แอปจองอุปกรณ์: ป้องกันการจองซ้ำและติดตามการคืน
วางแผนแอปจองอุปกรณ์ที่ป้องกันการจองซ้ำ บันทึกการคืนและความเสียหาย พร้อมระงับอุปกรณ์ที่มีปัญหาเพื่อรอการบำรุงรักษา
เปรียบเทียบ pgvector กับ managed vector database สำหรับการค้นหาเชิงความหมาย: งานตั้งค่า ปัญหาการสเกล การรองรับการกรอง และการใช้งานในสแตกแอปทั่วไป.
การค้นหาเชิงความหมายช่วยให้ผู้คนเจอคำตอบที่ถูกต้องแม้จะไม่ได้ใช้คำที่ 'ถูกต้อง' ตามตัวอักษร แทนที่จะจับคู่คำตรง ๆ มันจับคู่ความหมาย ใครสักคนพิมพ์ว่า “รีเซ็ตการเข้าสู่ระบบของฉัน” ควรยังเห็นบทความชื่อว่า “เปลี่ยนรหัสผ่านแล้วล็อกอินใหม่” เพราะเจตนาเหมือนกัน
การค้นหาด้วยคีย์เวิร์ดใช้ไม่ได้ในแอปธุรกิจเพราะผู้ใช้จริงไม่สม่ำเสมอ พวกเขาใช้คำย่อ พิมพ์ผิด ผสมชื่อผลิตภัณฑ์ และอธิบายอาการแทนคำทางการ ใน FAQ ตั๋วซัพพอร์ต เอกสารนโยบาย และคู่มือเริ่มต้น ปัญหาเดียวกันปรากฏในประโยคที่ต่างกัน การค้นหาด้วยคีย์เวิร์ดมักคืนอะไรที่ไม่เป็นประโยชน์หรือรายชื่อยาวที่บังคับให้ผู้ใช้ต้องคลิกวน
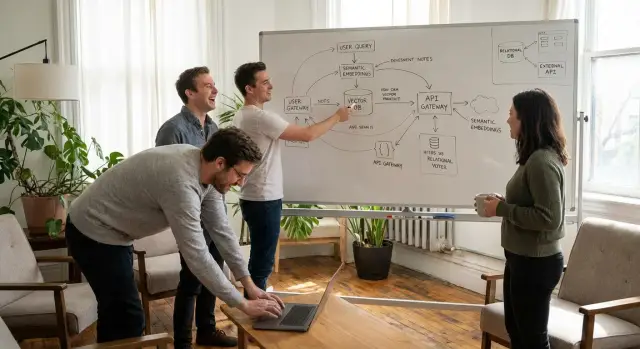
Embeddings เป็นบล็อกพื้นฐาน แอปของคุณแปลงเอกสารแต่ละชิ้น (บทความ ตั๋ว โน้ตสินค้า) เป็นเวกเตอร์ รายการตัวเลขยาวที่แทนความหมาย เมื่อผู้ใช้ถามคำถาม คุณก็แปลงคำถามเป็นเวกเตอร์แล้วค้นหาเวกเตอร์ที่ใกล้ที่สุด “ฐานข้อมูลเวกเตอร์” คือที่ที่คุณเก็บเวกเตอร์เหล่านั้นและวิธีค้นหาอย่างรวดเร็ว
ในสแต็กแอปธุรกิจปกติ การค้นหาเชิงความหมายเกี่ยวข้องกับสี่ส่วน: ที่เก็บเนื้อหา (ฐานความรู้ เอกสาร ระบบตั๋ว), พายพอร์ต embedding (นำเข้าและอัปเดตเมื่อเนื้อหาเปลี่ยน), ประสบการณ์การค้นหา (กล่องค้นหา คำตอบแนะนำ ผู้ช่วยตัวแทน), และกรอบนิรภัย (สิทธิ์บวกเมตาดาตาเช่นทีม ลูกค้า แผน และภูมิภาค)
สำหรับทีมส่วนใหญ่ “พอใช้” ย่อมดีกว่า “สมบูรณ์แบบ” เป้าหมายเชิงปฏิบัติคือได้ความเกี่ยวข้องรอบแรก ตอบกลับภายใต้หนึ่งวินาที และต้นทุนที่คาดการณ์ได้เมื่อข้อมูลโต เป้าหมายนี้สำคัญกว่าการถกเถียงเรื่องเครื่องมือ
ทีมส่วนใหญ่จะเลือกระหว่างสองรูปแบบสำหรับการค้นหาเชิงความหมาย: เก็บทุกอย่างใน PostgreSQL ด้วย pgvector หรือเพิ่มบริการ vector database ที่มีผู้ดูแลข้างฐานข้อมูลหลัก ทางเลือกที่เหมาะสมขึ้นกับว่าคุณต้องการให้ความซับซ้อนอยู่ที่ไหน
pgvector เป็นส่วนขยายของ PostgreSQL ที่เพิ่มชนิดข้อมูลเวกเตอร์และดัชนี ทำให้คุณเก็บ embeddings ในตารางปกติและรันการค้นหาเชิงความคล้ายด้วย SQL ในการใช้งานจริง ตารางเอกสารของคุณอาจมีข้อความ เมตาดาตา (customer_id, status, visibility) และคอลัมน์ embedding การค้นหาก็จะเป็น “แปลงคำถามเป็นเวกเตอร์ แล้วคืนแถวที่เวกเตอร์ใกล้ที่สุด”
