แอปจองอุปกรณ์: ป้องกันการจองซ้ำและติดตามการคืน
วางแผนแอปจองอุปกรณ์ที่ป้องกันการจองซ้ำ บันทึกการคืนและความเสียหาย พร้อมระงับอุปกรณ์ที่มีปัญหาเพื่อรอการบำรุงรักษา
การจัดทำดัชนีสำหรับแผงผู้ดูแล: ปรับตัวกรองที่ผู้ใช้คลิกบ่อยที่สุดก่อน—สถานะ ผู้รับมอบหมาย ช่วงวันที่ และการค้นหาข้อความ ตามรูปแบบคำสั่งจริง
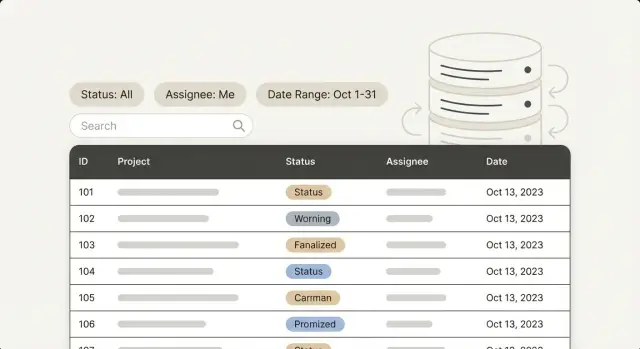
status = 'open', assignee_id = 42\n- ตัวกรองช่วง: created_at ระหว่างสองวันที่\n- การเรียงและแบ่งหน้า: ORDER BY created_at DESC และดึงหน้า 2\n- การค้นหาข้อความ: การจับคู่แบบแม่นยำ (หมายเลขคำสั่ง), การจับคู่แบบ prefix (อีเมลขึ้นต้นด้วย), หรือการค้นหาแบบ contains\n\nจดรูปแบบสำหรับแต่ละหน้าจอที่สำคัญ รวม WHERE, ORDER BY และการแบ่งหน้า สองคำสั่งที่ดูคล้ายกันใน UI อาจทำงานต่างกันมากในฐานข้อมูล\n\n### เลือกชุดเล็กๆ ก่อน\n\nเริ่มจากเป้าหมายลำดับหนึ่ง: คำสั่งรายการเริ่มต้นที่โหลดก่อน จากนั้นเลือกอีก 2–3 คำสั่งที่รันบ่อย นั่นมักพอที่จะตัดความล่าช้าหลักๆ โดยไม่เปลี่ยนฐานข้อมูลให้กลายเป็นพิพิธภัณฑ์ดัชนี\n\nตัวอย่าง: ทีมซัพพอร์ตเปิดรายการ Tickets กรองเป็น status = 'open' เรียงตามใหม่สุด และมีตัวกรองผู้รับมอบหมายและช่วงวันที่เป็นทางเลือก ปรับแต่งคอมโบนี้ก่อน เมื่อเร็วขึ้นแล้ว ค่อยไปหน้าต่อไปตามการใช้งาน\n\n## การจัดทำดัชนีตัวกรองสถานะโดยไม่ทำเกินความจำเป็น\n\nสถานะเป็นตัวกรองที่ผู้คนมักเพิ่มเป็นอันดับต้นๆ และเป็นหนึ่งในสิ่งที่ง่ายที่สุดที่จะทำดัชนีแต่ได้ประโยชน์น้อย\n\nฟิลด์สถานะส่วนใหญ่มีความหลากค่าน้อย: มีไม่กี่ค่า (open, pending, closed) ดัชนีช่วยได้เมื่อมันสามารถแยกผลลัพธ์ให้เป็นชิ้นเล็กๆ ได้ หาก 80%–95% ของแถวมีสถานะเดียวกัน ดัชนี status เพียงอย่างเดียวมักจะไม่เปลี่ยนมาก ฐานข้อมูลยังต้องอ่านชิ้นส่วนข้อมูลขนาดใหญ่และดัชนีเพิ่มภาระ\n\nคุณมักรู้สึกถึงประโยชน์เมื่อ:\n\n- สถานะหนึ่งหายาก (เช่น escalated)\n- สถานะถูกรวมกับเงื่อนไขอื่นที่ทำให้ชุดผลลัพธ์เล็กลง\n- สถานะบวกการเรียงลำดับตรงกับมุมมองรายการที่ใช้บ่อย\n\nรูปแบบที่มักคุ้มค่าก่อนคือการจัดดัชนีตัวกรองพร้อมการเรียง เช่น status + updated_at หรือการรวม status + assignee_id\n\nPartial index เป็นทางสายกลางที่ดีเมื่อสถานะเดียวถูกใช้เป็นหลัก ถ้า "open" เป็นมุมมองหลัก ให้ทำดัชนีเฉพาะแถว open ดัชนีจะเล็กลงและค่าเขียนจะต่ำลง\n\n```sql-- PostgreSQL example: index only open rows, optimized for newest-first lists CREATE INDEX CONCURRENTLY tickets_open_updated_idx ON tickets (updated_at DESC) WHERE status = 'open';
