แอปจองอุปกรณ์: ป้องกันการจองซ้ำและติดตามการคืน
วางแผนแอปจองอุปกรณ์ที่ป้องกันการจองซ้ำ บันทึกการคืนและความเสียหาย พร้อมระงับอุปกรณ์ที่มีปัญหาเพื่อรอการบำรุงรักษา
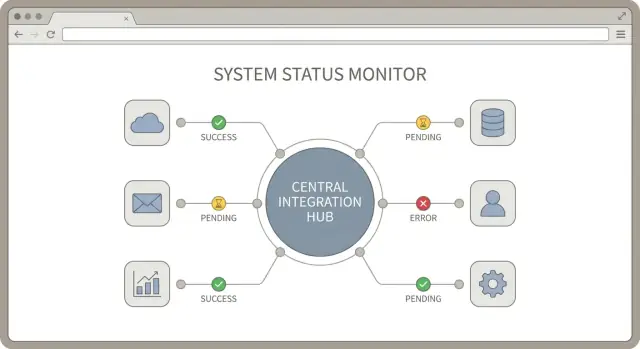
เรียนรู้การออกแบบศูนย์กลางการเชื่อมต่อ (integration hub) เพื่อรวมข้อมูลรับรอง ติดตามสถานะการซิงค์ และจัดการข้อผิดพลาดอย่างสม่ำเสมอเมื่อสแต็ก SaaS ของคุณขยายตัวข้ามหลายบริการ
สแต็ก SaaS มักเริ่มจากเรียบง่าย: CRM หนึ่งตัว, ระบบเรียกเก็บเงินหนึ่งตัว, กล่องจดหมายสนับสนุนหนึ่งช่อง แล้วทีมเพิ่มการตลาดอัตโนมัติ, คลังข้อมูล, ช่องทางสนับสนุนที่สอง, และเครื่องมือเฉพาะทางไม่กี่ตัวที่ “แค่ต้องซิงค์เร็วๆ” ไม่นานก็กลายเป็นเว็บของการเชื่อมต่อแบบจุดถึงจุดที่ไม่มีใครเป็นเจ้าของทั้งหมด
สิ่งที่พังก่อนมักไม่ใช่ข้อมูล แต่เป็นกาวที่เชื่อมทุกอย่างเข้าด้วยกัน
ข้อมูลรับรองกระจัดกระจายอยู่ในบัญชีส่วนตัว, สเปรดชีตที่แชร์, และตัวแปรแวดล้อมต่างๆ โทเค็นหมดอายุ, คนออกจากงาน, แล้วจู่ๆ “การเชื่อมต่อ” นั้นก็ขึ้นกับการเข้าสู่ระบบที่ไม่มีใครหาเจอ แม้การรักษาความปลอดภัยจะทำได้ดี การหมุนรหัสลับก็เจ็บปวดเพราะการเชื่อมต่อแต่ละตัวมีการตั้งค่าและที่อัพเดตของตัวเอง
การมองเห็นก็ล่มต่อมา การแจ้งสถานะแต่ละตัวต่างกัน (หรือไม่มีเลย) เครื่องมือหนึ่งบอกว่า “connected” ขณะที่ยังล้มเหลวในการซิงค์อย่างเงียบๆ อีกเครื่องส่งอีเมลกำกวมที่ถูกมองข้าม เมื่อเซลส์ถามว่าทำไมลูกค้าไม่ถูกจัดเตรียม คำตอบกลายเป็นการล่าหลักฐานในล็อก, แดชบอร์ด, และเธรดแชท
ภาระงานฝ่ายซัพพอร์ตเพิ่มขึ้นเร็วเพราะความล้มเหลววินิจฉัยยากและเกิดซ้ำง่าย ปัญหาเล็กๆ เช่น ข้อจำกัดอัตรา (rate limits), การเปลี่ยนสคีมา, และการ retry บางส่วน กลายเป็นเหตุการณ์ยาวนานเมื่อไม่มีใครเห็นเส้นทางเต็มจาก “เกิดเหตุการณ์” ถึง “ข้อมูลมาถึง”
ฮับการเชื่อมต่อ (integration hub) เป็นไอเดียเรียบง่าย: จุดศูนย์กลางที่การเชื่อมต่อไปยังบริการภายนอกถูกจัดการ, มอนิเตอร์, และสนับสนุน การออกแบบฮับที่ดีสร้างกฎสม่ำเสมอว่าการพิสูจน์ตัวตนทำอย่างไร, รายงานสถานะการซิงค์อย่างไร, และจัดการข้อผิดพลาดอย่างไร
ฮับเชิงปฏิบัติการมุ่งผลลัพธ์สี่ประการ: ข้อผิดพลาดน้อยลง (รูปแบบ retry และการตรวจสอบร่วม), การแก้ไขเร็วขึ้น (ติดตามง่าย), การเข้าถึงปลอดภัยขึ้น (การเป็นเจ้าของข้อมูลรับรองกลาง), และความพยายามซัพพอร์ตต่ำลง (การแจ้งเตือนและข้อความมาตรฐาน)
ถ้าคุณสร้างสแต็กบนแพลตฟอร์มอย่าง AppMaster เป้าหมายก็เหมือนเดิม: ทำให้การปฏิบัติการการเชื่อมต่อเรียบง่ายพอที่คนทั่วไปจะเข้าใจสิ่งที่เกิดขึ้น และผู้เชี่ยวชาญจะแก้ได้เร็วเมื่อเกิดปัญหา
