
機器予約アプリで競合を防ぎ、返却を追跡する
二重予約を防ぎ、返却と破損を記録し、故障した機器を保守対象にする機器予約アプリの設計方法を紹介します。
キュー、ステータスモデル、UIメッセージ、キャンセル/再試行、エラー報告など、進捗表示付きバックグラウンドタスクの実践的なパターンを学ぶ。
長時間の処理がUIを塞ぐべきではありません。人はタブを切り替えたり、接続が切れたり、ノートパソコンを閉じたり、単に何かが起きているか疑問に思います。画面が固まっているとユーザーは推測し始め、推測は繰り返しクリックや二重送信、サポート問い合わせにつながります。
良いバックグラウンド処理は「信頼感」を作ることです。ユーザーが望むのは主に3つです:
これらがないと、ジョブは正常に動いていても体験は壊れたように感じられます。
よくある誤解の一つは「遅いリクエスト」を本当のバックグラウンド処理と同じ扱いにすることです。遅いリクエストは依然として単一のWeb呼び出しでユーザーを待たせます。バックグラウンド処理は別物です:ジョブを開始してすぐに確認を受け取り、重い処理は別の場所で行われ、UIは使い続けられます。
例:ユーザーが顧客をインポートするためにCSVをアップロードする場面。UIがブロックされると、ユーザーはリロードして再アップロードし、重複が発生するかもしれません。インポートがバックグラウンドで始まり、ジョブカードに進捗と安全なキャンセルが表示されれば、作業を続けて結果に戻ることができます。
バックグラウンドタスクの進捗表示と言うと、通常は4つの要素が連携します。
ジョブは作業単位です:"このCSVをインポートする"、"このレポートを生成する"、"5,000通のメールを送る"など。キューはジョブが処理されるまで待つ列です。ワーカーはキューからジョブを取り出して作業を行います(逐次または並列)。
UIにとって最も重要なのはジョブのライフサイクル状態です。状態は少なく予測可能に保ちましょう:
すべてのジョブにはジョブID(一意の参照)が必要です。ユーザーがボタンを押したらそのIDを即座に返し、タスクパネルに「タスク開始」の行を表示します。
次に「今何が起きているか?」を問い合わせる方法が必要です。通常はジョブIDを受け取り状態と進捗の詳細を返すステータスエンドポイント(または任意の読み取りメソッド)です。UIはこれを使って完了率、現在のステップ、メッセージを表示します。
最後に、ステータスは永続的なストアに保存されるべきで、メモリだけに置いてはいけません。ワーカーはクラッシュするし、アプリは再起動し、ユーザーはページをリロードします。永続化は進捗と結果を信頼できるものにします。最低限保存すべき項目:
AppMasterのようなプラットフォームで構築するなら、ステータスストアを他のデータモデルと同様に扱ってください:UIはジョブIDで読み取り、ワーカーが進行に合わせて更新します。
選ぶキューパターンでアプリの「公平さ」と予測性が変わります。あるタスクが他の大量の仕事の後ろに並んでいると、ユーザーはランダムな遅延を経験します。キューの選択はインフラだけでなくUXの決定でもあります。
ボリュームが少なく、ジョブが短く、時折のリトライが許容できるなら、単純にデータベースでキューを実装するだけで十分なことが多いです。設定が簡単で検査もしやすく、すべてを一か所で管理できます。例:管理者が小さなチーム向けに夜間レポートを実行する場合。もし1回リトライしても大きな問題になりません。
スループットが上がり、ジョブが重く、信頼性が不可欠になると専用のキューシステムが必要になります。インポート、ビデオ処理、大量通知、再起動後も確実に続ける必要があるワークフローは、分離性、可視性、安全なリトライがある方が有利です。これはユーザー向け進捗に影響します。人は更新が止まったりスタックした状態に気付きます。
キュー構造は優先度にも影響します。1つのキューは単純ですが、短時間で処理すべき作業と長時間のバッチ作業を混ぜると、短い方が遅く感じられます。ユーザーが引き起こす即時性のある作業と、待てるスケジュール作業を分けると良いでしょう。
同時実行数は意図的に設定してください。並列度が高すぎるとデータベースに負荷がかかり進捗が飛び飛びになります。少なすぎるとシステム全体が遅く感じられます。各キューごとに小さく予測可能な並列度から始め、完了時間の安定性を保てるときだけ増やしましょう。
進捗モデルが曖昧だとUIも曖昧に感じられます。システムが正直に報告できること、どれくらいの頻度で変わるか、ユーザーがその情報で何をすべきかを決めてください。
多くのジョブで対応できるシンプルなステータススキーマの例:
次に「進捗」を何と定義するか決めます。
分母が明確(ファイルの行数、送信するメール数)な場合はパーセントが使えます。第三者待ちや計算負荷の変動、重いクエリなど予測不能な処理では誤解を招くことがあります。その場合はステップベースの進捗が信頼を高めます。
