを意味します。これを達成するには、明確な昇格ルール(dev→staging→prod)、緊張下でも従えるロールバック計画、そして実際に変わった箇所に結びついた回帰チェックが必要です。
これはソロビルダーや頻繁に出荷する小さなチーム向けです。週次や日次でリリースするなら、たとえプラットフォームがワンクリックで全てを再生成できても、変更が日常に感じられるルーチンが必要です。
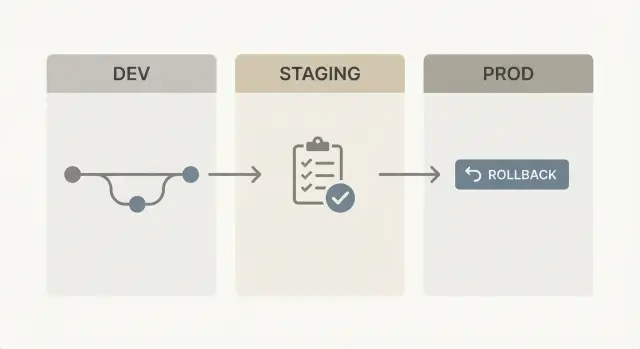
ノーコードでも最も安全なセットアップは最もシンプルなものです:役割がはっきりした3つの環境。
Dev は意図的に壊して作る場所です。AppMaster ではデータモデル編集、ビジネスプロセス調整、UI の素早い反復を行います。速度重視で安定性は二の次です。
Staging はリハーサルです。本番のように見えて振る舞うべきですが、実際の顧客が依存してはいけません。再生成されたビルドが認証、Stripe 支払い、メール/SMS、Telegram などの連携を含めてエンドツーエンドで動くことを確認するのが目的です。
Prod は実際のユーザーと実データの場所です。本番での変更は再現可能かつ最小限であるべきです。
チームを整列させる実務的な分担:
自信に基づいて昇格させ、カレンダーに基づいて動かないでください。画面、ロジック、権限、データ変更がまとまって機能テスト可能になったら dev から staging に移し、クリーンなデプロイで一度、軽い設定変更後にもう一度、主要フローを実行して問題がないことを確認してから staging から prod に移します。
緊張時の混乱を減らす簡単な命名ルール:
ステージングは「ほぼ終わりの作業置き場」ではなく、本番の挙動のコピーとして扱ってください。
ブランチはコードジェネレータを守るためではなく、本番の動作を守るためのものです。
本番と一致し、常にリリース可能な主線ブランチから始めます。AppMaster の文脈では、この mainline は現在の Data Designer のスキーマ、ビジネスプロセス、ユーザーが頼る UI 状態を表します。
実務的セットアップ:
フィーチャーブランチは小さく短く保ちます。変更がデータ、ロジック、UI にまたがる場合は、アプリが動く状態を保つように 2~3 回に分けてマージしてください(機能はトグルで隠すか管理者のみ可にしてもよい)。
複数チームが同週に出すような場合を除き、リリースブランチは使わず頻繁に main にマージしてブランチの乖離を減らします。
いくつかのマージルールで「再生成のサプライズ」を防げます:
例:承認ステップを追加するなら、まずワークフローロジックをマージして旧ルートが動き続けるようにし、次に UI と権限をマージする。小さなステップに分けるほど回帰は見つけやすくなります。
一貫性とはすべてをクローンすることではなく、正しいものを同一に保つことです。
アプリ定義(データモデル、ロジック、UI)は安全に前進させつつ、各環境は自分の設定を持ちます。実務的には dev、staging、prod は同じ生成コードと同じスキーマルールを使い、環境固有の値(ドメイン、サードパーティのエンドポイント、レート制限、機能トグル)だけを変えます。
シークレットは必要になる前に計画を立てておきましょう。API キー、OAuth クライアントシークレット、Webhook はプロジェクト所有ではなく環境所有にしてください。シンプルなルールが有効です:開発者は dev のシークレットを読める、ステージングはより少人数、prod はほとんど誰も読めない。キーは定期的にローテーションし、本番キーが開発ツールに流出したら即時ローテーションします。
ステージングは失敗を検出する点で本番と同じにし、リスクを作らないようにします:
可能でなければ本番データをステージングにコピーするのは避けてください。どうしてもコピーするなら個人データはマスクし、コピーは短期間に限定します。
例:ビジネスプロセスに新しい承認ステップを追加する場合、ステージングではテスト用の Stripe アカウントとテスト Telegram チャネル、さらに本番の最大注文を模した合成注文を用意します。こうすれば顧客を晒すことなく壊れた条件や欠けた権限を見つけられます。
AppMaster を使っているなら、環境ごとにアプリ設計を一貫させ、デプロイごとに環境設定とシークレットだけを変える規律が、リリースを予測可能にする鍵です。
プラットフォームが変更後にコードを再生成する場合、最も安全な習慣は小さなステップで進み、各ステップの検証を容易にすることです。
変更を小さく、テスト可能な要件に落とす。 非技術の同僚が確認できる一文にする(例:「マネージャーは承認メモを追加でき、マネージャー承認までリクエストは Pending のまま」)。確認項目を2~3個付ける(誰が見られるか、承認/拒否時に何が起きるか)。
dev で作り、頻繁に再生成する。 AppMaster では通常、Data Designer の更新(データ変更がある場合)、Business Process ロジックの調整、その後再生成してアプリを実行します。変更は狭く保ち、何が原因で壊れたか分かるようにします。
