แอปจองอุปกรณ์: ป้องกันการจองซ้ำและติดตามการคืน
วางแผนแอปจองอุปกรณ์ที่ป้องกันการจองซ้ำ บันทึกการคืนและความเสียหาย พร้อมระงับอุปกรณ์ที่มีปัญหาเพื่อรอการบำรุงรักษา
การจัดการการปล่อยสำหรับแอปโนโค้ด: การตั้งค่าสภาพแวดล้อมแบบปฏิบัติได้ การวางแผนการย้อนกลับ และการตรวจสอบการถดถอยอย่างรวดเร็วเมื่อต้องการเปลี่ยน
เมื่อแพลตฟอร์มสร้างแอปของคุณขึ้นใหม่จากโมเดลและตรรกะเชิงภาพ การปล่อยอาจรู้สึกไม่ใช่แค่ “ส่งการเปลี่ยนเล็กน้อย” แต่เหมือนกับ “สร้างบ้านใหม่” นั่นดีสำหรับการรักษาโค้ดให้สะอาด แต่ทำลายนิสัยหลายอย่างที่ทีมเรียนรู้จากโค้ดที่เขียนด้วยมือ
กับโค้ดที่สร้างขึ้นใหม่ คุณไม่ได้แพตช์ไฟล์ไม่กี่ไฟล์ คุณเปลี่ยนโมเดลข้อมูล เวิร์กโฟลว์ หรือหน้าจอ แล้วแพลตฟอร์มจะสร้างเวอร์ชันใหม่ของแอปขึ้นมา ตัวอย่างเช่น ใน AppMaster backend, เว็บ และมือถือ สามารถอัปเดตจากการเปลี่ยนชุดเดียวกัน ข้อดีคือไม่มีความยุ่งเหยิงสะสม ข้อเสียคือการแก้ไขเล็กน้อยอาจกระทบกว้างกว่าที่คาด
ปัญหามักแสดงตัวเป็น:
"ปลอดภัย" ไม่ได้หมายความว่า "จะไม่มีอะไรผิดพลาดเลย" แต่ว่าการปล่อยต้องคาดเดาได้ ปัญหาปรากฏก่อนที่ผู้ใช้จะรายงาน และการย้อนกลับทำได้เร็วและไม่วุ่นวาย คุณจะไปถึงจุดนั้นด้วยกฎการเลื่อนสภาพแวดล้อมที่ชัดเจน (dev → staging → prod), แผนการย้อนกลับที่ทำตามได้ขณะเครียด และการตรวจสอบการถดถอยที่ผูกกับสิ่งที่เปลี่ยนจริง
บทความนี้สำหรับผู้สร้างเดี่ยวและทีมขนาดเล็กที่ปล่อยบ่อย ถ้าคุณปล่อยทุกสัปดาห์หรือทุกวัน คุณต้องมีรูทีนที่ทำให้การเปลี่ยนรู้สึกปกติ แม้ว่าแพลตฟอร์มจะสร้างทุกอย่างใหม่ด้วยคลิกเดียวก็ตาม
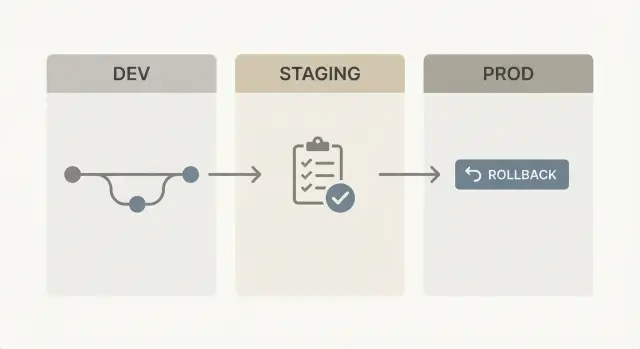
แม้จะเป็นโนโค้ด การตั้งค่าสภาพแวดล้อมที่ปลอดภัยที่สุดยังคงเรียบง่าย: สามสภาพแวดล้อมที่มีหน้าที่ชัดเจน
Dev คือที่ที่คุณสร้างและตั้งใจทำให้พัง ใน AppMaster นี่คือที่แก้ไข Data Designer, ปรับกระบวนการธุรกิจ และวนซ้ำ UI อย่างรวดเร็ว Dev เพื่อความเร็ว ไม่ใช่เพื่อความเสถียร
Staging คือการซ้อม ควรดูและทำงานเหมือนโปรดักชัน แต่ไม่มีลูกค้าจริงพึ่งพา Staging คือที่ที่คุณยืนยันว่า build ที่สร้างใหม่ยังทำงาน end to end รวมถึงการรวมเช่น auth, การชำระเงิน Stripe, อีเมล/SMS, หรือการส่งข้อความ Telegram
Prod คือที่ที่ผู้ใช้จริงและข้อมูลจริงอยู่ การเปลี่ยนในโปรดักชันควรทำซ้ำได้และน้อยที่สุด
