
機器予約アプリで競合を防ぎ、返却を追跡する
二重予約を防ぎ、返却と破損を記録し、故障した機器を保守対象にする機器予約アプリの設計方法を紹介します。
長時間実行されるワークフローは複雑に失敗しがちです。明確な状態パターン、ステップ単位のリトライ、デッドレター処理、そしてオペレータが信頼できるダッシュボードの作り方を解説します。
長時間実行されるワークフローは、短いリクエストとは違った形で失敗します。短いAPIコールは即座に成功かエラーになりますが、数時間や数日かかるワークフローは10ステップ中9ステップが成功していても混乱を残します:中途半端に作成されたレコード、わかりにくいステータス、次に何をすべきか不明、などです。
だから「昨日は動いていた」がよく出てきます。ワークフロー自体は変わらなくても、周囲の環境が変わるからです。長時間ワークフローは他サービスの健全性、資格情報の有効性、データの形が期待どおりであることに依存します。
よくある失敗モードは次の通りです:タイムアウトや遅い依存先(パートナーAPIが動いていても今日は40秒かかる)、部分的な更新(Aは作られたがBは作られず安全に再実行できない)、依存先の障害(メール/SMSプロバイダ、決済ゲートウェイ、メンテナンスウィンドウ)、コールバックやスケジュールの見落とし(Webhookが届かない、タイマージョブが実行されない)、そして人が介在するステップの停滞(承認が何日も放置され、再開時には前提が古くなっている)などです。
厄介なのは状態です。短いリクエストは終了するまでメモリに状態を保持できますが、ワークフローはそうできません。ステップ間で状態を永続化し、再起動やデプロイ、クラッシュ後に再開できる必要があります。また同じステップが二度トリガーされる(リトライ、重複Webhook、オペレータのリプレイ)ことにも対処しなければなりません。
実際には「信頼できる」とは決して失敗しないことではなく、「予測可能で説明可能、復旧可能で所有が明確」なことです。
予測可能とは、依存先が失敗したときに毎回同じように振る舞うこと。説明可能とは、オペレータが1分以内に「どこで詰まっているか、なぜか」を答えられること。復旧可能とは、被害を与えず安全に再試行や続行ができること。所有が明確とは、詰まったアイテムに対して次の明確な行動(待機、リトライ、データ修正、人への引き渡し)があることです。
単純な例:オンボーディング自動化が顧客レコードを作り、アクセスをプロビジョニングし、歓迎メッセージを送るとします。プロビジョニングは成功したが、メールプロバイダが落ちてメッセージ送信に失敗した場合、信頼できるワークフローは「Provisioned, message pending」と記録してリトライをスケジュールします。プロビジョニングを盲目的に再実行しません。
ツールはワークフローロジックと永続データを近づけることで楽にしてくれます。たとえばAppMasterではData Designerでワークフロー状態をモデル化し、Business Processesから更新できます。しかし信頼性はツールではなくパターンから来ます:長時間実行の自動化を、時間や障害、人の介入に耐えられる一連の耐久的な状態として扱いましょう。
長時間ワークフローは繰り返し起きる失敗を抱えがちです:サードパーティAPIが遅くなる、人が承認していない、ジョブがキューの後ろにある、など。明確な状態はそうした状況を一目でわかるようにし、「時間がかかっている」ことと「壊れている」ことを混同させません。
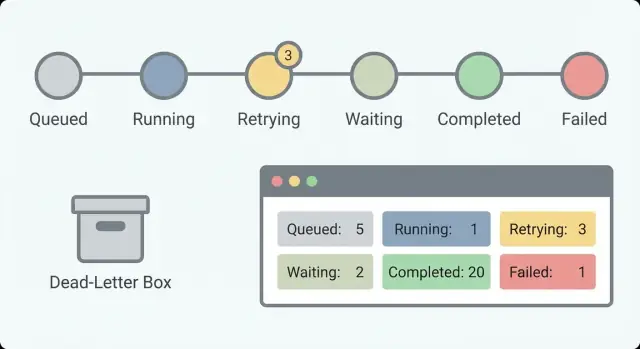
現在何が起きているかを答える小さな状態セットから始めてください。状態が30個もあると誰も覚えられません。5〜8個程度ならオンコールの人が一覧を見て理解できます。
多くのワークフローで実用的な状態例:
WaitingとRunningを分けることは重要です。「顧客の回答待ち」は正常です。「6時間実行中」はハングの可能性があります。この分離がないと誤検知を追いかけ、本当の問題を見逃します。
状態名だけでは不十分です。ステータスを実用的にするためにいくつかのフィールドを追加します:
例:あるオンボーディングフローが「Waiting」で理由が「上長承認待ち」、最終変更が「2日前」と表示されれば、ハングではなくリマインドが必要だとわかります。
