
機器予約アプリで競合を防ぎ、返却を追跡する
二重予約を防ぎ、返却と破損を記録し、故障した機器を保守対象にする機器予約アプリの設計方法を紹介します。
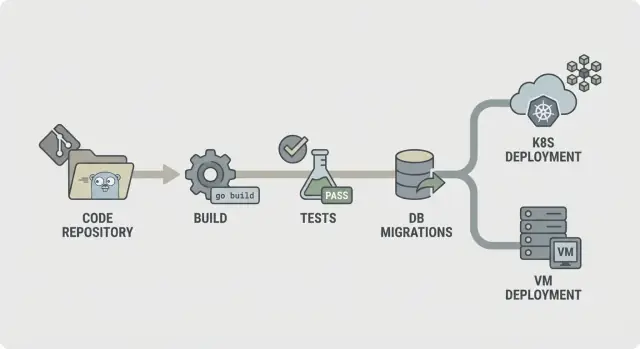
Goバックエンド向けCI/CD:ビルド、テスト、マイグレーション、KubernetesやVMへの安全なデプロイのための実践的なパイプライン手順(予測可能な環境を前提)。
手動のデプロイは、つまらない繰り返しミスで失敗します。誰かがローカルで別のGoバージョンでビルドしたり、環境変数を忘れたり、マイグレーションを飛ばしたり、間違ったサービスを再起動したりします。リリースは「自分の環境では動く」けれど本番では動かず、ユーザーが気づいて初めて問題が発覚します。
生成されたコードだからといってリリースの規律が不要になるわけではありません。要件を更新してバックエンドを再生成すると、新しいエンドポイントやデータ形、依存関係が導入されることがあり、手でコードを触っていなくても差分が出ます。まさにそういうときにパイプラインが安全柵のように働いてほしいのです:すべての変更は毎回同じチェックを通ります。
予測可能な環境とは、ビルドとデプロイのステップが名前をつけて再現できる条件で動くことです。いくつかのルールで大部分はカバーできます:
Goバックエンド向けのCI/CDの目的は、単なる自動化ではなく、再現可能でストレスの少ないリリースです:再生成してパイプラインを回し、出てきたものがデプロイ可能だと信頼できること。
AppMasterのようなジェネレータ(AppMasterやappmaster.io)を使ってGoバックエンドを生成する場合、これがさらに重要になります。再生成は便利な機能ですが、変更から本番までの道筋が一貫してテストされ再現可能であるときにだけ安全に感じられます。
“予測可能”とは、同じ入力がどこで実行しても同じ結果を生むことを意味します。GoバックエンドのCI/CDでは、まず開発・ステージング・本番で何を同一に保つか合意するところから始めます。
通常の非交渉項目は、Goのバージョン、ベースOSイメージ、ビルドフラグ、設定の読み込み方法です。どれかが環境ごとに変わると、TLSの挙動が違ったり、システムパッケージが足りなかったり、本番でしか出ないバグが生じます。
環境差分は大抵次の場所に現れます:
KubernetesとVMのどちらを選ぶかは「どちらが最適か」ではなく、チームが落ち着いて運用できるかが重要です。
Kubernetesはオートスケーリングやローリングアップデート、多数のサービスを標準化して実行したい場合に適しています。また、Podが同じイメージから動くため一貫性を高めます。VMはサービスが一つか少数でチームが小さく、構成要素を減らしたい場合に有効です。
ランタイムが異なってもパイプラインを同じに保つことは可能です。アーティファクトとその周囲の契約を標準化すればよい例として:CIで常に同じコンテナイメージをビルドし、同じテストを走らせ、同じマイグレーションバンドルを公開する。デプロイの実装だけ変える:Kubernetesならイメージタグを当て替え、VMならイメージをプルしてサービスを再起動する。
実用例:チームがAppMasterでGoバックエンドを再生成し、ステージングはKubernetes、本番は現時点でVMを使うとします。両方がまったく同じイメージを引き、同じ種類のシークレットストアから設定を読み込むなら、“異なるランタイム”はデプロイの詳細に過ぎず、バグの原因にはなりません。AppMaster(appmaster.io)を使っている場合、このモデルは管理されたクラウドターゲットにデプロイするか、ソースをエクスポートして自前のインフラで同じパイプラインを動かすどちらにも適合します。
予測可能なパイプラインは説明が簡単です:コードをチェックして、ビルドして、動作を証明し、テストしたのと同じものを出荷し、毎回同じ方法でデプロイする。バックエンドを再生成する場合(たとえばAppMasterから)、変更が多数のファイルに及ぶことがあり、迅速で一貫したフィードバックがより重要になります。