ฐานข้อมูลเวกเตอร์แบบมีผู้ดูแลคือบริการโฮสต์ที่ออกแบบมาสำหรับ embeddings โดยตรง มักให้ API สำหรับแทรกเวกเตอร์และการค้นหาเชิงความคล้าย รวมถึงฟีเจอร์ปฏิบัติการที่คุณต้องสร้างเอง
ทั้งสองทางเลือกทำงานหลักเหมือนกัน: เก็บ embeddings พร้อม ID และเมตาดาตา หาค่าเพื่อนบ้านที่ใกล้ที่สุดสำหรับคำถาม แล้วคืนผลลัพธ์บนสุดเพื่อให้แอปแสดงรายการที่เกี่ยวข้อง
ความแตกต่างสำคัญคือตรงที่เก็บข้อมูล แม้คุณจะใช้บริการ vector แบบมีผู้ดูแล คุณก็แทบจะยังเก็บ PostgreSQL สำหรับข้อมูลธุรกิจ: บัญชี สิทธิ์ การเรียกเก็บเงิน สถานะเวิร์กโฟลว์ และล็อกตรวจสอบ การเก็บเวกเตอร์กลายเป็นเลเยอร์การดึงข้อมูล ไม่ใช่ที่ที่รันทั้งแอป
สถาปัตยกรรมที่พบบ่อยคือเก็บระเบียนที่เชื่อถือได้ใน Postgres เก็บ embeddings ใน Postgres (pgvector) หรือในบริการเวกเตอร์ รันการค้นหาเชิงความคล้ายเพื่อได้ ID ที่ตรงกัน แล้วดึงแถวเต็มจาก Postgres
ถ้าคุณสร้างแอปในแพลตฟอร์มอย่าง AppMaster, PostgreSQL ก็เป็นที่อยู่ตามธรรมชาติสำหรับข้อมูลเชิงโครงสร้างและสิทธิ์ คำถามคือการค้นหา embedding ควรอยู่ในนั้นด้วยหรือย้ายไปบริการเฉพาะทางในขณะที่ Postgres ยังคงเป็นแหล่งความจริง
ทีมมักเลือกตามฟีเจอร์แล้วประหลาดใจกับงานประจำ การตัดสินใจที่แท้จริงคือคุณอยากให้ความซับซ้อนอยู่ที่ไหน: ในการตั้งค่า Postgres ที่มีอยู่ หรือในบริการแยกต่างหาก
กับ pgvector คุณกำลังเพิ่มการค้นหาเวกเตอร์เข้าไปในฐานข้อมูลที่คุณรันอยู่แล้ว การตั้งค่ามักตรงไปตรงมา แต่ก็ยังเป็นงานด้านฐานข้อมูล ไม่ใช่แค่โค้ดแอป
การตั้งค่า pgvector ทั่วไปรวมถึงการเปิดใช้ extension เพิ่มคอลัมน์ embedding สร้างดัชนีที่ตรงกับรูปแบบคำค้น (และปรับจูนภายหลัง) ตัดสินใจว่าจะอัปเดต embeddings เมื่อเนื้อหาเปลี่ยนอย่างไร และเขียนคำสั่ง similarity ที่รวมตัวกรองปกติของคุณด้วย
กับบริการ managed vector database คุณกำลังสร้างระบบใหม่ข้างฐานข้อมูลหลัก นั่นอาจหมายถึง SQL น้อยลง แต่ต้องมีการเชื่อมต่อมากขึ้น
การตั้งค่าสำหรับบริการมักรวมการสร้างดัชนี (มิติและเมทริกการวัดระยะทาง) ต่อสาย API keys เข้ากับความลับ สร้างงาน ingestion เพื่อผลัก embeddings และเมตาดาตา รักษาการแมป ID ระหว่างเรกคอร์ดแอปและเรกคอร์ดเวกเตอร์ให้คงที่ และล็อกดาวน์การเข้าถึงเครือข่ายให้เฉพาะ backend ของคุณเท่านั้น
CI/CD และมิเกรชันก็แตกต่างกัน pgvector เข้ากับมิเกรชันและกระบวนการรีวิวที่มีอยู่ได้ตามธรรมชาติ บริการที่มีผู้ดูแลย้ายการเปลี่ยนแปลงเป็นโค้ดบวกการตั้งค่าผู้ดูแล ดังนั้นคุณต้องมีกระบวนการชัดเจนสำหรับการเปลี่ยนการกำหนดค่าและการรี-อินเด็กซ์
