แอปจองอุปกรณ์: ป้องกันการจองซ้ำและติดตามการคืน
วางแผนแอปจองอุปกรณ์ที่ป้องกันการจองซ้ำ บันทึกการคืนและความเสียหาย พร้อมระงับอุปกรณ์ที่มีปัญหาเพื่อรอการบำรุงรักษา
เวิร์กโฟลว์ที่ทำงานนานอาจล้มในแบบที่ซับซ้อน เรียนรู้รูปแบบสถานะที่ชัดเจน ตัวนับการลองใหม่ การจัดการ dead-letter และแดชบอร์ดที่ผู้ปฏิบัติงานวางใจได้
เวิร์กโฟลว์ที่ทำงานนานล้มเหลวต่างจากการเรียกสั้นๆ เสมอ การเรียก API สั้นๆ จะสำเร็จหรือเกิดข้อผิดพลาดทันที แต่เวิร์กโฟลว์ที่ใช้เป็นชั่วโมงหรือวัน อาจทำสำเร็จ 9 ขั้นตอนจาก 10 แล้วทิ้งความยุ่งเหยิงไว้: ข้อมูลสร้างไม่ครบ สถานะสับสน และไม่มีการกระทำถัดไปที่ชัดเจน
นั่นคือเหตุผลที่ประโยคว่า “เมื่อวานมันทำงานได้” มาบ่อย เวิร์กโฟลว์ไม่ได้เปลี่ยน แต่สภาพแวดล้อมรอบๆ เปลี่ยน เวิร์กโฟลว์ระยะยาวพึ่งพาบริการอื่นให้คงสภาพ ตัวตน (credentials) ต้องยังใช้ได้ และข้อมูลต้องมีรูปแบบตามที่คาด
รูปแบบความล้มเหลวยอดนิยมได้แก่: หมดเวลาและการตอบช้า (เช่น API พาร์ทเนอร์ใช้งานได้แต่วันนี้ใช้เวลา 40 วินาที), การอัปเดตไม่ครบ (บันทึก A ถูกสร้าง แต่ B ไม่ถูกสร้าง ทำให้ไม่สามารถรันซ้ำได้อย่างปลอดภัย), การล่มของ dependency (ผู้ให้บริการอีเมล/SMS หรือเกตเวย์ชำระเงิน), callback หายหรือตารางเวลาพลาด (webhook ไม่มาถึง, งานที่ตั้งเวลาไม่ทำงาน), และขั้นตอนที่ต้องใช้คนแล้วติดค้าง (การอนุมัติรอเป็นวันแล้วกลับมาด้วยสมมติฐานที่ล้าสมัย)
ปัญหาหลักคือสถานะ ระบบเรียกสั้นๆ เก็บสถานะไว้ในหน่วยความจำจนเสร็จ แต่เวิร์กโฟลว์ไม่สามารถทำแบบนั้นได้ มันต้องบันทึกสถานะระหว่างขั้นตอนและพร้อมเริ่มต่อหลังการรีสตาร์ท การดีพลอย หรือการล่ม และต้องจัดการกับการที่ขั้นตอนเดียวกันอาจถูกทริกเกอร์สองครั้ง (การลองใหม่, webhook ซ้ำ, การ replay ของผู้ปฏิบัติงาน)
ในการปฏิบัติ “เชื่อถือได้” ไม่ใช่หมายถึงไม่เคยล้ม แต่หมายถึงสามารถคาดเดาได้ อธิบายได้ กู้คืนได้ และมีเจ้าของชัดเจน
คาดเดาได้ หมายถึงเมื่อ dependency ล้ม เวิร์กโฟลว์ตอบสนองแบบเดียวกันทุกครั้ง อธิบายได้ หมายถึงผู้ปฏิบัติงานตอบได้ภายในหนึ่งนาทีว่า “มันติดตรงไหน ทำไม?” กู้คืนได้ หมายถึงคุณสามารถลองใหม่หรือดำเนินการต่อโดยไม่ทำให้ข้อมูลเสียหาย เจ้าของชัดเจน หมายถึงทุกรายการที่ติดค้างมีการกระทำถัดไปที่ชัดเจน: รอ, ลองใหม่, แก้ข้อมูล, หรือส่งต่อให้คนดูแล
ตัวอย่างง่ายๆ: ระบบ onboarding สร้างบันทึกลูกค้า จัดการสิทธิ์ แล้วส่งข้อความต้อนรับ ถ้าการจัดการสิทธิ์สำเร็จแต่การส่งข้อความล้มเพราะผู้ให้บริการอีเมลล่ม เวิร์กโฟลว์ที่เชื่อถือได้จะบันทึกว่า “Provisioned, message pending” และตั้งเวลาลองใหม่ มันจะไม่ทำ provisioning ซ้ำโดยไม่ตรวจสอบ