同じバージョンをステージングにデプロイしてフルチェックする。 ステージングは本番設定にできる限り近づけ、連携はステージング用の安全なアカウントで確認します。
リリース候補を作り短時間フリーズする。 あるビルドを RC に選び、短時間だけ(30~60 分でも)マージを止めてテスト結果を有効にします。問題があればその問題だけを修正して新しい RC を切ります。
本番にデプロイし、主要なユーザーフローを検証する。 リリース直後に収益や業務を支える3~5のフローを簡単に確認します(ログイン、リクエスト作成、承認、エクスポート/レポート、通知など)。
ステージングで不明点があれば中断してください。冷静な遅延は急いでロールバックするより安いです。
再生成されるコードでは「ロールバック」の意味を明確に決めておく必要があります。事前に次のどれを指すか決めてください:
多くのインシデントでは両方が必要です:コードを戻し、サードパーティ接続やトグルを既知の良好な状態に戻す。各環境(dev、staging、prod)について、リリースタグ、デプロイ日時、承認者、変更点を簡単に記録しておきましょう。AppMaster ではデプロイした正確なアプリ版とその時の環境変数・連携設定を保存しておくことが重要です。緊張した状況でどのビルドが安定だったかを推測してはいけません。
データベースの変更が高速ロールバックを最も妨げます。変更を可逆と不可逆に分けてください。nullable カラムの追加は通常可逆です。カラムの削除や値の意味を変える変更は多くの場合不可逆です。リスクの高い変更には迅速に出せるホットフィックスの道筋を用意し、必要ならリリース直前に復元点(バックアップ)を取っておきます。
実行しやすいロールバック計画の例:
ステージングで練習してください。月に一度は模擬インシデントを実行して、ロールバックが体で覚える動作になるようにします。
最良の回帰チェックは破壊しうる範囲に結びついています。フォームに新しいフィールドを追加するだけなら全てを再テストする必要はほとんどありませんが、バリデーション、権限、下流の自動化に影響を与えることがあります。
まずブラスト半径を名前付けしてください:どの画面、ロール、テーブル、連携が影響を受けるか。そこを横切るパスと、常に動作すべきコアフローをテストします。
ゴールデンパスは毎リリース必ず通す必須ワークフローです:
期待される結果を平易な言葉で書いておきます(何が見えるか、何が作られるか、どのステータスになるか)。それが繰り返せる完了の定義になります。
連携はミニシステムのように扱います。変更後は UI が問題なく見えても、各連携について1回の簡単な確認を行ってください。例:Stripe の支払いが完了する、メールテンプレートが正しくレンダリングされる、Telegram のメッセージが届く、AI 呼び出しが使える応答を返す、など。
静かな失敗を捕まえるためのデータチェックをいくつか追加します:
AppMaster のようなプラットフォームでは、編集後にアプリが再生成されるため、焦点を絞ったチェックが新しいビルドが意図外に振る舞いを変えていないことを確認する助けになります。
本番投入直前に目指すのは完璧ではなく、最も痛い障害を捕まえることです:サインイン不能、誤った権限、連携失敗、静かなバックグラウンドエラー。
ステージングを本番のドレスリハーサルにしてください。AppMaster では通常、ステージングに対して新鮮なビルドとデプロイを行い(半端な更新ではない)、本番に出すものをそのままテストします。
約10分で行える5つのチェック:
自動化を使うなら、1つのスケジュール/非同期ジョブをトリガーして重複実行(同じレコードや二重請求)をしていないかを確認する静かな失敗チェックを追加してください。
チェックが失敗したらリリースを止め、再現手順を正確に書き留めます。再現可能な問題を直す方が、出してから運任せにするより速いです。
オペスチームが購入リクエストを承認する内部ツールを使っています。現状は申請者が送信し、マネージャーが承認する二段階です。要件:$5,000 超のものに対して finance 承認を追加し、finance が承認/却下したら通知を送る。
これを独立した変更として扱います。安定した mainline(現在本番にあるバージョン)から短命の feature ブランチを作り、まず dev で作ります。AppMaster では通常 Data Designer(新しいステータスやフィールド)、Business Process Editor でのロジック追加、その後 Web/Mobile UI の更新を行います。
dev で動いたら同じブランチをステージングに昇格させます(設定スタイルは同じ、データは別)。特に権限やエッジケース周りを意図的に壊してみてください。
ステージングでテストする項目:
静かな時間帯に本番へデプロイします。本番に入れる前に以前の prod リリースをすぐ再デプロイできるように用意しておきます。データ変更を含めたなら、ロールバックが「旧バージョンを再デプロイするだけ」なのか、それとも「旧バージョン+小さなデータ修正」なのかを事前に決めておきます。
変更内容を数行で文書化してください:追加したもの、ステージングでテストしたこと、リリースタグ/バージョン、最大のリスク(通常は権限や通知)。次回要件が変わっても素早く動けます。