ความเป็นเจ้าของมักตามตัวเลือก pgvector มักพึ่งพา dev แอปบวกผู้ที่เป็นเจ้าของ Postgres (บางครั้ง DBA) บริการที่มีผู้ดูแลมักถูกดูแลโดยทีมแพลตฟอร์ม โดย dev แอปจัดการ ingestion และตรรกะการค้นหา นี่คือเหตุผลว่าการตัดสินใจนี้เกี่ยวกับโครงสร้างทีมพอ ๆ กับเทคโนโลยี
การค้นหาเชิงความหมายมีประโยชน์ก็ต่อเมื่อมันเคารพสิ่งที่ผู้ใช้ดูได้ ในแอปธุรกิจจริง ทุกเรกคอร์ดมีเมตาดาตาติดกับ embedding: org_id, user_id, role, status (open, closed), visibility (public, internal, private) ถ้าชั้นค้นหาไม่สามารถกรองเมตาดาตาเหล่านี้อย่างสะอาด คุณจะได้ผลลัพธ์ที่สับสนหรือแย่กว่านั้นคือข้อมูลรั่วไหล
ความแตกต่างเชิงปฏิบัติที่ใหญ่ที่สุดคือการกรองก่อนกับหลังการค้นหาเชิงเวกเตอร์ การกรองหลังฟังดูง่าย (ค้นหาทั้งหมดแล้วคัดแถวที่ห้ามทิ้ง) แต่ล้มเหลวในสองทางทั่วไป ประการแรก ผลลัพธ์ที่ดีที่สุดอาจถูกเอาออก ทำให้เหลือผลลัพธ์ที่แย่กว่า ประการที่สอง เพิ่มความเสี่ยงด้านความปลอดภัยหากส่วนใดของ pipeline เก็บล็อก แคช หรือเผยแพร่ผลลัพธ์ที่ยังไม่ผ่านการกรอง
กับ pgvector เวกเตอร์อยู่ใน PostgreSQL เคียงข้างเมตาดาตา ดังนั้นคุณสามารถใช้สิทธิ์ในคำสั่ง SQL เดียวกันและให้ Postgres บังคับใช้
ถ้าแอปของคุณใช้ Postgres อยู่แล้ว pgvector มักได้เปรียบเรื่องความเรียบง่าย: การค้นหาคือ "อีกคำสั่ง SQL" คุณสามารถ JOIN ข้ามตั๋ว ลูกค้า และสมาชิก และใช้ Row Level Security ให้ฐานข้อมูลบล็อกแถวที่ไม่ได้รับอนุญาต
รูปแบบที่พบบ่อยคือจำกัดชุดผู้สมัครด้วยตัวกรอง org และ status แล้วรัน similarity บนสิ่งที่เหลือ อาจผสมการแมตช์คีย์เวิร์ดสำหรับตัวระบุที่ต้องตรงด้วย
บริการ vector หลายรายรองรับตัวกรองเมตาดาตา แต่ภาษาตัวกรองอาจจำกัดและไม่มี JOIN คุณมักทำ denormalize เมตาดาตาเข้าทุกเรกคอร์ดเวกเตอร์และทำการเช็คสิทธิ์ในแอปอีกครั้ง
สำหรับการค้นหาไฮบริดในแอปธุรกิจ คุณมักต้องการให้ส่วนเหล่านี้ทำงานร่วมกัน: ตัวกรองแข็ง (org, role, status, visibility), การแมตช์คีย์เวิร์ด (คำตรงเช่นหมายเลขใบแจ้งหนี้), ความคล้ายเชิงเวกเตอร์ (ความหมาย), และกฎการจัดลำดับ (ให้คะแนนรายการล่าสุดหรือรายการจากลูกค้าแพลนสูงขึ้น)
ตัวอย่าง: พอร์ทัลซัพพอร์ตที่สร้างใน AppMaster สามารถเก็บตั๋วและสิทธิ์ใน PostgreSQL ทำให้การบังคับ "agent เห็นเฉพาะ org ของตัวเอง" ทำได้ตรงไปตรงมาพร้อมยังได้ผลลัพธ์เชิงความหมายจากสรุปตั๋วและการตอบกลับ