เครื่องมือช่วยได้ถ้าเก็บตรรกะเวิร์กโฟลว์และข้อมูลถาวรใกล้กัน ยกตัวอย่าง AppMaster ช่วยให้คุณโมเดลสถานะเวิร์กโฟลว์ในข้อมูล (ผ่าน Data Designer) และอัปเดตจาก Business Processes แบบมองเห็น แต่ความเชื่อถือได้มาจากรูปแบบ ไม่ใช่เครื่องมือ: ปฏิบัติต่อระบบอัตโนมัติที่ทำงานนานเหมือนชุดสถานะถาวรที่อยู่รอดได้แม้เวลาผ่าน ความล้มเหลว และการแทรกแซงของคน
เวิร์กโฟลว์ที่ทำงานนานมักล้มในรูปแบบเดิมๆ: API ภายนอกตอบช้าลง คนยังไม่ได้อนุมัติ หรืองานรออยู่ในคิว สถานะที่ชัดเจนทำให้สถานการณ์เหล่านี้เห็นได้ทันที จึงไม่ต้องสับสนระหว่าง "กำลังใช้เวลา" กับ "พัง"
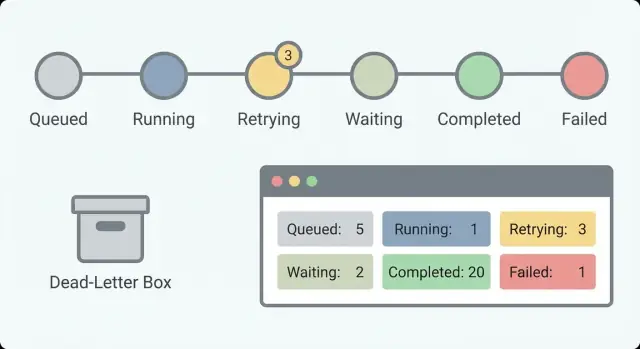
เริ่มจากชุดสถานะเล็กๆ ที่ตอบคำถามเดียว: ตอนนี้เกิดอะไรขึ้น? ถ้ามี 30 สถานะ ไม่มีใครจำได้ แต่ถ้ามีประมาณ 5–8 สถานะ ผู้รับผิดชอบสามารถสแกนรายการแล้วเข้าใจได้
ชุดสถานะที่ใช้งานได้จริงสำหรับหลายเวิร์กโฟลว์:
การแยก Waiting ออกจาก Running สำคัญ “รอคำตอบจากลูกค้า” อาจเป็นเรื่องปกติ ขณะที่ “กำลังทำงาน 6 ชั่วโมง” อาจเป็นการค้าง ถ้าไม่แยก คุณจะตามล่าเตือนผิดและพลาดเหตุการณ์จริง
แค่ชื่อสถานะไม่พอ ให้เพิ่มฟิลด์ไม่กี่อย่างที่เปลี่ยนสถานะให้เป็นสิ่งที่ปฏิบัติได้:
ตัวอย่าง: เวิร์กโฟลว์ onboarding อาจโชว์ “Waiting” พร้อมเหตุผล “Pending manager approval” และเปลี่ยนล่าสุด “2 วันที่แล้ว” นั่นบอกว่าไม่ใช่การค้าง แต่อาจต้องเตือน
ปฏิบัติต่อชื่สถานะเหมือน API ถ้าคุณเปลี่ยนชื่อบ่อย แดชบอร์ด การแจ้งเตือน และ playbook ของซัพพอร์ตจะสับสนอย่างรวดเร็ว ถ้าต้องการความหมายใหม่ ให้พิจารณาเพิ่มสถานะใหม่และปล่อยสถานะเก่าสำหรับรายการเดิม
ใน AppMaster คุณสามารถโมเดลสถานะเหล่านี้ใน Data Designer และอัปเดตจาก Business Process logic เพื่อให้สถานะมองเห็นได้และสอดคล้องในแอปของคุณ แทนที่จะฝังไว้ในล็อก
การลองใหม่ช่วยได้จนกว่าจะไปซ่อนปัญหาจริง เป้าหมายไม่ใช่ “ไม่ล้มเลย” แต่เป็น “ล้มในทางที่คนเข้าใจและซ่อมแซมได้” ซึ่งเริ่มจากกฎชัดเจนว่าข้อผิดพลาดประเภทไหนลองใหม่ได้และประเภทไหนไม่ได้
กฎที่ทีมส่วนใหญ่ใช้ได้: ลองใหม่กับข้อผิดพลาดที่เป็นชั่วคราว (network timeout, rate limit, การล่มชั่วคราวของภายนอก) อย่าลองใหม่กับข้อผิดพลาดที่ชัดว่าเป็นถาวร (ข้อมูลไม่ถูกต้อง, ขาดสิทธิ์, “บัญชีปิด”, “บัตรปฏิเสธ”) ถ้าคุณบอกไม่ได้ว่าเป็นประเภทไหน ให้ถือเป็นไม่ควรลองใหม่จนกว่าจะรู้มากขึ้น
