
機器予約アプリで競合を防ぎ、返却を追跡する
二重予約を防ぎ、返却と破損を記録し、故障した機器を保守対象にする機器予約アプリの設計方法を紹介します。
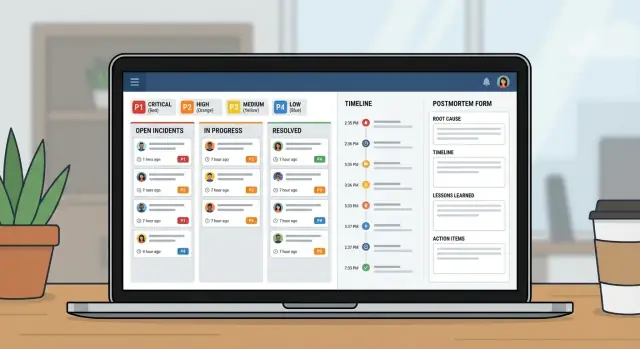
重大度ワークフロー、明確な所有権、タイムライン、ポストモーテムを1つの内部ツールで計画・構築する方法。
障害が発生すると、多くのチームは開いているものに手当たり次第頼ります:チャットスレッド、メールのやり取り、あるいは誰かが空いた時間に更新するスプレッドシート。プレッシャーがかかると、その仕組みは毎回同じように崩れます:所有権が曖昧になり、タイムスタンプが失われ、意思決定がスクロールの彼方に消えます。
シンプルなインシデント管理アプリは基本を解決します。インシデントが1カ所にまとまり、明確なオーナー、全員が合意する重大度、いつ何が起きたかのタイムラインが残ります。その単一の記録が重要なのは、どのインシデントでも同じ質問が出るからです:誰がリードしているのか?いつ始まったのか?現在の状況は?既に試したことは何か?
共有レコードがなければ、引き継ぎで時間が無駄になります。サポートは顧客にあることを伝え、エンジニアリングは別の対応をしている。マネージャーは更新を求めて対応者の手を止めてしまう。あとで誰も自信を持ってタイムラインを再現できず、ポストモーテムは推測に頼るものになります。
目的は監視やチャット、チケットを置き換えることではありません。アラートは他の場所から始まっても構いません。重要なのは意思決定の軌跡を記録し、人間の連携を保つことです。
IT運用やオンコールエンジニアは対応の調整に使います。サポートは正確な更新を素早く出すために使います。マネージャーは対応者を邪魔せずに進捗を確認できます。
9:12 AMに監視がカスタマーポータルの500エラーの急増を検出します。サポート担当からも「多くのユーザーでログイン失敗」と報告が入ります。オンコールのITリードがインシデントアプリでP1インシデントを作成し、最初のアラートとサポートのスクリーンショットを添付します。
P1だと振る舞いが速く変わります。インシデントオーナーはバックエンドの担当、データベース担当、サポートのリエゾンを招集します。非必須作業は停止し、計画済みのデプロイも止めます。チームは更新の頻度(例:15分ごと)に合意します。共通の通話が始まっても、インシデントの記録が唯一の真実の場です。
9:18 AMに「何が変わった?」という質問が出ます。タイムラインには8:57 AMのデプロイが記録されていますが、何がデプロイされたかは書かれていません。バックエンド担当はとりあえずロールバックします。エラーは減少し、再び戻ります。チームはデータベースを疑い始めます。
遅延の多くは予測できる場所に現れます:曖昧な引き継ぎ(「それを見ていると思ってた」)、文脈の欠如(最近の変更、既知のリスク、現在の担当者)、チャットやチケット、メールに散らばった更新。
9:41 AMにデータベース担当がスケジュールされたジョブによる暴走クエリを発見します。ジョブを無効化し、影響を受けたサービスを再起動して復旧を確認。重大度は監視のためP2に下げられます。
良いクローズとは「直った」だけではありません。きれいな記録です:分単位のタイムライン、最終的な根本原因、誰がどの決定をしたか、何が一時停止されたか、オーナーと期日付きのフォローアップ作業。こうしてストレスフルなP1が繰り返しの痛みではなく学びになります。
良いインシデントツールは主に良いデータモデルです。レコードがあいまいだと、インシデントが何か、いつ始まったか、何が未解決かで議論になります。
コアのエンティティはITチームが既に話している形に近づけてください:
後で混乱を避けるために、インシデントには常に埋められる構造化フィールドをいくつか用意してください。フリーテキストは役立ちますが、それだけに頼ってはいけません。実用的な最小項目は、明確なタイトル、影響(ユーザーが何を体験しているか)、影響を受けるサービス、開始時刻、現在のステータス、重大度です。