คุณภาพการค้นหาคือการผสมระหว่างความเกี่ยวข้อง (ผลลัพธ์มีประโยชน์ไหม) และความเร็ว (รู้สึกทันทีไหม) กับทั้ง pgvector และบริการที่มีผู้ดูแล คุณมักแลกความแม่นยำเล็กน้อยเพื่อความหน่วงต่ำด้วยการใช้การค้นหาโดยประมาณ การแลกเปลี่ยนนี้มักพอรับได้สำหรับแอปธุรกิจ ตราบที่คุณวัดด้วยคำค้นจริง
โดยรวมคุณปรับจูนสามอย่าง: โมเดล embedding (ความหมายเป็นอย่างไร), การตั้งค่าดัชนี (เครื่องมือค้นหาต้องค้นหาลึกแค่ไหน), และเลเยอร์การจัดลำดับ (จัดผลลัพธ์อย่างไรเมื่อรวมตัวกรอง ความสด หรือความนิยม)
ใน PostgreSQL กับ pgvector คุณมักเลือกดัชนีอย่าง IVFFlat หรือ HNSW IVFFlat เร็วและเบาสร้าง แต่คุณต้องปรับจำนวน "lists" และมักต้องมีข้อมูลพอสมควรก่อนจะเห็นผล HNSW ให้ recall ดีกว่าในความหน่วงต่ำ แต่ใช้หน่วยความจำมากและสร้างนาน บริการที่มีผู้ดูแลก็มักมีตัวเลือกคล้ายกันแค่ชื่อและค่าเริ่มต้นต่างกัน
มีวิธีปฏิบัติที่สำคัญกว่าที่คนคาดคิด: แคชคำค้นยอดนิยม งานแบบแบตช์เมื่อทำได้ (เช่น prefetch หน้าถัดไป) และพิจารณาฟลูว์สองขั้นตอนที่ทำการค้นหาเวกเตอร์เร็ว ๆ แล้วรี-แร็งก์ท็อป 20–100 ด้วยสัญญาณธุรกิจเช่นความสดหรือระดับลูกค้า นอกจากนี้จงระวังจำนวนรอบเครือข่าย ถ้าการค้นหาอยู่ในบริการแยก ทุกคำค้นคือการโต้ตอบอีกครั้ง
เพื่อวัดคุณภาพ เริ่มจากเล็กและจับต้องได้ เก็บ 20–50 คำถามผู้ใช้จริง กำหนดว่า "คำตอบที่ดี" เป็นอย่างไร แล้วติดตามอัตราการถูกในท็อป 3 และท็อป 10 ค่ากลางและ p95 ของความหน่วง เปอร์เซ็นต์คำค้นที่ไม่มีผลลัพธ์ดี และการลดลงของคุณภาพเมื่อใช้สิทธิ์และตัวกรอง
ตรงนี้เองที่ตัวเลือกเลิกเป็นทฤษฎี ตัวเลือกที่ดีที่สุดคืออันที่เข้าถึงเป้าความเกี่ยวข้องได้ที่ความหน่วงที่ผู้ใช้รับได้ โดยมีการปรับจูนที่ทีมดูแลได้จริง
ทีมหลายทีมเริ่มด้วย pgvector เพราะเก็บทุกอย่างในที่เดียว: ข้อมูลแอปและ embeddings สำหรับแอปธุรกิจจำนวนมาก โหนด PostgreSQL เดียวพอเพียง โดยเฉพาะถ้าคุณมีเวกเตอร์เป็นหลักหมื่นถึงหลักแสนและการค้นหาไม่ใช่ไดร์เวอร์ทราฟฟิกหลัก
คุณจะเจอข้อจำกัดเมื่อการค้นหาเชิงความหมายกลายเป็นการกระทำหลักของผู้ใช้ (บนหลายหน้า ในทุกตั๋ว ในแชท) หรือเมื่อคุณเก็บล้านๆ เวกเตอร์และต้องการเวลาแรงตอบสนองที่เข้มงวดในพีค
สัญญาณทั่วไปว่า Postgres เดียวเริ่มตึงคือ p95 ของการค้นพุ่งขึ้นขณะเขียนปกติ ต้องเลือกระหว่างดัชนีที่เร็วกับความเร็วเขียนที่ยอมรับได้ งานบำรุงรักษากลายเป็นต้อง "กำหนดเวลาในตอนกลางคืน" และต้องการการสเกลที่ต่างจากฐานข้อมูลส่วนอื่น
