แอปจองอุปกรณ์: ป้องกันการจองซ้ำและติดตามการคืน
วางแผนแอปจองอุปกรณ์ที่ป้องกันการจองซ้ำ บันทึกการคืนและความเสียหาย พร้อมระงับอุปกรณ์ที่มีปัญหาเพื่อรอการบำรุงรักษา
เรียนรู้การเปลี่ยนสคีมาแบบไม่มี downtime ด้วยมิเกรชันแบบเพิ่ม การเติมข้อมูลย้อนหลังอย่างปลอดภัย และการปล่อยเป็นเฟสที่ช่วยให้ไคลเอนต์เก่ายังคงทำงานได้ระหว่างปล่อย
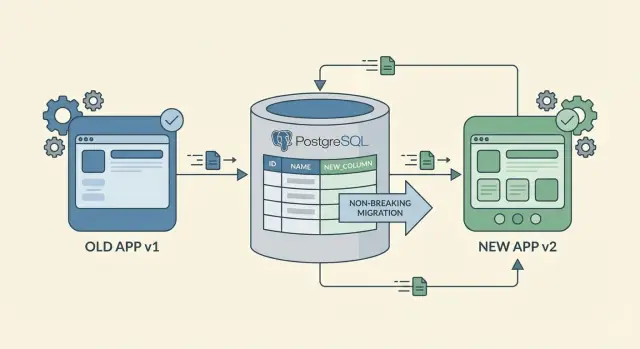
การเปลี่ยนสคีมาแบบไม่มีเวลาหยุดทำงานไม่ได้หมายความว่าไม่มีอะไรเปลี่ยนเลย แต่มันหมายความว่าผู้ใช้ยังทำงานต่อได้ในขณะที่คุณอัปเดตฐานข้อมูลและแอป โดยไม่เกิดความล้มเหลวหรือกระบวนการที่ติดขัด
เวลา "downtime" คือช่วงเวลาที่ระบบหยุดทำงานตามปกติ อาการอาจเป็น 500 errors, การตอบ API ช้า, หน้าจอโหลดแล้วว่างหรือแสดงค่าผิด, งานแบ็กกราวด์ล้ม หรือฐานข้อมูลที่ยอมอ่านแต่บล็อกการเขียนเพราะมิเกรชันยาวกำลังถือล็อกอยู่
การเปลี่ยนสคีมาอาจทำให้ส่วนอื่นของระบบพังได้ไม่ใช่แค่ UI หลัก จุดพังที่พบบ่อยได้แก่ไคลเอนต์ API ที่คาดหวังรูปร่างการตอบแบบเก่า งานแบ็กกราวด์ที่อ่าน/เขียนคอลัมน์เฉพาะ รายงานที่คิวรีโดยตรง ระบบเชื่อมต่อภายนอก และสคริปต์แอดมินภายในที่ "ยังทำงานได้เมื่อวาน"
แอปมือถือเก่าและไคลเอนต์ที่แคชไว้เป็นปัญหาพบบ่อยเพราะคุณไม่สามารถอัปเดตพวกมันได้ทันที บางคนเก็บเวอร์ชันเก่าเป็นสัปดาห์ บางคนมีการเชื่อมต่อเป็นช่วงๆ และ retry คำขอเก่าในภายหลัง แม้แต่ไคลเอนต์เว็บก็อาจทำตัวเป็น "เวอร์ชันเก่า" เมื่อ service worker, CDN หรือ proxy cache ยังคงเก็บโค้ดหรือสมมติฐานที่ล้าสมัย
เป้าหมายที่แท้จริงไม่ใช่ "มิเกรชันครั้งเดียวให้เสร็จเร็ว" แต่เป็นลำดับของก้าวเล็กๆ ที่แต่ละก้าวทำงานได้ด้วยตัวเอง แม้ว่าจะมีไคลเอนต์คนละเวอร์ชันอยู่พร้อมกัน
คำนิยามเชิงปฏิบัติ: คุณควรสามารถดีพลอยโค้ดใหม่และสคีมาใหม่ในลำดับใดก็ได้ แล้วระบบยังทำงานได้
วิธีคิดนี้ช่วยให้คุณหลีกเลี่ยงกับดักคลาสสิก: ดีพลอยแอปใหม่ที่คาดหวังคอลัมน์ใหม่ก่อนที่คอลัมน์จะมีอยู่จริง หรือเพิ่มคอลัมน์ใหม่ที่โค้ดเก่าไม่สามารถจัดการได้ วางแผนการเปลี่ยนให้เป็นแบบเพิ่มก่อน ปล่อยเป็นเฟส แล้วค่อยเอาทางเก่าออกเมื่อมั่นใจว่าไม่มีใครใช้อีกต่อไป