ก่อนตัดสินใจเรื่องการเชื่อมต่อครั้งใหญ่ ให้เห็นภาพชัดว่าคุณเชื่อมต่ออะไรอยู่ (หรือวางแผนจะเชื่อมต่อ) นี่เป็นส่วนที่คนมักข้าม และมักสร้างความประหลาดใจทีหลัง
เริ่มจากการระบุทุกบริการบุคคลที่สามในสแต็กของคุณ แม้แต่ตัว "เล็กๆ" ระบุว่าใครเป็นเจ้าของ (บุคคลหรือทีม) และสถานะว่าเปิดใช้งานแล้ว, วางแผน, หรือทดสอบ
ต่อมา แยกระหว่างการเชื่อมต่อที่ลูกค้าเห็นกับอัตโนมัติพื้นหลัง การเชื่อมต่อหน้าใช้งานอาจเป็น “เชื่อมบัญชี Salesforce ของคุณ” ขณะที่ออโตเมชันภายในอาจเป็น “เมื่อใบแจ้งหนี้ใน Stripe ถูกจ่าย ให้ทำเครื่องหมายลูกค้าว่าใช้งานได้ในฐานข้อมูล” ทั้งสองชนิดมีความคาดหวังด้านความน่าเชื่อถือและล้มเหลวในรูปแบบต่างกัน
จากนั้นแม็ปการไหลของข้อมูลด้วยคำถามเดียว: ใครต้องการข้อมูลนั้นเพื่อทำงานของพวกเขา? ทีมผลิตภัณฑ์อาจต้องการเหตุการณ์การใช้งานสำหรับการ Onboarding, ฝ่ายปฏิบัติการต้องการสถานะบัญชีและการจัดเตรียม, ฝ่ายการเงินต้องการใบแจ้งหนี้ การคืนเงิน และฟิลด์ภาษี, ฝ่ายซัพพอร์ตต้องการตั๋ว ประวัติการสนทนา และการจับคู่ตัวตนของผู้ใช้ ความต้องการเหล่านี้กำหนดฮับการเชื่อมต่อของคุณมากกว่าที่ API ของผู้ขายกำหนด
สุดท้าย กำหนดความคาดหวังด้านเวลาให้แต่ละการไหล:
ตัวอย่าง: “ใบแจ้งหนี้ที่จ่ายแล้ว” อาจต้องการความใกล้เคียงเรียลไทม์สำหรับการควบคุมการเข้าถึง แต่รายวันสำหรับสรุปทางการเงิน จับข้อกำหนดเหล่านี้แต่เนิ่นๆ และการมอนิเตอร์กับการจัดการข้อผิดพลาดจะมาตรฐานง่ายขึ้น
การออกแบบฮับที่ดีเริ่มจากขอบเขต หากฮับพยายามทำทุกอย่าง มันจะกลายเป็นคอขวดสำหรับทุกทีม ถ้ามันทำงานน้อยไป คุณจะจบด้วยสคริปต์จำนวนมากที่ทำงานไม่เหมือนกัน
เขียนลงมาว่าฮับเป็นเจ้าของอะไรและไม่เป็นเจ้าของอะไร แบ่งงานแบบปฏิบัติได้คือ:
เลือกจุดเข้าเดียวสำหรับการเชื่อมต่อทั้งหมดและยึดติดกับมัน จุดเข้าอาจเป็น API (ระบบอื่นเรียกฮับ) หรือ job runner (ฮับรันการดึง/ส่งตามกำหนด) การใช้ทั้งสองแบบทำได้แต่ต้องใช้ท่อภายในเดียวกันเพื่อให้ retries, logging, และการแจ้งเตือนทำงานเหมือนกัน
การตัดสินใจไม่กี่อย่างช่วยให้ฮับโฟกัส: มาตรฐานว่าจะเริ่มการเชื่อมต่ออย่างไร (webhook, schedule, rerun แบบแมนนวล), ตกลงรูปแบบ payload พื้นฐาน (แม้ว่าพาร์ทเนอร์จะแตกต่างกัน), ตัดสินใจว่าจะเก็บอะไรไว้ (เหตุการณ์ดิบ, ระเบียนที่ทำให้เป็นมาตรฐาน, ทั้งสอง หรือไม่เก็บเลย), นิยามว่า “เสร็จ” คืออะไร (ยอมรับ, ส่งมอบ, ยืนยัน), และมอบหมายความเป็นเจ้าของสำหรับความพิเศษของพาร์ทเนอร์
ตัดสินใจว่าจะทำการแปลงข้อมูลที่ไหน หากคุณทำ normalization ในฮับ บริการปลายทางจะเรียบง่ายขึ้น แต่ฮับต้องมีการจัดเวอร์ชันและทดสอบที่แข็งแรง หากฮับบางเบาและส่ง payload ดิบผ่านไป บริการปลายทางแต่ละตัวต้องเรียนรู้รูปแบบของพาร์ทเนอร์หลายแบบ ทีมส่วนใหญ่จะเลือกทางกลาง: ทำ normalization เฉพาะฟิลด์ที่ใช้ร่วมกัน (ID, timestamps, สถานะพื้นฐาน) แล้วเก็บกฎโดเมนไว้ที่ปลายทาง