กับ pgvector การสเกลมักหมายถึงเพิ่ม read replicas สำหรับโหลดการค้นหา แบ่งพาร์ติชันตาราง ปรับจูนดัชนี และวางแผนสำหรับการสร้างดัชนีและการเติบโตของสตอเรจ ทำได้แน่แต่กลายเป็นงานต่อเนื่อง คุณยังต้องตัดสินใจเช่นเก็บ embeddings ในตารางเดียวกับข้อมูลธุรกิจหรือแยกเพื่อลดบวมและการล็อก
บริการ vector แบบมีผู้ดูแลย้ายงานส่วนใหญ่ให้กับผู้ขาย มักเสนอการสเกลแยกคำนวณและสตอเรจ การชาร์ดในตัว และความพร้อมใช้งานที่ง่ายกว่า ข้อแลกคือต้องปฏิบัติการสองระบบ (Postgres และที่เก็บเวกเตอร์) และรักษาเมตาดาตาและสิทธิ์ให้สอดคล้อง
ต้นทุนมักทำให้ทีมประหลาดใจมากกว่าประสิทธิภาพ ปัจจัยหลักคือสตอเรจ (เวกเตอร์บวกดัชนีโตเร็ว), ปริมาณคำค้นพีค (มักกำหนดบิล), ความถี่การอัปเดต (รี-embed และ upsert), และการย้ายข้อมูล (การเรียกเพิ่มเมื่อแอปต้องกรองหนัก)
ถ้าคุณตัดสินใจระหว่าง pgvector และบริการ เลือกความเจ็บปวดที่คุณยอมรับได้: ปรับจูน Postgres และวางแผนความจุอย่างลึก หรือจ่ายเพิ่มเพื่อสเกลง่ายขึ้นขณะที่จัดการพึ่งพาเพิ่มอีกหนึ่งชิ้น
รายละเอียดด้านความปลอดภัยมักตัดสินเร็วกว่าการทดสอบความเร็ว ถามตั้งแต่ต้นว่าข้อมูลจะอยู่ที่ไหน ใครดูได้ และเกิดอะไรขึ้นเวลาระบบล่ม
เริ่มจากที่ตั้งข้อมูลและการเข้าถึง Embeddings ยังสามารถรั่วความหมายได้ และทีมหลายแห่งเก็บคลิปข้อความดิบสำหรับการเน้นไฮไลต์ ให้ชัดเจนว่าระบบไหนเก็บข้อความดิบ (ตั๋ว โน้ต เอกสาร) และระบบไหนเก็บเฉพาะ embeddings ตัดสินใจด้วยว่าใครในบริษัทสามารถเรียกดูสโตร์โดยตรง และคุณต้องแยกสภาพแวดล้อมโปรดักชันกับการวิเคราะห์อย่างเข้มงวดหรือไม่
ถามคำถามเหล่านี้สำหรับทั้งสองทางเลือก:
การแยกผู้เช่าแบบหลายรายเป็นสิ่งที่ทำให้คนสะดุด หากลูกค้าหนึ่งต้องไม่ส่งผลต่อลูกค้าอีกคน คุณต้องกำหนด tenant scoping อย่างเข้มงวดในทุกคำค้น กับ PostgreSQL ทำได้โดย Row Level Security และรูปแบบคำค้นที่ระมัดระวัง กับบริการ managed มักพึ่ง namespaces หรือ collections บวกตรรกะแอป
วางแผนสำหรับการหยุดชะงักของการค้นหา ถ้าสตอร์การค้นหาล้ม จะให้ผู้ใช้เห็นอะไร ค่าเริ่มต้นที่ปลอดภัยคือ fallback เป็นการค้นหาด้วยคีย์เวิร์ด หรือแสดงรายการล่าสุดเท่านั้น แทนที่จะทำให้หน้าใช้งานไม่ได้
ตัวอย่าง: ในพอร์ทัลซัพพอร์ตที่สร้างด้วย AppMaster คุณอาจเก็บตั๋วใน PostgreSQL และมองว่าการค้นหาเชิงความหมายเป็นฟีเจอร์เสริม ถ้า embeddings โหลดไม่ขึ้น พอร์ทัลยังสามารถแสดงรายการตั๋วและอนุญาตการค้นหาด้วยคีย์เวิร์ดระบุคำเฉพาะจนกว่าจะกู้บริการเวกเตอร์ได้
วิธีปลอดภัยสุดคือรันพายลอตเล็กที่มีลักษณะเหมือนแอปจริง ไม่ใช่โน้ตบุ๊กเดโม