การแบ่งงานแบบปฏิบัติได้ที่ช่วยให้ทีมสอดคล้อง:
เลื่อนการเปลี่ยนตามความมั่นใจ ไม่ใช่ตามปฏิทิน ย้ายจาก dev → staging เมื่อฟีเจอร์สามารถทดสอบเป็นองค์รวมได้ (หน้าจอ, ตรรกะ, สิทธิ์ และการเปลี่ยนข้อมูลร่วมกัน) ย้ายจาก staging → prod ก็ต่อเมื่อคุณสามารถรันฟลว์หลักสองครั้งโดยไม่มีความประหลาดใจ: ครั้งแรกบนการปรับใช้สะอาด และครั้งที่สองหลังการเปลี่ยนการตั้งค่าเล็กน้อย
การตั้งชื่อเรียบง่ายช่วยลดความสับสนเมื่อสถานการณ์ตึงเครียด:
ปฏิบัติต่อ staging เป็นสำเนาพฤติกรรมโปรดักชัน ไม่ใช่ที่จอดงาน "เกือบเสร็จ"
การแตกสาขาไม่ใช่เพื่อปกป้องตัวสร้างโค้ด แต่เพื่อปกป้องพฤติกรรมในโปรดักชัน
เริ่มด้วยสาขา mainline เดียวที่ตรงกับโปรดักชันและพร้อมปล่อยเสมอ ในคำศัพท์ AppMaster สาขานี้แทนสถานะ Data Designer, กระบวนการธุรกิจ และ UI ที่ผู้ใช้พึ่งพา
การตั้งค่าที่ปฏิบัติได้:
รักษาสาขา feature ให้เล็กและสั้น หากการเปลี่ยนแตะข้อมูล ตรรกะ และ UI ให้แยกเป็นสองหรือสามการ merge ที่แต่ละขั้นยังคงทำให้แอปทำงานได้ (แม้ว่าฟีเจอร์จะซ่อนอยู่หลังท็อกเกิลหรือเห็นได้เฉพาะผู้ดูแล)
ใช้สาขา release เฉพาะเมื่อคุณต้องการเวลาสำหรับเสถียรโดยไม่บล็อกงานใหม่ เช่น ทีมหลายทีมปล่อยในสัปดาห์เดียว มิฉะนั้น merge ไปที่ main บ่อย ๆ เพื่อไม่ให้เกิดการเบี่ยงเบนของสาขา
กฎการ merge บางอย่างช่วยป้องกัน "เซอร์ไพรส์จากการสร้างใหม่":
ตัวอย่าง: ถ้าคุณเพิ่มขั้นตอนการอนุมัติ ให้ merge ตรรกะเวิร์กโฟลว์ก่อนในขณะที่เส้นทางเก่ายังทำงาน จากนั้นค่อย merge UI และสิทธิ์ ขั้นตอนย่อยทำให้การถดถอยสังเกตเห็นได้ง่ายขึ้น
ความสอดคล้องไม่ได้หมายความว่าต้องโคลนทุกอย่าง แต่หมายถึงการทำให้สิ่งที่สำคัญเหมือนกัน
คำจำกัดความของแอป (data model, logic, UI) ควรเดินหน้าปลอดภัย ในขณะที่แต่ละสภาพแวดล้อมเก็บการตั้งค่าของตัวเอง ในทางปฏิบัติ dev, staging, prod ควรใช้โค้ดที่สร้างเดียวกันและกฎสกีม่าเดียวกัน แต่มีค่าของสภาพแวดล้อมต่างกัน: โดเมน, จุดปลายของซอฟต์แวร์ภายนอก, ขีดจำกัดอัตรา, และท็อกเกิลฟีเจอร์
ความลับต้องมีแผนก่อนที่จะต้องใช้ ปฏิบัติต่อ API keys, OAuth client secrets และเว็บฮุกว่าเป็นของสภาพแวดล้อม ไม่ใช่ของโปรเจกต์ กฎง่าย ๆ ทำงานได้ดี: นักพัฒนาสามารถอ่านความลับของ dev ได้, กลุ่มเล็กอ่านความลับของ staging ได้, และแทบไม่มีใครอ่านความลับของ prod ได้ หมุนคีย์ตามตาราง และหมุนทันทีหากคีย์โปรดักชันไปอยู่ในเครื่องมือ dev