関係性は余計なフィールドより重要です。1つのインシデントは多数の更新と多数のタスクを持ち、サービスとは多対多でリンクします(障害は複数システムに影響することが多いため)。ポストモーテムはインシデントと1対1にして、最終的なストーリーを1つにします。
例:"Checkout errors" のインシデントはサービス「Payments API」と「PostgreSQL」にリンクし、15分ごとの更新があり、「ロールバック」「リトライガード追加」などのタスクがあります。後でポストモーテムに根本原因がまとめられ、長期タスクが作られます。
人がストレスを受けているときには、全員が同じ意味で理解できる単純なラベルが必要です。P1〜P4を平易な言葉で定義し、重大度フィールドのすぐ横に定義を表示してください。
対応目標はコミットメントのように読めるようにします。単純な基準(実情に合わせて調整):
| 重大度 | 最初の応答(受領) | 最初の更新 | 更新頻度 |
|---|---|---|---|
| P1 | 5分 | 15分 | 30分ごと |
| P2 | 15分 | 30分 | 60分ごと |
| P3 | 4時間 | 1営業日 | 毎日 |
| P4 | 2営業日 | 1週間 | 週次 |
エスカレーションルールは機械的にしておくとよいです。P2が更新頻度を逃したり影響が拡大したら、システムが重大度の再評価を促すべきです。混乱を避けるために、重大度を変更できるのは限定された人(多くはインシデントオーナーやインシデントコマンダー)にしつつ、誰でもコメントでレビューを依頼できるようにします。
インパクトマトリクスを用意すると重大度を素早く決められます。必要項目として:影響ユーザー数、収益リスク、安全性、コンプライアンス/セキュリティ、回避策の有無を捕捉します。
インシデント中に人々が必要なのはオプションの多さではなく、次に何をすべきかが明確になる少数の状態です。
普段うまくいっているときの手順から始め、リストは短く保ってください。状態が6〜7個以上になると、チームは文言の議論を始めてしまい、本来の問題解決が進みません。
実用的なセット:
各ステータスには明確な入出条件を設けます。例えば:
遷移で人が忘れがちなフィールドを強制してください。一般的なルール:短い根本原因要約と最低1件のフォローアップがないとインシデントを閉じられない、という具合です。“RCA: TBD”を許すと、そのまま残りがちです。
インシデントページは一目で次の3つに答えられるべきです:誰が担当か、次のアクションは何か、最後の更新はいつか。
インシデントが騒がしいときに時間を失う最速の方法は曖昧な所有権です。アプリは1人を明確に責任者にしつつ、他の人が手を貸しやすくすべきです。
単純で有効なパターン:
割り当ては明示かつ監査可能にします。誰がオーナーを設定したか、誰が承認したか、以降の変更履歴を追跡してください。“Accepted(受諾)”は重要です。誰かを割り当ててもその人が寝ていたりオフラインだと実際の所有権になりません。
オンコール割り当てとチームベース割り当ては重大度で使い分けるとよいです。P1/P2ではオンコールのローテーションをデフォルトにして必ず名前がつくようにします。低い重大度ではチームベースで問題ありませんが、短時間で1人の主要オーナーを必須にしてください。
休暇や障害を人のプロセスだけでなく仕組みでも扱う計画を立ててください。割り当てられた人が不在設定なら、セカンダリのオンコールやチームリードに自動ルーティングします。自動化しつつも修正が見えるようにしてください。
エスカレーションは重大度と沈黙の両方で発火させます。出発点として有用な例:
良いタイムラインは共有の記憶です。インシデント中は文脈がすぐ失われます。適切な瞬間を1カ所に記録すれば、引き継ぎが容易になり、ポストモーテムは誰かがドキュメントを開く前にほぼ書かれた状態になります。
タイムラインは意見を持たせてください。チャットログにしてはいけません。多くのチームは検知、受領、主要な緩和ステップ、復旧、クローズのような少数のエントリを頼りにします。
各エントリにはタイムスタンプ、作成者、短い平易な説明が必要です。遅れて参加した人が5件読めば状況を理解できるべきです。
異なる更新は異なる対象に向いています。エントリにタイプを持たせると便利です(内部メモ(生の詳細)、顧客向け更新(表現を安全にしたもの)、決定(なぜ選んだか)、引き継ぎ(次の人が知るべきこと)など)。
リマインダーは個人の好みではなく重大度に従わせます。タイマーが鳴ったらまず現在のオーナーに通知し、それでも繰り返し無視されればエスカレーションします。
通知は対象を絞り、予測可能にします。作成時、重大度変更時、復旧時、更新の期限超過時に通知する小さなルールセットで十分です。全社に毎回通知するのは避けてください。
ポストモーテムには2つの仕事があります:平易な言葉で何が起きたかを説明すること、そして同じ故障が再発しにくくすること。
書き出しは短くし、アウトプットをアクションに強制してください。実用的な構成は:要約、顧客影響、根本原因、実施した修正、フォローアップです。
フォローアップが要点です。段落で終わらせないでください。各フォローアップを担当者と期日付きの追跡タスクに変えてください。たとえ期日が「次のスプリント」でも構いません。それが「監視を改善すべき」から「Alexが金曜日までにDB接続飽和のアラートを追加する」への違いです。
タグは後でポストモーテムを有用にします。各インシデントに1〜3個のテーマを追加してください(監視の穴、リリース、キャパシティ、プロセスなど)。1か月後には多くのP1がリリース由来かアラート不足由来かといった基本的な問いに答えられます。
証拠は添付しやすく、必須にしないでください。スクリーンショット、ログスニペット、外部システムへの参照(チケットID、チャットスレッド、ベンダーのケース番号)を任意で添付できるようにして、軽量に保ち、人が実際に記入するようにします。
これはスプレッドシートに列を増やしただけのものではなく、小さなプロダクトとして扱ってください。良いインシデントアプリは実際に3つのビューで構成されます:今何が起きているか、次に何をするか、そして後で何を学ぶか。
プレッシャー下で人が開く画面をスケッチすることから始めます:
データモデルと権限設定を同時に作ってください。誰でも全部を編集できると履歴が乱れます。一般的なアプローチは:ITには広い閲覧権限、ステートや重大度の変更は制御、対応者は更新を追加でき、ポストモーテム承認には明確なオーナーがいること。
次に半端なインシデントを防ぐワークフロールールを追加します。必須フィールドは状態に依存させます。"New"ならタイトルと報告者だけでよいが、"Mitigating"には影響の要約を必須にし、"Resolved"には根本原因の要約と最低1件のフォローアップを必須にする、といった具合です。
最後に過去のインシデント2〜3件を再現してテストします。1人がインシデントコマンダー役、1人がレスポンダー役を演じます。どのステータスが不明瞭か、どのフィールドを飛ばすか、どこにデフォルトが必要かがすぐ見えてきます。
多くのインシデントシステムが失敗する理由は単純です:ストレス下でルールを覚えられない、アプリが後で必要な事実を捕らえない。
6つの重大度や10の状態があると人は推測します。重大度は3〜4に抑え、状態は次に何をすべきかに集中させてください。
誰もが“見ている”だけだと誰もそれを進めません。インシデントが前に進む前に必ず1人の名前付きオーナーを要求し、引き継ぎは明示的にしてください。