シンプルなGoバックエンド向けCI/CDの流れは次の通りです:
失敗が早く止まるように構成してください。lintで失敗したらそれ以降は何も走らないべきです。ビルドが失敗したら、統合チェック用にDBを起動するような無駄は避けます。これでコストを下げ、パイプラインを速く感じさせます。
すべてのステップをすべてのコミットで走らせる必要はありません。一般的な分け方は:
アーティファクトとして何を保持するか決めてください。通常はコンパイル済みバイナリかコンテナイメージ(デプロイ対象)と、マイグレーションログやテストレポートです。これを残しておくとロールバックや監査が簡単になります。どのアーティファクトがテストされプロモートされたかを正確に示せるからです。
ビルド段階は一つの問いに答えるべきです:今日も明日も別のランナーでも同じバイナリを作れるか。これができないと、後の全てのステップ(テスト、マイグレーション、デプロイ)は信頼できなくなります。
まず環境を固定します。固定のGoバージョン(例: 1.22.x)と固定のランナーイメージ(Linuxディストロとパッケージの版)を使い、「latest」タグは避けます。libcやGit、Goツールチェーンの小さな差分で「自分の環境では動く」問題が生じ、デバッグが厄介になります。
モジュールキャッシュは速度向上になりますが、真実のソースではありません。Goビルドキャッシュやモジュールダウンロードキャッシュは使いつつも、go.sumでキーを切る(依存が変わったらmainでクリアする)などして、新しい依存はクリーンにダウンロードされるようにします。
コンパイルの前に短時間で済むゲートを入れてください。開発者が回避しないように短くて素早いチェックが望ましい。典型的には gofmtチェック、go vet、可能ならstaticcheck を入れます。生成済みファイルの欠落や古さを検出して失敗させるのも重要です。再生成されたコードベースでよくある問題です。
再現可能にコンパイルし、バージョン情報を埋め込みます。-trimpath のようなフラグや、-ldflagsでコミットSHAやビルド時刻を注入する方法があります。サービスごとに一つの名前付きアーティファクトを生成すると、KubernetesやVM上で何が動いているか追跡しやすくなります。再生成する場合は特に有効です。
テストは毎回同じ方法で実行されて初めて役に立ちます。まずは速いフィードバックを優先し、そのあとで予測可能な時間内に終わる深いチェックを追加します。
コミットごとにユニットテストを走らせ、ハードタイムアウトを設定してテストがハングしたらパイプライン全体を止めること。カバレッジの「十分さ」をチームで決めておくとよいですが、カバレッジ自体は目的ではなく最低限の基準を示すものです。
安定したテスト段階の例:
go test ./... をパッケージごとのタイムアウトとグローバルなジョブタイムアウトで実行レースデテクタは有用ですがビルドを大幅に遅くします。PRやナイトリービルド、あるいは選択したパッケージだけで走らせるのが現実的な折衷案です。
フレークするテストはビルドを失敗させるべきです。どうしても隔離する必要があるなら、別ジョブに移して可視化したままにし、オーナーと修正期限を必須にしてください。
デバッグのためにテスト出力を保存しておきます。生ログと簡潔なレポート(合否、所要時間、遅いテスト上位)を残すと、特に再生成で多くのファイルに触れた変更の回帰を見つけやすくなります。
ユニットテストはコード単体で動くことを確認します。統合チェックはサービス全体が起動して実際のサービスに接続し、正しく振る舞うかを確認します。これはすべてが繋がったときにしか出ない問題を捕まえる安全網です。
必要ならエフェメラルな依存(一時的なPostgreSQL、Redisなど)をジョブごとに立ち上げます。本番に近いバージョンを使いますが、すべての本番詳細をコピーする必要はありません。
良い統合段階は意図的に小さくします:
API契約チェックは、壊れたときに最も影響が大きいエンドポイントに集中します。400で必須フィールドが拒否される、認証が必要なときは401が返る、ハッピーパスは200で期待されるJSONキーを含む、などの少数の真実で十分です。
統合テストを頻繁に回せる速度に保つには、スコープを絞り、時間を制御してください。小さなデータセットを使った一つのDBで、数件のリクエストだけ実行し、起動がハングしたら秒単位で失敗させます。
AppMasterでバックエンドを再生成する場合、これらのチェックは特に重要です。再生成されたサービスが問題なく起動し、フロントエンドが期待するAPIを提供していることを確認してくれます。
まずマイグレーションをどこで実行するか決めます。CIで実行して早期にエラーを捕まえるのは有効ですが、CIが本番に触れるべきではないことが多いです。多くのチームはデプロイ中にマイグレーションを実行するか、デプロイ前に完了させる独立した「migrate」ジョブを使います。
実践的なルールは:CIでビルドとテストを行い、マイグレーションは本番に近い環境と資格情報で実行する。KubernetesならワンオフのJob、VMならリリース手順内のスクリプトが一般的です。
順序は予想以上に重要です。タイムスタンプ付きファイルや連番を使い、「順番に一度だけ適用」を強制してください。可能ならマイグレーションを冪等にして、再試行しても重複や途中クラッシュを引き起こさないようにします。
マイグレーション戦略はシンプルに保ちます:
何か実行する前にセーフティゲートを入れてください。例えば単一実行のデータベースロックや、「破壊的変更は承認が必要」といったポリシーです。パイプラインが DROP TABLE や DROP COLUMN を含むマイグレーションを検出したら、本番では手動承認が必要になるようにするとよいでしょう。
ロールバックは厳しい現実です:多くのスキーマ変更は元に戻せません。列を削除したらデータは戻りません。ダウンマイグレーションは本当に安全な場合だけ用意し、そうでない場合はバックアップと前向きな修正に頼る計画を立ててください。
各マイグレーションには復旧計画を付けます:途中で失敗したらどうするか、アプリをロールバックする必要があるときにどう対応するか。AppMasterのようにGoバックエンドを生成している場合、マイグレーションはリリース契約の一部として扱い、生成されたコードとスキーマが同期するようにしてください。
デプロイするものが常にテストしたものと同じであるときに、パイプラインは予測可能に感じられます。それはパッケージングと設定にかかっています。ビルド出力を封印されたアーティファクトとみなし、環境差分はすべて外に置きます。
パッケージ化の道筋は主に2つです。Kubernetesにデプロイするならコンテナイメージがデフォルトです。OSレイヤーを固定しロールアウトを一貫させます。VM向けバンドルでも、コンパイル済みバイナリとランタイムに必要な最小限のファイル(CA証明書、テンプレート、静的資産など)を含め、毎回同じ方法でデプロイすれば同等に信頼できます。
設定はバイナリに焼き込まず外部に置きます。大部分の設定には環境変数を使い(ポート、DBホスト、フィーチャーフラグ)、長く構造化された値だけ設定ファイルにします。設定サービスを使うなら、それを依存として扱い、アクセス制御と監査ログ、フォールバックを明確にします。
シークレットは絶対に越えてはいけない線です。リポジトリにもイメージにもCIログにも置かないでください。起動時に接続文字列を出力しないようにし、CIのシークレットストアに保存してデプロイ時に注入します。
アーティファクトを追跡可能にするため、すべてのビルドに識別情報を埋めます:コミットSHA付きでタグ付けし、ビルドメタデータ(バージョン、コミット、ビルド時刻)をinfoエンドポイントに含め、デプロイログにアーティファクトタグを記録する。これで「今動いているのは何か」を一つのコマンドやダッシュボードで答えられます。
AppMasterでGoバックエンドを生成している場合、この規律はさらに重要です:再生成が安全なのは、アーティファクト名付けと設定ルールが毎回のリリースを再現しやすくしているときです。