วิถีที่ปลอดภัยที่สุดเพื่อให้ไม่มี downtime คือต้องเพิ่ม ไม่ใช่แทนที่ การเพิ่มคอลัมน์ใหม่หรือเทเบิลใหม่มักไม่ทำให้เกิดปัญหาเพราะโค้ดเดิมยังอ่าน/เขียนรูปร่างเดิมได้
การเปลี่ยนชื่อและการลบนั้นมีความเสี่ยง การเปลี่ยนชื่อเท่ากับ "เพิ่มใหม่ + เอาเก่าออก" และส่วนที่เป็นปัญหาคือการเอาเก่าออก ซึ่งทำให้ไคลเอนต์เก่าล้ม หากต้องการเปลี่ยนชื่อ ให้ทำเป็นสองขั้นตอน: เพิ่มฟิลด์ใหม่ก่อน เก็บฟิลด์เก่าไว้สักพัก แล้วเอาออกเมื่อแน่ใจว่าไม่มีอะไรพึ่งพา
เมื่อเพิ่มคอลัมน์ ให้เริ่มจากฟิลด์ที่เป็น nullable คอลัมน์ที่เป็น nullable ทำให้โค้ดเก่ายังสามารถแทรกแถวโดยไม่รู้จักคอลัมน์ใหม่ได้ ถ้าคุณต้องการในท้ายที่สุดเป็น NOT NULL ให้เพิ่มเป็น nullable ก่อน เติมข้อมูลย้อนหลัง แล้วค่อยบังคับ NOT NULL ภายหลัง ค่า default ก็ช่วยได้ แต่ระวัง: การเพิ่ม default อาจกระทบแถวจำนวนมากในบางฐานข้อมูล และทำให้การเปลี่ยนช้าลงได้
ดัชนี (index) เป็นการเพิ่มที่ "ปลอดภัยแต่ไม่ฟรี" พวกมันทำให้การอ่านเร็วขึ้น แต่การสร้างและรักษา index อาจชะลอการเขียน ให้เพิ่ม index เมื่อคุณแน่ใจว่าคิวรีไหนจะใช้มัน และพิจารณาเพิ่มในช่วงเวลาที่เบากว่าถ้าฐานข้อมูลยุ่ง
ชุดกฎง่ายๆ สำหรับมิเกรชันฐานข้อมูลแบบเพิ่ม:
มองการเปลี่ยนสคีมาแบบไม่มี downtime เป็นการ rollout ไม่ใช่การดีพลอยครั้งเดียว เป้าหมายคือปล่อยให้เวอร์ชันเก่าและใหม่ทำงานร่วมกันได้ในขณะที่ฐานข้อมูลย้ายไปยังรูปร่างใหม่อย่างค่อยเป็นค่อยไป
ลำดับปฏิบัติได้จริง:
ตัวอย่าง: คุณเพิ่ม full_name แต่ไคลเอนต์เก่ายังคงส่ง first_name และ last_name ในช่วงหนึ่ง backend สามารถสร้าง full_name ขณะเขียน เติมข้อมูลผู้ใช้เก่า แล้วค่อยอ่าน full_name เป็นค่าเริ่มต้น แต่ยังรองรับ payload เก่า จนกว่า adoption ชัดเจนแล้วจึงลบฟิลด์เก่า
Backfill คือการเติมคอลัมน์หรือเทเบิลใหม่ให้กับแถวที่มีอยู่ มักเป็นส่วนที่เสี่ยงที่สุดเพราะอาจสร้างโหลดหนัก ล็อกยาว และพฤติกรรม "กึ่งมิเกรต" ที่ทำให้สับสน
เริ่มจากการเลือกวิธีรัน backfill สำหรับ dataset เล็ก run แบบแมนนวลตาม runbook ก็พอ แต่สำหรับ dataset ใหญ่ ควรใช้ background worker หรือ scheduled task ที่รันซ้ำได้และหยุดปลอดภัย