痛いリリースは大きなバグ1つが原因なことは稀です。どこを変えたか、何が変わったか、どう元に戻すかが見えにくくなる近道を踏んだ結果です。
よくある落とし穴は「準備ができるまで長期間ブランチを残す」ことです。ブランチはズレ、誰かが dev で修正し、staging をいじり、本番をホットフィックスする。数週間後、どれが現実のバージョンか誰にも分からなくなり、マージは賭けになります。AppMaster のようなプラットフォームでは短命ブランチと頻繁なマージで変更を分かりやすく保ちます。
別のキラーは「小さな変更だから」とステージングを飛ばすことです。小さな変更はしばしば共有ロジックに触れます:バリデーションルール、承認ステップ、支払いコールバック。UI の変更が小さく見えても副作用は本番で出ます。
本番での手動修正も高コストです。誰かが本番で環境変数、機能フラグ、支払いキー、Webhook を「ちょっとだけ」変えると再現性を失います。すべての本番設定変更をリリースの一部として記録し、毎回同じ方法で適用してください。
ロールバックの誤りは特に致命的です。チームがアプリ版だけロールバックしてデータが前進していることを忘れると、古いコードが新しいデータに対して失敗します。スキーマ変更や新しい必須フィールドがあれば、単にバージョンを戻すだけでは済まないことを前提にしてください。
これらを防ぐ習慣:
「完了」のシグナルがなければ、リリースは本当に終わらないまま次の緊急対応にフェードしていきます。
リリースストレスはリリース当日に下す判断から生まれます。解決策は一度決めて書き留め、それを繰り返すことです。
ブランチルールを誰でも従える平易な言葉で1ページにまとめてください。変更の「完了」とは何か(実行するチェック、サインオフ、リリース候補の定義)を定義します。
厳密な構造が欲しいなら、シンプルなルールセットは:
環境をわざと違わせてください。Dev は速い変更用、Staging はリリースを証明する場所、Prod は顧客のための場です。Prod のアクセスを厳しくし、Staging に明確なリリースゲートのオーナーを置きます。
AppMaster を使っているなら、プラットフォームの「クリーンなソースコードを再生成する」アプローチは、規律ある環境と短いゴールデンパスチェックと組み合わせることで最も力を発揮します。ツールを評価するチーム向けに言えば、AppMaster (appmaster.io) はバックエンド、Web、ネイティブモバイルを含むフルアプリを対象に設計されており、この種のリリースルーチンに特に向いています。
小さく、より頻繁に出荷しましょう。ペース(週次や月2回など)を決め、それを通常の作業として扱ってください。小さなリリースはレビューが速く、ロールバックが簡単になり、「うまくいけばいいな」となる瞬間が減ります。
3つの環境を使いましょう:dev は素早い変更用、staging は本番相当のリハーサル、prod は実際のユーザー用です。これによりリスクを抑えつつ頻繁にリリースできます。
再生成は意図以上の範囲を作り直すことがあるためです。共有フィールド、ワークフロー、権限などの小さな変更がスクリーンやロール全体に波及するため、ユーザーに届く前に確実に検出できる繰り返し可能な手順が必要になります。
ステージングは本番動作を再現するリハーサルとして扱ってください。スキーマルールや主要な連携は同じにしつつ、ステージング用の安全なアカウントと別のシークレットを使って本番のユーザーや資金を危険に晒さずにエンドツーエンドで検証します。
本番と常に一致するリリース可能な mainline ブランチを起点に、単一の変更ごとに短命な feature ブランチを使います。安定化が必要なときだけ release ブランチを作り、hotfix は最小限にします。
変更を小さく分割して、それぞれがアプリを動く状態に保つことです。例えばワークフローを先にマージして旧ルートを残し、その後でUIや権限、厳しいバリデーションを順に入れると回帰を見つけやすくなります。
APIキーやシークレットは環境ごとに管理し、誰が読めるかを限定してください。特に本番は読み取り権限を厳しくし、別々のキーを環境ごとに使い、定期的にローテーションし、本番キーが開発ツールに流出したら即座に回転させます。
1つのテスト済みビルドを RC(リリース候補)として選び、テスト結果が有効な短時間だけマージを止めます。問題が見つかればその問題だけを修正して新しい RC を切りましょう。テスト中に別の変更を追加すると検証が無意味になります。
事前にロールバックの定義を決めておきます:以前のビルドをデプロイするのか、以前の設定を復元するのか、あるいはその両方か。多くの事故ではコードと設定の両方が戻る必要があります。その後で主要な3~5個のフローを素早く検証します。
スキーマやバリデーションの変更はロールバックを難しくすることが多いです。可逆な変更(nullable カラムの追加など)を優先し、リスクの高い変更は事前に迅速に直せるホットフィックスや、リリース直前のバックアップを用意しておきます。
毎回ゴールデンパスの短いセットを実行し、変更のブラスト半径内だけを重点的にテストします。さらに連携ごとに1回のスモークチェックを行って、UI が正常でも静かな失敗を早期に見つけます。