Staging ควรเหมือน prod ในด้านที่จะจับข้อผิดพลาด ไม่ใช่ในด้านที่จะสร้างความเสี่ยง:
หลีกเลี่ยงการก็อปปี้ข้อมูลโปรดักชันมาที่ staging เว้นแต่จำเป็น หากต้องทำ ให้ปกปิดข้อมูลส่วนบุคคลและเก็บสำเนาไว้อย่างชั่วคราว
ตัวอย่าง: คุณเพิ่มขั้นตอนการอนุมัติใหม่ ใน staging ให้ใช้บัญชี Stripe ทดสอบและช่อง Telegram ทดสอบ พร้อมออร์เดอร์สังเคราะห์ที่เลียนแบบออร์เดอร์จริงที่ใหญ่ที่สุด คุณจะจับเงื่อนไขที่พังและสิทธิ์ที่ขาดหายโดยไม่เผยลูกค้า
ถ้าคุณใช้ AppMaster ให้รักษาการออกแบบแอปให้สอดคล้องข้ามสภาพแวดล้อมและเปลี่ยนแค่การตั้งค่าสภาพแวดล้อมกับความลับต่อการปรับใช้ วินัยนี้ทำให้การปล่อยรู้สึกคาดเดาได้
เมื่อแพลตฟอร์มสร้างโค้ดใหม่หลังการเปลี่ยน นิสัยที่ปลอดภัยคือเดินไปทีละก้าวและทำให้แต่ละก้าวตรวจสอบได้ง่าย
เขียนการเปลี่ยนเป็นข้อกำหนดเล็กและทดสอบได้. หนึ่งประโยคที่เพื่อนร่วมงานที่ไม่ใช่เทคนิคสามารถยืนยันได้ เช่น: “ผู้จัดการสามารถเพิ่มบันทึกการอนุมัติ และคำขอยังคงเป็น Pending จนกว่าผู้จัดการจะอนุมัติ” เพิ่มเช็คลิสต์ 2–3 ข้อ (ใครเห็นได้, เกิดอะไรเมื่ออนุมัติ/ปฏิเสธ)
สร้างใน dev และสร้างใหม่บ่อย ๆ. ใน AppMaster มักหมายถึงอัปเดต Data Designer (ถ้าข้อมูลเปลี่ยน), ปรับตรรกะ Business Process, แล้วสร้างใหม่และรันแอป เก็บการเปลี่ยนให้แคบเพื่อเห็นสาเหตุเมื่อพัง
ปรับใช้เวอร์ชันเดียวกันไปยัง staging สำหรับการตรวจสอบเต็มรูปแบบ. Staging ควรตรงกับการตั้งค่าโปรดักชันให้มากที่สุด ยืนยันการรวมโดยใช้บัญชีที่ปลอดภัยสำหรับ staging
สร้าง release candidate และแช่แข็งชั่วคราว. เลือกบิลด์เป็น RC หยุด merge งานใหม่เป็นช่วงสั้น ๆ (แม้แต่ 30–60 นาที) เพื่อให้ผลการทดสอบยังใช้ได้ ถ้าเจอปัญหา แก้ปัญหานั้นเท่านั้นแล้วตัด RC ใหม่
ปรับใช้สู่ prod แล้วยืนยันฟลว์ผู้ใช้หลัก. ทันทีหลังการปล่อย ให้ทำ smoke pass บน 3–5 ฟลว์ที่สร้างรายได้หรือทำให้อุปกรณ์ทำงานต่อ (ล็อกอิน, สร้างคำขอ, อนุมัติ, ส่งออก/รายงาน, การแจ้งเตือน)
ถ้าอะไรรู้สึกไม่ชัดเจนใน staging ให้หยุด ความล่าช้าอย่างสงบถูกกว่าการย้อนกลับที่รีบเร่ง
กับโค้ดที่สร้างใหม่ “การย้อนกลับ” ต้องมีความหมายชัดเจน ตัดสินใจก่อนว่าการย้อนกลับคือ:
เหตุการณ์จริงส่วนใหญ่ต้องทั้งสอง: โค้ดกลับบวกการกู้คืนคอนฟิกที่คืนการเชื่อมต่อบุคคลที่สามและท็อกเกิ้ลสู่สถานะที่รู้ว่าดี
เก็บบันทึกง่าย ๆ สำหรับแต่ละสภาพแวดล้อม (dev, staging, prod): แท็กการปล่อย, เวลาในการปรับใช้, ใครอนุมัติ, และสิ่งที่เปลี่ยน ใน AppMaster นั่นหมายถึงบันทึกเวอร์ชันแอปที่คุณปรับใช้และตัวแปรสภาพแวดล้อมกับการตั้งค่าการรวมที่ใช้ ขณะเครียดคุณไม่ควรต้องเดาว่าบิลด์ไหนเสถียร
การเปลี่ยนฐานข้อมูลมักเป็นสิ่งที่ขัดขวางการย้อนกลับอย่างรวดเร็ว แยกการเปลี่ยนเป็นแบบย้อนกลับได้และย้อนกลับไม่ได้ การเพิ่มคอลัมน์แบบ nullable มักย้อนกลับได้ การลบคอลัมน์หรือการเปลี่ยนความหมายของค่าไม่ค่อยจะย้อนกลับได้ สำหรับการเปลี่ยนที่เสี่ยง วางแผนเส้นทางแก้ไขต่อไป (hotfix ที่ส่งได้เร็ว) และถ้าจำเป็น ให้ทำจุดคืนค่าสำรองข้อมูลทันทีก่อนปล่อย
แผนการย้อนกลับที่ทำตามได้ง่าย:
ฝึกใน staging ทำเหตุการณ์จำลองรายเดือนเพื่อให้การย้อนกลับกลายเป็นความเคยชิน
การตรวจสอบการถดถอยที่ดีที่สุดผูกกับสิ่งที่อาจพัง ฟิลด์ใหม่ในฟอร์มไม่ค่อยต้องทดสอบทุกอย่าง แต่สามารถส่งผลต่อการตรวจสอบ ความถูกต้องสิทธิ์ และการทำงานอัตโนมัติด้านล่าง
เริ่มจากระบุรัศมีผลกระทบ: หน้าจอ, บทบาท, ตารางข้อมูล, และการรวมใดถูกแตะ ทดสอบเส้นทางที่ตัดผ่านรัศมีนั้น รวมถึงฟลว์หลักบางอย่างที่ต้องทำงานเสมอ
Golden paths คือเวิร์กโฟลว์สำคัญที่ต้องผ่านทุกการปล่อย:
เขียนผลลัพธ์ที่คาดหวังเป็นภาษาธรรมดา (เห็นอะไร ควรถูกสร้างอะไร สถานะควรเปลี่ยนอย่างไร) นั่นคือคำจำกัดความที่ทำซ้ำได้ของคำว่าเสร็จ
ปฏิบัติต่อการรวมเป็นมินิซิสเต็ม แค่หลังการเปลี่ยน ให้รันการตรวจสอบสั้น ๆ ต่อการรวมแต่ละตัว แม้ UI จะดูปกติก็ต้องตรวจสอบ เช่น: การชำระเงิน Stripe ผ่าน, เทมเพลตอีเมลเรนเดอร์, ข้อความ Telegram มาถึง, และการเรียก AI คืนค่าที่ใช้ได้
เพิ่มการตรวจสอบสุขภาพข้อมูลเล็ก ๆ เพื่อจับความล้มเหลวแบบเงียบ ๆ:
บนแพลตฟอร์มอย่าง AppMaster ที่แอปสามารถสร้างใหม่หลังแก้ไข การตรวจสอบแบบมุ่งเป้าช่วยยืนยันว่าสร้างใหม่ไม่ได้เปลี่ยนพฤติกรรมเกินความตั้งใจ
นาทีสุดท้ายก่อนผลักสู่โปรดักชัน เป้าหมายไม่ใช่ความสมบูรณ์แบบ แต่คือจับความล้มเหลวที่เจ็บปวดที่สุด: ล็อกอินพัง, สิทธิ์ผิด, การรวมล้มเหลว, และข้อผิดพลาดพื้นหลังเงียบ ๆ