วางแผนรองรับ multi-tenant ตั้งแต่วันแรก ตัดสินใจว่าหน่วยการแยกคือ ลูกค้า, workspace, หรือ org ตัวเลือกนี้ส่งผลต่อ rate limits, การจัดเก็บข้อมูลรับรอง, และ backfills เมื่อโทเค็นของลูกค้า A หมดอายุ คุณควรหยุดงานของเทนแนนต์นั้นเท่านั้น ไม่ใช่ทั้งพายป์ไลน์ เครื่องมืออย่าง AppMaster ช่วยออกแบบเทนแนนต์และเวิร์กโฟลว์แบบภาพได้ แต่ขอบเขตยังต้องชัดก่อนสร้าง
คลังข้อมูลรับรองอาจทำให้ชีวิตสงบหรือกลายเป็นความเสี่ยงถาวร เป้าหมายง่ายๆ คือ: มีที่เดียวเก็บการเข้าถึง โดยไม่ให้ระบบและเพื่อนร่วมงานมีอำนาจเกินความจำเป็น
OAuth และ API keys ปรากฏในที่ต่างกัน OAuth เป็นเรื่องปกติสำหรับแอปที่มีผู้ใช้หน้าบ้านอย่าง Google, Slack, Microsoft และ CRM หลายตัว ผู้ใช้อนุญาตการเข้าถึง แล้วคุณเก็บ access token บวก refresh token API keys พบในการเชื่อมต่อเซิร์ฟเวอร์ต่อเซิร์ฟเวอร์และ API เก่าๆ พวกมันอาจยาวนาน ซึ่งทำให้การจัดเก็บและการหมุนเวียนปลอดภัยสำคัญขึ้น
เก็บทุกอย่างแบบเข้ารหัสและจำกัดตามเทนแนนต์ ในผลิตภัณฑ์มัลติ-คัสโตเมอร์ ให้ปฏิบัติต่อข้อมูลรับรองเป็นข้อมูลลูกค้า รักษาการแยกอย่างเคร่งครัดเพื่อให้โทเค็นของ Tenant A ไม่สามารถใช้กับ Tenant B โดยไม่ได้ตั้งใจ เก็บเมตาดาต้าที่ต้องใช้ภายหลังด้วย เช่น การเชื่อมต่อที่เป็นของใคร, วันหมดอายุ, และสิทธิ์ที่มอบให้
กฎปฏิบัติที่ป้องกันปัญหาส่วนใหญ่:
วางแผนการ refresh และ revocation โดยไม่ทำให้การซิงค์พัง สำหรับ OAuth การ refresh ควรเกิดอัตโนมัติในพื้นหลัง ฮับของคุณควรจัดการกรณี "token expired" โดย refresh ครั้งหนึ่งแล้ว retry อย่างปลอดภัย สำหรับการเพิกถอน (ผู้ใช้ตัดการเชื่อมต่อ, ทีมความปลอดภัยปิดแอป, หรือสโคปเปลี่ยน) ให้หยุดการซิงค์ ทำเครื่องหมายการเชื่อมต่อเป็น needs_auth และเก็บแทร็กการตรวจสอบที่ชัดเจนของสิ่งที่เกิดขึ้น
ถ้าคุณสร้างฮับบน AppMaster ให้ปฏิบัติต่อข้อมูลรับรองเป็น data model ที่ป้องกัน, เก็บการเข้าถึงในโลจิก backend เท่านั้น, และแสดงสถานะ connected/disconnected ให้ UI เห็น ผู้ปฏิบัติการสามารถแก้การเชื่อมต่อได้โดยไม่เคยเห็นความลับ
เมื่อเชื่อมต่อเครื่องมือหลายตัว คำถาม "มันทำงานไหม?" จะกลายเป็นคำถามประจำวัน การแก้ไขไม่ใช่การเพิ่มล็อก แต่เป็นชุดสัญญาณการซิงค์ขนาดเล็กและสม่ำเสมอที่เหมือนกันสำหรับทุกการเชื่อมต่อ การออกแบบฮับที่ดีถือว่าสถานะเป็นฟีเจอร์ระดับหนึ่ง
เริ่มจากการกำหนดรายการสั้นๆ ของสเตตัสการเชื่อมต่อและใช้ให้ทั่ว: ใน UI แอดมิน, ในการแจ้งเตือน, และในโน้ตซัพพอร์ต ใช้ชื่อตรงๆ เพื่อให้เพื่อนร่วมงานที่ไม่ใช่เทคนิคก็ทำตามได้