ติดตามตัวนับการลองต่อขั้นตอน (หรือการเรียกภายนอกแต่ละครั้ง) ไม่ใช่ตัวเดียวสำหรับทั้งเวิร์กโฟลว์ เวิร์กโฟลว์อาจมีสิบขั้นตอนและมีเพียงหนึ่งขั้นตอนที่แกว่ง การนับแยกช่วยไม่ให้ขั้นตอนหลังๆ มากินโอกาสของขั้นตอนก่อนหน้า
ตัวอย่าง: การเรียก “Upload document” อาจลองใหม่ได้ไม่กี่ครั้ง ขณะที่ “Send welcome email” ไม่ควรลองเรื่อยๆ เพราะขั้นตอนอัปโหลดใช้โอกาสไปก่อน
เลือกรูปแบบ backoff ที่สอดคล้องกับความเสี่ยง หน่วงคงที่พอใช้ได้สำหรับ retry ง่ายๆ ที่มีต้นทุนต่ำ Exponential backoff เหมาะเมื่อเสี่ยงโดน rate limit ตั้ง cap เพื่อไม่ให้เวลารอเพิ่มไม่จำกัด และใส่ jitter เล็กน้อยเพื่อหลีกเลี่ยงการเกิด retry storm
แล้วตัดสินใจว่าเมื่อไหร่จะหยุด เงื่อนไขหยุดที่ดีควรชัดเจน: จำนวนครั้งสูงสุด เวลาสูงสุดรวม หรือ “ยอมแพ้สำหรับรหัสข้อผิดพลาดบางอย่าง” เกตเวย์ชำระเงินที่ตอบกลับว่า “บัตรไม่ถูกต้อง” ควรหยุดทันทีแม้ว่าปกติให้ลองได้ 5 ครั้ง
ผู้ปฏิบัติงานต้องรู้ว่าจะเกิดอะไรต่อ บันทึกเวลาลองครั้งถัดไปและเหตุผล (เช่น “Retry 3/5 at 14:32 due to timeout”) ใน AppMaster คุณสามารถเก็บตรงนี้ในเรคอร์ดเวิร์กโฟลว์เพื่อให้แดชบอร์ดโชว์ว่า “รอถึง” แทนการเดา
นโยบายการลองใหม่ที่ดีต้องทิ้งร่องรอย: อะไรล้มเหลว ลองไปกี่ครั้ง ครั้งต่อไปเมื่อไหร่ และเมื่อไหร่จะหยุดแล้วส่งต่อไปยังการจัดการ dead-letter
เมื่อเวิร์กโฟลว์ทำงานนาน การลองใหม่เป็นเรื่องปกติ ความเสี่ยงคือการทำขั้นตอนที่สำเร็จไปแล้วซ้ำ Idempotency คือกฎที่ทำให้ปลอดภัย: ขั้นตอนหนึ่งเป็น idempotent ถ้าการรันสองครั้งมีผลเหมือนรันครั้งเดียว
ตัวอย่างคลาสสิก: คุณคิดบัตร แล้วเวิร์กโฟลว์ล้มก่อนบันทึกว่า “ชำระเงินสำเร็จ” เมื่อลองใหม่ มันคิดบัตรอีกครั้ง นี่คือปัญหา double-write โลกภายนอกเปลี่ยน แต่สถานะในเวิร์กโฟลว์ไม่ได้เปลี่ยน
รูปแบบที่ปลอดภัยคือสร้างคีย์ idempotency ที่คงที่ต่อแต่ละขั้นตอนที่มีผลข้างเคียง ส่งคีย์นี้กับการเรียกภายนอก และบันทึกผลของขั้นตอนทันทีที่ได้กลับมา ผู้ให้บริการหลายรายสนับสนุน idempotency keys (เช่น เรียกเก็บเงินโดย OrderID) ถ้าขั้นตอนถูกเรียกซ้ำ ผู้ให้บริการจะคืนผลเดิมแทนการทำซ้ำ
ในเอนจินเวิร์กโฟลว์ ให้ถือว่าทุกขั้นตอนอาจถูก replay ได้ ใน AppMaster นั่นมักหมายถึงการบันทึกผลลัพธ์ของขั้นตอนในฐานข้อมูลและตรวจสอบก่อนเรียก integration อีกครั้ง ถ้า “Send welcome email” มี MessageID บันทึกไว้แล้ว การลองใหม่ควรใช้บันทึกนั้นและข้ามการส่งใหม่
แนวทางป้องกันการซ้ำในทางปฏิบัติ:
การซ้ำยังเกิดขึ้นได้ โดยเฉพาะกับ webhook เข้ามาซ้ำหรือผู้ใช้กดปุ่มครั้งเดียวหลายครั้ง ตัดสินนโยบายต่อประเภทเหตุการณ์: ปฏิเสธ exact duplicates (คีย์เดียวกัน), รวมการอัปเดตที่เข้ากันได้ (เช่น last-write-wins สำหรับฟิลด์โปรไฟล์), หรือทำเครื่องหมายให้ตรวจสอบเมื่อมีความเสี่ยงเรื่องเงินหรือกฎระเบียบ
Dead-letter คือรายการเวิร์กโฟลว์ที่ล้มและถูกย้ายออกจากเส้นทางปกติเพื่อไม่ให้บล็อกงานอื่น คุณเก็บมันไว้เพราะต้องการให้สามารถวินิจฉัย ตัดสินใจว่าซ่อมได้ไหม และประมวลผลซ้ำอย่างปลอดภัย
ความผิดพลาดใหญ่คือเก็บแค่ข้อความผิดพลาด เมื่อคนดู dead-letter ในภายหลัง พวกเขาต้องการบริบทพอที่จะทำซ้ำปัญหาโดยไม่ต้องเดา
รายการ dead-letter ที่มีประโยชน์ควรเก็บ:
การจัดหมวดหมู่ช่วยให้ dead-letter ทำงานได้จริง ป้ายสั้นๆ ช่วยผู้ปฏิบัติงานเลือกขั้นตอนถัดไปได้ถูกต้อง กลุ่มทั่วไปได้แก่ permanent error (กฎตรรกะ, สถานะไม่ถูกต้อง), data issue (ฟิลด์หาย, รูปแบบไม่ถูก), dependency down (timeout, rate limit, outage), และ auth/permission (token หมดอายุ, credential ถูกปฏิเสธ)
การประมวลผลซ้ำควรถูกควบคุม จุดประสงค์คือลดความเสียหายซ้ำ เช่น คิดเงินสองครั้งหรือส่งอีเมลสแปม กำหนดกฎว่าใครสามารถลองใหม่ เมื่อใด จะเปลี่ยนอะไรได้ (แก้ฟิลด์บางอย่าง, แนบเอกสารที่ขาด, รีเฟรช token) และอะไรที่ต้องคงที่ (request ID และ downstream idempotency keys)
ทำให้รายการ dead-letter ค้นหาได้ด้วยตัวระบุที่คงที่ เมื่อผู้ปฏิบัติงานพิมพ์ “order 18422” แล้วเห็นขั้นตอนที่ชัดเจน ข้อมูลนำเข้า และประวัติการพยายาม การแก้ไขจะรวดเร็วและสม่ำเสมอ
ถ้าคุณสร้างใน AppMaster ให้ถือ dead-letter เป็นโมเดลฐานข้อมูลชั้นหนึ่งและเก็บสถานะ การพยายาม และตัวระบุเป็นฟิลด์ เพื่อแดชบอร์ดภายในสามารถค้นหา กรอง และเรียกการประมวลผลซ้ำแบบควบคุมได้
เวิร์กโฟลว์ที่ทำงานนานล้มได้ในวิธีที่ช้าและสับสน: ขั้นตอนรอการตอบอีเมล, ผู้ให้บริการชำระเงินหมดเวลา, หรือ webhook มาสองครั้ง ถ้าคุณมองไม่เห็นว่าเวิร์กโฟลว์กำลังทำอะไร คุณจะต้องเดา การมองเห็นที่ดีเปลี่ยนคำถามจาก “มันพังไหม” เป็นคำตอบชัดเจน: เวิร์กโฟลว์ไหน ขั้นตอนใด สถานะอะไร และต้องทำอะไรต่อ
เริ่มจากให้ทุกขั้นตอนส่งฟิลด์ชุดเล็กเดียวกันเพื่อให้ผู้ปฏิบัติงานสแกนได้เร็ว:
ฟิลด์เหล่านี้รองรับตัวนับพื้นฐานที่แสดงสุขภาพโดยรวม สำหรับเวิร์กโฟลว์ระยะยาว ตัวเลขรวมมีความสำคัญกว่าข้อผิดพลาดเดี่ยวๆ เพราะคุณกำลังมองหาความโน้มเอียง: งานสะสม, การลองใหม่พุ่ง, หรือการรอที่ไม่สิ้นสุด
ติดตาม started, completed, failed, retrying และ waiting ตามเวลา จำนวน waiting เล็กๆ อาจเป็นปกติ (การอนุมัติของคน) แต่ถ้าจำนวน waiting เพิ่มขึ้นมักหมายถึงบางอย่างถูกบล็อก จำนวน retrying ที่เพิ่มมักชี้ไปที่ปัญหาผู้ให้บริการหรือบั๊กที่ทำให้เกิดข้อผิดพลาดเดิมซ้ำ
การแจ้งเตือนควรตรงกับสิ่งที่ผู้ปฏิบัติงานพบ แทนที่จะเตือนว่า “เกิดข้อผิดพลาด” ให้แจ้งอาการ: backlog เพิ่มขึ้น (started minus completed เพิ่มขึ้นเรื่อยๆ), เวิร์กโฟลว์ติดค้างใน waiting เกินเวลาที่คาด, อัตราการลองใหม่สูงสำหรับขั้นตอนเฉพาะ, หรือการกระโดดของข้อผิดพลาดทันทีหลังปล่อย release หรือเปลี่ยน config
เก็บ event trail สำหรับแต่ละเวิร์กโฟลว์เพื่อให้ตอบคำถามว่า “เกิดอะไรขึ้น?” ได้ในมุมมองเดียว trail ที่มีประโยชน์รวมถึง timestamps, การเปลี่ยนสถานะ, สรุปของ input และ output (ไม่ใช่ payload ที่ละเอียดและอ่อนไหว), และเหตุผลของการลองใหม่หรือข้อผิดพลาด ตัวอย่าง: “Charge card: retry 3/5, timeout from provider, next attempt in 10m.”
Correlation IDs คือกาวเชื่อม ถ้าลูกค้าบอกว่า “ฉันถูกคิดเงินสองครั้ง” คุณต้องเชื่อมเหตุการณ์ในระบบกับ charge ID ของผู้ให้บริการและ order ID ภายใน ใน AppMaster คุณสามารถมาตรฐานสิ่งนี้ใน Business Process logic โดยสร้างและส่ง correlation IDs ผ่านการเรียก API และขั้นตอนส่งข้อความเพื่อให้แดชบอร์ดและล็อกตรงกัน
เมื่อเวิร์กโฟลว์ใช้เวลาหลายชั่วโมงหรือหลายวัน ความล้มเหลวเป็นเรื่องปกติ สิ่งที่จะทำให้มันกลายเป็น outage คือแดชบอร์ดที่แค่บอกว่า “Failed” แล้วไม่มีข้อมูลอื่น เป้าหมายคือตอบสามคำถามให้ผู้ปฏิบัติงานได้เร็ว: กำลังเกิดอะไรขึ้น ทำไมมันเกิด และพวกเขาสามารถทำอะไรต่อได้อย่างปลอดภัย
เริ่มจากรายการเวิร์กโฟลว์ที่หาของสำคัญได้ง่าย ตัวกรองลดความตื่นตระหนกและเสียงคุยเพราะทุกคนสามารถจำกัดมุมมองได้อย่างรวดเร็ว
ตัวกรองที่มีประโยชน์ได้แก่ สถานะ อายุ (เวลาที่เริ่มและเวลาในสถานะปัจจุบัน) เจ้าของ (ทีม/ลูกค้า/ผู้รับผิดชอบ) ประเภท (ชื่อเวิร์กโฟลว์/เวอร์ชัน) และลำดับความสำคัญถ้ามีขั้นตอนที่มีผลต่อผู้ใช้ปลายทาง
ต่อมาให้โชว์ "ทำไม" ติดกับสถานะ แทนที่จะซ่อนในล็อก เพียงป้ายสถานะไม่พอถ้าไม่จับคู่กับข้อความผิดพลาดล่าสุด หมวดสั้นๆ ของข้อผิดพลาด และสิ่งที่ระบบจะทำต่อไป สองฟิลด์ที่ทำงานได้มากคือ last error และ next retry time ถ้า next retry ว่าง ให้ทำให้ชัดเลยว่าเวิร์กโฟลว์รอคน หยุดชั่วคราว หรือผิดพลาดถาวร
การกระทำของผู้ปฏิบัติงานควรปลอดภัยเป็นค่าดีฟอลต์ ช่วยชี้ไปยังการกระทำความเสี่ยงต่ำก่อน และทำให้การกระทำเสี่ยงชัดเจน:
“Force continue” มักทำให้เกิดความเสียหาย หากให้ฟังก์ชันนี้ ให้เขียนความเสี่ยงเป็นภาษาธรรมดา: “การดำเนินการนี้ข้ามการตรวจสอบการชำระเงินและอาจสร้างออร์เดอร์ที่ยังไม่จ่าย” และโชว์ข้อมูลที่จะถูกเขียนหากดำเนินต่อ
