แอปจองอุปกรณ์: ป้องกันการจองซ้ำและติดตามการคืน
วางแผนแอปจองอุปกรณ์ที่ป้องกันการจองซ้ำ บันทึกการคืนและความเสียหาย พร้อมระงับอุปกรณ์ที่มีปัญหาเพื่อรอการบำรุงรักษา
การตั้งค่าการสังเกตการณ์ขั้นพื้นฐานสำหรับ backend ที่เน้น CRUD: ล็อกแบบมีโครงสร้าง เมตริกหลัก และการแจ้งเตือนเชิงปฏิบัติการ เพื่อจับ query ช้า ข้อผิดพลาด และการล่มได้ตั้งแต่เนิ่นๆ
request_id, user, endpoint และ error\n- เมตริกหลักสองสามตัว: อัตราคำขอ, อัตรา error, latency, และเวลาในฐานข้อมูล\n- การแจ้งเตือนที่ผูกกับผลกระทบต่อผู้ใช้ (การพุ่งของ error หรือตอบช้าต่อเนื่อง) ไม่ใช่ทุกคำเตือนภายใน\n\nแยกอาการออกจากสาเหตุเป็นประโยชน์ อาการคือสิ่งที่ผู้ใช้รู้สึก: 500s, timeout, หน้าช้า สาเหตุคือสิ่งที่สร้างปัญหา: lock contention, pool connections อิ่มตัว, หรือ query ช้าเพราะฟิลเตอร์ใหม่ เพิ่มการแจ้งเตือนบนอาการแล้วใช้สัญญาณสาเหตุเพื่อสืบสวน\n\nกฎปฏิบัติหนึ่ง: เลือกที่เดียวในการดูสัญญาณสำคัญ การสลับบริบทระหว่างเครื่องมือล็อก, เครื่องมือเมตริก และ inbox การแจ้งเตือนแยกกันจะทำให้ช้าลงเมื่อต้องการเร็วที่สุด\n\n## ล็อกแบบมีโครงสร้างที่อ่านได้แม้ในความกดดัน\n\nเมื่อมีบางอย่างพัง ทางลัดที่เร็วที่สุดมักเป็น: “คำขอไหนกันแน่ที่ผู้ใช้คนนี้เรียก?” นั่นคือเหตุผลว่าทำไม correlation ID ที่เสถียรจึงสำคัญมากกว่าการปรับแต่งล็อกหลายอย่าง\n\nเลือกชื่อตัวแปรเดียว (โดยทั่วไป request_id) และถือเป็นฟิลด์บังคับ สร้างที่ขอบ (API gateway หรือ handler แรก), ส่งผ่านการเรียกภายใน, และใส่มันในทุกบรรทัดล็อก สำหรับงานแบ็กกราวด์ สร้าง request_id ใหม่สำหรับการรันแต่ละครั้งและเก็บ parent_request_id เมื่องานถูกทริกเกอร์โดยการเรียก API\n\nบันทึกเป็น JSON ไม่ใช่ข้อความเสรี มันทำให้ล็อกค้นหาได้และสม่ำเสมอเมื่อคุณเหนื่อย เครียด และกำลังอ่านผ่าน\n\nชุดฟิลด์เรียบง่ายเพียงพอสำหรับบริการ API ที่เน้น CRUD ส่วนใหญ่:\n\n- timestamp, level, service, env\n- request_id, route, method, status\n- duration_ms, db_query_count\n- tenant_id หรือ account_id (ตัวระบุที่ปลอดภัย ไม่ใช่ข้อมูลส่วนบุคคล)\n\nล็อกควรช่วยให้คุณระบุได้ว่า “ลูกค้ารายไหนและหน้าจอไหน” โดยไม่กลายเป็นการรั่วไหลของข้อมูล หลีกเลี่ยงการบันทึกชื่อ อีเมล เบอร์โทร ที่อยู่ โทเคน หรือร่างคำขอเต็มโดยดีฟอลต์ หากต้องการรายละเอียดลึก ให้บันทึกเมื่อร้องขอและทำ redaction\n\nสองฟิลด์ที่ให้ผลเร็วในระบบ CRUD คือ duration_ms และ db_query_count พวกมันจับ handler ช้าและรูปแบบ N+1 โดยไม่ต้องมี tracing\n\nกำหนดระดับล็อกให้ทุกคนใช้แบบเดียวกัน:\n\n- info: เหตุการณ์ที่คาดว่าจะเกิด (คำขอเสร็จสิ้น งานเริ่ม)\n- warn: เรื่องผิดปกติแต่กู้คืนได้ (คำขอช้า retry สำเร็จ)\n- error: คำขอหรืองานล้มเหลว (exception, timeout, dependency ผิดพลาด)\n\nถ้าคุณสร้าง