"いつ何が起きたか"がチャット履歴頼みだとポストモーテムが議論になります。開いた、受領、緩和、解決のタイムスタンプを自動取得し、タイムラインエントリは短く保ってください。
また曖昧な根本原因メモ("ネットワークの問題")で閉じるのは避けてください。明確な根本原因の一文と少なくとも1件の具体的な次ステップを要求します。
全IT組織に展開する前に基本をストレステストしてください。最初の2分で適切なボタンが見つからなければ、人はチャットやスプレッドシートに戻ります。
短めのローンチチェックに注力します:役割と権限、明確な重大度定義、所有権の強制、リマインダールール、応答目標未達時のエスカレーション経路。
まずは1チームと頻繁にアラートが出る数サービスでパイロットを行い、2週間運用して実際のインシデントに基づき調整してください。
もしスプレッドシートや別アプリをつなぎ合わせずに単一の内部ツールとして構築したければ、AppMaster (appmaster.io) は一つの選択肢です。データモデル、ワークフロールール、Web/モバイルのインターフェースを一箇所で作れるので、インシデントキュー、インシデントページ、ポストモーテム追跡にうまく合います。
散在する更新を1つの共有レコードに置き換え、次の基本をすばやく答えられるようにします:誰がインシデントを担当しているか、ユーザーが何を経験しているか、何が試されたか、次に何をするか。これにより、引き継ぎで失う時間、矛盾したメッセージ、要約を求める中断が減ります。
顧客やビジネスへの実害があると判断したら、根本原因が不明でもインシデントを立て始めてください。仮のタイトルや「影響不明」として開いておき、範囲や重大度が確定したら詳細を詰めていけばよいです。
小さく構造化しておくこと:明確なタイトル、影響の要約、影響を受けるサービス、開始時刻、現在のステータス、重大度、そして1人のオーナー。状況が進むにつれて更新とタスクを追加しますが、主要な事実をフリーテキストだけに頼らないでください。
議論にならないように3〜4レベルにまとめ、誰でも理解できる平易な定義にします。デフォルト例としては、P1はコアのダウンやデータ損失リスク、P2は回避策のある主要機能障害、P3は小規模な影響、P4は軽微・見た目の問題です。
約束のように感じられる目標を設定します:応答時間、最初の更新までの時間、更新の頻度。更新の頻度が守られなければリマインダーやエスカレーションを起動してください。インシデント中の“沈黙”が本当の失敗であることが多いです。
6つ前後に抑えたステータスを目指します:New、Acknowledged、Investigating、Mitigating、Monitoring、Resolved。各状態が次に何をすべきかを明確にし、ストレス下で人が忘れがちな項目を遷移で強制します(例えばAcknowledged前に所有者を必須にするなど)。
1人のプライマリオーナーを必須にして、その人が対応を主導し、更新を投稿する責任を持つようにします。受諾(Accepted)を記録して、割り当てた相手がオフラインだと実際の所有権にならない状況を避けます。引き継ぎは記録されたイベントにしてください。
検出、承認、主要な決定、緩和ステップ、復旧、クローズを各エントリとして記録し、各エントリにタイムスタンプと作成者を付けます。チャットの書き起こしではなく共有の“記憶”として扱い、後から来た人が数件読めば状況を把握できるようにします。
短く具体的に:何が起きたか、顧客への影響、根本原因、緩和中に行った変更、そしてオーナーと期限付きのフォローアップ項目。書かれた文章も重要ですが、同じ失敗を防ぐのは追跡されたタスクです。
はい。インシデント、更新、タスク、サービス、ポストモーテムを実際のデータとしてモデル化し、アプリ内でワークフロールールを適用すれば可能です。AppMasterでは、データモデル、ワークフロー、Web/モバイル画面を一箇所で作れるので、プレッシャー下でスプレッドシートに戻るリスクを減らせます。