บันทึกการกระทำของผู้ปฏิบัติงานทุกอย่างไว้เป็น audit: ใครทำเมื่อไหร่ สถานะก่อน/หลัง และเหตุผล ถ้าสร้างเครื่องมือภายในใน AppMaster ให้เก็บ audit trail นี้เป็นตารางชั้นหนึ่งและแสดงในหน้ารายละเอียดเวิร์กโฟลว์เพื่อให้การส่งต่องานชัดเจน
รูปแบบนี้ทำให้เวิร์กโฟลว์คาดเดาได้: ทุกรายการมีสถานะที่ชัดเจน ความล้มเหลวมีที่ไป ผู้ปฏิบัติงานสามารถทำโดยไม่ต้องเดา
ขั้นตอนที่ 1: กำหนดสถานะและการย้ายที่อนุญาต. เขียนชุดสถานะเล็ก ๆ ที่คนเข้าใจได้ (เช่น: Queued, Running, Waiting on external, Succeeded, Failed, Dead-letter) แล้วกำหนดการย้ายที่ถูกต้องเพื่อไม่ให้งานลอยไปในลิมโบ
ขั้นตอนที่ 2: แบ่งงานเป็นขั้นตอนย่อยที่มี input/output ชัดเจน. แต่ละขั้นตอนควรรับ input ที่ชัดและส่ง output หนึ่งอย่างหรือคืน error ชัดเจน ถ้าต้องการการตัดสินของคนหรือการเรียก API ภายนอก ให้แยกเป็นขั้นตอนของตัวเองเพื่อให้หยุดและกลับมาทำต่อได้สะอาด
ขั้นตอนที่ 3: เพิ่มนโยบายการลองใหม่ต่อขั้นตอน. กำหนดจำนวนครั้งสูงสุด เวลาหน่วงระหว่างการลอง และเหตุผลที่ไม่ควรลองใหม่ (ข้อมูลไม่ถูกต้อง, ไม่มีสิทธิ์, ขาดฟิลด์ที่ต้องการ) เก็บตัวนับการลองต่อขั้นตอนเพื่อให้ผู้ปฏิบัติงานเห็นได้ชัดว่าติดตรงไหน
ขั้นตอนที่ 4: บันทึกความก้าวหน้าหลังแต่ละขั้นตอน. เมื่อขั้นตอนเสร็จ ให้บันทึกสถานะใหม่พร้อมผลลัพธ์สำคัญ ถ้ากระบวนการรีสตาร์ท มันควรดำเนินต่อจากขั้นตอนที่เสร็จล่าสุด ไม่ใช่เริ่มใหม่ทั้งหมด
ขั้นตอนที่ 5: ส่งไปยังบันทึก dead-letter และรองรับการประมวลผลซ้ำ. เมื่อลองครบตามจำนวนแล้ว ให้ย้ายรายการไปสถานะ dead-letter และเก็บบริบทเต็ม: ข้อมูลนำเข้า ข้อผิดพลาดสุดท้าย ชื่อขั้นตอน ตัวนับการลอง และ timestamps การประมวลผลซ้ำควรทำอย่างมีสติเพื่อแก้ข้อมูลหรือ config ก่อนแล้วค่อย re-queue จากขั้นตอนที่ระบุ
ขั้นตอนที่ 6: กำหนดฟิลด์แดชบอร์ดและการกระทำของผู้ปฏิบัติงาน. แดชบอร์ดที่ดีตอบว่า “อะไรล้ม ไหน และฉันทำอะไรต่อได้บ้าง?” ใน AppMaster คุณสามารถสร้างเป็นแอปแอดมินเรียบง่ายที่อิงตารางเวิร์กโฟลว์
ฟิลด์และการกระทำสำคัญที่ควรมี:
การ onboarding พนักงานเป็นบททดสอบที่ดี ผสมการอนุมัติ ระบบภายนอก และคนที่ออฟไลน์ ไหลงานง่ายๆ อาจเป็น: HR ส่งฟอร์มพนักงานใหม่ ผู้จัดการอนุมัติ IT สร้างบัญชี และส่งข้อความต้อนรับแก่พนักงานใหม่
ทำให้สถานะอ่านง่าย เมื่่อคนเปิดบันทึกควรเห็นทันทีความแตกต่างระหว่าง “Waiting for approval” และ “Retrying account setup” บรรทัดเดียวที่ชัดเจนช่วยประหยัดเวลาการเดาได้เป็นชั่วโมง