ทำให้ staging เป็นการซ้อมจริง ใน AppMaster นั่นมักหมายถึงบิลด์ใหม่และปรับใช้สู่ staging (ไม่ใช่สภาพแวดล้อมที่อัปเดตครึ่งเดียว) เพื่อทดสอบสิ่งที่จะปล่อยจริง
ห้าเช็คที่พอทำได้ใน 10 นาที:
ถ้าแอปมีงานอัตโนมัติ เพิ่มการตรวจเงียบ ๆ หนึ่งข้อ: ทริกเกอร์งานตามเวลา/อะซิงค์หนึ่งงานและยืนยันว่าจบโดยไม่สร้างซ้ำ (สองเรคคอร์ด, สองข้อความ, สองค่าใช้จ่าย)
ถ้าเช็คใดล้มเหลว ให้หยุดการปล่อยและจดขั้นตอนการทำซ้ำที่ชัดเจน การแก้ปัญหาที่ทำซ้ำได้เร็วกว่าการผลักและหวัง
ทีมปฏิบัติการของคุณใช้เครื่องมือภายในสำหรับอนุมัติคำขอซื้อ วันนี้มีสองขั้นตอน: ผู้ขอส่ง, ผู้จัดการอนุมัติ ข้อกำหนดใหม่: เพิ่มขั้นตอนการอนุมัติจากฝ่ายการเงินสำหรับรายการที่มากกว่า $5,000 และส่งการแจ้งเตือนเมื่อฝ่ายการเงินอนุมัติหรือปฏิเสธ
ปฏิบัติต่อมันเป็นการเปลี่ยนที่ควบคุมได้ สร้างสาขา feature ระยะสั้นจาก mainline ที่เสถียร (เวอร์ชันที่อยู่ใน prod) สร้างใน dev ก่อน ใน AppMaster นั่นมักหมายถึงอัปเดต Data Designer (สถานะหรือฟิลด์ใหม่), เพิ่มตรรกะใน Business Process Editor, แล้วอัปเดต UI เว็บ/มือถือเพื่อแสดงขั้นตอนใหม่
เมื่อมันทำงานใน dev ส่งสาขาเดียวกันนั้นไปยัง staging (สไตล์คอนฟิกเหมือนกัน แต่ข้อมูลต่างกัน) พยายามทำให้พังโดยตั้งใจ โดยเฉพาะรอบ ๆ สิทธิ์และเคสขอบเขต
ใน staging ให้ทดสอบ:
ปรับใช้สู่ prod ในช่วงเวลาที่เงียบ Keep บิลด์ prod ก่อนหน้าพร้อมให้ redeploy หากการอนุมัติฝ่ายการเงินล้มเหลวหรือการแจ้งเตือนผิดพลาด หากคุณรวมการเปลี่ยนข้อมูล ตัดสินใจก่อนว่าการย้อนกลับหมายถึง “ปรับใช้เวอร์ชันเก่า” หรือ “ปรับใช้เวอร์ชันเก่าพร้อมกับการแก้ข้อมูลเล็กน้อย”
บันทึกการเปลี่ยนสั้น ๆ: เพิ่มอะไร ทดสอบอะไรใน staging แท็ก/เวอร์ชันการปล่อย และความเสี่ยงใหญ่ที่สุด (มักเป็นสิทธิ์หรือการแจ้งเตือน) ครั้งหน้าความต้องการเปลี่ยน คุณจะเคลื่อนไหวเร็วขึ้นโดยมีข้อถกเถียงน้อยลง
การปล่อยที่เจ็บปวดไม่ค่อยมาจากบั๊กใหญ่เดียว แต่มาจากทางลัดที่ทำให้ยากจะเห็นว่าอะไรเปลี่ยน ที่ไหนเปลี่ยน และจะแก้อย่างไร
กับดักหนึ่งคือสาขาที่ยืดเยื้อที่เก็บไว้ "จนกว่าจะเสร็จ" มันเกิดการเบี่ยงเบน คนแก้ปัญหาใน dev, ปรับ staging, แล้ว hotfix prod สัปดาห์ต่อมา ไม่มีใครบอกได้ว่าเวอร์ชันไหนเป็นของจริง และการ merge กลายเป็นการเดาที่เสี่ยง ในแพลตฟอร์มอย่าง AppMaster สาขาระยะสั้นและการ merge บ่อยช่วยให้การเปลี่ยนเข้าใจได้