เริ่มจากเขียนสิ่งที่คุณกำลังค้นหาและสิ่งที่ต้องกรองจริง ๆ “ค้นหาบทความเรา” คลุมเครือเกินไป แต่ “ค้นหาบทความช่วยเหลือ คำตอบตั๋ว และคู่มือ PDF แต่แสดงเฉพาะรายการที่ผู้ใช้ดูได้” เป็นข้อกำหนดจริงๆ สิทธิ์ ผู้เช่า ภาษา พื้นที่ผลิตภัณฑ์ และตัวกรอง “เฉพาะเนื้อหาที่เผยแพร่” มักตัดสินผู้ชนะ
ถัดไป เลือกโมเดล embedding และแผนรีเฟรช ตัดสินใจว่าอะไรจะถูก embed (ทั้งเอกสาร ชิ้นย่อย หรือทั้งสอง) และอัปเดตบ่อยแค่ไหน (ทุกการแก้ไข ทุกคืน หรือเมื่อเผยแพร่) ถ้าเนื้อเปลี่ยนบ่อย ให้วัดว่าการรี-embed จะเจ็บปวดแค่ไหน ไม่ใช่แค่วัดความเร็วคำค้น
จากนั้น สร้าง API การค้นหาแบบบาง ๆ ใน backend ของคุณ เก็บให้เรียบง่าย: endpoint เดียวที่รับคำค้นพร้อมฟิลด์ตัวกรอง คืนผลท็อป และบันทึกเหตุการณ์ หากสร้างด้วย AppMaster คุณสามารถทำ ingestion และโฟลว์อัปเดตเป็นบริการ backend บวก Business Process ที่เรียก provider ของ embedding เขียนเวกเตอร์และเมตาดาตา และบังคับกฎการเข้าถึง
รันพายลอตสองสัปดาห์กับผู้ใช้จริงและงานจริง ใช้คำถามที่ผู้ใช้ถามบ่อย ๆ จำนวนหนึ่ง ติดตามอัตราการหาคำตอบและเวลาถึงผลลัพธ์ที่มีประโยชน์ ตรวจสอบผลลัพธ์ที่แย่ทุกสัปดาห์ ดูปริมาณการรี-embedและโหลดคำค้น และทดสอบโหมดล้มเหลวเช่นเมตาดาตาหายหรือเวกเตอร์ล้าสมัย
สุดท้าย ตัดสินใจบนหลักฐาน เก็บ pgvector ถ้ามันตอบโจทย์คุณภาพและการกรองด้วยงานปฏิบัติการที่รับได้ เปลี่ยนเป็น managed ถ้าการสเกลและความน่าเชื่อถือเป็นเรื่องสำคัญ หรือรันฮับริด (PostgreSQL สำหรับเมตาดาตาและสิทธิ์, vector store สำหรับการดึง) ถ้าเหมาะกับสแตกคุณ
ข้อผิดพลาดส่วนใหญ่ปรากฏหลังเดโมแรกทำงานได้ Proof of concept เร็ว ๆ อาจดูดี แต่พังเมื่อเอาผู้ใช้จริง ข้อมูลจริง และกฎจริงเข้ามา
ปัญหาที่มักทำให้ต้องทำงานซ้ำมีดังนี้:
การทดสอบง่าย ๆ ใน "วัน-2" จะจับสิ่งเหล่านี้เร็ว: เพิ่มกฎสิทธิ์ใหม่ อัปเดต 20 รายการ ลบ 5 รายการ แล้วถาม 10 คำถามประเมินเดิมอีกครั้ง ถ้าสร้างบนแพลตฟอร์มอย่าง AppMaster ให้วางแผนเช็คนี้ควบคู่กับลอจิกธุรกิจและโมเดลฐานข้อมูลของคุณ ไม่ใช่แค่คิดทีหลัง
บริษัท SaaS ขนาดกลางมีพอร์ทัลซัพพอร์ตที่มีสองประเภทเนื้อหาหลัก: ตั๋วลูกค้าและบทความศูนย์ช่วยเหลือ พวกเขาต้องการกล่องค้นหาที่เข้าใจความหมาย ดังนั้นพิมพ์ว่า “ล็อกอินไม่ได้หลังเปลี่ยนเบอร์” ควรแสดงบทความที่ใช่และตั๋วเก่าที่คล้ายกัน
ข้อที่ต้องมีไม่ได้นั้นปฏิเสธไม่ได้: ลูกค้าแต่ละรายต้องเห็นตั๋วของตัวเองเท่านั้น เอเจนต์ต้องกรองตามสถานะ (open, pending, solved) และผลลัพธ์ต้องรู้สึกทันทีเพราะมีคำแนะนำขณะแพทย์พิมพ์