状態名はAPIのように扱ってください。毎月名前を変えると、ダッシュボード、アラート、サポート手順がすぐに誤解を生みます。新しい意味が必要なら新しい状態を導入し、既存のレコードは古い状態のままにすることを検討してください。
AppMasterではData Designerでこれらの状態をモデル化し、Business Processロジックから更新できます。こうすることでステータスがログに埋もれずアプリ全体で見えるようになります。
リトライは問題を隠すまで役に立ちます。目標は「決して失敗しない」ことではなく、「人が理解して修正できる形で失敗する」ことです。そのためには何がリトライ可能で何がそうでないかの明確なルールが必要です。
多くのチームが受け入れられるルール:一時的である可能性の高いエラー(ネットワークタイムアウト、レート制限、一時的な外部障害)はリトライする。明らかに恒久的なエラー(無効な入力、権限不足、「アカウント閉鎖」、「カード拒否」)はリトライしない。どちらか判別できない場合は、学ぶまでは非リトライ扱いにするのが安全です。
リトライカウンターはステップ(または外部呼び出し)ごとに追跡してください。ワークフローに10ステップあり、そのうち1つだけが不安定なことはよくあります。ステップレベルのカウンターは後ろのステップが前のステップの試行を奪うのを防ぎます。
例:"Upload document"呼び出しは数回リトライされるべきだが、"Send welcome email"はアップロードが試行回数を使い果たしたためにいつまでもリトライされるべきではありません。
リスクに合ったバックオフパターンを選んでください。単純でコストが低ければ固定遅延で構いません。レート制限に当たる可能性があるなら指数バックオフが有効です。待ち時間が無限に大きくならないよう上限を設け、リトライストームを避けるためにジッタを加えます。
次にいつ止めるかを決めます。良い停止条件は明示的です:最大試行回数、合計時間の上限、あるいは特定のエラーコードでは即時にあきらめる。決済ゲートウェイが「無効なカード」と返したら、通常5回試みるルールでも即停止すべきです。
オペレータは次に何が起きるかを知る必要があります。次のリトライ時刻と理由を記録してください(例:「Retry 3/5 at 14:32 due to timeout」)。AppMasterではワークフローのレコードにこれを保存すれば、ダッシュボードが「いつまで待つか」を推測する必要がなくなります。
良いリトライポリシーは痕跡を残します:何が失敗したか、何回試したか、次はいつ試すか、いつ止めてデッドレターに移すか。
数時間〜数日動くワークフローではリトライは日常的です。懸念は既に成功したステップを繰り返すことです。冪等性はこれを安全にするルールです:あるステップを2回実行しても1回と同じ効果ならそれは冪等です。
典型的な失敗例:カードに課金したがワークフローが「支払い成功」を保存する前にクラッシュした。再試行でまた課金してしまう。これは外部の世界は変わったのにワークフロー状態が変わっていない二重書き込みの問題です。
最も安全なパターンは、各副作用を伴うステップに対して安定した冪等キーを作り、それを外部呼び出しに送って、結果を受け取ったらすぐに保存することです。多くの決済プロバイダやWebhook受信側は冪等キーをサポートしています(例:OrderIDでの課金)。ステップが繰り返されても、プロバイダは元の結果を返し、再実行を抑制します。
ワークフローエンジン内部では、すべてのステップが再生され得ると仮定してください。AppMasterでは多くの場合、ステップの出力をデータベースモデルに保存し、Business Processで統合呼び出しを行う前にそれを確認します。例えば「Send welcome email」に既にMessageIDが記録されていれば、リトライはそのレコードを再利用して先に進みます。
実用的な重複安全アプローチ:
重複はインバウンドWebhookやユーザーの二度押しで依然発生します。イベントタイプごとに方針を決めてください:完全に同一の冪等キーなら無視、プロファイル更新のような互換性のある更新はマージ(最終書き込み優先)する、金銭やコンプライアンスのリスクがある場合はレビューでフラグを立てる、など。