backend ด้วยแพลตฟอร์มเช่น AppMaster ให้ใช้ชื่อตัวแปรเดียวกันข้ามบริการที่สร้างขึ้น เพื่อให้การค้นหาโดย request_id ทำงานทุกที่\n\n## เมตริกสำคัญที่มีความหมายสำหรับ backend CRUD และ API\n\nเหตุการณ์ส่วนใหญ่ในแอป CRUD มีรูปแบบคล้ายกัน: หนึ่งหรือสอง endpoint ช้าลง, ฐานข้อมูลถูกกดดัน, และผู้ใช้เห็นสปินเนอร์หรือ timeout เมตริกของคุณควรบอกเรื่องนี้ให้ชัดภายในไม่กี่นาที\n\nชุดเมตริกขั้นต่ำมักครอบคลุมห้าด้าน:\n\n- Traffic: requests per second (แยกตาม route หรืออย่างน้อยแยกตาม service) และอัตราร้องขอตามกลุ่มสถานะ (2xx, 4xx, 5xx)\n- Errors: อัตรา 5xx, จำนวน timeout, และเมตริกแยกสำหรับ “business errors” ที่ส่งกลับเป็น 4xx (เพื่อไม่ให้คนถูกปลุกเพราะความผิดของผู้ใช้)\n- Latency (percentiles): p50 สำหรับประสบการณ์ทั่วไป และ p95 (บางครั้ง p99) สำหรับตรวจจับว่า “มีอะไรผิด”\n- Saturation: CPU และหน่วยความจำ รวมถึงความอิ่มตัวเฉพาะแอป (การใช้งาน worker, ความกดดัน thread/goroutine ถ้าคุณเปิดเผย)\n- Database pressure: query duration p95, การใช้งาน pool ของ connection เทียบกับค่า max, และเวลาในการรอการล็อก (หรือจำนวน query ที่รอล็อก)\n\nสองรายละเอียดทำให้เมตริกนำไปปฏิบัติได้มากขึ้น\n\nประการแรก แยกคำขอแบบอินเทอร์แอคทีฟออกจากงานแบ็กกราวด์ งานอีเมลช้า ๆ หรือ retry ของ webhook อาจแย่ง CPU, connection ของ DB, หรือเครือข่ายออกไป ทำให้ API ดู “ช้าแบบสุ่ม” ติดตามคิว retry และระยะเวลางานเป็น time series แยกต่างหาก แม้ว่าจะรันใน backend เดียวกัน\n\nประการที่สอง แนบเมตาดาต้าเวอร์ชัน/บิลด์การ build กับแดชบอร์ดและการแจ้งเตือน เมื่อคุณ deploy backend ที่สร้างขึ้นใหม่ (เช่น หลังจาก regenerate โค้ดจากเครื่องมือ no-code อย่าง AppMaster) คุณจะตอบคำถามได้เร็วขึ้น: อัตรา error หรือ p95 latency กระโดดหลัง release นี้ไหม?\n\nกฎง่าย ๆ: ถ้าเมตริกบอกคุณไม่ได้ว่าควรทำอะไรต่อ (rollback, scale, แก้ query, หรือหยุดงาน) มันไม่ควรอยู่ในชุดขั้นต่ำของคุณ\n\n## สัญญาณจากฐานข้อมูล: สาเหตุที่พบบ่อยของความเจ็บปวดใน CRUD\n\nในแอป CRUD ฐานข้อมูลมักเป็นที่ที่ “ความรู้สึกช้า” กลายเป็นความเจ็บปวดของผู้ใช้ การตั้งค่าขั้นต่ำควรบอกชัดว่า bottleneck อยู่ที่ PostgreSQL (ไม่ใช่โค้ด API) และเป็นปัญหาแบบไหน\n\n### สิ่งที่ควรวัดก่อนใน PostgreSQL\n\nคุณไม่ต้องมีแดชบอร์ดเป็นสิบหน้า เริ่มด้วยสัญญาณที่อธิบายเหตุการณ์ส่วนใหญ่ได้:\n\n- อัตรา query ช้า และ query time p95/p99 (รวมถึง top slow queries)\n- การรอล็อกและ deadlock (ใครบล็อกใคร)\n- การใช้งาน connection (active connections เทียบกับ pool limit, การเชื่อมต่อที่ล้มเหลว)\n- แรงกดดันดิสก์และ I/O (latency, saturation, พื้นที่ว่าง)\n- การหน่วงของ replication (ถ้าคุณใช้ read replicas)\n\n### แยกเวลาแอปกับเวลา