実用ルール:
ジョブ実行中に部分的な結果を保存しておくと、ジョブ完了前でもUIで有益な情報(ライブエラー数や変更のプレビュー)を表示できます。CSVインポートなら rows_read、rows_created、rows_updated、rows_rejected といった値や直近のエラーメッセージを保存すると良いでしょう。
これがユーザーに信頼されるバックグラウンドタスクの基礎です:UIは落ち着き、数値は進み、完了時に「何が起きたか」要約が用意されます。
バックエンドから画面への進捗の届け方で多くの実装が失敗します。進捗がどのくらい頻繁に変わるかと、何人のユーザーが見守るかに合った方法を選んでください。
ポーリングは最もシンプルです:UIがN秒ごとにステータスを問い合わせます。ユーザーが画面を見ている間は2〜5秒が良いデフォルトで、1分以上続くタスクなら10〜30秒に落とします。タブがバックグラウンドの場合はさらに遅くします。
プッシュ(WebSocket、Server-Sent Events、モバイル通知)は進捗が速く変わるか「今すぐ知りたい」場面で有効です。即時性に優れますが、接続が切れた場合のフォールバックが必須です。
ハイブリッドが最適なことが多い:開始直後は速いポーリング(queued→running を素早くキャッチするため)、ジョブが安定したら遅くする。プッシュを追加する場合でも安全のために遅いポーリングを残しておきます。
更新が止まったらそれを一級の状態として扱ってください。「最終更新 2分前」と表示して更新を促すなど。バックエンドではハートビートが途切れたジョブを stale としてマークします。
明瞭さは2つの要素で生まれます:少数で予測可能な状態と、次に何が起きるかを伝える文章です。
状態はUIでも名前を付けて見せてください。ジョブは queued(順番待ち)、running(処理中)、waiting for input(入力待ち)、completed(完了)、completed with errors(問題ありで完了)、failed(失敗)などに分けられます。ユーザーがこれらを区別できないとアプリが固まったと感じます。
進捗表示の近くには平易で有用な文言を置きます。例:"Importing 3,200 rows (1,140 processed)" は単に "Processing." よりずっと良いです。1行で「離れてよいか」「何が起きるか」を答えると親切です。例:「このウィンドウを閉じても大丈夫です。バックグラウンドでインポートを続け、完了時に通知します。」
進捗を表示する場所はユーザーの文脈に合わせます:
1分以上かかるものは Jobs ページや Activity パネルを用意して、ユーザーが後で作業を見つけられるようにします。
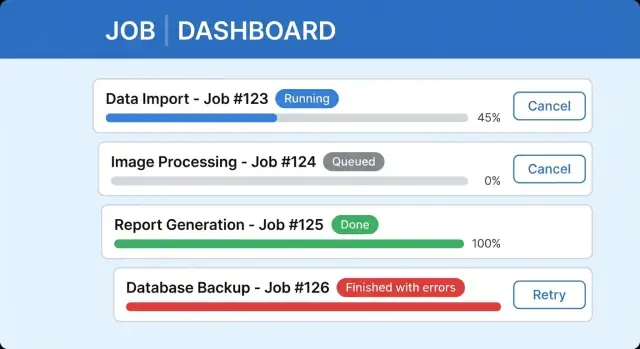
明確な長時間処理UIには通常、最終更新時間付きのステータスラベル、進捗バー(またはステップ)、一行の詳細、 安全なキャンセル動作、サマリと次アクションの領域が含まれます。完了したジョブはあとで参照できるようにして、ユーザーが一つの画面で待たされる必要がないようにします。
「完了」=成功とは限りません。例えば9,500件中120件が失敗した場合、ユーザーはログを読まずに何が起きたか把握したいはずです。
部分成功を正当な結果として扱ってください。メインのステータス行で両方を示します:"Imported 9,380 of 9,500. 120 failed."。正直に示すことで信頼が保てます。
次にユーザーが対応できる小さなエラーサマリを示します:"Missing required field (63)", "Invalid date format (41)" のように。最終状態は "Completed with issues" のほうが "Failed" よりも分かりやすいことが多いです。
エクスポート可能なエラーレポートは混乱をタスクに変えます。シンプルに:行番号やアイテム識別子、エラー分類、ユーザー向けの説明、該当フィールド名。
次に取るアクション(データを修正して失敗分だけ再試行、エラーレポートをダウンロード、システム側の問題ならサポートに連絡)をサマリの近くに置いてください。
キャンセルと再試行は見た目は簡単ですが、UIと実態がずれると信頼を失います。各ジョブタイプで Cancel の意味を定義し、それをUIで正直に反映してください。
一般に有効なキャンセルモードは2つです:
UIでは "Cancel requested" のような中間状態を表示して、ユーザーが繰り返し押さないようにします。
キャンセルを安全にするには処理を繰り返し実行しても問題ない(冪等)に設計することが大切です。CSVインポートがレコードを作成するならジョブ実行IDを保存して、run #123 がどのように変えたかを後で確認できるようにします。