デッドレターとは、失敗して通常の経路から外されたワークフロー項目です。それをあえて保存しておき、他の作業をブロックしないようにする仕組みです。目的は何が起きたかを分かりやすくし、修復可能か判断し、安全に再処理できるようにすることです。
最大の間違いはエラーメッセージだけを保存することです。後で誰かがデッドレターを見たとき、推測なしに問題を再現できるだけのコンテキストが必要です。
有用なデッドレターエントリは次を含みます:
分類するとデッドレターが実行可能になります。短いカテゴリはオペレータが適切な次のステップを選ぶのに役立ちます。よくある分類は恒久的エラー(論理ルール、無効な状態)、データ問題(必須フィールド欠落、形式不備)、依存先ダウン(タイムアウト、レート制限、障害)、認証/権限(期限切れトークン、拒否)などです。
再処理は管理されたものであるべきです。二重課金やスパム送信のような繰り返しの害を避けるため、誰がいつ再試行できるか、何を変更できるか(特定フィールドの編集、欠落ドキュメントの添付、トークン更新)、何が固定であるべきか(リクエストIDや下流の冪等キー)を明確にしてください。
デッドレター項目は安定した識別子で検索できるようにします。オペレータが「order 18422」と入力して正確なステップ、入力、試行履歴を見られれば、修正は早く一貫して行えます。
AppMasterでこれを構築する場合、デッドレターをファーストクラスのデータモデルとして扱い、状態、試行回数、識別子をフィールドとして保存してください。そうすれば内部ダッシュボードで検索、フィルタ、制御された再処理アクションを実装できます。
長時間実行ワークフローはメール返信待ち、決済プロバイダのタイムアウト、Webhook二重受信など、遅くて紛らわしい障害を起こします。現在ワークフローが何をしているか見えないと推測に頼ることになります。良い可視化は「壊れている」から「どのワークフロー、どのステップ、どの状態、次に何をすべきか」へと変えます。
まず全てのステップが同じ小さなフィールドセットを出力するようにしてください。オペレータが素早くスキャンできるようにするためです:
これらのフィールドは健康状態を一目で示す基本的なカウンタを支えます。長時間ワークフローでは単発のエラーよりもカウントの変化が重要です:処理が溜まっているか、リトライが急増しているか、待ちが終わらないかを見ます。
時間に対する開始、完了、失敗、リトライ中、待機中を追跡してください。小さな待機数は正常(人の承認)ですが、待機数が増え続けるのはブロックの兆候です。リトライ中が増えるのはプロバイダ問題かバグの可能性を示します。
アラートはオペレータの経験に合わせてください。「エラーが発生した」ではなく、症状でアラートを出します:バックログの増加(開始数−完了数が増える)、期待時間を超えた待機の増加、特定ステップの高いリトライ率、リリースや設定変更直後の障害急増などです。
各ワークフローのイベントトレイルを保持して「何が起きたか?」を一つの画面で答えられるようにします。便利なトレイルにはタイムスタンプ、状態遷移、入力と出力の要約(機密情報ではない)、リトライや失敗の理由の要約が含まれます。例:「Charge card: retry 3/5, timeout from provider, next attempt in 10m」。
相関IDは接着剤の役割を果たします。顧客が「支払いが二重に請求された」と言ったら、ワークフローイベントを決済プロバイダのチャージIDと社内の注文IDにつなげる必要があります。AppMasterではBusiness Processロジックで相関IDを生成してAPI呼び出しやメッセージングに渡し、ダッシュボードとログが整合するように標準化できます。
ワークフローが何時間も何日も動くと、失敗自体は普通になります。問題を大きな障害にするのは「Failed」としか表示しないダッシュボードです。目標はオペレータが素早く三つの質問に答えられるようにすること:何が起きているか、なぜ起きているか、安全に次に何ができるか。
まず重要なアイテムを見つけやすいワークフロー一覧を作ってください。フィルタはパニックや無駄なチャットを減らします。誰でも素早くビューを絞り込めるようにします。
有用なフィルタ例:状態、経過時間(開始時刻と現在状態での滞留時間)、オーナー(チーム/顧客/担当者)、種類(ワークフロー名/バージョン)、顧客向けステップなら優先度。