DB\n\nเพิ่ม histogram เวลาของ query ในชั้น API และแท็กด้วย endpoint หรือ use case (เช่น: GET /customers, “search orders”, “update ticket status”) นี่จะแสดงว่า endpoint ช้าจากการรันหลาย query เล็ก ๆ หรือจาก query ใหญ่เพียงตัวเดียว\n\n### ตรวจจับรูปแบบ N+1 ได้เร็ว\n\nหน้าจอ CRUD มักกระตุ้น N+1 queries: query รายการหนึ่ง แล้ว query ต่อแถวเพื่อดึงข้อมูลที่เกี่ยวข้อง ตรวจสอบ endpoint ที่จำนวนคำขอคงที่แต่จำนวน query ต่อคำขอเพิ่มขึ้น หากคุณสร้าง backend จากโมเดลและ business logic แบบ generate นี่มักเป็นจุดที่ต้องปรับรูปแบบการดึงข้อมูล\n\nถ้าคุณมี cache อยู่แล้ว ให้ติดตาม hit rate อย่าเพิ่ม cache แค่เพื่อให้กราฟดีขึ้น\n\nจัดการการเปลี่ยนสคีมาและ migration เป็นหน้าต่างเสี่ยง บันทึกเวลาที่เริ่มและจบ แล้วดู spike ของล็อก เวลา query และข้อผิดพลาดการเชื่อมต่อในช่วงนั้น\n\n## การแจ้งเตือนที่ปลุกคนที่ถูกคนและด้วยเหตุผลที่ถูกต้อง\n\nการแจ้งเตือนควรชี้ไปยังปัญหาจริงของผู้ใช้ ไม่ใช่กราฟที่ยุ่ง สำหรับแอป CRUD เริ่มจากการดูสิ่งที่ผู้ใช้รู้สึก: error และความช้า\n\nถ้าจะเพิ่มแค่สามการแจ้งเตือนตอนแรก ให้เป็น:\n\n- อัตรา 5xx ที่เพิ่มขึ้น\n- p95 latency ที่สูงอย่างต่อเนื่อง\n- การลดลงอย่างฉับพลันของคำขอที่สำเร็จ\n\nหลังจากนั้น เพิ่มการแจ้งเตือนแบบ “สาเหตุที่น่าจะเป็น” สองสามรายการ แอป CRUD มักล้มเหลวแบบที่คาดได้: DB หมด connections, คิวแบ็กกราวด์สะสม, หรือ endpoint เดียวเริ่ม timeout แล้วลากทั้ง API ลง\n\n### เกณฑ์: ใช้ baseline + margin ไม่ใช่การเดา\n\nการตั้งค่าเลขแข็งเช่น “p95 > 200ms” มักไม่เวิร์กในทุกสภาพแวดล้อม ให้วัดสัปดาห์ปกติแล้วตั้งการแจ้งเตือนเหนือปกติพร้อมมาร์จิ้นตัวอย่าง เช่น ถ้า p95 ปกติ 350-450ms ในชั่วโมงทำการ ให้แจ้งเตือนที่ 700ms เป็นเวลา 10 นาที ถ้า 5xx ปกติ 0.1-0.3% ให้ page ที่ 2% เป็นเวลา 5 นาที\n\nรักษาเกณฑ์ให้คงที่ หลีกเลี่ยงปรับทุกวัน ปรับหลังเหตุการณ์เมื่อคุณผูกการเปลี่ยนแปลงกับผลลัพธ์จริงได้\n\n### การเรียกผ่าน pager vs สร้างตั๋ว: ตัดสินใจก่อนจะต้องใช้มัน\n\nใช้สองระดับความรุนแรงเพื่อให้คนเชื่อถือสัญญาณ:\n\n- Page เมื่อผู้ใช้ถูกบล็อกหรือข้อมูลมีความเสี่ยง (5xx สูง, API timeout, pool connection ของ DB เกือบเต็ม)\n- สร้างตั๋ว เมื่อระบบเสื่อมลงแต่ไม่ฉุกเฉิน (p95 เพิ่มช้า ๆ, backlog คิวเพิ่ม, การใช้งานดิสก์ที่ขึ้นแนวโน้ม)\n\nเงียบการแจ้งเตือนในช่วงการเปลี่ยนแปลงที่คาดไว้เช่นหน้าต่าง deploy และการบำรุงรักษาที่วางแผนไว้\n\nทำให้การแจ้งเตือนปฏิบัติได้ แนบ “เช็คอะไรเป็นอันดับแรก” (top endpoint, DB connections, deploy ล่าสุด) และ “มีอะไรเปลี่ยน” (release ใหม่, migration) ถ้าคุณสร้างด้วย AppMaster ให้ระบุว่า backend หรือโมดูลใดถูก regenerate และ deploy ล่าสุด เพราะนั่นมักเป็นเบาะแสที่เร็วที่สุด\n\n## SLO ง่าย ๆ สำหรับแอปธุรกิจ (และวิธีที่มันกำหนดการแจ้งเตือน)\n\nการตั้งค่าขั้นพื้นฐานง่ายขึ้นเมื่อคุณตัดสินใจว่า “พอเพียง” คืออะไร นั่นคือหน้าที่ของ SLO: เป้าหมายชัดเจนที่เปลี่ยนการมอนิเตอร์ที่คลุมเครือให้เป็นการแจ้งเตือนเฉพาะ\n\nเริ่มด้วย SLIs ที่แม็ปกับสิ่งที่ผู้ใช้รู้สึก: availability (ผู้ใช้ทำคำขอสำเร็จไหม), latency (การทำงานเสร็จเร็วแค่ไหน), และอัตรา error (คำขอล้มเหลวบ่อยแค่ไหน)\n\nตั้ง SLO ต่อกลุ่ม endpoint ไม่ใช่ต่อ route ย่อย สำหรับแอป CRUD การจัดกลุ่มช่วยให้เข้าใจง่าย: reads (GET/list/search), writes (create/update/delete), และ auth (login/token refresh) จะหลีกเลี่ยงการมี SLO ย่อยเป็นร้อยที่ไม่มีใครดูแล\n\nตัวอย่าง SLO ที่เข้ากับความคาดหวังทั่วไป:\n\n- แอป CRUD ภายใน (พอร์ทัลแอดมิน): availability 99.5% ต่อเดือน, 95% ของ read requests ต่ำกว่า 800 ms, 95% ของ write requests ต่ำกว่า 1.5 s, อัตรา error ต่ำกว่า 0.5%\n- Public API: availability 99.9% ต่อเดือน, 99% ของ read requests ต่ำกว่า 400 ms, 99% ของ write requests ต่ำกว่า 800 ms, อัตรา error ต่ำกว่า 0.1%\n\nError budget คือเวลาที่ยอมให้ระบบแย่ภายใน SLO ตัวอย่าง SLO availability 99.9% ต่อเดือนหมายถึงคุณมีเวลาประมาณ 43 นาทีของ downtime ต่อเดือน ถ้าใช้หมดเร็ว ให้หยุดการเปลี่ยนแปลงเสี่ยงจนกว่าจะกลับมามั่นคง\n\nใช้ SLO เพื่อแยกว่าควรแจ้งเตือนหรือแค่ดูเป็นแนวโน้มบนแดชบอร์ด แจ้งเตือนเมื่อคุณกำลังเผา error budget อย่างรวดเร็ว (ผู้ใช้ล้มเหลวจริง) ไม่ใช่เมื่อเมตริกแค่แย่กว่าวันก่อนเล็กน้อย\n\nถ้าคุณสร้าง backend อย่างรวดเร็ว (เช่น AppMaster ที่สร้าง Go service) SLO ช่วยให้มุ่งเน้นที่ผลกระทบต่อผู้ใช้แม้การ implement จะเปลี่ยนแปลงได้บ่อย\n\n## ขั้นตอนทีละขั้น: สร้างการสังเกตการณ์ขั้นต่ำในหนึ่งวัน\n\nเริ่มจากส่วนที่ผู้ใช้แตะมากที่สุด เลือก API calls และงานที่ถ้าช้า/พัง จะทำให้แอปทั้งระบบรู้สึกล่ม\n\nจด endpoint และงานแบ็กกราวด์สำคัญ สำหรับแอป CRUD มักเป็น login, list/search, create/update, และงาน export/import หนึ่งงาน ถ้าคุณสร้าง backend ด้วย AppMaster ให้รวม endpoint ที่สร้างขึ้นและ Business Process ที่รันตามตารางหรือ webhook\n\n### แผนหนึ่งวัน\n\n- ชั่วโมงที่ 1: เลือก top 5 endpoints และ 1-2 background jobs จดว่า “ดี” เป็นอย่างไร: latency ทั่วไป อัตรา error ปกติ เวลา DB ปกติ\n- ชั่วโมงที่ 2-3: เพิ่มล็อกแบบมีโครงสร้างพร้อมฟิลด์สม่ำเสมอ: request_id, user_id (ถ้ามี), endpoint, status_code, latency_ms, db_time_ms, และ error_code สั้น ๆ สำหรับความล้มเหลวที่รู้จัก\n- ชั่วโมงที่ 3-4: เพิ่มเมตริกหลัก: requests per second, p95 latency, อัตรา 4xx, อัตรา 5xx, และเวลา DB (query duration และการใช้งาน pool