ชุดสถานะที่ชัดเจนสำหรับ UI:
การลองใหม่เหมาะกับขั้นตอนที่พึ่งพาเครือข่ายหรือ API ภายนอก เช่น การ provision บัญชี (อีเมล, SSO, Slack), การส่งอีเมล/SMS, และการเรียก API ภายใน ให้ตัวนับการลองเห็นได้และจำกัด (เช่น ลองสูงสุด 5 ครั้งด้วยเวลาหน่วงเพิ่มขึ้น แล้วหยุด)
การจัดการ dead-letter สำหรับปัญหาที่ไม่หายเอง เช่น ไม่มีผู้จัดการในฟอร์ม, อีเมลไม่ถูกต้อง, หรือคำขอสิทธิ์ขัดกับนโยบาย เมื่อย้ายไหลรันไป dead-letter ให้เก็บบริบท: ฟิลด์ที่ล้ม การตอบกลับ API สุดท้าย และใครเป็นคนที่อนุมัติการยกเว้นได้
ผู้ปฏิบัติงานควรมีชุดการกระทำที่ตรงไปตรงมา: แก้ข้อมูล (ใส่ผู้จัดการ, แก้อีเมล), รันเฉพาะขั้นตอนที่ล้ม (ไม่ใช่ทั้งเวิร์กโฟลว์), หยุดอย่างสะอาด (และยกเลิกการตั้งค่าบางส่วนถ้าจำเป็น)
ด้วย AppMaster คุณสามารถโมเดลนี้ใน Business Process Editor เก็บตัวนับการลองในข้อมูล และสร้างหน้าจอผู้ปฏิบัติงานใน web UI builder ที่โชว์สถานะ ข้อผิดพลาดล่าสุด และปุ่มลองขั้นตอนที่ล้มอีกครั้ง
ปัญหาความเชื่อถือได้ส่วนใหญ่คาดเดาได้: ขั้นตอนทำงานสองครั้ง, การลองใหม่หมุนตอนตีสอง, หรือรายการติดค้างไม่มีเบาะแส เช็คลิสต์ช่วยป้องกันไม่ให้กลายเป็นการเดา
การตรวจสอบด่วนที่จับปัญหาได้ส่วนใหญ่ตั้งแต่ต้น:
ถ้าจะปรับปรุงทีเดียว ให้ปรับการมองเห็นก่อน ปัญหาเวิร์กโฟลว์หลายอย่างแท้จริงแล้วคือ “เราไม่เห็นมันทำอะไร” แดชบอร์ดควรแสดงสิ่งที่เกิดขึ้นล่าสุด สิ่งที่จะเกิดต่อไป และเวลา ผู้ปฏิบัติงานควรเห็นสถานะปัจจุบัน ข้อผิดพลาดล่าสุด ตัวนับการลอง เวลาลองครั้งถัดไป และการกระทำชัดหนึ่งอย่าง (ลองใหม่ตอนนี้, ทำเครื่องหมายว่าแก้แล้ว, หรือส่งให้ตรวจด้วยคน) ทำให้การกระทำปลอดภัยเป็นค่าปกติ: รันซ้ำแค่ขั้นตอนเดียว ไม่ใช่ทั้งเวิร์กโฟลว์
ขั้นตอนถัดไป:
ปฏิบัติต่อเช็คลิสต์นี้เป็นของมีชีวิต เมื่อใดก็ตามที่เพิ่มขั้นตอนใหม่ ให้ทำเช็กเหล่านี้ก่อนนำขึ้นโปรดักชัน
เวิร์กโฟลว์ที่ทำงานนานอาจทำงานสำเร็จเป็นเวลาหลายชั่วโมงแล้วล้มเหลวตอนท้าย ทำให้มีการเปลี่ยนแปลงบางส่วนที่ค้างอยู่ได้ นอกจากนี้ยังพึ่งพาสิ่งที่อาจเปลี่ยนแปลงระหว่างการทำงาน เช่น ความพร้อมใช้งานของบริการภายนอก ข้อมูลประจำตัว (credentials) โครงสร้างข้อมูล และเวลาตอบของคนที่เกี่ยวข้อง
เก็บชุดสถานะให้เล็กและอ่านง่าย เพื่อให้ผู้ดูแลระบบเข้าใจได้ทันที ตัวเลือกมาตรฐานเช่น queued, running, waiting, succeeded และ failed ช่วยได้ โดยแยก “waiting” ออกจาก “running” ให้ชัดเจน เพื่อบอกความต่างระหว่างการรอที่ปกติกับการค้าง