\nการทดสอบจริง: รันคำสั่งแอดมินที่ช้าพร้อมและไม่มีตัวกรองสถานะ หากมันช้าในทั้งสองกรณี ดัชนีเฉพาะ `status` มักไม่ช่วย ให้โฟกัสที่การเรียงและเงื่อนไขที่สองที่ทำให้รายการแคบจริงๆ\n\n## การกรองผู้รับมอบหมาย: ดัชนีแบบ equality และคอมโบที่พบบ่อย\n\nในแผงผู้ดูแลส่วนใหญ่ ผู้รับมอบหมายคือ user ID ที่เก็บบนเรคคอร์ด: foreign key เช่น `assignee_id` นั่นเป็นตัวกรองแบบ equality คลาสสิก และมักเป็นกำไรที่รวดเร็วด้วยดัชนีง่ายๆ\n\nผู้รับมอบหมายยังปรากฏพร้อมตัวกรองอื่นเพราะมันตรงกับวิธีการทำงาน ทีมผู้นำซัพพอร์ตอาจกรองเป็น "มอบหมายให้ Alex" แล้วแคบลงเป็น "Open" เพื่อดูสิ่งที่ยังต้องระวัง ถ้ามุมมองนี้ช้า มักต้องมากกว่าดัชนีคอลัมน์เดียว\n\nจุดเริ่มต้นที่ดีคือดัชนีประกอบที่ตรงกับคอมโบตัวกรองทั่วไป:\n\n- `(assignee_id, status)` สำหรับ "งานของฉันที่เปิดอยู่"\n- `(assignee_id, status, updated_at)` หากรายการถูกเรียงตามกิจกรรมล่าสุดด้วย\n\nลำดับสำคัญในดัชนีประกอบ ให้ใส่ตัวกรองแบบ equality ก่อน (มักเป็น `assignee_id` แล้วตามด้วย `status`) และใส่คอลัมน์เรียงหรือช่วงท้ายสุด (`updated_at`) เพื่อให้ฐานข้อมูลใช้ได้อย่างมีประสิทธิภาพ\n\nรายการที่ยังไม่ถูกมอบหมายเป็นกับดักทั่วไป หลายระบบแทนค่า "unassigned" ด้วย `NULL` ใน `assignee_id` และผู้จัดการมักกรองหา ตามฐานข้อมูลและรูปแบบคำสั่ง ค่า `NULL` อาจเปลี่ยนแผนคิวให้ดัชนีที่ดีสำหรับรายการที่มอบหมายแล้วแต่ใช้ไม่ได้สำหรับ unassigned\n\nถ้า unassigned เป็นเวิร์กโฟลว์สำคัญ ให้เลือกแนวทางเดียวและทดสอบมัน:\n\n- คงให้ `assignee_id` nullable แต่ทดสอบ `WHERE assignee_id IS NULL` และจัดทำดัชนีเมื่อจำเป็น\n- ใช้ค่าพิเศษ (เช่นผู้ใช้ "Unassigned") เฉพาะเมื่อมันเหมาะกับโมเดลข้อมูล\n- เพิ่ม partial index สำหรับแถวที่ยังไม่มอบหมายถ้าฐานข้อมูลรองรับ\n\nถ้าคุณสร้างแผงผู้ดูแลใน AppMaster จะช่วยให้บันทึกตัวกรองและการเรียงลำดับที่ทีมใช้บ่อย แล้วจำลองรูปแบบเหล่านั้นด้วยดัชนีจำนวนน้อยที่เหมาะสม แทนการทำดัชนีทุกฟิลด์ที่มีให้เลือก\n\n## ช่วงวันที่: ดัชนีที่ตรงกับวิธีที่ผู้คนกรอง\n\nตัวกรองวันที่มักปรากฏเป็นพรีเซ็ตอย่าง "7 วันที่ผ่านมา" หรือ "30 วันที่ผ่านมา" พร้อมตัวเลือกกำหนดเองด้วยวันเริ่มต้นและสิ้นสุด ดูเรียบง่ายแต่สามารถบังคับให้ฐานข้อมูลทำงานต่างกันมากบนตารางขนาดใหญ่\n\nก่อนอื่น ให้ชัดเจนว่าผู้ใช้หมายถึงคอลัมน์ timestamp ไหน ใช้:\n\n- `created_at` สำหรับมุมมอง "รายการใหม่"\n- `updated_at` สำหรับมุมมอง "เปลี่ยนแปลงล่าสุด"\n\nใส่ดัชนี btree ปกติบนคอลัมน์นั้น ถ้าไม่มี ทุกคลิก "30 วันที่ผ่านมา" อาจกลายเป็นการสแกนทั้งตาราง\n\nพรีเซ็ตช่วงมักเป็น `created_at >= now() - interval '30 days'` นั่นคือเงื่อนไขช่วง และดัชนี `created_at` ใช้ได้อย่างมีประสิทธิภาพ ถ้า UI ยังเรียงจากใหม่สุด การจับทิศทางการเรียง (`created_at DESC`) ในดัชนีสามารถช่วยในรายการที่ใช้บ่อยมาก\n\nเมื่อช่วงวันที่รวมกับตัวกรองอื่น (status, assignee) ให้เลือกเฉพาะเมื่อคอมโบเป็นเรื่องปกติ ดัชนีประกอบดีเมื่อคอมโบใช้บ่อย มิฉะนั้นเพิ่มค่าเขียนโดยไม่คุ้มค่า\n\nกฎปฏิบัติ:\n\n- ถ้ามุมมองส่วนใหญ่กรองด้วย status แล้วตามด้วยวันที่ `(status, created_at)` ช่วยได้\n- ถ้า status เป็นทางเลือกแต่วันที่อยู่เสมอ ให้เก็บดัชนี `created_at` แบบเรียบง่ายและหลีกเลี่ยงการประกอบมากเกินไป\n- อย่าสร้างทุกคอมโบ ดัชนีแต่ละอันเพิ่มพื้นที่และทำให้การเขียนช้าลง\n\nโซนเวลาและขอบเขตวันที่ก่อให้เกิดบั๊ก "ขาดหาย" มาก ถ้าผู้ใช้เลือกวันที่ (ไม่ใช่เวลา) ตัดสินใจว่าจะตีความวันสิ้นสุดอย่างไร แบบที่ปลอดภัยคือจุดเริ่มต้นรวมและสิ้นสุดไม่รวม: `created_at >= start` และ `created_at < end_next_day` เก็บ timestamp เป็น UTC และแปลงอินพุตผู้ใช้เป็น UTC ก่อนคิวรี\n\nตัวอย่าง: ผู้ดูแลเลือก 10 ม.ค. ถึง 12 ม.ค. และคาดหวังเห็นรายการตลอดทั้ง 12 ม.ค. ถ้าคุณใช้ `<= '2026-01-12 00:00'` คุณจะตัดรายการส่วนใหญ่ของ 12 ม.ค. ดัชนียังโอเค แต่ตรรกะขอบเขตผิด\n\n## ฟิลด์ข้อความ: การค้นหาแบบแม่นยำ vs การค้นหาแบบ contains\n\nการค้นหาข้อความเป็นเหตุผลที่แผงผู้ดูแลหลายแห่งช้า เพราะผู้คนคาดหวังให้กล่องเดียวหาทุกอย่าง การแก้ตัวแรกคือแยกสองความต้องการ: การจับคู่แม่นยำ (เร็วและคาดเดาได้) กับการค้นหาแบบ contains (ยืดหยุ่นแต่หนักกว่า)\n\n**การจับคู่แม่นยำ** ได้แก่ Order ID, หมายเลขตั๋ว, อีเมล, เบอร์โทรศัพท์ หรือ reference ภายนอก เหล่านี้เหมาะกับดัชนีฐานข้อมูลปกติ หากผู้ดูแลมักวาง ID หรืออีเมล ดัชนีและการคิวรีแบบ equality ทำให้ทันใจ\n\n**การค้นหาแบบ contains** คือเมื่อใครสักคนพิมพ์ชิ้นคำเช่น "refund" หรือ "john" และคาดว่าจะเจอในชื่อ บันทึก และคำอธิบาย มักถูกทำเป็น `LIKE %term%` ตัว wildcard นำหน้าทำให้ดัชนี B-tree ปกติไม่สามารถช่วย จึงต้องสแกนแถวจำนวนมาก\n\nวิธีปฏิบัติที่เป็นรูปธรรมเพื่อสร้างการค้นหาโดยไม่โหลดระบบเกินไป:\n\n- ทำให้การค้นหาแบบแม่นยำเป็นทางเลือกหลัก (ID, อีเมล, username) และแสดงอย่างชัดเจน\n- สำหรับการค้นหาแบบ "ขึ้นต้น" (`term%`) ดัชนีปกติช่วยได้และมักพอสำหรับชื่อ\n- เพิ่มการค้นหาแบบ contains เมื่อมีบันทึกหรือร้องเรียนแสดงว่าจำเป็น\n- เมื่อเพิ่ม ให้ใช้เครื่องมือที่เหมาะสม (PostgreSQL full-text หรือ trigram) แทนหวังว่าดัชนีปกติจะแก้ `LIKE %term%`\n\nกฎการป้อนข้อมูลสำคัญกว่าที่หลายทีมคิด มันลดโหลดและทำให้ผลลัพธ์คงที่:\n\n- กำหนดความยาวขั้นต่ำสำหรับการค้นหาแบบ contains (เช่น 3+ อักขระ)\n- ทำให้ไม่สนใจตัวพิมพ์หรือใช้การเปรียบเทียบไม่สนใจเคสอย่างสม่ำเสมอ\n- ตัดช่องว่างข้างหน้าและข้างหลังและย่อช่องว่างซ้ำ\n- ให้ถืออีเมลและ ID เป็นการค้นหาแบบแม่นยำเป็นค่าเริ่มต้น แม้จะป้อนในกล่องค้นหาทั่วไป\n- ถ้าคำค้นกว้างเกินไป ให้แจ้งผู้ใช้ให้ละเอียดขึ้นแทนรันคิวรีขนาดใหญ่\n\nตัวอย่างเล็กๆ: ผู้จัดการซัพพอร์ตค้นหา "ann" ถ้าระบบรัน `LIKE %ann%` ข้ามบันทึก ชื่อ และที่อยู่ มันอาจสแกนพันๆ ระเบียน หากคุณเช็กฟิลด์แม่นยำก่อน (อีเมล หรือ customer ID) แล้วค่อย fallback ไปยังดัชนีข้อความที่ฉลาดเมื่อจำเป็น การค้นหาจะเร็วโดยไม่ทำให้ทุกคำสั่งเป็นการออกกำลังกายหนักหน่วงกับฐานข้อมูล\n\n## เวิร์กโฟลว์ทีละขั้นตอนเพื่อเพิ่มดัชนีอย่างปลอดภัย\n\nดัชนีง่ายจะเพิ่มและง่ายจะเสียดาย วงจรที่ปลอดภัยจะช่วยให้คุณมุ่งที่ตัวกรองที่แอดมินพึ่งพา และหลีกเลี่ยงดัชนี "อาจมีประโยชน์" ที่ทำให้การเขียนช้าลงในภายหลัง\n\nเริ่มจากการใช้งานจริง ดึงคำสั่งยอดนิยมสองแบบ:\n\n- คำสั่งที่รันบ่อยที่สุด\n- คำสั่งที่ช้าที่สุด\n\nสำหรับแผงผู้ดูแล มักเป็นหน้ารายการที่มีตัวกรองและการเรียงลำดับ\n\nถัดไป จับรูปแบบคำสั่งให้ตรงตามที่ฐานข้อมูลเห็น จด `WHERE` และ `ORDER BY` เป๊ะ รวมทิศทางการเรียงและคอมโบที่ใช้บ่อย (เช่น: `status = 'open' AND assignee_id = 42 ORDER BY created_at DESC`) ความต่างเล็กๆ อาจเปลี่ยนดัชนีที่ช่วยได้\n\nใช้ลูปง่ายๆ:\n\n- เลือกคำสั่งช้าหนึ่งรายการและเปลี่ยนดัชนีหนึ่งอย่างเพื่อทดลอง\n- เพิ่มหรือปรับดัชนีหนึ่งรายการ\n- วัดใหม่ด้วยตัวกรองและการเรียงเดิม\n- ตรวจสอบว่า insert/update ช้าลงอย่างเห็นได้ชัดหรือไม่\n- เก็บการเปลี่ยนแปลงเฉพาะเมื่อมันปรับปรุงคำสั่งเป้าหมายอย่างชัดเจน\n\nการแบ่งหน้า (pagination) ต้องตรวจเช็คเป็นพิเศษ การแบ่งหน้าแบบ offset (`OFFSET 20000`) มักช้าขึ้นเมื่อไปลึก แม้จะมีดัชนีก็ตาม ถ้าผู้ใช้มักข้ามไปยังหน้าลึก ให้พิจารณา pagination แบบ cursor (เช่น "แสดงรายการก่อน timestamp/id นี้") เพื่อให้ดัชนีทำงานสม่ำเสมอบนาตารางใหญ่\n\nสุดท้าย เก็บบันทึกเล็กๆ ให้รายการดัชนีเข้าใจง่ายในอีกหลายเดือนข้างหน้า: ชื่อดัชนี ตาราง คอลัมน์ (และลำดับ) และคำสั่งที่มันรองรับ\n\n## ข้อผิดพลาดในการจัดทำดัชนีที่พบบ่อยในแผงผู้ดูแล\n\nวิธีที่เร็วที่สุดที่จะทำให้แผงผู้ดูแลรู้สึกช้าคือการเพิ่มดัชนีโดยไม่ตรวจดูว่าผู้ใช้กรอง เรียง และแบ่งหน้าอย่างไร ดัชนีมีต้นทุนพื้นที่และเพิ่มงานให้กับทุกการ insert และ update\n\n### ข้อผิดพลาดที่พบบ่อยที่สุด\n\nรูปแบบเหล่านี้ก่อปัญหาส่วนใหญ่:\n\n- ทำดัชนีทุกคอลัมน์ "เผื่อไว้"\n- สร้างดัชนีประกอบโดยเรียงคอลัมน์ผิด\n- มองข้ามการเรียงและการแบ่งหน้า\n- คาดหวังว่าดัชนีปกติจะแก้ `LIKE '%term%'` ได้\n- ทิ้งดัชนีเก่าหลังเปลี่ยน UI\n\nสถานการณ์ทั่วไป: ทีมซัพพอร์ตกรองตั๋วโดย Status = Open เรียงตาม updated time และเลื่อนดูผล ถ้าคุณเพิ่มดัชนีเฉพาะบน `status` ฐานข้อมูลอาจยังต้องรวบรวมตั๋วทั้งหมดที่เปิดอยู่แล้วเรียงผล ดัชนีที่ตรงกับตัวกรองและการเรียงพร้อมกันสามารถส่งกลับหน้า 1 ได้เร็ว\n\n### วิธีตรวจจับปัญหาอย่างรวดเร็ว\n\nก่อนและหลังเปลี่ยน UI แอดมิน ให้ทำรีวิวสั้นๆ:\n\n- ระบุตัวกรองยอดนิยมและการเรียงเริ่มต้น แล้วยืนยันว่ามีดัชนีที่ตรงกับรูปแบบ `WHERE + ORDER BY`\n- เช็ก wildcard นำหน้า (`LIKE '%term%'`) และตัดสินใจว่าการค้นหาแบบ contains จำเป็นจริงหรือไม่\n- มองหาดัชนีซ้ำหรือทับซ้อน\n- ติดตามดัชนีที่ไม่ถูกใช้สักพัก แล้วลบออกเมื่อมั่นใจว่าไม่จำเป็น\n\nถ้าคุณสร้างแผงผู้ดูแลใน AppMaster บน PostgreSQL ให้ทำรีวิวนี้เป็นส่วนหนึ่งของการปล่อยหน้าจอใหม่ ดัชนีที่ถูกต้องมักตามมาจากตัวกรองและการเรียงที่ UI ใช้จริง\n\n## การตรวจสอบด่วนและขั้นตอนต่อไป\n\nก่อนเพิ่มดัชนีมากกว่าเดิม