กับดักอีกอย่างคือข้าม staging เพราะคิดว่า "แค่การเปลี่ยนเล็กน้อย" การเปลี่ยนเล็กมักแตะตรรกะที่แชร์: กฎการตรวจสอบ, ขั้นตอนการอนุมัติ, callback การชำระเงิน UI ดูน้อย แต่ผลข้างเคียงปรากฏในโปรดักชัน
การแก้ไขในโปรดักชันด้วยมือก็แพงเช่นกัน ถ้าใครเปลี่ยนตัวแปรสภาพแวดล้อม, ท็อกเกิ้ลฟีเจอร์, คีย์การชำระเงิน, หรือเว็บฮุกโดยตรงใน prod "แค่ครั้งเดียว" คุณจะเสียความสามารถในการทำซ้ำ การปล่อยครั้งถัดไปทำงานต่างออกไปและไม่มีใครรู้ว่าทำไม บันทึกการเปลี่ยนแปลงทุกอย่างในโปรดักชันเป็นส่วนหนึ่งของการปล่อย และใช้วิธีเดียวกันทุกครั้ง
ความผิดพลาดในการย้อนกลับมักเจ็บที่สุด ทีมมักย้อนกลับเวอร์ชันแอปแต่ลืมว่าข้อมูลอาจเดินหน้าแล้ว หากการปล่อยรวมการเปลี่ยนสกีมาหรือฟิลด์ที่จำเป็น โค้ดเก่าอาจล้มเหลวกับข้อมูลใหม่
นิสัยบางอย่างช่วยป้องกันสิ่งนี้เกือบทั้งหมด:
ถ้าไม่มีสัญญาณ "เสร็จ" การปล่อยไม่เคยจบจริง ๆ มันแค่เลื่อนเข้าสู่เหตุฉุกเฉินถัดไป
ความเครียดจากการปล่อยมาจากการตัดสินใจที่ทำในวันปล่อย วิธีแก้คือกำหนดครั้งเดียว เขียนลง แล้วทำซ้ำ
ใส่กฎการแตกสาขาไว้หน้าเดียว เป็นภาษาง่าย ๆ ที่ใครก็ทำตามได้เมื่อคุณไม่อยู่ กำหนดคำว่า "เสร็จ" สำหรับการเปลี่ยน (เช็คที่รัน, การเซ็นอนุมัติ, อะไรนับเป็น release candidate)
ถ้าคุณต้องการโครงสร้างเข้มงวด กฎง่าย ๆ คือ:
ทำให้สภาพแวดล้อมรู้สึกต่างอย่างมีเหตุผล Dev เพื่อการเปลี่ยนเร็ว, Staging เพื่อพิสูจน์การปล่อย, Prod เพื่อผู้ใช้ ล็อกการเข้าถึง prod และมอบเจ้าของเกตการปล่อยให้ staging
ถ้าคุณสร้างบน AppMaster วิธีการ "สร้างซอร์สโค้ดใหม่สะอาด" จะสบายที่สุดเมื่อจับคู่กับสภาพแวดล้อมมีวินัยและการตรวจสอบ golden-path ที่รวดเร็ว สำหรับทีมที่ประเมินเครื่องมือ AppMaster (appmaster.io) ถูกออกแบบสำหรับแอปเต็มรูปแบบ (backend, เว็บ, และมือถือ native) ซึ่งทำให้รูทีนการปล่อยแบบนี้มีประโยชน์เป็นพิเศษ
ปล่อยให้เล็กลงและบ่อยขึ้น เลือกจังหวะ (ทุกสัปดาห์หรือสองครั้งต่อเดือน) และทำให้เป็นงานปกติ การปล่อยขนาดเล็กทำให้การตรวจสอบเร็วขึ้น การย้อนกลับง่ายขึ้น และช่วง "หวังว่ามันจะทำงาน" หายากลง