再試行にも同じ明快さが必要です。再開できるなら同じジョブインスタンスのリトライは合理的ですが、クリーンな実行や監査を残したいなら新しいジョブIDを作る方が安全です。いずれにせよ何が起きるかを説明してください。
守るべきガードレール:
良いフローは一つのルールから始まります:UIは作業自体を待たない。待つのはジョブIDだけ。
ユーザーがタスクを開始し、APIは即座に応答する。 ユーザーがImportやGenerate reportを押すと、サーバはすぐにジョブレコードを作成してユニークなジョブIDを返します。
作業をキューに入れ、初期ステータスを設定する。 ジョブIDをキューに入れ、progress 0% で queued にセットします。ワーカーが拾う前でもUIに表示する実体ができます。
ワーカーが実行し進捗を報告する。 ワーカーが開始したら status を running にし、開始時間を保存し、小さく正直なステップで進捗を更新します。パーセントが測れない場合は Parsing、Validating、Saving のようなステップを表示します。
UIはユーザーの向きを保つ。 UIはポーリングまたはサブスクライブして更新を描画し、短いメッセージ(現在何をしているか)とその時に可能なアクションだけを表示します。
永続的な結果で最終化する。 完了時に finish time、出力(ダウンロード参照、作成されたID、サマリカウント)、エラー詳細を保存します。Finished-with-errors を曖昧な成功として扱わないでください。
キャンセルは明確に:キャンセルはまずリクエストを出し、ワーカーがそれを受け取りキャンセル済みにマークします。リトライは新しいジョブIDを作るのが安全で、元のジョブは履歴として残します。
CSVインポートは進捗表示が重要になる典型例です。CRMで sales ops が customers.csv(8,420行)をアップロードする場面を想像してください。
アップロード直後にUIは「ボタンを押した状態」から「ジョブが作成され、離れてよい」へ切り替わるべきです。Importsページのシンプルなジョブカードが有効です:
実行中はユーザーが信用できる1つの進捗数(処理済み行数)と短いステータス行(今何をしているか)を表示します。ユーザーが離れても、Recent jobs にジョブを残しておきます。
部分失敗を追加した場合、完了時に怖い Failed バナーは避けてください。代わりに Finished with issues として明確に分けます:
Imported 8,102 customers. Skipped 318 rows.
上位の原因を平易な言葉で示します:無効なメール形式、company のような必須フィールドの欠落、重複する外部IDなど。エラーテーブル(行番号、顧客名、該当フィールド)をダウンロードまたは閲覧できるようにします。
再試行は安全で具体的に感じられるべきです。主要なアクションは "Retry failed rows" として新しいジョブを作り、ユーザーがCSVを修正した後に 318 行だけ再処理するようにします。元のジョブは読み取り専用にして履歴を保ちます。
最後に、結果を後で簡単に見つけられるようにします。各インポートは安定したサマリ(誰が実行したか、いつ、ファイル名、件数、エラーレポートを開く方法)を持つべきです。
信頼を失う最短ルートは実態と合わない数値を表示することです。0%のまま2分止まってから90%に飛ぶ進捗バーは推測に見えます。真のパーセントが不明なら、ステップ表示(Queued、Processing、Finalizing)や "X of Y items processed" を使ってください。
もう一つの問題は進捗をメモリだけに保存することです。ワーカーが再起動するとUIがジョブを "忘れる" か進捗がリセットされます。ジョブ状態は永続ストレージに保存し、UIはその単一の信頼できるソースから読み取るようにしましょう。
リトライUXが壊れるのは、ユーザーが同じジョブを何度も開始できる場合です。Import CSV ボタンが有効なままだと誰かが二度クリックして重複が生じます。どの実行を修正すべきか分かりにくくなります。
繰り返し出る誤り:
小さなが重要な点:ユーザー向けメッセージと開発者向けの詳細を分けること。ユーザーには "12 rows failed validation" と示し、技術的なトレースはログに残します。
リリース前にユーザーが目にする部分を簡単に確認してください:明確さ、信頼、回復。
各ジョブはどこでも表示できるスナップショットを提供すべきです:状態(queued, running, succeeded, failed, canceled)、進捗(0-100またはステップ)、短いメッセージ、タイムスタンプ、結果ポインタ(出力やレポートの場所)。