แบ่งงานเป็นแบตช์เพื่อควบคุมแรงกดบนฐานข้อมูล อย่าอัปเดตล้านแถวในทรานแซกชันเดียว ตั้งขนาดชิ้นงานที่คาดการณ์ได้และพักสั้นๆ ระหว่างแบตช์เพื่อให้ทราฟิกผู้ใช้ปกติราบรื่น
รูปแบบปฏิบัติได้จริง:
ทำให้ job รันซ้ำได้โดยไม่พัง เก็บตัวชี้ความคืบหน้าในตารางเฉพาะ และออกแบบให้การรันซ้ำไม่ทำให้ข้อมูลเสียหาย การอัปเดตแบบ idempotent (เช่น update where new_field IS NULL) จะช่วยได้มาก
ตรวจสอบขณะทำงาน ติดตามจำนวนแถวที่ยังขาดค่า และเพิ่มการตรวจสอบความสมเหตุสมผล เช่น ยอดเงินไม่เป็นลบ, timestamp อยู่ในช่วงที่คาดไว้, สถานะอยู่ในชุดที่อนุญาต ตัวอย่างจริงๆ ให้สุ่มตรวจดูแถวบางส่วน
ตัดสินใจพฤติกรรมแอปในขณะที่ backfill ยังไม่เสร็จ ทางเลือกปลอดภัยคือ fallback reads: ถ้าฟิลด์ใหม่เป็น null ให้คำนวณหรืออ่านค่าจากช่องทางเก่า เช่น ถ้าคุณเพิ่ม preferred_language จนกว่าจะเติมเสร็จ API อาจคืนค่าภาษาจากการตั้งค่า profile เมื่อตัวใหม่ว่าง แล้วค่อยเริ่มบังคับหลังเติมเสร็จ
เมื่อคุณปล่อยการเปลี่ยนสคีมา คุณไม่คุมทุกไคลเอนต์เสมอ ผู้ใช้เว็บมักอัปเดตเร็ว ในขณะที่แอปมือถือเก่าอาจอยู่เป็นสัปดาห์ นั่นคือสาเหตุที่ API ที่เข้ากันได้ย้อนหลังสำคัญแม้มิเกรชันฐานข้อมูลจะปลอดภัยแล้วก็ตาม
ปฏิบัติต่อข้อมูลใหม่เป็น optional ก่อน เพิ่มฟิลด์ใหม่ในคำขอและการตอบ แต่ไม่บังคับตั้งแต่วันแรก ถ้าไคลเอนต์เก่าไม่ส่งฟิลด์ใหม่ เซิร์ฟเวอร์ควรรับคำขอและทำงานเหมือนเมื่อวาน
หลีกเลี่ยงการเปลี่ยนความหมายของฟิลด์เดิม การเปลี่ยนชื่ออาจโอเคถ้าคุณยังคงให้ชื่อเก่าทำงานต่อ การเอาฟิลด์เดิมมาใช้ความหมายใหม่คือจุดที่เกิดปัญหาได้ง่าย
ค่า default ฝั่งเซิร์ฟเวอร์คือเน็ตนิทรรศน์ความปลอดภัย เมื่อเพิ่มคอลัมน์ใหม่เช่น preferred_language ให้เซ็ตค่าเริ่มต้นฝั่งเซิร์ฟเวอร์เมื่อขาดหาย การตอบ API อาจรวมฟิลด์ใหม่และไคลเอนต์เก่าสามารถละเลยมันได้
กฎเข้ากันได้ที่ป้องกันการล่มส่วนใหญ่:
ตัวอย่าง: คุณเพิ่ม company_size ใน flow ลงทะเบียน backend สามารถเซ็ตค่า default เป็น "unknown" เมื่อฟิลด์ขาด ไคลเอนต์ใหม่ส่งค่าจริง ไคลเอนต์เก่าทำงานต่อได้ แดชบอร์ดยังอ่านได้