ยืนยันว่าดัชนีที่มีอยู่ช่วยคำสั่งที่ผู้ใช้ใช้ทุกวันจริงๆ แผงผู้ดูแลที่ดีควรรู้สึกทันใจบนเส้นทางยอดนิยม ไม่ใช่การค้นหาแบบครั้งเดียว\n\nการตรวจสอบไม่กี่อย่างจับปัญหาได้มาก:\n\n- เปิดคอมโบตัวกรองที่ใช้บ่อยที่สุด (status, assignee, ช่วงวันที่, และการเรียงเริ่มต้น) แล้วยืนยันว่ามันยังเร็วเมื่อโตขึ้น\n- สำหรับแต่ละมุมมองที่ช้า ให้ยืนยันว่าคำสั่งใช้ดัชนีที่ตรงกับทั้ง `WHERE` และ `ORDER BY` ไม่ใช่แค่ชิ้นเดียว\n- เก็บรายการดัชนีให้เล็กพอที่คุณอธิบายหน้าที่ของแต่ละดัชนีได้ในประโยคเดียว\n- ดูการกระทำที่เขียนหนัก (create, update, เปลี่ยนสถานะ) ถ้าพวกนี้ช้าลงหลังการเพิ่มดัชนี คุณอาจมีดัชนีมากเกินไปหรือทับซ้อน\n- ตัดสินใจว่า "ค้นหา" ใน UI ของคุณหมายถึงอะไร: การจับคู่แม่นยำ, prefix, หรือ contains แผนการจัดทำดัชนีต้องตรงกับการตัดสินใจนี้\n\nขั้นตอนปฏิบัติถัดไปคือเขียนเส้นทางทองคำ (golden paths) ของคุณเป็นประโยคง่ายๆ เช่น: "เจ้าหน้าที่ซัพพอร์ตกรองตั๋วที่เปิดอยู่ มอบหมายให้ฉัน ใน 7 วันที่ผ่านมา เรียงจากใหม่สุด" ใช้ประโยคเหล่านี้ออกแบบชุดดัชนีเล็กๆ ที่รองรับพวกมันอย่างชัดเจน\n\nถ้าคุณยังอยู่ในขั้นต้น ช่วยวางแบบข้อมูลและตัวกรองเริ่มต้นก่อนสร้างหน้าจอมากเกินไป กับ AppMaster (appmaster.io) คุณสามารถทำซ้ำมุมมองแอดมินได้เร็ว แล้วเพิ่มดัชนีจำนวนน้อยที่ตรงกับการใช้งานจริงเมื่อเส้นทางร้อนชัดเจน
เริ่มจากคำสั่งที่รันบ่อยที่สุด: มุมมองรายการเริ่มต้นที่ผู้ดูแลเห็นก่อนเป็นอันดับแรก รวมทั้งตัวกรอง 2–3 ตัวที่คลิกบ่อยที่สุด วัดความถี่และความเจ็บปวด (รายการที่ช้าและใช้บ่อยที่สุด) แล้วจัดทำดัชนีเฉพาะสิ่งที่ลดเวลารอได้อย่างชัดเจนบนรูปแบบคำสั่งที่แน่นอนเหล่านั้น
เพราะตัวกรองต่างกันจะบังคับให้ฐานข้อมูลทำงานต่างกัน บางตัวกรองจะแคบลงจนได้ชุดแถวเล็ก ขณะที่ตัวอื่นจะต้องอ่านช่วงข้อมูลกว้างหรือเรียงผลลัพธ์จำนวนมาก ทำให้บางคำสั่งสามารถใช้ดัชนีได้ดี ในขณะที่อีกคำสั่งยังคงต้องสแกนและเรียงข้อมูลจำนวนมาก
ไม่เสมอไป หากแถวส่วนใหญ่มีสถานะเดียวกัน ดัชนีบนคอลัมน์ status เพียงอย่างเดียวมักจะช่วยไม่มากนัก มันได้ประโยชน์มากขึ้นเมื่อสถานะนั้นหายาก หรือเมื่อคุณจับคู่ status กับการเรียงหรือเงื่อนไขอื่นที่ทำให้ชุดผลลัพธ์แคบลงจริงๆ