次にステータスの横に「なぜ」を表示します。ステータス表示だけではログを開かないとわからないことが多いので、最後のエラーメッセージ、短いエラーカテゴリ、システムが次に何をする予定かを並べて見せます。2つのフィールドで十分なことが多い:last error と next retry time。next retry が空なら、そのワークフローが人待ちなのか一時停止なのか永続的に失敗しているのかを明示してください。
オペレータアクションはデフォルトで安全に。まず低リスクな操作を案内し、リスクの高い操作は明示します:
「強制続行」は最も危険な箇所です。提供するならリスクを平易な言葉で示してください:「これにより決済確認をスキップし、未払いの注文が作られる可能性があります。」また進めた場合に書き込まれるデータも表示します。
オペレータの全操作を監査記録してください。誰がいつ何をしたか、前後の状態、理由ノートを記録します。AppMasterで内部ツールを作る場合、この監査トレイルをファーストクラスのテーブルとして保存し、ワークフローディテールページに表示すると引き継ぎが整います。
このパターンはワークフローを予測可能にします:各アイテムは常に明確な状態にあり、失敗は定位置へ行き、オペレータは推測せずに行動できます。
Step 1: 状態と許容遷移を定義する。 人が理解できる小さな状態セットを書き出します(例:Queued, Running, Waiting on external, Succeeded, Failed, Dead-letter)。次にどの遷移が許されるか決めて、作業が宙ぶらりんにならないようにします。
Step 2: 作業を明確な入力と出力を持つ小さなステップに分解する。 各ステップは1つの定義された入力を受け取り、1つの出力(または明確なエラー)を返すべきです。人の判断や外部API呼び出しが必要なら、それ自体をステップにして一時停止と再開を可能にします。
Step 3: ステップごとにリトライポリシーを追加する。 試行回数の上限、試行間の遅延、決してリトライしない理由(無効データ、権限拒否、必須フィールド欠落)を決めます。ステップごとのリトライカウンターを保存して、どこが止まっているかが明確に見えるようにします。
Step 4: 各ステップ後に進捗を永続化する。 ステップが完了したら新しい状態と主要な出力を保存します。プロセスが再起動しても最後に完了したステップから再開できるようにします。
Step 5: デッドレターへルートし再処理をサポートする。 リトライが尽きたらアイテムをデッドレター状態に移し、入力、最後のエラー、ステップ名、試行回数、タイムスタンプなどのコンテキストを保持します。再処理は意図的に行う:まずデータや設定を修正し、特定のステップから再キューするようにします。
Step 6: ダッシュボードのフィールドとオペレーター操作を定義する。 良いダッシュボードは「何が失敗し、どこで、次に何ができるか」を答えます。AppMasterではこれをワークフローテーブルに基づく管理用Webアプリとして構築できます。
含めるべき主要フィールドと操作:
従業員のオンボーディングはよいテストケースです。承認、人がオフライン、外部システムが混在します。シンプルなフローは:HRが採用フォームを提出、マネージャが承認、ITでアカウント作成、入社者へ歓迎メッセージ送信、です。
状態を読みやすくしてください。レコードを開いたときに「Waiting for approval」と「Retrying account setup」の違いがすぐわかるべきです。一行の明確さが1時間の推測を節約します。
UIに表示する明確な状態例:
ネットワークやサードパーティAPIに依存するステップにはリトライを設定してください。アカウントプロビジョニング(メール、SSO、Slack)、メール/SMS送信、内部API呼び出しはリトライ候補です。リトライカウンタを可視化し上限を設けます(例:最大5回まで増加する遅延でリトライし、それ以上は止める)。
デッドレターは自動で直らない問題向けです:マネージャがフォームにいない、無効なメールアドレス、ポリシーと矛盾するアクセス要求など。デッドレターに移すときはどのフィールドが検証で失敗したか、最後のAPI応答、オーバーライドできる人物を保存します。