ถ้าแพลตฟอร์มของคุณ regenerate แอป คุณจะได้การสร้างโค้ดและคอนฟิกใหม่ที่สะอาด การนี้ช่วยกับการเปลี่ยนสคีมาแบบไม่มี downtime เพราะคุณสามารถทำก้าวเล็กๆ เพิ่มและดีพลอยบ่อยๆ แทนการค้างแพตช์นานๆ
กุญแจคือต้นทางความจริงแหล่งเดียว (one source of truth) ถ้าสคีมาเปลี่ยนที่ที่หนึ่งและตรรกะธุรกิจเปลี่ยนที่อีกที่ ความแตกต่างจะเกิดเร็ว กำหนดที่เดียวว่าเป็นที่นิยามการเปลี่ยน และจัดการส่วนอื่นเป็น output ที่ถูกสร้าง
การตั้งชื่อตรงไปตรงมาช่วยลดอุบัติเหตุในช่วง rollout ถ้าคุณเพิ่มฟิลด์ใหม่ ให้ตั้งชื่อที่ชัดเจนว่าอันไหนปลอดภัยสำหรับไคลเอนต์เก่าและอันไหนเป็นทางใหม่ ตัวอย่างเช่น ตั้งคอลัมน์ใหม่เป็น status_v2 ปลอดภัยกว่าตั้งเป็น status_new เพราะยังมีความหมายในระยะยาว
แม้การเปลี่ยนจะเป็นแบบเพิ่ม การ rebuild อาจเปิดเผย coupling ที่ซ่อนอยู่ หลังการ regenerate และดีพลอยทุกครั้ง ให้ตรวจสอบ flow สำคัญบางอย่าง:
วางแผนมิเกรชันก่อนแก้ไขใน editor: เพิ่มฟิลด์ใหม่, ดีพลอยรองรับทั้งสองฟิลด์, เติมข้อมูลย้อนหลัง, สลับการอ่าน, แล้วเก็บทางเก่าออกทีหลัง ลำดับนี้ช่วยให้สคีมา ตรรกะ และโค้ดที่ regenerate เคลื่อนไปด้วยกัน ทำให้การเปลี่ยนเล็ก ทบทวนได้ และย้อนกลับได้
การล่มส่วนใหญ่ตอนมิเกรชันแบบไม่มี downtime ไม่ได้เกิดจากงานฐานข้อมูลหนัก แต่มาจากการเปลี่ยนสัญญาระหว่างฐานข้อมูล API และไคลเอนต์ในลำดับที่ผิด
กับดักที่พบบ่อยและการตัดสินใจที่ปลอดภัยกว่า:
ถ้าคุณ regenerate แอป มักจะอยาก "ทำความสะอาด" ชื่อและ constraint ในครั้งเดียว ให้ต้านแรงกระตุ้นนั้นไว้ การล้างทำความสะอาดควรเป็นก้าวสุดท้าย ไม่ใช่ก้าวแรก
กฎที่ดี: ถ้าการเปลี่ยนไม่สามารถ rollback และ roll forward ได้อย่างปลอดภัย แสดงว่าไม่พร้อมลง production
ความสำเร็จของการเปลี่ยนสคีมาแบบไม่มี downtime ขึ้นกับสองอย่าง: สิ่งที่คุณมอนิเตอร์ และความเร็วที่คุณหยุดได้
ติดตามสัญญาณที่สะท้อนผลกระทบต่อผู้ใช้จริง ไม่ใช่แค่ "การดีพลอยเสร็จ" เช่น:
ถ้าคุณทำ dual writes ให้เพิ่ม logging ชั่วคราวเพื่อเปรียบเทียบทั้งสองค่า เก็บเฉพาะเมื่อค่าต่างกัน รวม ID ระเบียนและรหัสเหตุผลสั้นๆ และ sample ถ้าปริมาณมาก ตั้งเตือนให้ลบ logging นี้หลังการมิเกรชันเพื่อไม่ให้กลายเป็นเสียงรบกวนถาวร