ถ้ามี)\n- ชั่วโมงที่ 4-6: สร้างแดชบอร์ดสามหน้า: ภาพรวม (สุขภาพโดยรวม), มุมมองรายละเอียด API (แยกตาม endpoint), และมุมมองฐานข้อมูล (query ช้า, การล็อก, การใช้งาน connection)\n- ชั่วโมงที่ 6-8: เพิ่มการแจ้งเตือน, กระตุ้นความล้มเหลวที่ควบคุมได้, และยืนยันว่าการแจ้งเตือนปฏิบัติได้\n\nรักษาการแจ้งเตือนให้น้อยและชัดเจน คุณต้องการแจ้งเตือนที่ชี้ไปยังผลกระทบต่อผู้ใช้ ไม่ใช่แค่ “มีอะไรเปลี่ยน”\n\n### การแจ้งเตือนที่ควรเริ่มด้วย (5-8 รายการ)\n\nชุดเริ่มต้นที่มั่นคงคือ: p95 latency ของ API สูงเกินไป, อัตรา 5xx ต่อเนื่อง, พุ่งขึ้นของ 4xx (มักเกี่ยวกับ auth หรือ validation), งานแบ็กกราวด์ล้มเหลว, query ช้าใน DB, การใช้งาน connection ของ DB ใกล้ขีดจำกัด, และพื้นที่ดิสก์ต่ำ (ถ้าโฮสต์เอง)\n\nแล้วเขียน runbook ย่อสำหรับแต่ละการแจ้งเตือน หน้ากระดาษเดียวพอ: จะเช็คอะไรแรก (แผงแดชบอร์ดและฟิลด์ล็อกสำคัญ), สาเหตุที่น่าจะเป็น, และการกระทำแรกที่ปลอดภัย (restart worker ติดค้าง, rollback การเปลี่ยนแปลง, หยุดงานหนักชั่วคราว)\n\n## ความผิดพลาดทั่วไปที่ทำให้การมอนิเตอร์ดังหรือไร้ประโยชน์\n\nวิธีที่เร็วที่สุดจะเสียการตั้งค่าการสังเกตการณ์ขั้นพื้นฐานคือทำมันเป็นแค่ checkbox แอป CRUD มักล้มเหลวด้วยวิธีที่คาดได้ไม่กี่แบบ (query ช้า, timeout, release ผิดพลาด) ดังนั้นสัญญาณของคุณควรโฟกัสเรื่องเหล่านั้น\n\nความล้มเหลวที่พบบ่อยที่สุดคือ alert fatigue: แจ้งเตือนมากเกินไป แก้ไขน้อย ถ้าคุณปลุกคนทุกครั้ง ผู้คนจะหยุดเชื่อถือการแจ้งเตือนภายในสองสัปดาห์ กฎดี ๆ คือ: การแจ้งเตือนควรชี้ไปยังวิธีแก้ที่เป็นไปได้ ไม่ใช่แค่ “มีอะไรเปลี่ยน”\n\nอีกความผิดพลาดคลาสสิกคือขาด correlation IDs ถ้าคุณผูกล็อกข้อผิดพลาด คำขอช้า และ query ใน DB กับคำขอเดียวไม่ได้ คุณจะเสียเวลาหลายชั่วโมง ให้แน่ใจว่าทุกคำขอมี request_id (และใส่มันในล็อก, traces ถ้ามี, และการตอบกลับเมื่อปลอดภัย)\n\n### สิ่งที่สร้างเสียงรบกวนได้บ่อย\n\nระบบที่ดังมักมีปัญหาเหมือนกัน:\n\n- แจ้งเตือนเดียวรวม 4xx และ 5xx ทำให้ความผิดของลูกค้าและความล้มเหลวของเซิร์ฟเวอร์ดูเหมือนกัน\n- เมตริกจับเฉพาะค่าเฉลี่ย ทำให้หางของ latency (p95 หรือ p99) ถูกซ่อนไว้\n- ล็อกบันทึกข้อมูลละเอียดอ่อนโดยไม่ตั้งใจ (รหัสผ่าน, โทเคน, ร่างคำขอ)\n- การแจ้งเตือนเกิดขึ้นจากอาการโดยไม่มีบริบท (CPU สูง) แทนที่จะเป็นผลกระทบต่อผู้ใช้ (อัตรา error, latency)\n- การปล่อย deploy มองไม่เห็น ทำให้ regression ดูเหมือนความล้มเหลวแบบสุ่ม\n\nแอป CRUD เสี่ยงต่อ “กับดักค่าเฉลี่ย” มาก ค่าเฉลี่ยอาจดูปกติ แต่ query ช้าเพียงตัวเดียวก็ทำให้ 5% ของคำขอเจ็บปวดได้ การดู tail latency ควบคู่กับอัตราข้อผิดพลาดให้ภาพที่ชัดเจนกว่า\n\nเพิ่ม deploy markers ไม่ว่าคุณจะส่งจาก CI หรือ regenerate โค้ดบนแพลตฟอร์มอย่าง AppMaster ให้บันทึกเวอร์ชันและเวลาการ deploy เป็นเหตุการณ์และในล็อกของคุณ\n\n## เช็คลิสต์ด่วน: การสังเกตการณ์ขั้นต่ำ\n\nการตั้งค่าของคุณใช้งานได้เมื่อคุณตอบคำถามไม่กี่ข้อได้เร็ว โดยไม่ต้องค้นแดชบอร์ด 20 นาที ถ้าไม่ตอบ “ใช่/ไม่” ได้เร็ว คุณขาดสัญญาณสำคัญหรือมุมมองกระจัดกระจายเกินไป\n\n### การตรวจสอบเร็วในเหตุการณ์\n\nคุณควรทำส่วนใหญ่ได้ภายในนาทีเดียว:\n\n- คุณบอกได้ไหมว่าผู้ใช้กำลังล้มเหลวตอนนี้ (ใช่/ไม่) จากมุมมองข้อผิดพลาดเดียว (5xx, timeout, งานล้มเหลว)?\n- คุณหาจุดที่ช้าที่สุดของกลุ่ม endpoint และ p95 ของมันได้ไหม และเห็นว่ามันแย่ลงหรือไม่?\n- คุณแยกเวลาแอปกับเวลา DB สำหรับคำขอได้ไหม (handler time, DB query time, external calls)?\n- คุณเห็นว่าฐานข้อมูลใกล้ขีดจำกัด connection หรือ CPU ไหม และ query กำลังต่อคิวหรือไม่?\n- ถ้ามีการแจ้งเตือน มันแนะนำการกระทำถัดไปได้ไหม (rollback, scale, เช็ค DB connections, ตรวจ endpoint หนึ่ง) ไม่ใช่แค่ “latency สูง”?\n\nล็อกควรปลอดภัยและมีประโยชน์พร้อมกัน พวกมันต้องมีบริบทพอให้ติดตามคำขอที่ล้มเหลวข้ามบริการ แต่ต้องไม่รั่วไหลของข้อมูลส่วนบุคคล\n\n### การตรวจสอบความสมเหตุสมผลของล็อก\n\nเลือกความล้มเหลวล่าสุดหนึ่งรายการแล้วเปิดล็อก ยืนยันว่ามี request_id, endpoint, status code, duration, และข้อความข้อผิดพลาดที่ชัดเจน แล้วยืนยันด้วยว่าคุณไม่ได้ล็อกโทเคน รหัสผ่าน รายละเอียดการชำระเงินเต็ม หรือฟิลด์ส่วนบุคคล\n\nถ้าคุณสร้าง backend CRUD ด้วย AppMaster ตั้งเป้าสำหรับมุมมอง “incident” เดียวที่รวมเช็คเหล่านี้: ข้อผิดพลาด, p95 latency ตาม endpoint, และสุขภาพ DB นั่นครอบคลุม outage ส่วนใหญ่ในแอปธุรกิจจริงๆ\n\n## ตัวอย่าง: วินิจฉัยหน้าจอ CRUD ช้าที่สุดด้วยสัญญาณที่ถูกต้อง\n\nพอร์ทัลแอดมินภายในทำงานได้ดีทั้งเช้า แต่ช้าลงในชั่วโมงที่มีคนใช้มาก ผู้ใช้บ่นว่าเปิดรายการ “Orders” และบันทึกแก้ไขใช้ 10-20 วินาที\n\nเริ่มจากสัญญาณระดับสูง แดชบอร์ด API แสดงว่า p95 latency สำหรับ read endpoints กระโดดจาก ~300 ms เป็น 4-6 s ในขณะที่อัตรา error ยังต่ำ พร้อมกันนั้น แผงฐานข้อมูลแสดง active connections ใกล้ขีดจำกัด pool และการรอล็อกเพิ่มขึ้น CPU ของโหนด backend ปกติ จึงไม่ใช่ปัญหา compute\n\nต่อมาเลือกคำขอช้าหนึ่งรายการแล้วตามผ่านล็อก กรองตาม endpoint (เช่น GET /orders) แล้วเรียงตามระยะเวลา หาค่า request_id จากคำขอ 6 วินาทีแล้วค้นหาในบริการทั้งหมด คุณเห็น handler เสร็จเร็ว แต่บรรทัดล็อก query ใน request_id เดียวกันแสดง query 5.4 วินาที พร้อม rows=50 และ lock_wait_ms สูง\n\nตอนนี้คุณสรุปสาเหตุได้อย่างมั่นใจ: ความช้ามาจากเส้นทางฐานข้อมูล (query ช้าหรือ lock contention) ไม่ใช่เครือข่ายหรือ CPU ของ backend สิ่งนี้คือสิ่งที่การตั้งค่าขั้นต่ำให้คุณ: การจำกัดขอบเขตการค้นหาได้เร็วขึ้น\n\nวิธีแก้ปัญหาทั่วไปตามลำดับความปลอดภัย:\n\n- เพิ่มหรือตั้งค่า