ถ้าพอร์ทัลเก็บตั๋วและบทความใน PostgreSQL อยู่แล้ว (พบบ่อยถ้าสร้างบนสแตกที่รวม Postgres เช่น AppMaster) การเพิ่ม pgvector มักเป็นก้าวแรกที่สะอาด คุณเก็บ embeddings เมตาดาตา และสิทธิ์ในที่เดียว ดังนั้น "เฉพาะตั๋วของ customer_123" ก็เป็น WHERE clause ปกติ
สิ่งนี้มักเวิร์กดีเมื่อชุดข้อมูลยังปานกลาง (หลักหมื่นถึงหลักแสน) ทีมของคุณคุ้นเคยกับการจูนดัชนีและแผนคำสั่งของ Postgres และคุณต้องการชิ้นส่วนระบบน้อยลงเพื่อลดงานด้านการจัดการสิทธิ์
ข้อแลกคือการค้นหาเชิงเวกเตอร์อาจแข่งกับงานธุรกรรม เมื่อการใช้งานโตขึ้นคุณอาจต้องเพิ่มความจุ ระบุตรรกะดัชนี หรือตั้งค่า Postgres แยกเพื่อปกป้องการเขียนตั๋วและ SLA
กับบริการ managed คุณมักเก็บ embeddings และ ID ในบริการนั้น แล้วเก็บความจริง (status, customer_id, permissions) ใน PostgreSQL ทีมมักกรองใน Postgres ก่อนแล้วค้นหา ID ที่มีสิทธิ์ หรือค้นหาก่อนแล้วเช็คสิทธิ์อีกครั้งก่อนแสดงผล
ตัวเลือกนี้มักชนะเมื่อการเติบโตไม่แน่นอนหรือทีมไม่ต้องการใช้เวลาปรับจูนประสิทธิภาพ แต่ลำดับการเช็คสิทธิ์ต้องรอบคอบ มิฉะนั้นเสี่ยงข้อมูลรั่วข้ามลูกค้า
การตัดสินใจเชิงปฏิบัติคือเริ่มด้วย pgvector ถ้าคุณต้องการการกรองเข้มงวดและการปฏิบัติการเรียบง่ายตอนนี้ แล้ววางแผนย้ายไปบริการ managed ถ้าคาดว่าจะโตเร็ว มีปริมาณคำค้นมาก หรือต้องไม่ให้การค้นหาชะลอฐานข้อมูลหลัก
ถ้าติดอยู่ หยุดถกเถียงและเขียนสิ่งที่แอปต้องทำในวันแรก ข้อกำหนดจริงมักปรากฏในพายลอตเล็กกับผู้ใช้จริงและข้อมูลจริง
คำถามเหล่านี้มักตัดสินผู้ชนะเร็วกว่าการวัดประสิทธิภาพ:
วางแผนสำหรับการเปลี่ยนแปลง Embeddings ไม่ใช่ "ตั้งแล้วลืม" ข้อความเปลี่ยน โมเดลเปลี่ยน และความเกี่ยวข้องเปลี่ยนไปจนกว่าจะมีคนบ่น ตัดสินตั้งแต่ต้นว่าจะจัดการอัปเดตอย่างไร จะตรวจจับการเปลี่ยนแปลงอย่างไร และจะมอนิเตอร์อะไร (ความหน่วงคำค้น อัตราข้อผิดพลาด recall บนชุดทดสอบเล็ก ๆ และคำค้นที่ไม่มีผลลัพธ์)
ถ้าต้องการไปเร็วสำหรับแอปธุรกิจรอบการค้นหา AppMaster (appmaster.io) อาจเป็นทางเลือกปฏิบัติได้: มันให้การโมเดลข้อมูล PostgreSQL ลอจิก backend และ UI เว็บ/มือถือในเวิร์กโฟลว์โค้ดต่ำเดียว และคุณสามารถเพิ่มการค้นหาเชิงความหมายเป็นการทำซ้ำเมื่อฟีเจอร์หลักและสิทธิ์เสร็จแล้ว
Semantic search จะคืนผลลัพธ์ที่มีประโยชน์แม้คำที่ผู้ใช้พิมพ์จะไม่ตรงกับคำในเอกสาร สำหรับคนที่พิมพ์คำย่อ พิมพ์ผิด หรือบรรยายอาการแทนใช้คำทางการ เช่นในพอร์ทัลซัพพอร์ต เครื่องมือภายใน หรือฐานความรู้ การค้นหาเชิงความหมายช่วยจับเจตนาแทนคำตรงตัว