Rollback ต้องเป็นจริงจัง ในความเป็นจริงมักไม่ rollback สคีมา แต่ rollback โค้ดและเก็บสคีมาแบบเพิ่มไว้
Runbook การ rollback ที่ปฏิบัติได้จริง:
สำหรับ backfill ให้มีสวิตช์หยุดที่ปิดได้ในไม่กี่วินาที (feature flag, ค่าคอนฟิก, หยุด job) และสื่อสารเฟสล่วงหน้า: เมื่อ dual writes เริ่ม, เมื่อ backfill รัน, เมื่อสลับการอ่าน และนิยามว่า "หยุด" คืออะไร เพื่อให้ไม่มีใคร improvises ในภาวะกดดัน
ก่อนจะปล่อยการเปลี่ยนสคีมา หยุดสักครู่แล้วตรวจเช็คลิสต์นี้ มักจับสมมติฐานเล็กๆ ที่กลายเป็นการล่มเมื่อมีไคลเอนต์หลายเวอร์ชัน
ถ้าคุณใช้แพลตฟอร์มที่ regenerate ให้เพิ่มเช็คลิสต์อีกข้อ: สร้างและดีพลอยบิลด์ที่มาจากโมเดลที่คุณกำลังมิเกรต แล้วยืนยันว่า API และตรรกะที่ generate ยังคงทนต่อเรคอร์ดเก่า ความล้มเหลวที่พบบ่อยคือคิดว่าสคีมาใหม่เท่ากับตรรกะใหม่ที่เป็น required โดยทันที
เขียนสองการกระทำด่วนที่คุณจะทำถ้าพบปัญหาหลังดีพลอย: จะมอนิเตอร์อะไร (errors, timeouts, ความคืบหน้าการ backfill) และจะย้อนกลับอะไรก่อน (ปิดฟีเจอร์แฟล็ก, หยุด backfill, revert release) เพื่อให้จาก "เราจะตอบเร็ว" เป็นแผนที่ใช้งานได้จริง
คุณมีแอปสั่งของ ต้องการฟิลด์ใหม่ delivery_window และมันจะเป็น required สำหรับกฎธุรกิจใหม่ ปัญหาคือเวอร์ชัน iOS และ Android เก่ายังคงใช้งาน และจะไม่ส่งฟิลด์นี้เป็นระยะเวลา วันหรือสัปดาห์ ถ้าคุณทำให้ฐานข้อมูลบังคับฟิลด์นี้ทันที ไคลเอนต์เหล่านั้นจะเริ่มล้มเหลว
เส้นทางปลอดภัย:
delivery_window สำหรับแถวเก่าโดยใช้กฎ (อนุมานจากวิธีการจัดส่ง หรือค่า default เป็น "anytime" จนกว่าลูกค้าจะแก้ไข)delivery_window ก่อน แต่ fallback ไปยังค่าที่อนุมานไว้เมื่อยังว่างประสบการณ์ผู้ใช้ในแต่ละเฟสคงที่ (นั่นคือเป้าหมาย):
เกตมอนิเตอร์ง่ายๆ สำหรับแต่ละขั้น: ติดตามสัดส่วนของคำสั่งใหม่ที่ delivery_window ไม่เป็น null เมื่อตัวเลขนี้คงที่สูง และ validation error เกี่ยวกับ "ขาดฟิลด์" อยู่ใกล้ศูนย์ มักปลอดภัยที่จะไปจาก backfill เป็นการบังคับ constraint