多くのデプロイ失敗は「悪いコード」ではなく、環境の不一致が原因です:設定の違い、シークレットの欠如、起動はするが実際には準備ができていないサービスなど。目標はシンプルです:同じアーティファクトをすべての環境でデプロイし、変わるのは設定だけにすること。
Kubernetesではコントロールされたロールアウトを目指します。ローリングアップデートを使って徐々にPodを置き換え、リードネスとライブネスのチェックを追加してプラットフォームがトラフィック送信やハングしたコンテナの再起動を判断できるようにします。リソースのrequestsとlimitsも重要です。CIの大きなランナーで通っても、小さなノードでOOMキルされることがあります。
設定とシークレットはイメージの外に置きます。コミットごとに一つのイメージをビルドし、環境ごとの設定はデプロイ時に注入(ConfigMaps、Secrets、またはシークレットマネージャ)します。こうするとステージングと本番は同じバイナリで動きます。
仮想マシンにデプロイする場合、systemdが小さなオーケストレータの役を果たします。作業ディレクトリ、環境ファイル、再起動ポリシーを明確にしたユニットファイルを作成し、stdout/stderrをログコレクタやjournaldに送るようにして、インシデント時にSSHで探索する事態を避けます。
クラスタがなくても安全なロールアウトは可能です。ブルー/グリーン方式は単純で有効です:2つのディレクトリ(またはVM)を用意してロードバランサを切り替え、前のバージョンを素早くロールバックできる状態にしておきます。カナリアも同様で、新バージョンに少量のトラフィックを流して問題を確認してから全面展開します。
デプロイを「完了」とマークする前に、どこでも同じポストデプロイスモークチェックを実行してください:
AppMasterで生成したバックエンドでもこのアプローチは有効です:一度ビルドしてアーティファクトをデプロイし、環境設定で違いを吸収することで、場当たり的なスクリプトに頼らない運用ができます。
壊れたリリースの多くは「悪いコード」ではなく、パイプラインの振る舞いが実行ごとに異なることが原因です。Goバックエンド向けCI/CDを落ち着いて予測可能にするには、次のパターンに注意してください。
デプロイごとにガードなしで自動的にマイグレーションを実行するのは古典的な失敗です。テーブルロックを伴うマイグレーションは負荷の高いサービスを停止させます。本番では承認が必要なステップにする、再実行可能にするなどの対策を。
latest タグやアンピンのベースイメージを使うのも原因です。DockerイメージとGoバージョンを固定してビルド環境のドリフトを防ぎます。
環境をまたいで一時的にデータベースを共有するのも、恒常化しやすく、テストデータがステージングへ流れ、本番に影響を与える原因になります。環境ごとに別のデータベースと資格情報を使ってください。
ヘルスチェックやリードネスチェックがないと、デプロイが「成功」してもサービスは壊れており、トラフィックが早く流れてしまいます。アプリが起動しDBに接続できてリクエストを捌けるかを確認するチェックを入れてください。
最後に、シークレットや設定、アクセスの所有者が不明確だとリリースは推測作業になります。誰がシークレットを作り、回転させ、注入するかを明確にしておきます。
現実的な失敗例:チームが変更をマージしパイプラインがデプロイ、マイグレーションが自動で始まる。ステージングではデータが少なくて完了するが、本番では大量データでタイムアウトしてしまう。イメージを固定し、環境分離し、ゲート付きのマイグレーションにしていれば、安全に止められていたはずです。
AppMasterで生成する場合、再生成が多くのファイルに触るのでこれらのルールはさらに重要です。入力を予測可能にし、明示的なゲートを置くことで大きな変更がリスクの高いリリースになるのを防げます。
GoバックエンドのCI/CDについて、各項目に明確に「はい」と答えられればリリースは楽になります。