UI状態を明確かつ一貫しておきます。ユーザーは現在と過去のジョブを見つける信頼できる場所が必要です("昨日完了"、"まだ実行中")。Recent jobs パネルが繰り返しクリックや重複を防ぎます。
キャンセルとリトライのルールを平易に定義します。各ジョブで Cancel が何を意味するか、リトライが許可されるか、何が再利用されるか(同じ入力か新しいジョブIDか)を決め、境界ケース(完了直前にキャンセル)をテストします。
部分失敗は正式な結果として扱い、短いサマリ("Imported 97, skipped 3")を表示し、ユーザーがすぐに使える実行可能なレポートを提供します。
回復を計画します。ジョブは再起動に耐えるべきで、スタックしたジョブは明確な状態にタイムアウトし("再試行" か "サポートへ連絡")、ジョブIDを使って対応できるようにします。
既に不満が出ているワークフローを一つ選んでください:CSVインポート、レポートエクスポート、一括メール送信、画像処理など。小さく始めて基本を証明します:ジョブが作られ、実行され、ステータスを報告し、ユーザーが後で見つけられること。
シンプルなジョブ履歴画面はしばしば品質を大きく改善します。スピナーを眺め続ける代わりに戻って確認できる場所を与えます。
まず一つの進捗配信方法を選んでください。バージョン1ではポーリングで十分です。バックエンドに優しく、それでいて「生きている」感触が得られるリフレッシュ間隔に設定します。
書き直しを避ける実用的な構築順序:
コードを書かずにこれを構築する場合、AppMaster のようなノーコードプラットフォームはジョブステータステーブル(PostgreSQL)をモデル化し、ワークフローから更新してWebやモバイルUIに反映するのに役立ちます。バックエンド、UI、バックグラウンドロジックを一つの場所で作りたいチームには AppMaster (appmaster.io) が向いています。
バックグラウンドジョブはすぐに開始され、直ちにジョブIDを返すため、UIは使い続けられます。遅いリクエストは同じWeb呼び出しが終わるまでユーザーを待たせるので、リフレッシュや二重送信、重複が起きやすくなります。
シンプルにしておきましょう: queued, running, done, failed、キャンセルをサポートするなら canceled を表示します。大半の処理が成功したが一部失敗した場合は「done with issues」のような別の結果を追加すると、ユーザーは全てが失われたと誤解しません。
ユーザーがアクションを始めたらすぐにユニークなジョブIDを返し、そのIDでタスク行やカードを表示してください。UIはジョブIDでステータスを読み取るべきなので、ページをリロードしたりタブを切り替えてもタスクを見失いません。
ジョブステータスはメモリだけでなく永続データベースのテーブルに保存してください。現在の状態、タイムスタンプ、進捗値、短いユーザ向けメッセージ、結果やエラーの要約を保存すれば、再起動後でも同じ表示を復元できます。
「X/Y 件処理済み」と正直に報告できる場合のみパーセントを使ってください。分母が不明な場合はステップベース(例: Validating、Importing、Finalizing)を使い、ユーザーに前進している実感を与えます。
ポーリングは最も簡単で多くのアプリに十分です。ユーザーが見ている間は2〜5秒ごと、長時間なら10〜30秒に落とすのが良い出発点です。プッシュは即時性に優れますが接続切れのフォールバックが必要です。
更新が止まったら "最終更新: 2分前" のように古くなったことを示し、手動で更新できるようにします。バックエンドではハートビートが途切れたジョブを検出して、再試行やサポート連絡を促す明確な状態に移すべきです。
次に何ができるかを明確に示してください。ユーザーが作業を続けてよいのか、ページを離れてもよいのか、キャンセルして安全かどうか。1分以上かかる処理なら Jobs や Activity ビューを用意して、結果を後で確認できるようにします。
部分的な失敗を正式な結果として扱い、両方を明示します: 例として "Imported 9,380 of 9,500. 120 failed."。その後、ユーザーが対応できる簡潔なエラーサマリ(例: 必須フィールドが欠けている (63)、日付形式が無効 (41))を示します。技術的な詳細は内部ログに残してください。
各ジョブタイプで Cancel の意味を定義し、それを正直に反映してください。中間状態として "Cancel requested" を表示して、ユーザーが何度も押さないようにします。処理は可能な限り冪等にし、リトライ回数を制限し、リトライが同じジョブを再開するのか新しいジョブを作るのかを明示します。