การ rollout ระมัดระวังครั้งเดียวไม่ใช่กลยุทธ์ ปฏิบัติต่อการเปลี่ยนสคีมาเป็นกิจวัตร: ขั้นตอนเหมือนเดิม การตั้งชื่อเหมือนเดิม การเซ็นรับเหมือนเดิม แล้วการเปลี่ยนครั้งต่อไปจะยังคงน่าเบื่อแม้ระบบยุ่งและไคลเอนต์ต่างเวอร์ชัน
เก็บ playbook ให้สั้น ตอบคำถาม: เราเพิ่มอะไร, จะปล่อยอย่างปลอดภัยอย่างไร, และจะเอาอะไรเก่าออกเมื่อไร
เทมเพลตเรียบง่าย:
เริ่มจากตารางความเสี่ยงต่ำ (สถานะใหม่ที่เป็น optional หรือฟิลด์โน้ต) และรัน playbook ทั้งหมดตั้งแต่ต้นถึงท้าย: การเปลี่ยนแบบเพิ่ม, backfill, ไคลเอนต์หลายเวอร์ชัน, แล้ว cleanup การฝึกแบบนี้จะเปิดช่องโหว่ในมอนิเตอร์ การแบ่งแบตช์ และการสื่อสารก่อนคุณจะทำ redesign ใหญ่
นิสัยหนึ่งที่ป้องกันความยุ่งเหยิงระยะยาว: ติดตามรายการ "ต้องลบทีหลัง" เป็นงานจริง เมื่อคุณเพิ่มคอลัมน์ชั่วคราว โค้ดรองรับความเข้ากัน หรือ dual-write logic ให้สร้าง ticket cleanup ทันที พร้อมเจ้าของและวันที่ เก็บ "หนี้ความเข้ากัน" ไว้ในเอกสาร release เพื่อให้มองเห็นได้
ถ้าคุณสร้างด้วย AppMaster, คุณสามารถถือว่า regeneration เป็นส่วนหนึ่งของกระบวนการความปลอดภัย: model สคีมาแบบเพิ่ม, อัปเดตตรรกะธุรกิจให้รองรับทั้งฟิลด์เก่าและใหม่ระหว่างการเปลี่ยน, แล้ว regenerate เพื่อให้โค้ดต้นฉบับสะอาดเมื่อความต้องการเปลี่ยน หากต้องการดูว่าเวิร์กโฟลว์นี้เข้ากับการตั้งค่า no-code ที่ยังผลิตซอร์สโค้ดจริงได้อย่างไร AppMaster (appmaster.io) ถูกออกแบบให้สอดคล้องกับสไตล์การปล่อยแบบซ้ำๆ และเป็นขั้นตอน
เป้าหมายไม่ใช่ความสมบูรณ์แบบ แต่เป็นการทำซ้ำได้: ทุกมิเกรชันมีแผน, ตัวชี้วัด, และทางออกชัดเจน
Zero-downtime หมายความว่าผู้ใช้งานยังสามารถทำงานได้ปกติในขณะที่คุณเปลี่ยนสคีมาและดีพลอยโค้ด นั่นรวมถึงการหลีกเลี่ยงการล่มชัดเจน แต่ยังรวมถึงการหลีกเลี่ยงปัญหาเงียบๆ เช่น หน้าจอว่าง ค่าผิดพลาด งานแบ็กกราวด์ล้ม หรือตัวเขียนถูกบล็อกด้วยล็อกยาวๆ
เพราะหลายส่วนของระบบขึ้นกับรูปร่างของฐานข้อมูล ไม่ใช่แค่ UI หลัก งานแบ็กกราวด์ รายงาน สคริปต์แอดมิน การเชื่อมต่อภายนอก และแอปมือถือเวอร์ชันเก่า อาจยังคงส่งหรือคาดหวังฟิลด์เก่าๆ นานหลังจากที่คุณดีพลอยโค้ดใหม่ไปแล้ว