เก็บข้อมูลให้พอทำให้สถานะเป็นประโยชน์: สถานะปัจจุบัน เวลาที่เปลี่ยนสถานะล่าสุด สถานะก่อนหน้า และเหตุผลสั้นๆ เมื่ออยู่ในสถานะรอหรือผิดพลาด ถ้ามีการลองใหม่ ให้เก็บตัวนับความพยายามและเวลาที่จะลองครั้งต่อไปด้วย เพื่อคนไม่ต้องเดาต่อไป
เพราะมันช่วยลดสัญญาณเตือนเท็จและเหตุการณ์ที่พลาดได้ “Waiting for approval” หรือ “waiting for a webhook” อาจเป็นปกติ ขณะที่ “running for six hours” อาจหมายถึงขั้นตอนค้าง การแยกสองสถานะนี้ทำให้การแจ้งเตือนและการตัดสินใจของผู้ปฏิบัติงานดีขึ้น
ลองเฉพาะข้อผิดพลาดที่เป็นไปได้ชั่วคราว เช่น การหมดเวลา (timeout), การจำกัดอัตรา (rate limit) หรือการล่มชั่วคราวของผู้ให้บริการ หลีกเลี่ยงการลองใหม่กับข้อผิดพลาดที่ชัดเป็นถาวร เช่น ข้อมูลไม่ถูกต้อง สิทธิ์ขาด หรือการปฏิเสธบัตร เพราะการลองซ้ำจะเสียเวลาและอาจก่อผลข้างเคียงซ้ำซ้อน
การนับการลองควรแยกตามขั้นตอน (per step) ไม่ใช่รวมทั้งเวิร์กโฟลว์ ขั้นตอนเดียวที่มีปัญหาไม่ควรใช้โอกาสทั้งหมดของงานทั้งงาน การนับแยกช่วยระบุว่า ขั้นตอนไหนล้มเหลว ลองไปกี่ครั้ง และขั้นตอนอื่นยังไม่ถูกกระทบ
เลือกการหน่วงเวลาที่เหมาะสมและตั้งขีดจำกัดเสมอ เช่น หน่วงคงที่สำหรับงานต้นทุนต่ำ หรือ exponential backoff เมื่อเสี่ยงเจอ rate limit ใส่ cap เพื่อไม่ให้เวลารอเพิ่มขึ้นไร้ขอบเขต และเพิ่ม jitter เล็กน้อยเพื่อหลีกเลี่ยงการเกิดสตอร์มการลองใหม่
ถือว่าทุกขั้นตอนอาจทำซ้ำได้ และออกแบบให้การทำซ้ำไม่ก่อผลเสีย โดยใช้คีย์ idempotency ที่คงที่ต่อขั้นตอนที่มีผลข้างเคียง บันทึกว่า “เริ่มขั้นตอนแล้ว” ก่อนเรียกภายนอก และบันทึกผลลัพธ์ทันทีที่ได้มา เพื่อให้การเรียกซ้ำคืนสามารถใช้ผลเดิมแทนการทำซ้ำ
รายการ dead-letter คือรายการที่ล้มเหลวจนถูกย้ายออกจากเส้นทางปกติเพื่อไม่ให้บล็อกงานอื่น เป้าหมายคือทำให้คนที่มาดูเข้าใจว่ามันเกิดอะไรขึ้น ตัดสินใจได้ว่าจะซ่อมแซมได้ไหม และนำกลับมาประมวลผลใหม่อย่างปลอดภัย ดาวน์โหลดเฉพาะข้อความผิดพลาดสั้น ๆ ไม่พอ ต้องมีบริบทมากพอเพื่อให้ทำซ้ำปัญหาได้โดยไม่เดา
แดชบอร์ดที่ดีบอกได้ทันทีว่าเกิดอะไรขึ้น ทำไม และจะเกิดอะไรต่อไป สนับสนุนฟิลด์สม่ำเสมอ เช่น workflow ID, ขั้นตอนปัจจุบัน, สถานะ, เวลาที่อยู่ในสถานะ, ข้อผิดพลาดล่าสุด และ correlation IDs เพื่อให้เชื่อมเหตุการณ์กับระบบภายนอกได้ง่าย ผู้ปฏิบัติงานควรมีตัวเลือกที่ปลอดภัยโดยดีฟอลต์ เช่น ลองใหม่เฉพาะขั้นตอน หยุด/ทำงานต่อ ย้ายไป dead-letter และการกระทำเสี่ยงต้องมีการเตือนชัดเจน



ทดลองกับ AppMaster ด้วยแผนฟรี
เมื่อคุณพร้อม คุณสามารถเลือกการสมัครที่เหมาะสมได้