本番アクセスは限定し監査可能にします。CIは専用のサービスアカウントでデプロイし、シークレットは集中管理し、手動の本番操作は誰が何をいつやったかの記録が残るようにします。
4人の小さなオプスチームが週1回リリースします。プロダクトチームがワークフローを繰り返し改善するので、バックエンドの再生成を頻繁に行います。彼らの目標は単純:夜中の緊急対応を減らし、誰も驚かないリリース。
金曜日の典型的な変更:customers に新しいフィールドを追加(スキーマ変更)し、それを書き込むAPIを更新(コード変更)。パイプラインはこれらを一つのリリースとして扱います。一つのアーティファクトをビルドし、その正確なアーティファクトでテストを実行し、その後にマイグレーションを適用してデプロイします。こうするとデータベースがコードより先に進んだり、コードがスキーマと合っていないままデプロイされることがなくなります。
スキーマ変更があるとパイプラインにセーフティゲートが入ります。マイグレーションが増分(nullableなカラム追加など)かをチェックし、カラム削除や大規模なテーブル書き換えのような危険な操作はフラグを立てて本番前で止めます。チームはマイグレーションを書き直すか、計画されたウィンドウで実行します。
テストに失敗したら何も先に進みません。プレプロダクション環境でマイグレーションが失敗しても同様です。パイプラインは「今回は特別に押し通す」ような挙動をしてはいけません。
多くのチームに有効な簡単な次のステップ:
AppMasterでバックエンドを生成しているなら、再生成を同じパイプライン段階内に収めてください:再生成→ビルド→テスト→安全な環境でマイグレーション→デプロイ。生成されたソースを他のソースと同様に扱い、タグ付けされたバージョンから同じ手順で再現できるようにします。
Goのバージョンとビルド環境を固定して、同じ入力が常に同じバイナリやイメージを生成するようにします。これで「自分の環境では動く」差分が減り、失敗の再現と修正が容易になります。
再生成はエンドポイントやデータモデル、依存関係を変える可能性があり、誰も手作業で編集していなくても差分が出ます。パイプラインを通すことで、そのような変更も常に同じチェックを受け、安全に進められます。
一度ビルドして、そのままdev→staging→prodへとプロモートしてください。環境ごとに再ビルドすると、同じコミットでもテストしていないビルドを出荷してしまう危険があります。
PRごとに高速ゲートを通すのが良いです:フォーマット、基本的な静的チェック、ビルド、タイムアウト付きのユニットテスト。速くて厳格にしておくと、誰も回避しなくなります。
サービスをプロダクションに近い設定で起動し、PostgreSQLなど実際の依存サービスに接続してごく短いスイートを回す形にします。目的は「コンパイルは通るが起動しない」を捕まえることで、CIを数時間のE2Eにしないことです。
マイグレーションは暗黙で毎回実行するものではなく、明確に管理されたリリース手順として扱ってください。ログを残し、単一実行のロックを使い、巻き戻しが難しい変更は承認を必須にします。
Kubernetesではリードネスチェックを導入して、新しいPodが本当に準備できてからトラフィックを送るようにします。Livenessチェックでハングしたコンテナを再起動し、現実的なリソース要求と制限を設定してください。これが最もよくある問題の原因です。
仮想マシンの場合、systemdのユニットファイルと一貫したリリーススクリプトがあれば十分に安定したデプロイが可能です。アーティファクトモデルはコンテナと同じにして、デプロイ後に小さなスモークチェックを走らせましょう。
シークレットはリポジトリにもイメージにもCIログにも置かないでください。デプロイ時にマネージドなシークレットストアから注入し、誰が読めるかを制限し、定期的なローテーションを運用に組み込みます。
再生成は他の変更と同じパイプライン内で扱います:再生成→ビルド→テスト→パッケージ→ゲート付きでマイグレートとデプロイ。AppMasterで生成しているなら、この流れに乗せることで何が変わったかを推測する必要がなくなります。