ติดตามสาม timestamp ต่อการเชื่อมต่อ: เวลาเริ่มซิงค์ล่าสุด, เวลาเข้ารหัสซิงค์สำเร็จล่าสุด, และเวลาเกิดข้อผิดพลาดล่าสุด พวกนี้เล่าเรื่องได้เร็วโดยไม่ต้องขุดลึก
มุมมองต่อการเชื่อมต่อเล็กๆ ต่อหนึ่งการเชื่อมต่อช่วยทีมซัพพอร์ตทำงานเร็วขึ้น หน้าแต่ละการเชื่อมต่อควรแสดงสถานะปัจจุบัน, timestamp เหล่านั้น, และข้อความข้อผิดพลาดล่าสุดในรูปแบบที่ชัดเจนสำหรับผู้ใช้ (ไม่ใช่ stack trace) เพิ่มบรรทัดคำแนะนำสั้นๆ เช่น "ต้องการ re-auth" หรือ "Rate limit, กำลัง retry"
เพิ่มสัญญาณสุขภาพบางอย่างที่ทำนายปัญหาก่อนผู้ใช้สังเกต: ขนาดคิวค้าง, จำนวน retry, จำนวนการชนกับ rate limit, และความสำเร็จล่าสุดของ throughput (คร่าวๆ ว่ามีกี่รายการที่ซิงค์ต่อการรันครั้งล่าสุด)
ตัวอย่าง: การซิงค์ CRM ของคุณเชื่อมต่ออยู่ แต่ backlog เพิ่มและการชน rate limit พุ่ง นั่นยังไม่ใช่การล่ม แต่เป็นสัญญาณให้ลดความถี่การซิงค์หรือเพิ่มการจัดแบตช์ หากคุณสร้างฮับใน AppMaster ฟิลด์สถานะพวกนี้แมปเข้ากับ Data Designer และแดชบอร์ดสนับสนุนง่ายๆ ที่ทีมใช้ทุกวันได้อย่างเรียบร้อย
การซิงค์ที่เชื่อถือได้เกี่ยวกับขั้นตอนที่ทำซ้ำได้มากกว่าลอจิกหรู เริ่มจากแบบการดำเนินงานชัดเจนหนึ่งแบบ แล้วเพิ่มความซับซ้อนเมื่อจำเป็น
ทีมส่วนใหญ่ใช้ผสมกัน แต่แต่ละคอนเน็กเตอร์ควรมีทริกเกอร์หลักเพื่อให้ง่ายต่อการวิเคราะห์:
ถ้าคุณสร้างใน AppMaster นี่มักแมปกับ endpoint เว็บฮุก, กระบวนการเบื้องหลัง, และงานที่กำหนดเวลา ทั้งหมดป้อนเข้าท่อภายในเดียวกัน
ผู้ขายต่างกันตั้งชื่อต่างกันสำหรับข้อมูลเดียวกัน (customerId vs contact_id, สตริงสถานะ, รูปแบบวันที่). แปลง payload ขาเข้าทุกรายการเป็นรูปแบบภายในเดียวก่อนใช้กฎธุรกิจ จะทำให้ฮับส่วนที่เหลือง่ายขึ้นและการเปลี่ยนแปลงคอนเน็กเตอร์ไม่เจ็บปวด
การ retry เป็นเรื่องปกติ ฮับของคุณควรรันการกระทำเดิมสองครั้งโดยไม่สร้างรายการซ้ำ วิธีทั่วไปคือเก็บ external ID และ "last processed version" (timestamp, sequence number, หรือ event ID). หากเจอไอเท็มเดิมอีกครั้ง ให้ข้ามหรืออัปเดตอย่างปลอดภัย
API ของบุคคลที่สามอาจช้า หรือค้าง วางงานที่ถูก normalize ลงในคิวทนทาน แล้วประมวลผลด้วย timeout ชัดเจน หากการเรียกใช้ใช้เวลานานเกินไป ให้ล้มเหลว บันทึกสาเหตุ และ retry ทีหลัง แทนที่จะบล็อกทุกอย่าง
จัดการข้อจำกัดด้วยทั้ง backoff และ throttling ต่อคอนเน็กเตอร์ ย้อนหลังเมื่อได้รับ 429/5xx ด้วยตาราง retry ที่มีเพดาน, ตั้งขีดจำกัดความขนานแยกตามคอนเน็กเตอร์ (CRM ไม่เหมือน billing), และเพิ่ม jitter เพื่อหลีกเลี่ยงการระเบิดของ retry