ใช้ pgvector เมื่อคุณต้องการชิ้นส่วนระบบน้อยลง การกรองด้วย SQL ที่เข้มงวด และเมื่อขนาดข้อมูลกับทราฟฟิกยังไม่มาก pgvector มักเป็นทางลัดที่เร็วที่สุดสำหรับการค้นหาที่คำนึงถึงสิทธิ์ เพราะเวกเตอร์และเมตาดาตาอยู่ใน PostgreSQL เดียวกันที่คุณเชื่อถือ
พิจารณาใช้บริการ vector database แบบมีผู้ดูแลเมื่อคุณคาดว่าจะโตเร็ว ทั้งในด้านจำนวนเวกเตอร์หรือปริมาณคำค้น หรือเมื่อคุณต้องการให้การสเกลและความพร้อมใช้งานของการค้นหาจัดการนอกฐานข้อมูลหลัก คุณจะแลกกับงานปฏิบัติการที่ง่ายขึ้นด้วยงานบูรณาการเพิ่มเติมและการจัดการสิทธิ์อย่างระมัดระวัง
Embedding คือกระบวนการแปลงข้อความเป็นเวกเตอร์ตัวเลขที่แทนความหมาย เวกเตอร์สโตร์ (หรือ pgvector ใน PostgreSQL) เก็บเวกเตอร์เหล่านี้และสามารถหาคู่ที่ใกล้ที่สุดกับเวกเตอร์คำถามของผู้ใช้ได้อย่างรวดเร็ว ซึ่งทำให้คุณได้ผลลัพธ์ที่ “มีความหมายเหมือนกัน”
การกรองหลังการค้นหามักจะเอาผลลัพธ์ที่ดีที่สุดออกไปและทำให้ผู้ใช้ได้ผลลัพธ์แย่ลงหรือหน้าเปล่า นอกจากนี้ยังเพิ่มความเสี่ยงการเปิดเผยข้อมูลโดยไม่ตั้งใจผ่านล็อก แคช หรือดีบัก จึงปลอดภัยกว่าถ้าจะใช้ตัวกรองผู้เช่าและบทบาทให้เร็วที่สุดใน pipeline
กับ pgvector คุณสามารถใช้สิทธิ์ การ JOIN และ Row Level Security ในคำสั่ง SQL เดียวกับที่ทำการค้นหาเชิงความคล้าย ทำให้การการันตีว่า “จะไม่แสดงแถวที่ห้าม” ทำได้ง่ายขึ้นเพราะ PostgreSQL บังคับใช้ตรงที่ข้อมูลอยู่
บริการ vector แบบมีผู้ดูแลส่วนใหญ่รองรับตัวกรองเมตาดาตา แต่โดยทั่วไปไม่รองรับ JOIN และภาษาตัวกรองอาจจำกัด คุณมักต้อง denormalize เมตาดาตาที่เกี่ยวกับสิทธิ์เข้าไปในแต่ละเรกคอร์ดเวกเตอร์และบังคับเช็คการอนุญาตในแอปพลิเคชันอีกที
Chunking คือการแบ่งเอกสารยาวเป็นชิ้นเล็กก่อน embedding ซึ่งมักให้ความแม่นยำมากกว่าเพราะแต่ละเวกเตอร์แทนแนวคิดที่โฟกัส ชิ้นเดียวของเอกสารทั้งฉบับอาจพอใช้ได้กับรายการสั้น ๆ แต่ตั๋วยาว นโยบาย หรือ PDF มักจะคลุมเครือถ้าไม่แบ่งชิ้นและติดตามเวอร์ชัน
วางแผนการอัปเดตตั้งแต่วันแรก: รี-embed เมื่อเผยแพร่หรือแก้ไขเนื้อหาที่เปลี่ยนบ่อย และลบเวกเตอร์เมื่อระเบียนต้นทางถูกลบ หากไม่ทำคุณจะเสิร์ฟผลลัพธ์เก่าที่ชี้ไปยังข้อความที่หายไปหรือไม่อัปเดต
พาร์ทไพล็อตที่ใช้คำค้นจริงและตัวกรองเข้มงวด วัดความเกี่ยวข้องและความหน่วงเวลา ทดสอบกรณีล้มเหลวเช่นเมตาดาตาหายหรือเวกเตอร์ล้าสมัย แล้วเลือกตัวเลือกที่คืนผลลัพธ์บนสุดที่ดีภายใต้กฎการอนุญาตของคุณ โดยคำนึงถึงค่าใช้จ่ายและงานปฏิบัติการที่ทีมรับได้



ทดลองกับ AppMaster ด้วยแผนฟรี
เมื่อคุณพร้อม คุณสามารถเลือกการสมัครที่เหมาะสมได้