index ให้ตรงกับ filter/sort ที่ใช้บนหน้ารายการ\n- ลบ N+1 โดยดึงข้อมูลที่เกี่ยวข้องใน query เดียวหรือ join เดียว\n- จูน connection pool เพื่อไม่ให้ DB ถูกอดอาหารภายใต้โหลด\n- เพิ่ม caching เฉพาะข้อมูลอ่านมากที่มีความเสถียร (และจดวิธี invalidation)\n\nปิดวงด้วยการแจ้งเตือนที่เจาะจง Page ต่อเมื่อ p95 latency ของกลุ่ม endpoint อยู่เหนือเกณฑ์เป็นเวลา 10 นาทีพร้อมกับการใช้งาน connection ของ DB สูงกว่า (เช่น) 80% การผสมนี้ลดเสียงรบกวนและจับปัญหาได้เร็วยิ่งขึ้นครั้งถัดไป\n\n## ขั้นตอนต่อไป: รักษาให้เรียบง่าย แล้วปรับปรุงจากเหตุการณ์จริง\n\nการตั้งค่าการสังเกตการณ์ขั้นพื้นฐานควรรู้สึกน่าเบื่อในวันแรก ถ้าคุณเริ่มด้วยแดชบอร์ดและการแจ้งเตือนมากเกินไป คุณจะจูนมันตลอดเวลาและยังคงพลาดปัญหาจริงๆ\n\nทำให้เหตุการณ์แต่ละรายการเป็นฟีดแบ็ก หลังการปิดเหตุการณ์ ถามว่า: อะไรจะทำให้หาเจอเร็วขึ้นและวินิจฉัยง่ายขึ้น? เพิ่มแค่สิ่งนั้นเท่านั้น\n\nมาตรฐานตั้งแต่ต้นแม้จะมีบริการเดียวก็ให้ผลดี: ใช้ชื่อตัวแปรล็อกเดียวกันและชื่อตัวเมตริกเดียวกันทุกที่ เพื่อให้บริการใหม่เข้ารูปแบบได้ทันที มันยังทำให้แดชบอร์ดนำกลับมาใช้ซ้ำได้ด้วย\n\nวินัยการปล่อยเล็ก ๆ ให้ผลเร็ว:\n\n- เพิ่ม deploy marker (version, environment, commit/build ID) เพื่อให้เห็นว่าปัญหาเริ่มหลัง release ไหม\n- เขียน runbook ย่อสำหรับ top 3 alerts: ความหมาย, การเช็คแรก, และเจ้าของ\n- เก็บแดชบอร์ด “ทองคำ” เดียวที่มีสิ่งจำเป็นสำหรับแต่ละบริการ\n\nถ้าคุณสร้าง backend ด้วย AppMaster จะช่วยวางแผนฟิลด์ observability และเมตริกหลักก่อนการ generate โค้ด เพื่อให้ API ใหม่ทุกตัวมาพร้อมล็อกแบบมีโครงสร้างและสัญญาณสุขภาพโดยดีฟอลต์ ถ้าคุณต้องการจุดเริ่มต้นเดียวสำหรับการสร้าง backend เหล่านั้น AppMaster (appmaster.io) ออกแบบมาเพื่อ generate backend, เว็บ, และแอปมือถือที่พร้อมใช้งานในโปรดักชัน ขณะที่รักษาการ implement ให้สอดคล้องเมื่อความต้องการเปลี่ยน\n\nเลือกการปรับปรุงทีละอย่างตามสิ่งที่ทำให้คุณเจ็บจริง ๆ:\n\n- เพิ่มการจับเวลา query ของฐานข้อมูล (และบันทึก query ที่ช้าที่สุดพร้อมบริบท)\n- ปรับการแจ้งเตือนให้ชี้ผลกระทบต่อผู้ใช้ ไม่ใช่แค่ resource spike\n- ทำให้แดชบอร์ดหน้าเดียวชัดเจนขึ้น (เปลี่ยนชื่อชาร์ต, เพิ่มเกณฑ์, ลบแผงที่ไม่ใช้)\n\nทำวนหลังเหตุการณ์จริงสักไม่กี่ครั้ง แล้วคุณจะได้มอนิเตอร์ที่เหมาะกับแอป CRUD และทราฟฟิก API ของคุณ แทนที่จะใช้เทมเพลตทั่ว ๆ ไปเริ่มทำ observability เมื่อปัญหาในโปรดักชันใช้เวลานานกว่าเวลาในการแก้จริง หากคุณเห็น “500 แบบสุ่ม,” หน้า list ช้าลง หรือ timeout ที่ทำซ้ำไม่ได้ ชุดเล็ก ๆ ของล็อก เมตริก และการแจ้งเตือนที่สอดคล้องกันจะช่วยประหยัดเวลาที่ต้องเดาสถานะระบบได้มาก