ตัวอย่าง: "ใบแจ้งหนี้ที่ชำระใหม่" มาจาก billing ผ่านเว็บฮุก ถูก normalize และเข้าแถว จากนั้นสร้างหรืออัปเดตบัญชีที่ตรงกันใน CRM หาก CRM จำกัดอัตรา คอนเน็กเตอร์นั้นจะชะลอตัวโดยไม่ล่าช้าการซิงค์ตั๋วซัพพอร์ต
ฮับที่ "ล้มเหลวบ้าง" แย่กว่าฮับที่ไม่มีเลย การแก้ไขคือวิธีที่ใช้ร่วมกันในการอธิบายข้อผิดพลาด ตัดสินใจว่าจะทำอะไรต่อ และบอกแอดมินที่ไม่ใช่เทคนิคว่าต้องทำอย่างไร
เริ่มจากรูปแบบข้อผิดพลาดมาตรฐานที่คอนเน็กเตอร์ทุกตัวส่ง แม้ว่าพาต์นของบุคคลที่สามต่างกัน นั่นทำให้ UI, การแจ้งเตือน, และ playbook ซัพพอร์ตสม่ำเสมอ
RATE_LIMIT)จากนั้นจัดประเภทความล้มเหลวเป็นกลุ่มไม่กี่กลุ่ม (อย่ามากเกินไป): auth, validation, timeout, rate limit, และ outage
ผูกกฎ retry ชัดเจนกับแต่ละกลุ่ม Rate limits ได้ retry ล่าช้าพร้อม backoff, timeouts retry แบบเร็วและจำกัดจำนวน, validation ต้องแก้ไขด้วยมือจนกว่าข้อมูลจะถูกต้อง, auth หยุดการเชื่อมต่อและขอให้แอดมินเชื่อมต่อใหม่
เก็บการตอบกลับดิบจากบุคคลที่สามไว้ แต่เก็บอย่างปลอดภัย หลบข้อมูลลับ (โทเค็น, API keys, ข้อมูลบัตรเต็มรูปแบบ) ก่อนบันทึก หากมันสามารถให้การเข้าถึง มันไม่ควรอยู่ในล็อก
เขียนข้อความสองแบบต่อข้อผิดพลาด: หนึ่งสำหรับแอดมิน และหนึ่งสำหรับวิศวกร ตัวอย่างข้อความแอดมิน: "การเชื่อมต่อ Salesforce หมดอายุ ให้เชื่อมต่อใหม่เพื่อกลับมาซิงค์" วิวสำหรับวิศวกรอาจรวมการตอบกลับที่ถูก sanitized, request ID, และขั้นตอนที่ล้มเหลว นี่คือที่ที่ฮับแบบมีมาตรฐานให้ผลดี ไม่ว่าจะทำในโค้ดหรือเครื่องมือแบบภาพเช่น AppMaster's Business Process Editor
โปรเจกต์การรวมระบบหลายชิ้นล้มเหลวด้วยสาเหตุที่น่าเบื่อ ฮับทำงานในการสาธิต แล้วพังเมื่อเพิ่มเทนแนนต์ ข้อมูลประเภท และกรณีขอบ
กับดักใหญ่คือการผสม logic ของการเชื่อมต่อกับ logic ทางธุรกิจ เมื่อ "วิธีพูดกับ API" อยู่ในเส้นทางโค้ดเดียวกับ "ความหมายของระเบียนลูกค้า" ทุกกฎใหม่เสี่ยงทำลายคอนเน็กเตอร์ แยก adapter ให้ชัด (connect, fetch, push, transform) แล้วรันกฎธุรกิจหลัง adapter
ปัญหาทั่วไปอีกอันคือถือสถานะเทนแนนต์เป็นแบบ global ในผลิตภัณฑ์ B2B แต่ละเทนแนนต์ต้องมีโทเค็น cursors จุดเช็กพอยต์ retry ของตัวเอง หากคุณเก็บ "last sync time" ไว้ที่เดียว ลูกค้าคนหนึ่งอาจเขียนทับคนอื่นและเกิดการอัปเดตหายหรือการรั่วไหลของข้อมูลข้ามเทนแนนต์
ห้ากับดักที่ปรากฏบ่อยและการแก้ไขง่าย:
Retries ต้องให้ความใส่ใจเป็นพิเศษ หากการเรียกสร้าง (create) หมดเวลา การ retry อาจสร้างรายการซ้ำ เว้นแต่คุณใช้ idempotency keys หรือกลยุทธ์ upsert ที่แข็งแรง หาก API ของบุคคลที่สามไม่รองรับ idempotency ให้ติดตามบัญชีแยกท้องถิ่นเพื่อระบุและหลีกเลี่ยงการเขียนซ้ำ