ใช้สามสภาพแวดล้อม: dev สำหรับการเปลี่ยนแปลงเร็ว, staging สำหรับซ้อมที่ใกล้เคียงโปรดักชัน และ prod สำหรับผู้ใช้จริง วิธีนี้ช่วยจำกัดความเสี่ยงขณะยังสามารถปล่อยบ่อยได้
เพราะการสร้างใหม่อาจสร้างผลกระทบมากกว่าที่ตั้งใจ การเปลี่ยนเล็ก ๆ ในฟิลด์ที่แชร์ ตรรกะ หรือสิทธิ์ อาจกระทบหน้าจอและบทบาทอื่น ๆ ดังนั้นคุณต้องมีวิธีที่ทำซ้ำได้เพื่อจับข้อผิดพลาดก่อนผู้ใช้จะพบ
ปฏิบัติ staging เหมือนซ้อมจริงที่สะท้อนพฤติกรรมโปรดักชัน: รักษากฎสกีม่าและการรวมแกนหลักให้เหมือนกัน แต่ใช้บัญชีทดสอบและความลับแยกต่างหาก เพื่อทดสอบแบบ end-to-end โดยไม่เสี่ยงเงินหรือข้อมูลจริง
เริ่มจาก mainline เดียวที่ตรงกับโปรดักชันและพร้อมปล่อยเสมอ แล้วใช้สาขา feature ระยะสั้นสำหรับการเปลี่ยนแต่ละรายการ เพิ่มสาขา release เมื่อต้องการหน้าต่างการเสถียร และสาขา hotfix สำหรับแก้ไขด่วนเท่านั้น
แตกเป็นหลาย ๆ การรวมที่แต่ละขั้นทำให้อินสแตนซ์ยังทำงานได้ เช่น รวมตรรกะเวิร์กโฟลว์ก่อนโดยให้เส้นทางเก่ายังทำงาน แล้วค่อยรวม UI และสิทธิ์ จากนั้นค่อยเพิ่มการตรวจสอบที่เข้มงวดขึ้น การทำเป็นขั้นเล็ก ๆ จะช่วยให้หาการถดถอยได้ง่ายขึ้น
เก็บคีย์และความลับเป็นของสภาพแวดล้อม ไม่ใช่ของโปรเจกต์ กำหนดผู้ที่อ่านความลับได้ในแต่ละสภาพแวดล้อม แยกคีย์ตามสภาพแวดล้อม หมุนคีย์ตามตาราง และหมุนทันทีหากคีย์โปรดักชันหลุดไปยังเครื่องมือใน dev
เลือกบิลด์ที่ทดสอบแล้วเป็น RC และหยุดการ merge ชั่วคราวเพื่อให้ผลการทดสอบยังใช้ได้ ถ้าพบปัญหา แก้แค่นั้นแล้วสร้าง RC ใหม่ แทนที่จะเพิ่มการเปลี่ยนแปลงอื่น ๆ ขณะทดสอบ
กำหนดก่อนว่าการย้อนกลับหมายถึงอะไร: วางบิลด์ก่อนหน้าใหม่หรือกู้การตั้งค่ากลับ หรือทั้งสองอย่าง เหตุการณ์จริงมักต้องทั้งโค้ดกลับและการกู้ค่าคอนฟิก (คีย์/ท็อกเกิ้ล) ให้กลับสู่สถานะที่รู้ว่าดี
สมมติว่าการเปลี่ยนโครงสร้างฐานข้อมูลอาจกีดกันการย้อนกลับได้ ชอบการเปลี่ยนที่ย้อนกลับได้ก่อน (เช่น เพิ่มคอลัมน์ที่เป็น nullable) สำหรับการเปลี่ยนเสี่ยง ๆ ให้วางแผนแก้ไขต่อไปได้เร็วและสำรองข้อมูลก่อนปล่อย
รันชุด golden paths สั้น ๆ ทุกการปล่อย แล้วทดสอบเฉพาะสิ่งที่อยู่ในรัศมีผลกระทบของการเปลี่ยน (หน้าจอ, บทบาท, ตาราง, การรวม) แยกกันตรวจสอบการเชื่อมต่อแต่ละตัวเพื่อจับความล้มเหลวแบบเงียบ ๆ



ทดลองกับ AppMaster ด้วยแผนฟรี
เมื่อคุณพร้อม คุณสามารถเลือกการสมัครที่เหมาะสมได้