Monitoring จะบอกคุณว่า มี ปัญหาอะไรเกิดขึ้น ในขณะที่ observability ช่วยให้คุณเข้าใจ ทำไม มันเกิดขึ้น โดยให้สัญญาณที่มีบริบทและสามารถเชื่อมโยงกันได้ สำหรับ API แบบ CRUD เป้าหมายเชิงปฏิบัติคือการวินิจฉัยให้เร็ว: endpoint ไหน ลูกค้า/tenant ไหน และเวลาส่วนใหญ่อยู่ที่โค้ดแอปหรือฐานข้อมูลกันแน่
เริ่มด้วยล็อกคำขอแบบมีโครงสร้าง เมตริกหลักไม่กี่ตัว และการแจ้งเตือนที่โฟกัสที่ผลกระทบต่อผู้ใช้ การทำ tracing รอได้ในหลายกรณีถ้าคุณบันทึก duration_ms, db_time_ms และมี request_id ที่เสถียรเพื่อค้นหาเหตุการณ์ทุกที่
ใช้ฟิลด์ correlation เดียวเช่น request_id และใส่มันในทุกบรรทัดล็อกของคำขอและทุกการรันงานแบ็กกราวด์ สร้างมันที่ขอบ (edge) และส่งต่อผ่านการเรียกภายใน เพื่อให้ค้นหาล็อกตาม ID นั้นแล้วประกอบเหตุการณ์ช้า/ล้มเหลวได้อย่างรวดเร็ว
บันทึก timestamp, level, service, env, route, method, status, duration_ms และตัวระบุที่ปลอดภัย เช่น tenant_id หรือ account_id หลีกเลี่ยงการบันทึกข้อมูลส่วนบุคคล โทเคน หรือร่างคำขอเต็มโดยดีฟอลต์ หากต้องการรายละเอียดลึกขึ้น ให้บันทึกเฉพาะเมื่อจำเป็นและทำการ redaction
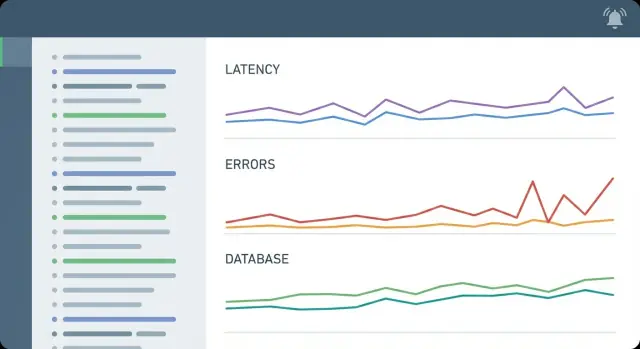
ติดตามอัตราการร้องขอ, อัตรา 5xx, ค่าสถิติ latency (อย่างน้อย p50 และ p95) และความอิ่มตัวพื้นฐาน (CPU/หน่วยความจำ และความกดดันของ worker หรือคิว) ใส่เวลาในฐานข้อมูลและการใช้งาน connection pool ตั้งแต่ต้น เพราะหลาย outage ของ CRUD มักมาจาก contention ในฐานข้อมูลหรือตัวเชื่อมต่อหมด
เพราะค่าเฉลี่ยซ่อนหางที่ผู้ใช้รู้สึกได้ ค่าเฉลี่ยอาจดูปกติขณะที่ p95 แย่มาก ซึ่งทำให้หน้าจอ CRUD รู้สึก “ช้าแบบสุ่ม” โดยไม่มีข้อผิดพลาดชัดเจน จึงต้องเน้น p95/p99 แทนค่าเฉลี่ย
เฝ้าดูอัตราคำถามช้าและเปอร์เซ็นไทล์ query time, การรอล็อก/deadlock, และการใช้งาน connection เทียบกับขีดจำกัดของ pool สัญญาณเหล่านี้บอกได้ว่าฐานข้อมูลเป็นคอขวดหรือไม่ และปัญหาเกิดจากประสิทธิภาพของ query การแข่งขันทรัพยากร หรือตัวเชื่อมต่อหมดภายใต้โหลด
เริ่มจากการแจ้งอาการที่ผู้ใช้รู้สึก: อัตรา 5xx ที่ต่อเนื่อง, p95 latency ที่ต่อเนื่อง, และการลดลงอย่างฉับพลันของคำขอที่สำเร็จ ตั้งค่า alert เหล่านี้ก่อน แล้วเพิ่มการแจ้งเตือนที่บอกสาเหตุเป็นลำดับถัดไป (เช่น การใช้งาน connection ของ DB ใกล้ขีดจำกัด หรือ backlog ของงาน) เพื่อให้สัญญาณที่ต้องเรียกคนทำงานยังเชื่อถือได้และปฏิบัติได้
แนบเมตาดาต้าเวอร์ชัน/บิลด์กับล็อก แดชบอร์ด และการแจ้งเตือน แล้วบันทึกเวลา deploy เพื่อให้เห็นว่าปัญหาเริ่มหลังการปล่อย release หรือไม่ สำหรับ backend ที่สร้างจากเครื่องมือเช่น AppMaster การ regenerate และ redeploy เกิดขึ้นบ่อย การมี deploy marker ช่วยให้เชื่อมปัญหากับ release ได้อย่างรวดเร็ว



ทดลองกับ AppMaster ด้วยแผนฟรี
เมื่อคุณพร้อม คุณสามารถเลือกการสมัครที่เหมาะสมได้