อย่าข้ามล็อก audit เมื่อซัพพอร์ตถามว่าทำไมระเบียนหาย คุณต้องมีคำตอบในไม่กี่นาที แทนที่จะเดา แม้คุณจะสร้างฮับด้วยเครื่องมือแบบภาพอย่าง AppMaster ให้ทำให้ล็อกและสถานะต่อเทนแนนต์เป็นเรื่องสำคัญตั้งแต่แรก
ฮับที่ดีน่าเบื่ออย่างดีที่สุด: มันเชื่อมต่อ, รายงานสุขภาพชัดเจน, และล้มเหลวในทางที่ทีมเข้าใจได้
เริ่มจากตรวจสอบวิธีการพิสูจน์ตัวตนของแต่ละการเชื่อมต่อและคุณจัดการข้อมูลรับรองอย่างไร ขอชุดสิทธิ์ที่เล็กที่สุดเท่าที่งานต้องการ (read-only ถ้าเป็นไปได้). เก็บความลับในที่จัดเก็บเฉพาะหรือวอลต์ที่เข้ารหัส และหมุนคีย์โดยไม่ต้องเปลี่ยนโค้ด ตรวจสอบให้แน่ใจว่าล็อกและข้อความผิดพลาดไม่รวมโทเค็น, API keys, refresh tokens, หรือ headers ดิบ
เมื่อข้อมูลรับรองปลอดภัย ยืนยันว่าการเชื่อมต่อของลูกค้าแต่ละรายมีแหล่งข้อมูลจริงเพียงแหล่งเดียว
ความชัดเจนเชิงปฏิบัติการคือสิ่งที่ทำให้การเชื่อมต่อจัดการได้เมื่อมีลูกค้าจำนวนมากและบริการบุคคลที่สามหลายตัว
ติดตามสถานะการเชื่อมต่อต่อเทนแนนต์ (connected, needs_auth, paused, failing) และแสดงใน UI แอดมิน บันทึกเวลาซิงค์สำเร็จล่าสุดต่อวัตถุหรือแต่ละงานซิงค์ ไม่ใช่แค่ "เรารันเมื่อวาน" ทำให้ข้อผิดพลาดล่าสุดหาง่ายพร้อมบริบท: ลูกค้าไหน, การเชื่อมต่อใด, ขั้นตอนไหน, คำขอภายนอกใด, และเกิดอะไรขึ้นถัดไป
จำกัด retries (จำนวนครั้งสูงสุดและหน้าต่างตัดขาด), ออกแบบการเขียนให้ idempotent เพื่อให้ reruns ไม่สร้างรายการซ้ำ ตั้งเป้าซัพพอร์ต: ใครสักคนในทีมควรหาข้อผิดพลาดล่าสุดและรายละเอียดได้ภายในสองนาทีโดยไม่ต้องอ่านโค้ด
ถ้าต้องทำ UI ฮับและการติดตามสถานะอย่างรวดเร็ว แพลตฟอร์มอย่าง AppMaster ช่วยให้คุณส่งมอบแดชบอร์ดภายในและโลจิกเวิร์กโฟลว์ได้เร็ว ในขณะที่ยังสร้างโค้ดที่พร้อมใช้งานจริง
จินตนาการผลิตภัณฑ์ SaaS ที่ต้องการการเชื่อมต่อสามอย่างทั่วไป: Stripe สำหรับเหตุการณ์การเรียกเก็บเงิน, HubSpot สำหรับการส่งมอบงานขาย, และ Zendesk สำหรับตั๋วซัพพอร์ต แทนที่จะเชื่อมแต่ละเครื่องมือเข้ากับแอปโดยตรง ให้ผ่านฮับการเชื่อมต่อเดียว
การ Onboarding เริ่มในแผงแอดมิน แอดมินคลิก "Connect Stripe", "Connect HubSpot", และ "Connect Zendesk" คอนเน็กเตอร์แต่ละตัวเก็บข้อมูลรับรองในฮับ ไม่ใช่ในสคริปต์สุ่มหรือแล็ปท็อปพนักงาน แล้วฮับรันการนำเข้าครั้งแรก:
หลังนำเข้า การซิงค์ครั้งแรกเริ่ม ฮับเขียนระเบียนซิงค์สำหรับแต่ละคอนเน็กเตอร์เพื่อให้ทุกคนเห็นเรื่องเดียวกัน มุมมองแอดมินง่ายๆ ตอบคำถามส่วนใหญ่: สถานะการเชื่อมต่อ, เวลาเข้ารหัสซิงค์ล่าสุด, งานปัจจุบัน (importing, syncing, idle), สรุปข้อผิดพลาดและรหัส, และรันถัดไปที่กำหนด