เวอร์ชันแอปมือถือเก่ามักอยู่ได้นานเป็นสัปดาห์ และบางไคลเอนต์อาจ retry คำขอเก่าเมื่อเครือข่ายกลับมา API ของคุณจึงต้องรับได้ทั้ง payload เก่าและใหม่ในช่วงเวลาหนึ่ง จึงจะไม่เกิดปัญหาเมื่อเวอร์ชันต่างกัน coexist กัน
การเปลี่ยนแบบเพิ่ม (additive) มักปลอดภัยที่สุด เพราะสคีมาเดิมยังอยู่ ฟีเจอร์ใหม่ที่เพิ่มตารางหรือคอลัมน์ไม่ค่อยทำให้โค้ดเดิมพัง การเปลี่ยนชื่อหรือการลบมีความเสี่ยงเพราะจะเอาสิ่งที่ไคลเอนต์เก่ายังอ่านหรือเขียนอยู่ออกไป
เพิ่มคอลัมน์เป็น nullable ก่อน เพื่อที่โค้ดเก่าจะยังแทรกแถวได้เหมือนเดิม หลังจากนั้นเติมข้อมูลย้อนหลังเป็นชุดๆ แล้วเมื่อครอบคลุมดีและการเขียนใหม่สม่ำเสมอ จึงค่อยบังคับ NOT NULL เป็นขั้นตอนสุดท้าย
จัดการเป็น rollout: เพิ่มสคีมาแบบเข้ากันได้, ดีพลอยโค้ดที่รองรับสองแบบ, เติมข้อมูลย้อนหลังเป็นแบตช์เล็กๆ, สลับการอ่านโดยมี fallback, แล้วลบฟิลด์เก่าเมื่อแน่ใจว่าไม่มีใครใช้แล้ว ทุกขั้นตอนต้องทำงานได้เองได้แม้มีไคลเอนต์หลายเวอร์ชันอยู่พร้อมกัน
รันเป็นแบตช์เล็กๆ ในทรานแซกชันสั้นๆ อย่าอัปเดตรายล้านแถวในครั้งเดียว ทำให้ job restartable เก็บตัวชี้ความคืบหน้า เช่น ID ล่าสุด อัปเดตเฉพาะแถวที่ยังว่าง (new_field IS NULL) และมีการลองตรวจสอบตัวอย่างข้อมูลจริงเป็นระยะ
ทำให้ฟิลด์ใหม่เป็น optional ก่อน และเซ็ต default ฝั่งเซิร์ฟเวอร์เมื่อฟิลด์ขาดหาย รักษาพฤติกรรมเก่าไว้ อย่าเปลี่ยนความหมายของฟิลด์เดิม และทดสอบทั้งสองเส้นทาง: “ไคลเอนต์ใหม่ส่งมา” และ “ไคลเอนต์เก่าไม่ส่ง”
โดยปกติจะย้อนกลับโค้ด ไม่ยกเลิกสคีมา เพิ่มคอลัมน์/ตารางไว้ก่อน เลิกใช้การอ่านใหม่ก่อน แล้วค่อยหยุดเขียนใหม่ หยุด backfill จนสัญญาณเมตริกนิ่ง เพื่อให้กู้กลับได้โดยไม่เสียข้อมูล
ดูสัญญาณที่มีผลต่อผู้ใช้จริง เช่น อัตราข้อผิดพลาดของ API (4xx/5xx), คำสั่งช้า (p95/p99), ความหน่วงการเขียน, ความลึกของคิวงาน, และการเพิ่มขึ้นของ CPU/IO ของฐานข้อมูล รอจนเมตริกนิ่งและเปอร์เซ็นต์การครอบคลุมฟิลด์ใหม่สูงก่อนจะไปขั้นต่อไป



ทดลองกับ AppMaster ด้วยแผนฟรี
เมื่อคุณพร้อม คุณสามารถเลือกการสมัครที่เหมาะสมได้