オペレータは小さな操作セットを持つべきです:データ修正(マネージャ追加、メール修正)、失敗した1ステップだけの再実行(ワークフロー全体ではない)、またはクリーンなキャンセル(部分的セットアップのロールバックが必要ならそれも行う)。
AppMasterではこれをBusiness Process Editorでモデル化し、リトライカウンタをデータに保持し、Web UIビルダーで状態、最終エラー、失敗ステップを再実行するボタンを持つオペレータ画面を作成できます。
多くの信頼性問題は予測可能です:ステップが二度動く、午前2時にリトライが暴走する、または「詰まった」アイテムに最後に何が起きたかわからない。チェックリストがあれば推測に頼らずに済みます。
早期に多くの問題を発見する簡単なチェック:
一つだけ改善できるなら、可視化を改善してください。多くの「ワークフローバグ」は実際には「何をしているか見えない」問題です。ダッシュボードは前回何が起きたか、次に何が起きるか、いつ起きるかを示すべきです。
実用的なオペレータビューには現在の状態、最終エラーメッセージ、試行回数、次のリトライ時刻、そして一つの明確なアクション(今すぐリトライ、解決済みにマーク、手動レビューへ送る)が含まれます。デフォルトで安全に:ワークフロー全体ではなく単一ステップを再実行させること。
次のステップ:
これを生きたチェックリストとして扱ってください。新しいステップを追加するたびに、本番に入れる前にこれらのチェックを実行しましょう。
長時間実行されるワークフローは、完了間際に失敗して途中の変更が残ることがあります。また、実行中にサードパーティの稼働状況や資格情報、データの形式、人の応答などが変わるため、短いAPIコールより壊れやすくなります。
オペレータが一目で理解できるように状態は少数に保ちます。標準的なセットは queued、running、waiting、succeeded、failed のようなものです。特に「waiting」を「running」と明確に分けることで、健康的な待ちとハングを区別できます。
ステータスを実用的にするために保存すべき情報は、現在の状態、最終状態変更時刻、前の状態、待機や失敗時の短い理由です。リトライがあるなら試行回数や次の予定リトライ時刻も保存すると推測が不要になります。
「Waiting」と「Running」を分けると誤報と見逃しを防げます。例えば「承認待ち」は正常な待ちですが「6時間実行中」はハングの可能性が高いため、別状態にすることでアラートも運用判断も改善します。
一時的なエラー(タイムアウト、レート制限、一時的な外部サービス障害)はリトライに値しますが、無効な入力や権限不足、カードの拒否など明らかに恒久的なエラーはリトライすべきではありません。どちらか分からない場合は、まず非リトライ扱いにして原因を調べるのが安全です。
ステップ単位でリトライを追跡すると、特定のフラッキーな連携だけを繰り返し試せます。ワークフロー全体で一つのカウンターにすると、あるステップが試行を使い切ってしまい、別のステップが再試行できなくなる問題が起きます。
リスクに合わせてバックオフを選び、必ず上限を設けて無限に待たないようにします。停止条件は明確に:最大試行回数、合計時間上限、あるいは特定のエラーコードで即停止するなど。次に何が起きるか(次の試行時刻と理由)を記録してオーナーシップを明確にします。
どのステップでも再実行が起こり得る前提で設計し、繰り返しても害が出ないようにします。一般的にはステップごとに安定した冪等キーを生成し、外部呼び出し前に“step started”を書き込み、成功時に結果を保存して再実行時はその結果を再利用します。
デッドレター項目には、再処理できるように十分なコンテキストを保管します。具体的には識別子(顧客ID、注文ID、ワークフローID)、元の入力(または安全なスナップショット)、どこで止まったか(ステップ名、最後の成功ステップ)、試行履歴とエラーの詳細(メッセージ、コード、依存先の応答)を含めます。
使いやすいダッシュボードは「どのワークフローのどのステップがなぜ止まっているか、次に何が起きるか」をすぐに示します。基本フィールドはワークフローID、現在のステップと状態、ステップ滞留時間、最終エラー、相関IDなどです。オペレーターには低リスクな操作をデフォルトで提示し、危険な操作は明確にラベル付けします。