ตอนที่งานยุ่งและ Stripe จำกัดอัตราการเรียก API แทนที่จะทำให้ระบบทั้งหมดล้มเหลว คอนเน็กเตอร์ Stripe ทำเครื่องหมายงานเป็น retrying, เก็บความคืบหน้าบางส่วน (เช่น "invoices ถึง 10:40"), และ back off HubSpot และ Zendesk ยังคงซิงค์ต่อ
ซัพพอร์ตได้ตั๋ว: "Billing ดูล้าหลัง" พวกเขาเปิดฮับและเห็น Stripe เป็น failing ด้วยข้อผิดพลาด rate limit การแก้ไขเป็นขั้นตอน:
หากคุณสร้างบนแพลตฟอร์มอย่าง AppMaster กระแสงานนี้แมปกับโลจิกแบบภาพ (สถานะงาน, retries, หน้าจอแอดมิน) โดยยังสร้างโค้ด backend จริงสำหรับการใช้งานจริง
การออกแบบฮับการเชื่อมต่อที่ดีไม่ใช่การสร้างทุกอย่างทีเดียว แต่เป็นการทำให้การเชื่อมต่อใหม่แต่ละครั้งคาดเดาได้ เริ่มจากชุดกฎที่ใช้ร่วมกันเล็กๆ ที่คอนเน็กเตอร์ทุกตัวต้องปฏิบัติตาม แม้เวอร์ชันแรกจะรู้สึก "เรียบง่ายเกินไป"
เริ่มด้วยความสม่ำเสมอ: สถานะมาตรฐานสำหรับงานซิงค์ (pending, running, succeeded, failed), กลุ่มข้อผิดพลาดสั้นๆ (auth, rate limit, validation, upstream outage, unknown), และล็อก audit ที่ตอบได้ว่าใครรันอะไร เมื่อไร และระเบียนใด หากคุณไม่เชื่อถือสถานะและล็อก แดชบอร์ดและการแจ้งเตือนจะกลายเป็นเสียงรบกวน
เพิ่มคอนเน็กเตอร์ทีละตัวโดยใช้เทมเพลตและแนวทางเดียวกัน คอนเน็กเตอร์แต่ละตัวควรใช้ flow ข้อมูลรับรองเดียวกัน กฎ retry เดียวกัน และวิธีการเขียนสถานะเดียวกัน การทำซ้ำแบบนี้คือสิ่งที่ทำให้ฮับสามารถดูแลได้เมื่อมีการเชื่อมต่อสิบตัวแทนที่จะเป็นสาม
แผนการเปิดใช้งานเชิงปฏิบัติ:
แนะนำแดชบอร์ดและการแจ้งเตือนก็ต่อเมื่อข้อมูลสถานะพื้นฐานถูกต้องแล้ว เริ่มจากหน้าจอเดียวที่แสดงเวลา sync ล่าสุด ผลลัพธ์ล่าสุด รันถัดไป และข้อความข้อผิดพลาดล่าสุดพร้อมหมวด หากคุณชอบแนวทางไม่ต้องเขียนโค้ด คุณสามารถโมเดลข้อมูล สร้างโลจิกซิงค์ และแสดงหน้าจอสถานะใน AppMaster แล้วปรับใช้บนคลาวด์หรือส่งออกซอร์สโค้ด เก็บเวอร์ชันแรกให้น่าเบื่อและสังเกตได้ แล้วค่อยปรับปรุงประสิทธิภาพและกรณีขอบเมื่อการปฏิบัติการเสถียร
เริ่มจากการทำรายการอย่างง่าย: ระบุทุกเครื่องมือภายนอกที่เชื่อมต่อ ใครเป็นเจ้าของ และสถานะ (ใช้งานจริง/วางแผน/ทดลอง) แล้วจดว่าข้อมูลใดถูกส่งระหว่างระบบและเพราะเหตุใดทีมต่างๆ ถึงต้องการข้อมูลนั้น (เช่น support, finance, ops). แผนผังนี้จะบอกว่าอันไหนต้องการเวลาจริง อันไหนทำได้รายวัน และอันไหนต้องการการมอนิเตอร์เข้มข้นจริงๆ
ให้ฮับเป็นผู้ดูแลงานเชื่อมพื้นฐาน: การตั้งค่าการเชื่อมต่อ, เก็บข้อมูลรับรอง, การตั้งเวลา/ทริกเกอร์, การรายงานสถานะที่สม่ำเสมอ และการจัดการข้อผิดพลาดแบบเดียวกัน ส่วนการตัดสินใจทางธุรกิจ (เช่น ใครควรถูกเรียกเก็บเงินหรือคืบหน้าเป็นลูกค้าที่มีคุณสมบัติ) ให้เก็บไว้ข้างนอกฮับ เพื่อไม่ต้องเปลี่ยนโค้ดของคอนเน็กเตอร์ทุกครั้งที่กฎผลิตภัณฑ์เปลี่ยน