ใช้ดัชนีประกอบที่สอดคล้องกับพฤติกรรมของผู้ใช้ เช่น กรองด้วย status แล้วเรียงตามกิจกรรมล่าสุด ตัวอย่าง: partial index ใน PostgreSQL ช่วยได้ดีเมื่อสถานะหนึ่งถูกใช้งานเป็นหลัก เพราะจะทำให้ดัชนีเล็กและค่าเขียนต่ำลง
ดัชนีเดี่ยวบน assignee_id มักให้ประโยชน์เร็ว เพราะเป็นตัวกรองแบบเท่ากับ ถ้ามุมมองหลักคือ “งานของฉันที่เปิดอยู่” ดัชนีประกอบที่เริ่มด้วย assignee_id แล้วตามด้วย status (และถ้าจำเป็นคอลัมน์เรียงลำดับ) มักทำงานดีกว่าดัชนีคอลัมน์เดี่ยวหลายอัน
การเก็บค่าเป็น NULL สำหรับไม่ถูกมอบหมายทำให้ WHERE assignee_id IS NULL มีพฤติกรรมต่างจาก WHERE assignee_id = 123 ขึ้นอยู่กับฐานข้อมูล ถ้าแถว Unassigned สำคัญ ให้ทดสอบคิวนี้โดยเฉพาะและเพิ่มกลยุทธ์ดัชนีที่รองรับมัน เช่น partial index สำหรับแถว unassigned หากฐานข้อมูลรองรับ
เพิ่มดัชนี btree บนคอลัมน์ timestamp ที่ผู้ใช้กรองจริง เช่น created_at สำหรับมุมมองรายการใหม่ และ updated_at สำหรับสิ่งที่เปลี่ยนล่าสุด หาก UI เรียงจากใหม่ไปเก่า การจับทิศทางการเรียง (created_at DESC) ในดัชนีอาจช่วยได้ แต่ให้จำกัดดัชนีประกอบเฉพาะคอมโบที่ใช้บ่อยจริงๆ
บั๊กที่ขาดหายมักมาจากขอบเขตเวลาไม่ใช่ดัชนี รูปแบบที่ปลอดภัยคือจุดเริ่มต้นรวมและจุดสิ้นสุดไม่รวม: แปลงวันที่ผู้ใช้เป็น UTC แล้วใช้ >= start และ < end_next_day เพื่อไม่ให้ตัดรายการที่เกิดขึ้นในวันสุดท้ายออกไปโดยไม่ตั้งใจ
เพราะ LIKE %term% ไม่สามารถใช้ดัชนี btree แบบปกติให้กระโดดไปยังการจับคู่ได้ จึงต้องสแกนแถวเป็นจำนวนมาก แยกการค้นหาแบบแม่นยำ (ID, อีเมล, หมายเลขคำสั่ง) เป็นทางเลือกแรก และเมื่อจำเป็นจึงเพิ่มการค้นหาแบบ contains ด้วยเครื่องมือที่เหมาะสม เช่น PostgreSQL full-text หรือ trigram index แทนการหวังให้ดัชนีปกติแก้ LIKE %term%
การเพิ่มดัชนีมากเกินไปเพิ่มพื้นที่จัดเก็บและทำให้การ insert/update ช้าลง และคุณอาจยังไม่แก้ปัญหาจริงถ้าดัชนีไม่ตรงกับรูปแบบ WHERE + ORDER BY ที่ใช้บ่อย วงจรที่ปลอดภัยคือเปลี่ยนดัชนีทีละรายการ วัดผลคำสั่งที่ช้าเดียวกัน แล้วเก็บเฉพาะการเปลี่ยนแปลงที่ปรับปรุงเส้นทางใช้งานจริงอย่างชัดเจน\n\nถ้าคุณสร้างหน้าจอแอดมินใน AppMaster ให้บันทึกตัวกรองและการเรียงลำดับที่ทีมใช้บ่อยที่สุด แล้วเพิ่มดัชนีจำนวนน้อยที่สะท้อนมุมมองจริงเหล่านั้น แทนการทำดัชนีทุกฟิลด์ที่เปิดให้กรอง



ทดลองกับ AppMaster ด้วยแผนฟรี
เมื่อคุณพร้อม คุณสามารถเลือกการสมัครที่เหมาะสมได้