เลือกทางเข้าหลักสำหรับแต่ละคอนเน็กเตอร์แล้วใช้แบบเดียวกันเสมอ: เว็บฮุกเหมาะกับการอัพเดตเกือบเรียลไทม์, scheduled pulls เหมาะกับผู้ให้บริการที่ไม่สามารถส่งเหตุการณ์ได้, และงานแบบ job เหมาะเมื่อมีขั้นตอนต้องรันตามลำดับ. ไม่ว่าเลือกแบบไหน ให้เก็บ retries, logging และการอัปเดตสถานะให้สม่ำเสมอทั้งหมด
ปฏิบัติต่อข้อมูลรับรองเหมือนข้อมูลลูกค้า: เก็บเข้ารหัส แยกตามเทนแนนต์ และจำกัดการเข้าถึง ไม่ให้แสดงโทเค็นในล็อก หน้าจอ UI หรือภาพหน้าจอการสนับสนุน อย่าใช้ความลับของ production ในสเตจ และเก็บเมตาดาต้าที่ต้องใช้ปฏิบัติการเช่น วันหมดอายุ สิทธิ์ และการเป็นเจ้าของการเชื่อมต่อ
OAuth เหมาะเมื่อผู้ใช้เชื่อมบัญชีของตัวเองและคุณต้องการสิทธิ์ที่ยกเลิกได้และแยกตามสโคป ส่วน API keys เหมาะกับการเชื่อมเซิร์ฟเวอร์ต่อเซิร์ฟเวอร์ แต่มักยาวนานและต้องหมุนเวียนบ่อย หากเลือกได้ ให้ใช้ OAuth กับการเชื่อมต่อที่มีผู้ใช้เป็นเจ้าของ และจำกัด/หมุนคีย์สำหรับการเชื่อมเซิร์ฟเวอร์
เก็บสถานะของเทนแนนต์แยกจากกันเสมอ: โทเค็น ตัวชี้วัด (cursors) จุดเช็กพอยต์การซิงค์ ตัวนับ retry และความคืบหน้าการ backfill. เมื่อปัญหาเกิดกับเทนแนนต์หนึ่ง ควรหยุดเฉพาะงานของเทนแนนต์นั้น ไม่ใช่ทั้งคอนเน็กเตอร์ นี่ช่วยป้องกันการรั่วไหลของข้อมูลข้ามเทนแนนต์และทำให้การแก้ปัญหาง่ายขึ้น
ใช้สถานะชุดเล็กๆ ที่เข้าใจง่ายทั่วทั้งคอนเน็กเตอร์ เช่น connected, needs_auth, paused, failing และบันทึกสามเวลาต่อการเชื่อมต่อ: เวลาที่เริ่มซิงค์ล่าสุด, เวลาที่ซิงค์สำเร็จล่าสุด, และเวลาเกิดข้อผิดพลาดล่าสุด ด้วยสัญญาณเหล่านี้ คำถามว่า “มันทำงานไหม?” ส่วนมากจะตอบได้โดยไม่ต้องเปิดล็อก
ทำให้การเขียนข้อมูลสามารถรันซ้ำได้โดยไม่สร้างข้อมูลซ้ำ: เก็บ external object ID พร้อมตัวชี้วัด “last processed” แล้วใช้ upsert แทนการสร้างใหม่ ถ้าผู้ให้บริการไม่รองรับ idempotency ให้เก็บบันทึกการเขียนท้องถิ่นเพื่อป้องกันการเขียนซ้ำ
จัดการ rate limit อย่างมีเจตนา: throttle ต่อคอนเน็กเตอร์, backoff เมื่อได้รับ 429 หรือข้อผิดพลาดชั่วคราว, และเพิ่ม jitter เพื่อหลีกเลี่ยงการระเบิดของ retries. วางงานลงคิวทนทาน (durable queue) พร้อม timeout เพื่อให้การเรียก API ช้าไม่บล็อกการซิงค์ของคอนเน็กเตอร์อื่น
ถ้าต้องการทำแบบ no-code ให้ออกแบบโมเดลการเชื่อมต่อ เทนแนนต์ และฟิลด์สถานะใน AppMaster’s Data Designer แล้วสร้างเวิร์กโฟลว์การซิงค์ใน Business Process Editor เก็บข้อมูลรับรองในโลจิกเฉพาะส่วน backend และแสดงเฉพาะสถานะที่ปลอดภัยใน UI แบบนี้คุณสามารถส่งมอบแดชบอร์ปภายในได้เร็ว โดยยังได้โค้ดที่พร้อมผลิตจริง



ทดลองกับ AppMaster ด้วยแผนฟรี
เมื่อคุณพร้อม คุณสามารถเลือกการสมัครที่เหมาะสมได้


